
直接操作DOM一定比虚拟DOM操作耗时,diff算法,key值,虚拟 DOM的定义
直接操作DOM一定比虚拟DOM操作耗时吗?
或者一次直接DOM操作一定比一次虚拟DOM操作耗时吗?
1)虚拟DOM的本质就是一个JS对象,虚拟DOM减少了真实DOM的操作,当修改数据的时候,就是修改虚拟DOM产生全新的虚拟DOM,
新旧虚拟DOM使用diff算法,得到patch(也就是需要修改的部分),然后将这个patch打到浏览器的DOM上
(减少重绘和回流,从而达到性能优化的目的)
2)每次DOM操作会引起重绘或者回流,频繁的真实DOM的修改会触发多次的排版和重绘相当耗性能(完全增删改)
一)、虚拟DOM
1)DOM的本质是什么?
DOM是浏览器中的概念,用js对象表示页面上的元素,并提供操作DOM对象的API
2)React中的虚拟DOM是什么?
虚拟DOM就是一个JS对象(数据+JXS模板),用一个js对象来描述真实的DOM
虚拟DOM为什么会提高性能?
虚拟DOM提高性能,不是说不操作DOM,而是减少操作DOM的次数,减少回流和重绘
虚拟 dom 相当于在 js 和真实 dom 中间加了一个缓存,利用 dom diff 算法避免了没有必要的 dom 操作,从而提高性能
1)用 JavaScript 对象结构表示 DOM 树的结构;
2)然后用这个树构建一个真正的 DOM 树,插到文档当中
3)当状态变更的时候,重新构造一棵新的对象树
4)然后用新的树和旧的树进行比较,记录两棵树差异
5)把 2所记录的差异应用到步骤 2)所构建的真正的 DOM 树上,视图就更新了
使用diff算法比较新旧虚拟DOM----即比较两个js对象不怎么耗性能,而比较两个真实的DOM比较耗性能,从而虚拟DOM极大的提升了性能
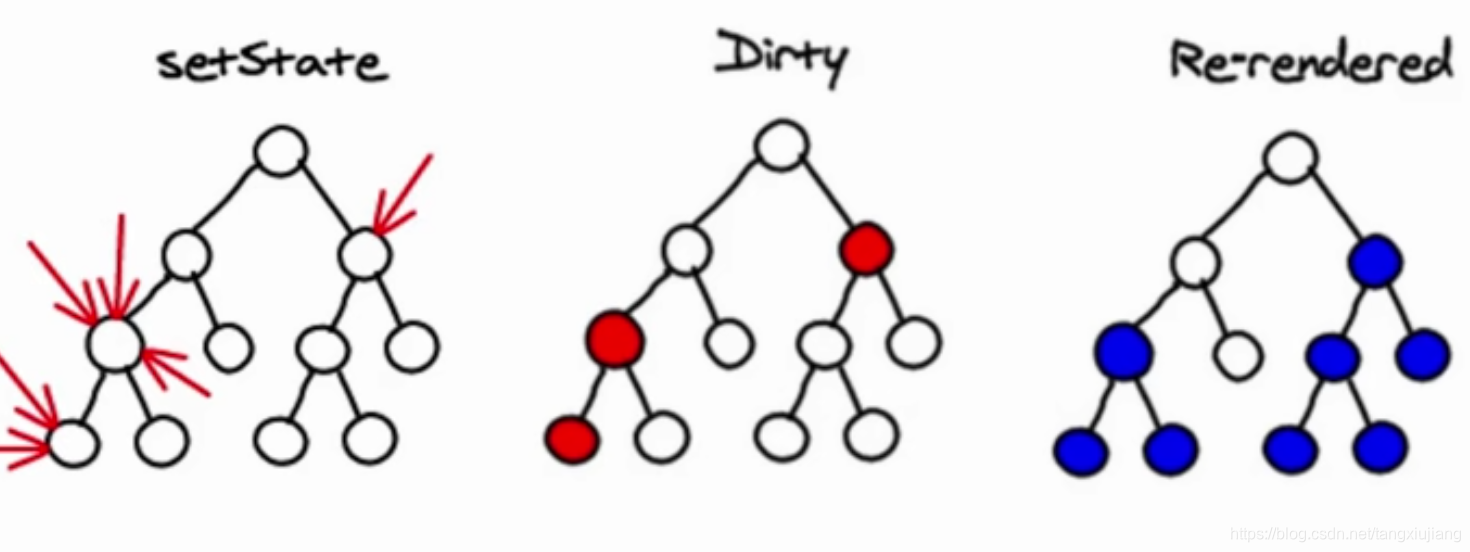
虚拟DOM发生比对的时机:当数据发生变化的时候会发生虚拟DOM的比对(props和state发生变化,而props的变化是父组件的state发生变化,归根结底就是调用setState()的时候state发生变化,然后虚拟DOM发生比对)。
setState()方法是异步的,从而提升性能-----例如调用3次setState()变更数据,而调用时间间隔小,React可以将3次setState合并成一次setState,只做一次虚拟DOM比对,然后对DOM更新,从而省去两次额外虚拟DOM比对的性能损耗
调用setState()之后发生了什么?
1)首先,React 将setState()方法中传入的参数对象与组件当前的状态合并
2)然后,触发调和过程(Reconciliation)
3)经过调和过程后,React 会以相对高效的方式,根据新的状态构建 React 元素树
4)在 React 得到元素树之后,React 会自动计算出新的树与老树的节点差异,然后根据差异对界面进行最小化重渲染。
在差异计算算法中,React 能够相对精确地知道哪些位置发生了改变以及应该如何改变,这就保证了按需更新,而不是全部重新渲染。
3)虚拟DOM的目的?
实现页面中DOM元素的高效更新
二)、diff算法:同层比对,列表使用不同的key值
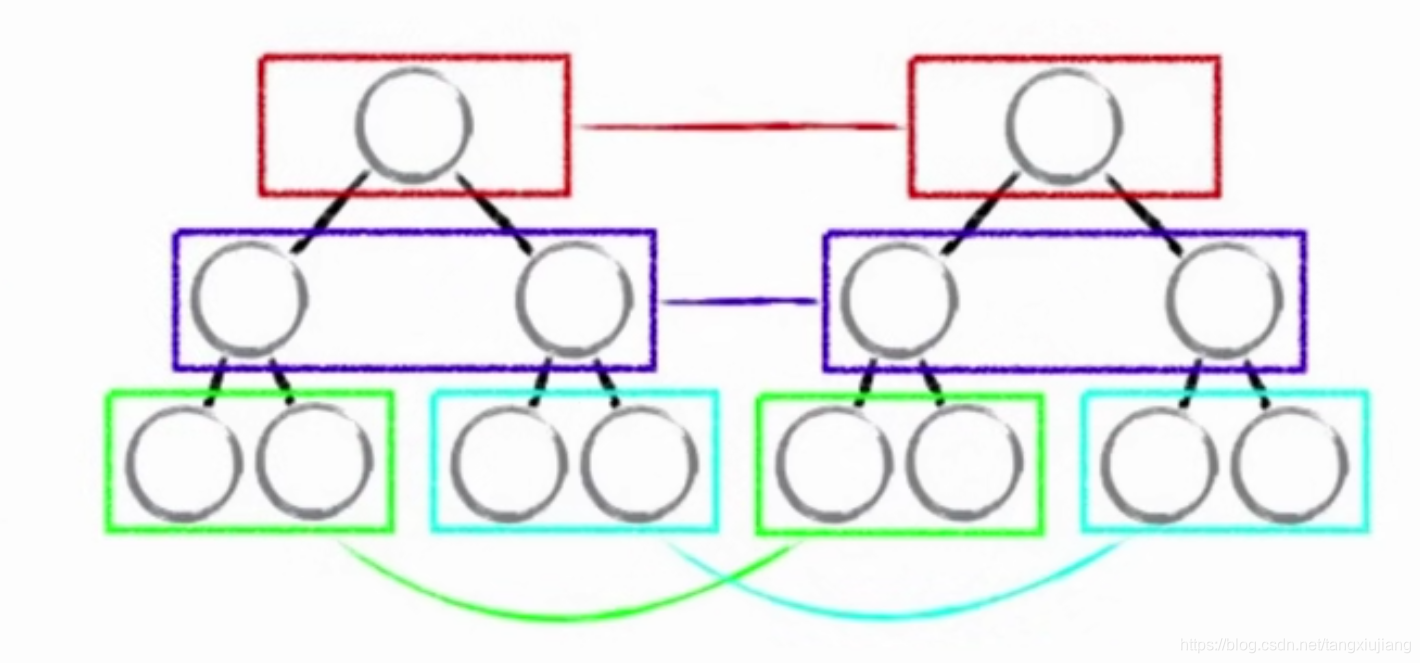
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的 key 属性,方便比较。
- React 只会匹配相同 class 的 component(这里面的 class 指的是组件的名字)
- 合并操作,调用 component 的 setState 方法的时候, React 将其标记为 dirty.到每一个事件循环结束, React 检查所有标记 dirty 的 component ,然后重新绘制.
- 选择性子树渲染。开发人员可以重写 shouldComponentUpdate 提高 diff 的性能
React的DOM是同层比对的
diff算法指的就是两个虚拟DOM作比对,在diff算法中有个概念就是同级比对,首先比对顶层虚拟DOM节点是否一致,如果一样就接着比对下一层,如果不一样,就停止向下比对,将原始页面中这个DOM及 下面的DOM全部删除掉,重新生成新的虚拟DOM,然后替换掉原始页面的DOM
存在问题:如果第一层虚拟DOM节点不同,下面的都同,使用虚拟DOM的diff算法,则这些节点都不能使用了,会造成重新渲染的浪费。
优点:同层虚拟DOM比对,只需要一层层的比较,算法简单,比对的速度快
虽然会造成重新渲染的浪费,但是会大大减少两个虚拟DOM比对的性能消耗
列表中的元素使用不同的key
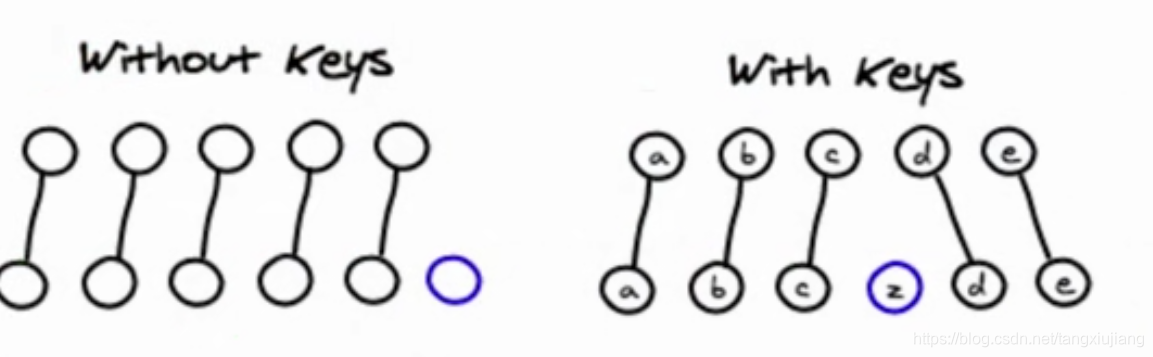
虚拟DOM中的列表中同级元素的key值要不同,使用diff算法,判断哪些元素是增删改,从而提高性能
列表中key的作用:
1)key是React用于跟踪哪些元素是增加、删除、修改的辅助标记,需要保证在同级元素中key的唯一性
2) React Diff 算法借助元素的 Key 值判断元素是新增、删除、修改,从而减少不必要的元素重渲染。
3)React 还需要借助 Key 值来判断元素与本地状态的关联关系
问题:在循环中key值最好不要用index的原因?
如果key值使用index的话,就可能无法使原始的虚拟DOM中的key值和新的虚拟DOM中的key值一致,从而不能充分发挥diff算法的优势。
比如一个数组里有数据a b c,用index表示的key分别为0 1 2
当删除a时,b c的key分别为0 2,从而导致元素的新旧key值不一样,即key值不稳定,所以key值就失去其存在的意义了
比较合适的key值有:id或者不一样的内容
1)tree diff
新旧两颗DOM树,逐层对比的过程,就是Tree Diff;当整颗DOM树逐层对比完毕,则所有按需更新的元素都能找到
2)component diff
在进行Tree Diff的时候,每一层中,组件级别的对比,叫做Component Diff
如果对比前后,组件类型相同,则暂时认为此组件不需要更新;
如果对比前后,组件类型不同,则需要移除旧组件。创建新组建,并追加到页面上
3)element diff
在进行组件对比的时候,如果两个组件类型相同,则需要进行元素级别的对比,这叫做element diff

 浙公网安备 33010602011771号
浙公网安备 33010602011771号