
纠错集锦(不断更新中)
1、##修复GRUB引导故障时,重新将GURB引导程序安装到第一块硬盘的MBR扇区时,一直转圈圈,无法进入
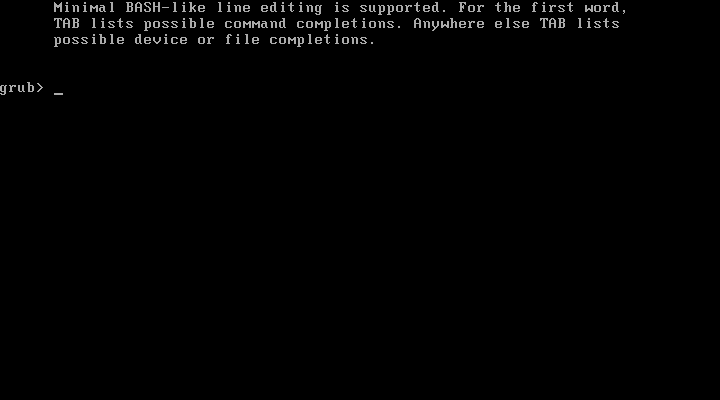
解:这里是因为你有多个分区,可以把分区给删除;也可以使用
##进入急救模式,加载光盘镜像,切换到系统根环境
sh-4.2# chroot /mnt/sysimage
##重新构建GRUB菜单配置文件
bash-4.2# grub2-mkconfig -o /boot/grub2/grub.cfg
##退出chroot环境,并重启
bash-4.2# exit
sh-4.2# exit
##限制使用su命令时,怎么都不成功
1、将允许使用su命令的用户加入wheel组

2、输入命令,进入界面(别忘记这步,也可能导致不成功)

然后把第二行和第六行的注释符“#"删除,保存并退出
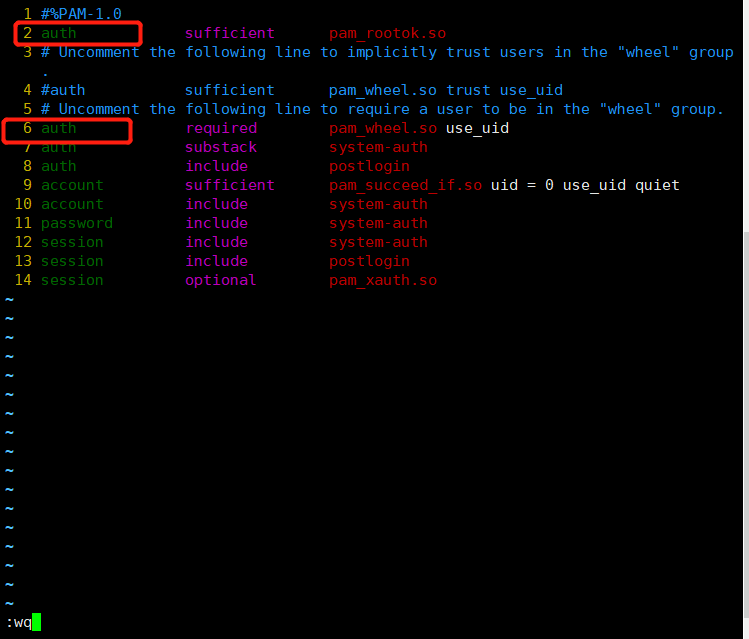
3、限制不成功:
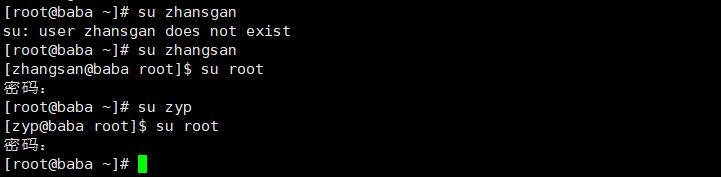
原因:
然后我输入命令进去查看,发现我的zyp账号加入了wheel组,删除之后就成功了


##免交互,实现ssh登录,出现报错
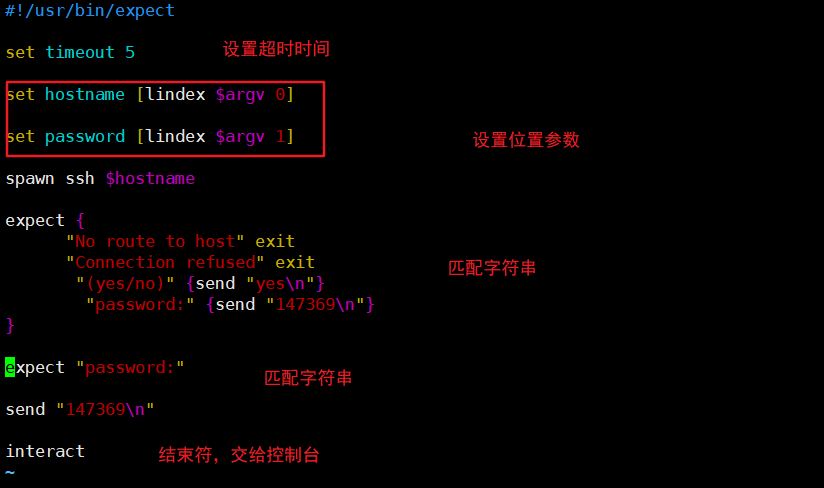
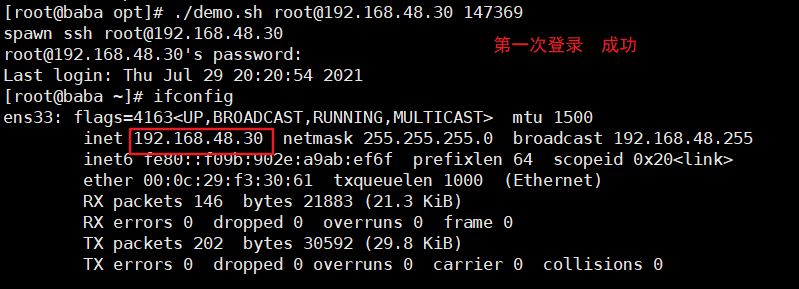

正确的方法
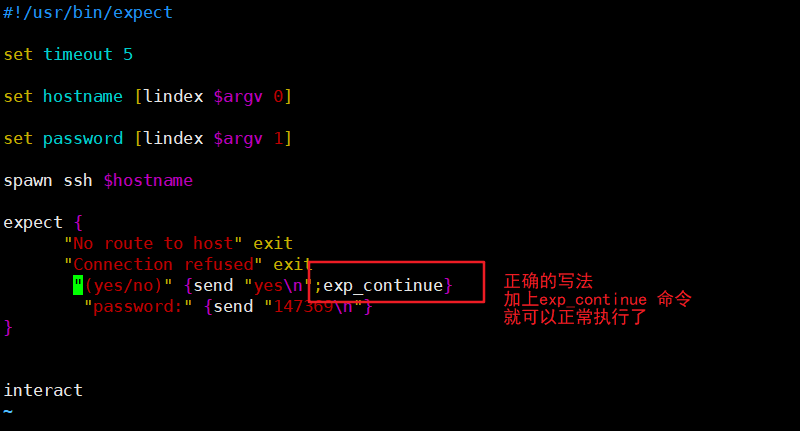
##文件已删除但空间不释放
错误现象:
运维监控系统发来通知,报告一台服务器空间满了

因为Linux没有回收站功能,所以线上服务器所有要删除的文件都会先移动到系统/tmp 目录下,然后定期清除数据。但是通过检查发现这台服务器的系统分区中没有单独划分/tmp 分区,这样还是占用根分区的空间

但是发现磁盘还是没有被释放,这是怎么回事呢?
解决思路:
一般来说删除文件后不会出现空间不被释放的情况,但是也有例外,比如文件被进程锁定,或者进程还在一直向这个文件写入数据
排查问题:

解决问题:
解决这个问题最好的方法就是在线清空这个文件

##Docker日志搞崩我心态
今天想用docker导出文件的时候,发现不行了(原来是空间不足)

查看一下磁盘,还真是满了
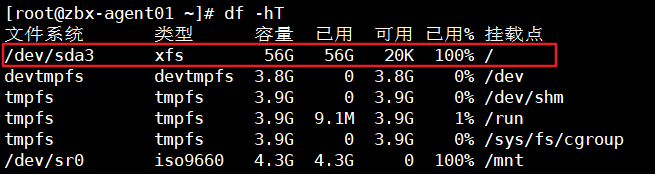
怎么会满了呢?一看原来是容器运行情况下产生的日志都会放在该目录下
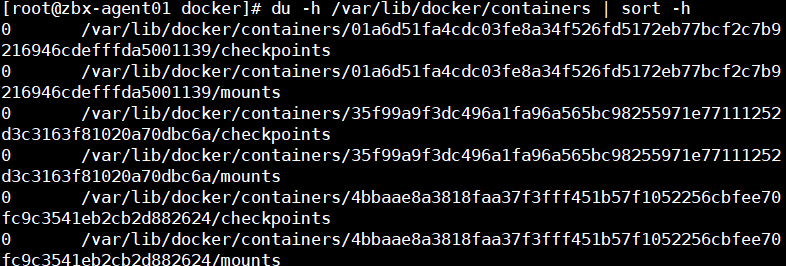
最后,找到问题,把日志文件清理以下就行了
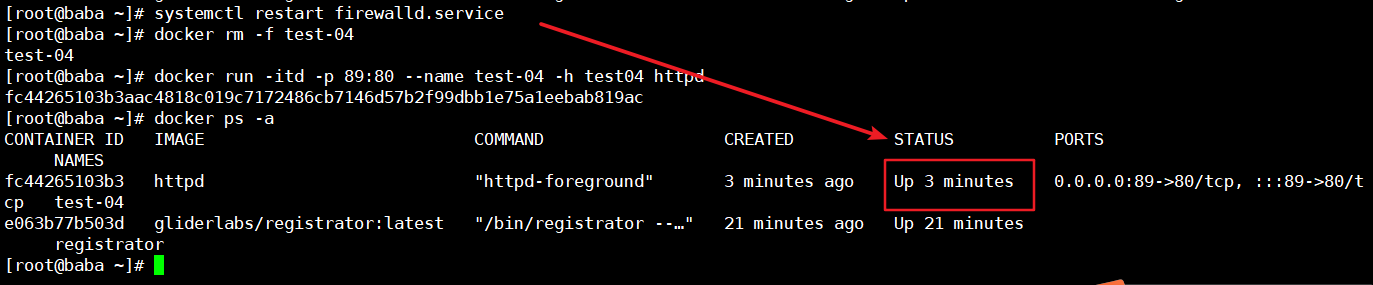
docker run创建镜像的时候,容器起不来
问题报错

这里我们可以看到是防火墙出现问题,之后我重启防火墙就成功了
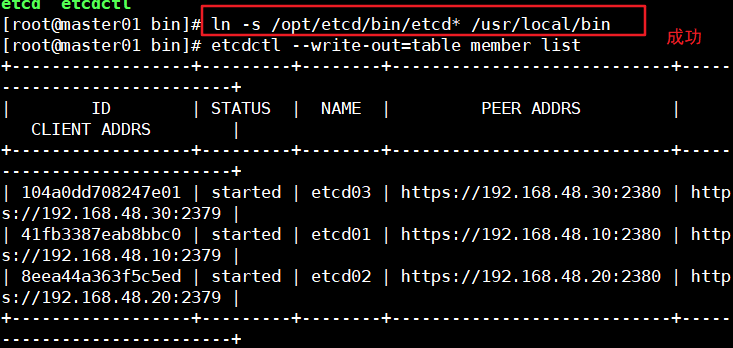
k8s切换到etcd3版本查看集群节点状态和成员列表时(报错:未找到命令 etcdctl)

最后找到问题, 这里需要给etcd做一个软链接,让系统直接识别
kubeadm部署k8s时修改 kube-proxy 的 configmap,开启 ipvs,报错(如下图)

原因:
kubernetes master没有与本机绑定,集群初始化的时候没有绑定。
解决:
此时设置在本机的环境变量即可解决问题。

报错(如下图)
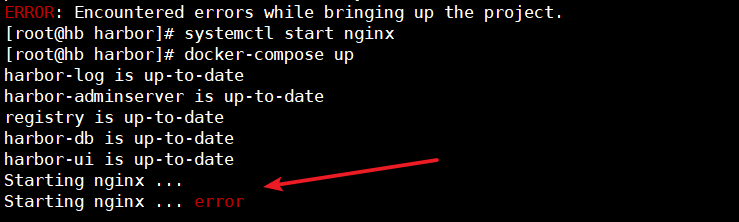
错误出现的原因是,之前启动的 docker-compose 没有关闭。
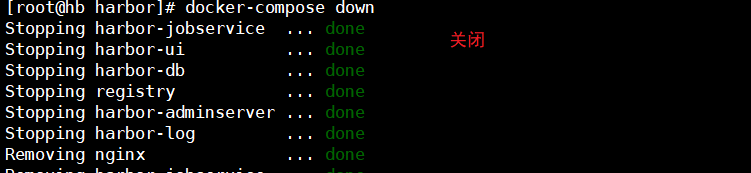
今天在安装Harbor私有仓库的时候,做到在一个node节点上登录harbor(一直报错)
后来我就想我在浏览器上都能成功,为什么在node节点上就不成功(想了很多方法:host没有映射、docker支持https不支持http、防火墙问题等等都不是)
后来再次查看,原来是我的配置文件/etc/docker/daemon.json里出错

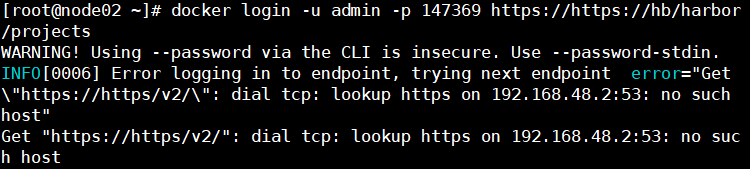
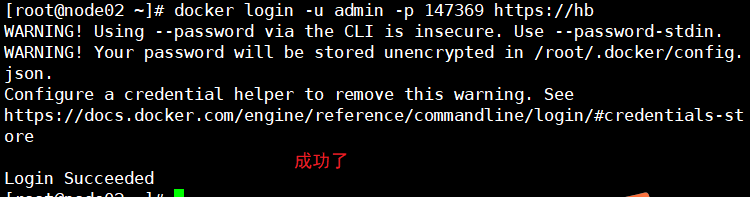
情景还原: 用docker拉取jenkins最新版本 docker pull jenkins/jenkins:lts报了这个错误:
Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker
一通百度,发现原来是dns服务器的错误,把服务器改成8.8.8.8或者114.114.114.114即可
具体做法:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
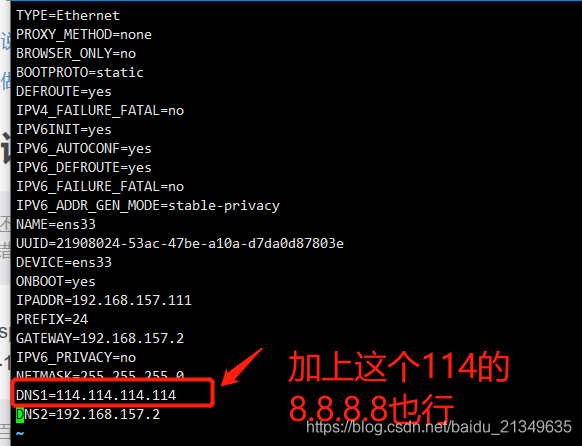
vim /etc/resolv.conf 也加上这行
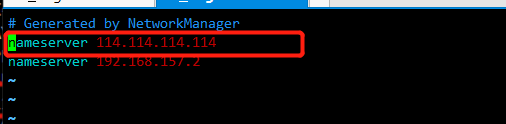
重启网络,systemctl restart network
再来看下,ok啦:

python 通过pip 安装包的时候报错:ImportError: cannot import name 'main'
之前pip升级后,安装包出现过报错:ImportError: cannot import name 'main'
后来就百度的一下,发现文章介绍更改pip设置文件,来实现直接pip install xxx ,
感觉可以,但是没必要,后来看了文档,知道了安装指令,今天安装又忘记了,回顾一下
既然pip升级,更改的原来的pip不可用,那肯定是有考量到某些问题,然后重新定义的加载包的方法,
方式更改为;python -m pip install xxx
在和之前直接pip install xxx 相比,增加了 python -m 属性,
我的理解是通过python脚本模式启动,会避免的pip有很多python版本的问题,直观上更容易操作和理解吧
echo_supervisord_conf > /etc/supervisord.conf
Centos6修改sysctl.conf报错解决方法
这几天一直在折腾VPS优化,openvz构架的,在做linux内核优化的时候,执行/sbin/sysctl -p老报错:
error: "net.bridge.bridge-nf-call-ip6tables" is an unknown key
error: "net.bridge.bridge-nf-call-iptables" is an unknown key
error: "net.bridge.bridge-nf-call-arptables" is an unknown key
error: permission denied on key 'net.ipv4.tcp_max_syn_backlog'
error: permission denied on key 'net.core.netdev_max_backlog'
error: permission denied on key 'net.core.wmem_default'
error: permission denied on key 'net.core.rmem_default'
error: permission denied on key 'net.core.rmem_max'
error: permission denied on key 'net.core.wmem_max'
error: permission denied on key 'net.ipv4.tcp_timestamps'
error: permission denied on key 'net.ipv4.tcp_synack_retries'
error: permission denied on key 'net.ipv4.tcp_syn_retries'
error: permission denied on key 'net.ipv4.tcp_tw_recycle'
error: permission denied on key 'net.ipv4.tcp_tw_reuse'
error: permission denied on key 'net.ipv4.tcp_mem'
error: permission denied on key 'net.ipv4.tcp_max_orphans'
error: permission denied on key 'net.ipv4.ip_local_port_range'
然后就去找资料解决,网络上说前三个错误执行:
帮助12 modprobe bridge lsmod|grep bridge
命令即可,但在执行第一个命令的时候又遇到新错误了~~~
FATAL: Module bridge not found.
咋办,又得去找资料,一开始用百度,找了好久,没一个解决的,后来果断用谷歌啊,接着,你懂的,找到了解决方案,但TM全是英文(也是我发这篇博文的原因),还好我有chrome~碰巧的是顺带找到了后面那七八个错误的解决方案,大快人心啊!
原来这些问题都是因为openvz模版的问题(谷歌翻译是这样说的),要进行修复操作, 修复也很简单,总共四个命令~
修复modprobe的:
| 代码如下 | 复制代码 |
|
rm -f /sbin/modprobe |
|
修复sysctl的:
| 代码如下 | 复制代码 |
|
rm -f /sbin/sysctl |
|
按命令来看就是重建这两个模块的软连接,不过,,,其实我也不是特别清楚,嘿嘿~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号