
节选翻译《Pro SQL Server Internals, 2nd edition》CHAPTER 1 Data Storage Internals 作者:Dmitri Korotkevitch
原文链接:http://www.doc88.com/p-4042504089228.html
Data Pages and Data Rows
数据页和数据行
The space in the database is divided into logical 8KB pages . These pages are continuously numbered starting with zero, and they can be referenced by specifying a file ID and page number. The page numbering is always continuous, such that when SQL Server grows the database file,
new pages are numbered starting from the highest page number in the file plus one. Similarly, when SQL Server shrinks the file, it removes the highest-number pages from the file.
数据库中的空间分为逻辑8KB页。这些页面从零开始连续编号,可以通过指定文件ID和页码来引用。页面编号是连续的,所以当SQL服务器生成数据库文件时,新页面的编号从文件中的最高页码加1开始。类似地,当SQL服务器缩小文件时,它会删除文件中最高的页。
DATA STORAGE IN SQL SERVER
在sql服务器中存储数据
Generally speaking, there are three different ways, or technologies, in which SQL Server stores and works with the data in the database. With the classic row-based storage , the data is stored in data rows that combine the data from all columns together.
一般来说,SQL Server存储和使用数据库中的数据有三种不同的方式或技术。使用经典的基于行的存储,数据存储在将所有列的数据组合在一起的数据行中。
SQL Server 2012 introduced columnstore indexes and column-based storage . This technology stores the data on a per-column rather than a per-row basis. We will cover column-based storage in Part VII of this book.
SQL Server 2012推出了柱状存储索引和基于柱状存储。此技术将数据存储在每列而不是每行。我们会在第7部分介绍柱式储存这部分。
Finally, there is the set of in-memory technologies introduced in SQL Server 2014 and further improved in SQL Server 2016. Even though they persist the data on disk for redundancy purposes, their storage format is very different from both row- and column-based storage. We will discuss in-memory technologies in Part VIII of this book.
最后,在SQL Server 2014中引入了一套内存技术,并在2016年SQL Server中进一步改进。即使他们坚持将数据存储在磁盘上是为了减少冗余,但是他们的存储格式与基于行和列的存储有很大的不同。我们将在本书第八部分讨论内存技术。
This part of the book is focused on row-based storage and classic B-Tree indexes and heaps.
这部分书的重点是基于行的存储和经典的b树索引和堆。
Figure 1-6 shows the structure of a data page.
图1-6显示了数据页的结构
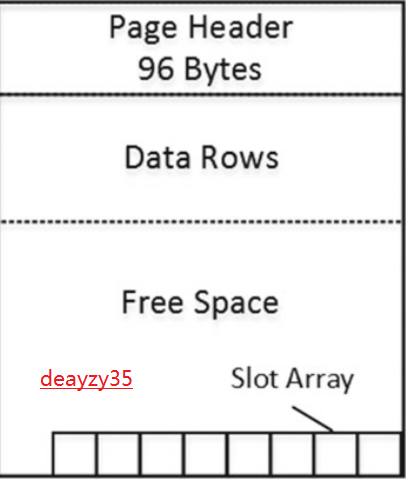
Figure 1-6. The data page structure
图1-6.数据页结构
A 96-byte page header contains various pieces of information about a page, such as the object to which the page belongs, the number of rows and amount of free space available on the page, links to the previous and next pages if the page is in an index-page chain, and so on.
一个96字节的页眉包含了关于页面的各种信息片段,例如页面所属的对象、页面上可用的行数和可用空间的数量,如果页面在索引页链中,则可链接到上一页和下一页等等。
Following the page header is the area where actual data is stored. This is followed by free space. Finally, there is a slot array, which is a block of two-byte entries indicating the offset at which the corresponding data rows begin on the page.
页眉之后是实际数据的存储区域。接下来是自由空间。最后,还有一个空闲数组,它是一个由两个字节组成的空闲框,表示在页面上相应数据行开始时的偏移量。
The slot array indicates the logical order of the data rows on the page. If data on a page needs to be sorted in the order of the index key, SQL Server does not physically sort the data rows on the page, but rather it populates the slot array based on the index sort order. Slot 0 (rightmost in Figure 1-6 ) stores the offset for the data row with the lowest key value on the page; slot 1, the second-lowest key value; and so forth. We will discuss indexes in greater depth in the next chapter.
空闲数组的指示是页上数据行的逻辑顺序。如果页面上的数据需要按照索引键的顺序排序,SQL Server不会对页面上的数据行进行物理排序,而是根据索引顺序填充空闲数组。空闲框0(图1-6中最右边)存储页面上键值最低的数据行的偏移量;空闲框1,键值次低的数据行的偏移量等等。我们将在下一章更深入地讨论索引。
SQL Server offers a rich set of system data types that can be logically separated into two different groups: fixed length and variable length. Fixed-length data types, such as int , datetime , char , and others, always use the same amount of storage space regardless of their value, even when it is NULL . For example, the int column always uses 4 bytes and an nchar(10) column always uses 20 bytes to store information.
SQL Server提供了一组丰富的系统数据类型,这些数据类型在逻辑上可以分为两个不同的组:固定长度和可变长度。固定长度的数据类型,如int、日期时间、char等,无论其值如何,总是使用相同数量的存储空间,即使它是空的。例如,int类型总是使用4字节,nchar(10)类型总是使用20字节来存储信息。
In contrast, variable-length data types, such as varchar , varbinary , and a few others, use as much storage space as is required to store data, plus two extra bytes. For example, an nvarchar(4000) column would use only 12 bytes to store a five-character string and, in most cases, two bytes to store a NULL value. We will discuss the case where variable-length columns do not use storage space for NULL values later in this chapter.
相比之下,可变长度的数据类型,如varchar、varbinary和其他的类型,使用存储数据所需的存储空间,需要再加上两个额外的字节。例如,nvarchar(4000)类型只使用12个字节来存储一个五个字符的字符串,在大多数情况下,使用两个字节来存储一个空值。我们将在本章后面讨论可变长列不使用空值存储空间的情况。
Let’s look at the structure of a data row, as shown in Figure 1-7 .
让我们看看数据行的结构,如图1-7所示。
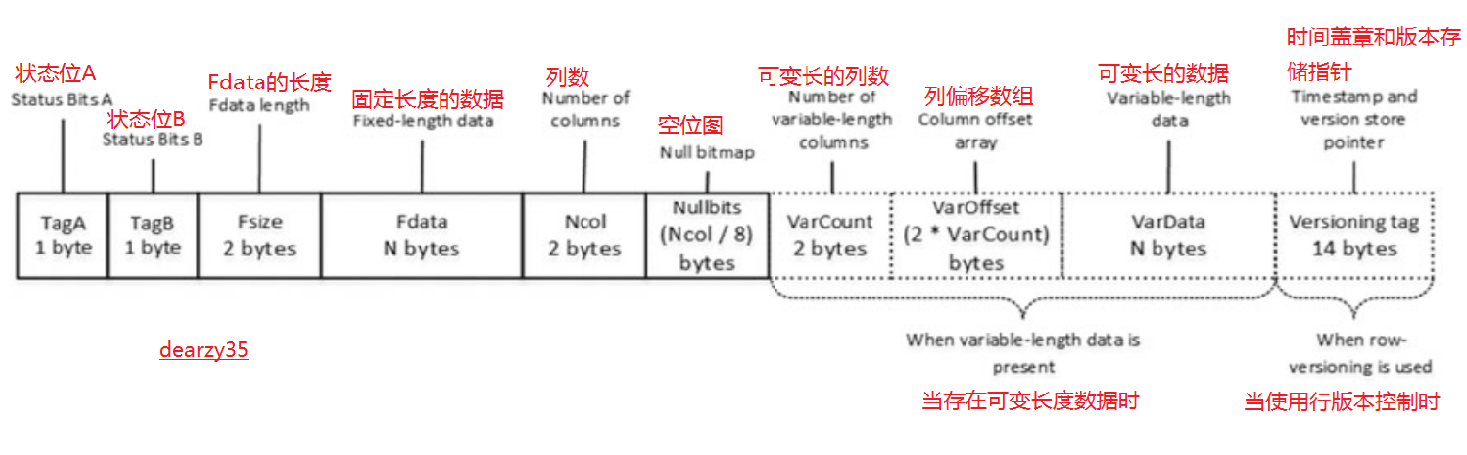
The first two bytes of the row, called Status Bits A and Status Bits B , are bitmaps that contain information about the row, such as row type, if the row has been logically deleted (ghosted), and if the row has NULL values, variable-length columns, and a versioning tag.
行的前两个字节,称为状态位A和状态位B,是位图,其中包含关于行的信息,比如行类型,如果行已经被逻辑删除(重定向),如果行有空值、可变长度列和版本控制标记。
The next two bytes in the row are used to store the length of the fixed-length portion of the data. They are followed by the fixed-length data itself.
行中接下来的两个字节用于存储数据的固定长度部分的长度。然后是固定长度的数据本身。
After the fixed-length data portion, there is a null bitmap , which includes two different data elements. The first two-byte element is the number of columns in the row. The second is a null bitmap array. This array uses one bit for each column of the table, regardless of whether it is nullable or not.
在固定长度的数据部分之后,有一个空位图,它包含两个不同的数据元素。第一个双字节元素是行中的列数。第二个是空位图数组。这个数组对表的每一列使用一位,不管它是否为空。
A null bitmap is always present in data rows in heap tables or clustered index leaf rows, even when the table does not have nullable columns. However, the null bitmap is not present in non-leaf index rows nor in leaf-level rows of nonclustered indexes when there are no nullable columns in the index.
空位图总是出现在堆表或聚集索引叶行的数据行中,即使表没有可空列。但是,当索引中没有可空列时,空位图不会出现在非叶索引行中,也不会出现在非聚集索引的叶级行中。
Following the null bitmap, there is the variable-length data portion of the row. It starts with a two-byte number of variable-length columns in the row followed by a column-offset array. SQL Server stores a two-byte offset value for each variable-length column in the row, even when the value is NULL. It is followed by the actual variable-length portion of the data. Finally, there is an optional 14-byte versioning tag at the end of the row. This tag is used during operations that require row versioning,such as an online index rebuild, optimistic isolation levels, triggers, and a few others.
在空位图之后,存在该行的可变长度数据部分。它以行中两个字节数量的可变长度列开始,接着是列-偏移阵列。SQL 服务器为行中的每个可变长列存储一个双字节偏移量值,即使该值为空。然后是数据的实际可变长度部分。最后,在该行的末尾有一个可选的14字节版本标记。此标记用于需要行版本控制的操作,例如在线索引重建、乐观隔离级别、触发器和其他一些操作。
Let’s create a table, populate it with some data, and look at the actual row data. The code is shown in Listing 1-4 . The Replicate function repeats the character provided as the first parameter ten times.
让我们创建一个表,用一些数据填充它,并查看实际的行数据。代码如列表1-4所示。复制函数将第一个参数提供的字符重复10次。
Listing 1-4. The data row format: Table creation
列表1-4 数据行格式:表创建
create table dbo.DataRows
(
ID int not null,
Col1 varchar(255) null,
Col2 varchar(255) null,
Col3 varchar(255) null
);
insert into dbo.DataRows(ID, Col1, Col3) values (1,replicate('a',10),replicate('c',10));
insert into dbo.DataRows(ID, Col2) values (2,replicate('b',10));
dbcc ind
(
'SQLServerInternals' /*Database Name*/
,'dbo.DataRows' /*Table Name*/
,-1 /*Display information for all pages of all indexes*/
);
An undocumented but well-known DBCC IND command returns information about table page allocations. You can see the output of this command in Figure 1-8 .
一个无记录的但知名的DBCC IND命令返回了关于页面分配的信息。您可以在图1-8中看到该命令的输出。

Figure 1-8. DBCC IND output
图1-8 DBCC IND 输出
There are two pages that belong to the table. The first one, with PageType=10 , is a special type of page called an IAM allocation map . This page tracks the pages that belong to a particular object.Do not focus on that now, however, as we will cover allocation map pages later in this chapter.
有两个页面是属于这个表的。第一个,带有PageType = 10,是被称为IAM分配映射的特殊类型的页面。这一页记录了某个特定对象的页面。但是,现在不要专注于此,因为我们将在本章后面讨论分配映射页面。
Note SQL Server 2012 introduces another undocumented data-management function (DMF) , sys.dm_db_database_page_allocations , which can be used as a replacement for the DBCC IND command. The output of this DMF provides more information when compared to DBCC IND , and it can be joined with other system DMVs and/or catalog views.
笔记 SQL Server 2012引入了另一个未文档化的数据管理功能(DMF) sys。dm_db_database_page_assignments,它可以用作DBCC IND命令的替代。与DBCC IND相比,此DMF的输出提供了更多信息,并且可以与其他系统dmv和/或目录视图连接。
The page with PageType=1 is the actual data page that contains the data rows. The PageFID and PagePID columns show the actual file and page numbers for the page. You can use another undocumented command, DBCC PAGE , to examine its contents, as shown in Listing 1-5.
带有PageType = 1的页面是包含数据行的实际数据页面。PageFID和PagePID列显示了页面的实际文件和页码。您可以使用另一个未文档化的命令DBCC PAGE来检查其内容,如列表1-5所示。
Listing 1-5. The data row format: DBCC PAGE call
列表1-5 数据行格式:DBCC页面调用
-- Redirecting DBCC PAGE output to console
——页面重定向DBCC输出到控制台
dbcc traceon(3604);
dbcc page
(
'SqlServerInternals' /*Database Name*/
,1 /*File ID*/
,214643 /*Page ID*/
,3 /*Output mode: 3 - display page header and row details */
);
Listing 1-6 shows the output of the DBCC PAGE that corresponds to the first data row. SQL Server stores the data in byte-swapped order. For example, a two-byte value of 0001 would be stored as 0100 .
列表1-6显示了对应于第一行数据的DBCC页面的输出。SQL Server以字节交换的顺序存储数据。例如,两个字节的值0001将存储为0100。
Listing 1-6. DBCC PAGE output for the first row Slot 0 Offset 0x60 Length 39
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 39 Memory Dump @0x000000000EABA060 0000000000000000: 30000800 01000000 04000403 001d001d 00270061 0................'.a
0000000000000014: 61616161 61616161 61636363 63636363 636363 aaaaaaaaacccccccccc
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4 ID = 1
Slot 0 Column 2 Offset 0x13 Length 10 Length (physical) 10 Col1 = aaaaaaaaaa
Slot 0 Column 3 Offset 0x0 Length 0 Length (physical) 0 Col2 = [NULL]
Slot 0 Column 4 Offset 0x1d Length 10 Length (physical) 10 Col3 = cccccccccc
Let’s look at the data row in more detail, as shown in Figure 1-9 .
让我们更详细地查看数据行,如图1-9所示。
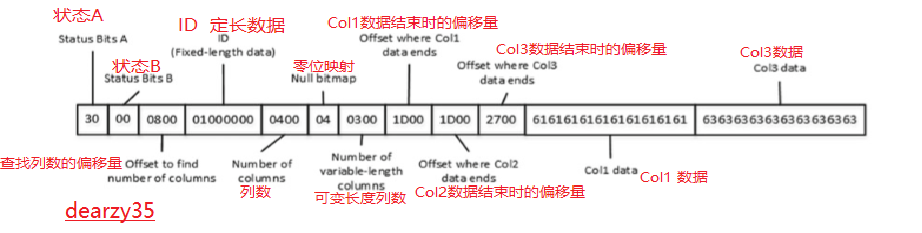
Figure 1-9. First data row
As you can see, the row starts with the two status bits followed by a two-byte value of 0800 . This is the byte-swapped value of 0008 , which is the offset for the Number of Columns attribute in the row. This offset tells SQL Server where the fixed-length data part of the row ends.
正如您所看到的,行以两个状态位开始,然后是两个字节的值0800。这是字节交换值0008,它是行中列数属性的偏移量。这个偏移量告诉SQL Server行中固定长度的数据部分在哪里结束。
The next four bytes are used to store fixed-length data, which is the ID column in our case. After that, there is the two-byte value that shows that the data row has four columns, followed by a one-byte NULL bitmap. With just four columns, one byte in the bitmap is enough. It stores the value of 04 , which is 00000100in the binary format. It indicates that the third column in the row contains a NULL value.
接下来的4个字节用于存储固定长度的数据,在我们的示例中是ID列。在那之后,有一个双字节值显示数据行有四列,然后是一个单字节的空位图。如果只有四列,位图中的一个字节就足够了。它以二进制格式存储04的值,即00000100。它表示行中的第三列包含空值。
The next two bytes store the number of variable-length columns in the row, which is 3 ( 0300 in byte[1]swapped order). It is followed by an offset array, in which every two bytes store the offset where the variable[1]length column data ends. As you can see, even though Col2 is NULL, it still uses the slot in the offset array. Finally, there is the actual data from the variable-length columns.
接下来的两个字节存储行中可变长度列的数量,即3(字节顺序为0300)。它后面是一个偏移量数组,其中每两个字节存储变量列数据结束的偏移量。如您所见,即使Col2为NULL,它仍然使用偏移数组中的插槽。最后,还有来自可变长度列的实际数据。
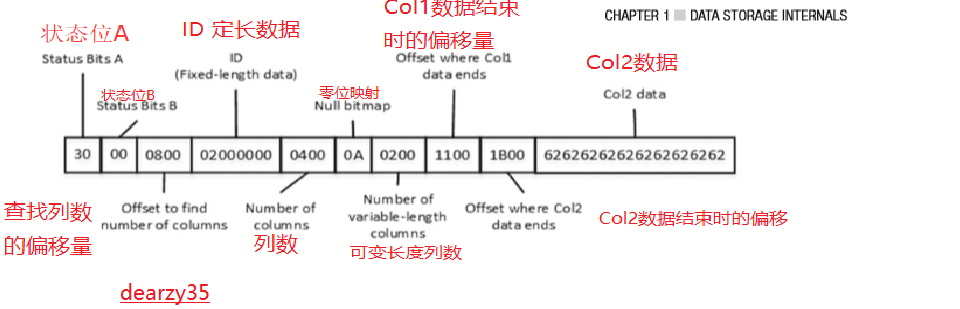
Now, let’s look at the second data row. Listing 1-7 shows the DBCC PAGE output, and Figure 1-10 shows
the row data.
现在,让我们看看第二个数据行。清单1-7显示DBCC页面输出,图1-10显示行数据。
Figure 1-10. Second data row data
图1-10。第二数据行数据
Listing 1-7. DBCC PAGE output for the second row
清单1-7。第二行的DCBC页输出
Record Type = PRIMARY_RECORD
Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 27
Memory Dump @0x000000000EABA087
0000000000000000: 30000800 02000000 04000a02 0011001b 00626262 0................bbb
0000000000000014: 62626262 626262 bbbbbbb
Slot 1 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID = 2
Slot 1 Column 2 Offset 0x0 Length 0 Length (physical) 0
Col1 = [NULL]
Slot 1 Column 3 Offset 0x11 Length 10 Length (physical) 10
Col2 = bbbbbbbbbb
Slot 1 Column 4 Offset 0x0 Length 0 Length (physical) 0
Col3 = [NULL]
The NULL bitmap in the second row represents a binary value of 00001010 , which shows that Col1 and Col3 are NULL. Even though the table has three variable-length columns, the number of variable-length columns in the row indicates that there are just two columns/slots in the offset array. SQL Server does not maintain the information about the trailing NULL variable-length columns in the row.
第二行中的NULL位图表示二进制值00001010,表明Col1和Col3是NULL。即使表有三个可变长度列,行中可变长度列的数量表明偏移数组中只有两个列/插槽。SQL Server不维护关于行中尾随的NULL可变长度列的信息。
Tip You can reduce the size of the data row by creating tables in a manner in which variable-length columns, which usually store null values, are defined as the last ones in the CREATE TABLE statement. This is the only case in which the order of columns in the CREATE TABLE statement matters.
提示:通过创建表,可以将通常存储空值的可变长列定义为CREATE TABLE语句中的最后一个列,可以减少数据行的大小。这是CREATE TABLE语句中列顺序唯一重要的情况。
The fixed-length data and internal attributes must fit into the 8,060 bytes available on the single data page. SQL Server does not let you create the table when this is not the case. For example, the code in Listing 1-8 produces an error.
固定长度的数据和内部属性必须符合单个数据页上可用的8060字节。当情况不是这样时,SQLServer不允许您创建表。例如,清单1-8中的代码会产生错误。
CHAPTER 1 DATA STORAGE INTERNALS
第一章 数据保存内部构件
Listing 1-8. Creating a table with a data row size that exceeds 8,060 bytes
列表1-8. 创建一个表,它的数据行大小超过8060
create table dbo.BadTable //创建一个表,表名为dbo.BadTable
(
Col1 char(4000), //定义一个长度为4000的数据Col1
Col2 char(4060) //定义一个长度为4060的数据Col2
)
Large Objects Storage
Even though the fixed-length data and the internal attributes of a row must fit into a single page, SQL Server can store the variable-length data on different data pages. There are two different ways to store the data, depending on the data type and length.
Msg 1701,16级,状态1,第1行
创建或更改“BadTable”表失败,因为最小行的大小是8067,包括7个字节的内部开销。这超过了最大表行允许的8060字节。
SQL Server stores variable-length column data that does not exceed 8,000 bytes on special pages called row-overflow pages. Let’s create a table and populate it with the data shown in Listing 1-9 .
大对象存储
即使固定长度数据和行的内部属性必须适合于单个页面,SQL Server也可以将可变长度数据存储在不同的数据页上。根据数据类型和长度,有两种不同的方法存储数据。
Row-Overflow Storage
SQL Server stores variable-length column data that does not exceed 8,000 bytes on special pages called row-overflow pages. Let’s create a table and populate it with the data shown in Listing 1-9 .
溢出存储
QL Server在称为行溢出页的特殊页上存储不超过8000字节的可变长度列数据。让我们创建一个表并用清单1-9所示的数据填充它。
Listing 1-9. Row-overflow data: Creating a table
清单1-9。行溢出数据:创建表
create table dbo.RowOverflow //建表,表名为dbo.RowOverflow
(
ID int not null, //定义一个整型数据,数据名为ID,不允许为空
Col1 varchar(8000) null, //定义一个变长数据,数据名为Col1,长度为8000,允许为空
Col2 varchar(8000) null //定义一个变长数据,数据名为Col2,长度为8000,允许为空
);
insert into dbo.RowOverflow(ID, Col1, Col2) values (1,replicate('a',8000),replicate('b',8000)); //插入一行记录,“ID”的值为1,“Col1”的值为a,a等于8000,“Col2”的值为b,b等于8000
As you see, SQL Server creates the table and inserts the data row without any errors, even though the data-row size exceeds 8,060 bytes. Let’s look at the table page allocation using the DBCC IND command. The results are shown in Figure 1-11 .
正如你所见,SQL Server创建表并插入数据行,即使数据行大小超过8060字节,也没有任何错误。让我们看看使用DCBC IND的命令分配表页。结果如图1-11所示。

Figure 1-11. R ow-overflow data: DBCC IND results
图1-11。溢出数据:DCBC IND结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号