
数据库 SQL Server Management Studio 20 的快速入门
这里可以在搜索的位置直接输入
数据库 ssms 是这个首字母
是这个软件的简称
数据库分好多种,最主流的是Oracle,Oracle是最重量级的,安装也比较难,属于最安全的。一般国家单位都用Oracle,Oracle正版的很贵。
还有一种就是 SQL Server,SQL Server是 Windows 的,如果说布到 Linux系统上 可能会有问题。有一定的局限性。
还有一种是MySQL两个相比呢,MySQL是比较轻量级的。
关系型数据库:Oracle,SQL Server,MySQL主流的就这些,但是现在大部分人用MySQL,MySQL是最轻量级的,安装也方便,好像还是开源的。其实基本都一样,大同小异。
这三个都是数据库,不是说电脑上安装了就可以访问,需要一个工具访问。也就是通过一个软件访问。
Oracle plsql
SQL Server ssms
MySQL navicat
还有非关系型数据库...,这里先不说了。
咱们这里就来说一下 SQL Server用这个 ssms ,
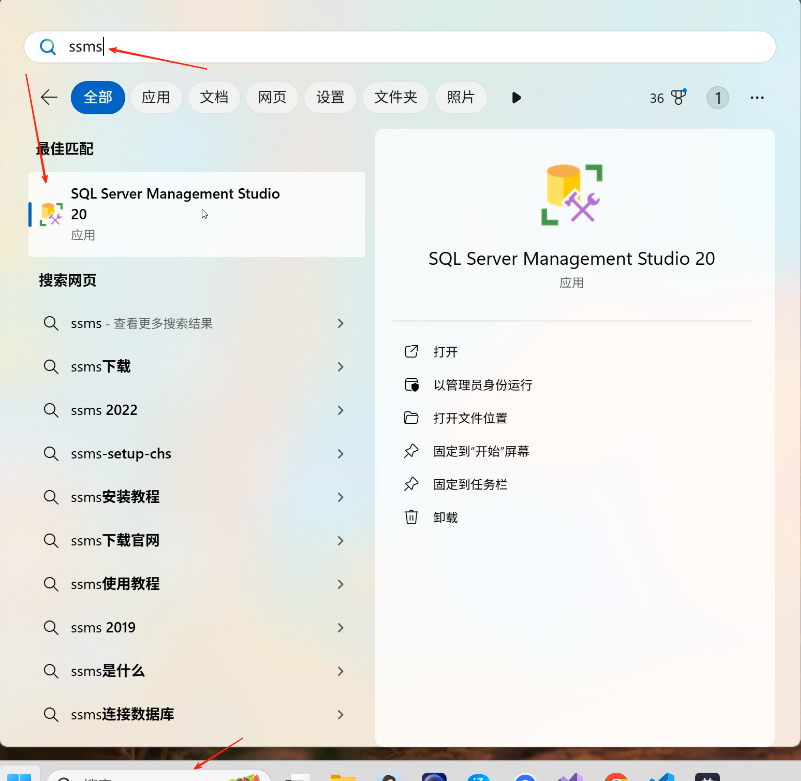
我们打开看一下
打开之后这里有连接
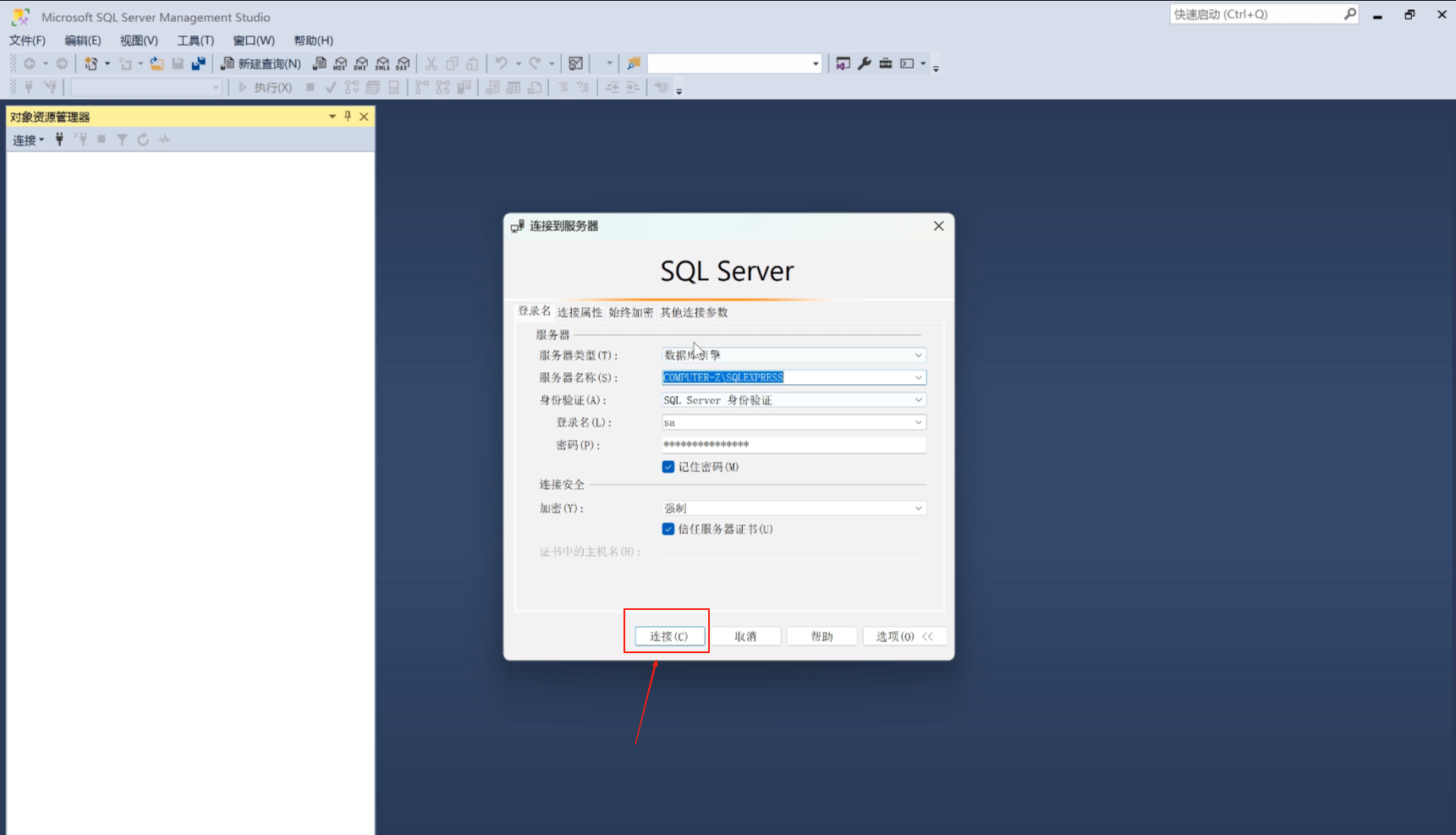
这里我们之前安装好了,这里是安装SQL Server的时候给的这个
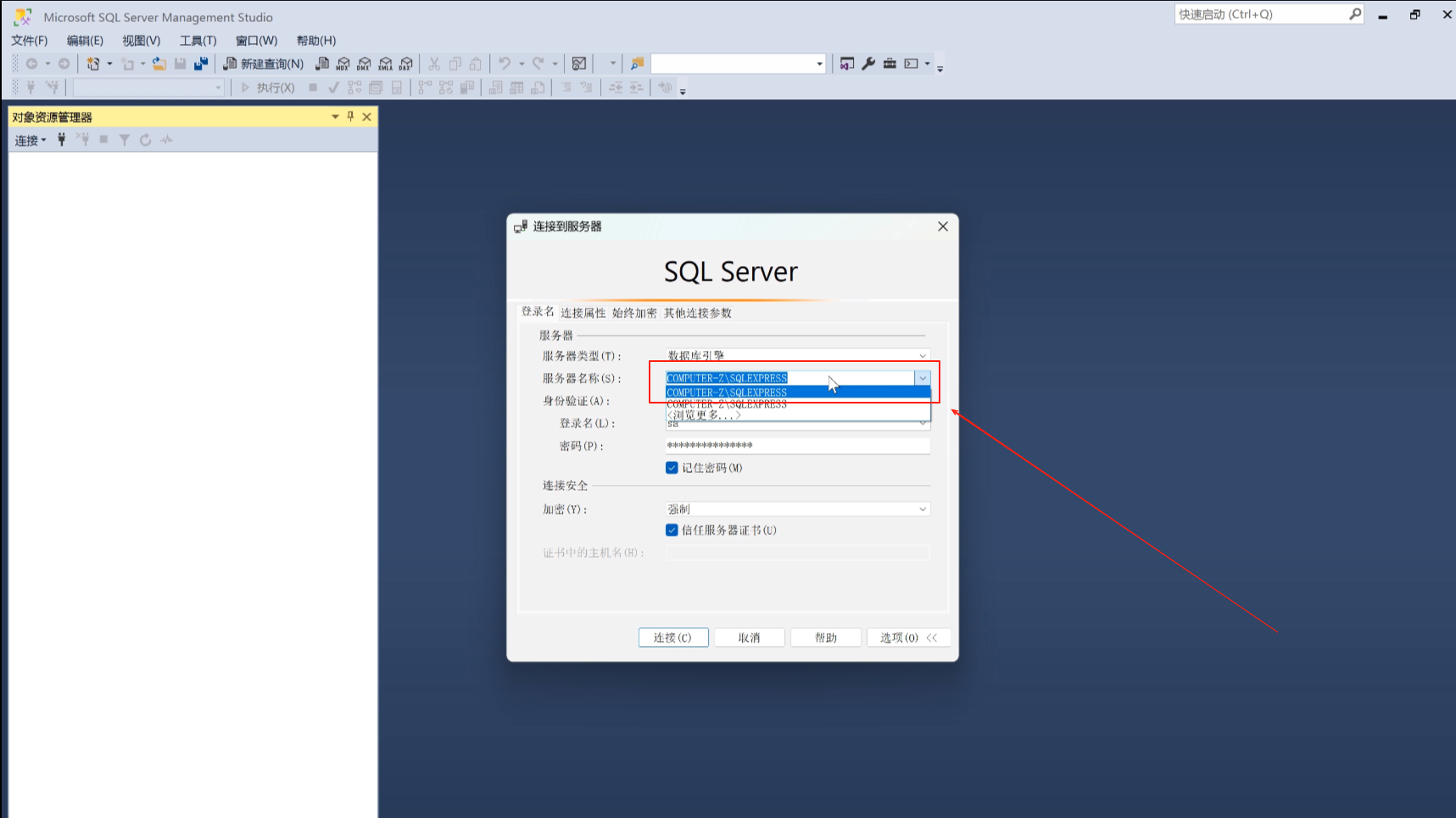
这是这个数据库的帐号密码
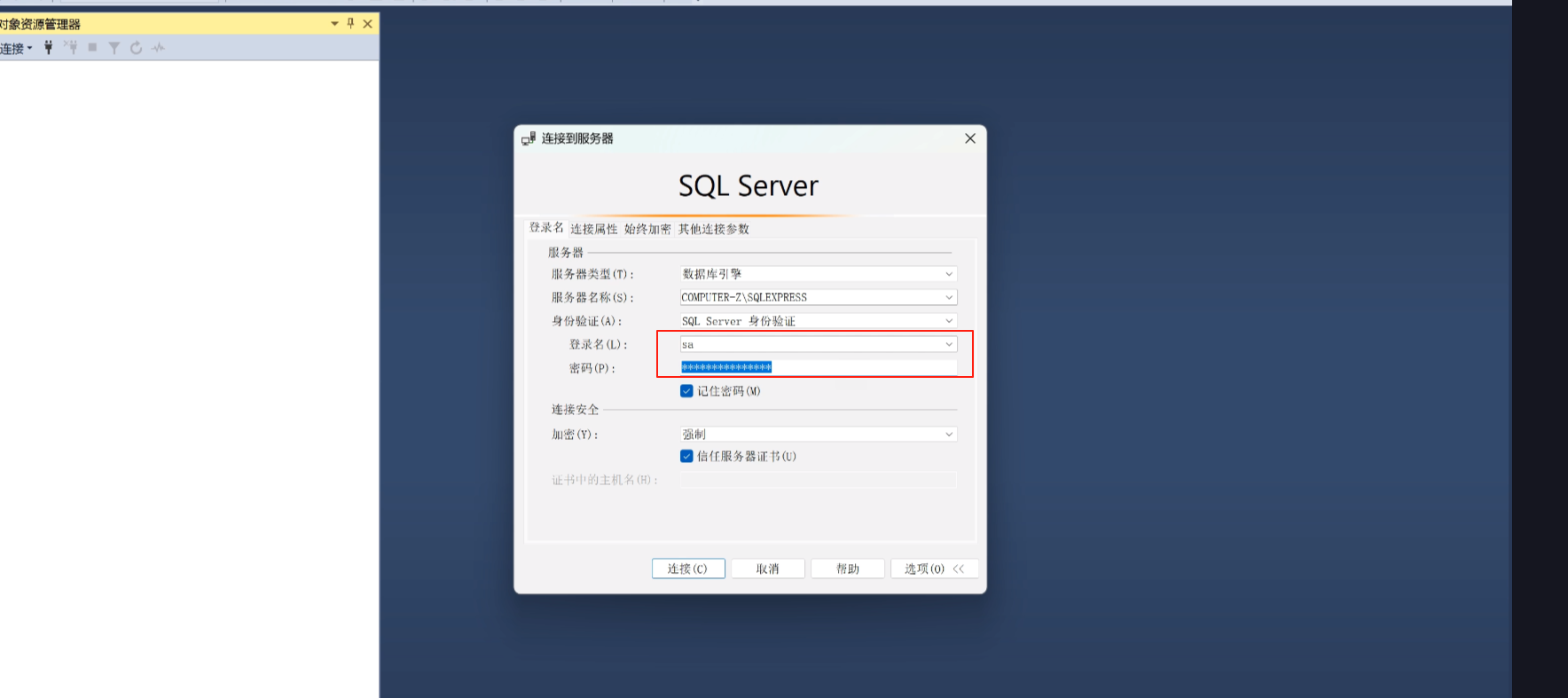
这就连上了这个数据库了
数据库里面有很多的内容,最主要的就是 表 。

一个数据库有好多表。就像Excel一样,一个Excel有很多Sheet页。

我们来看一样,鼠标右键点击表,会出现一个选项。
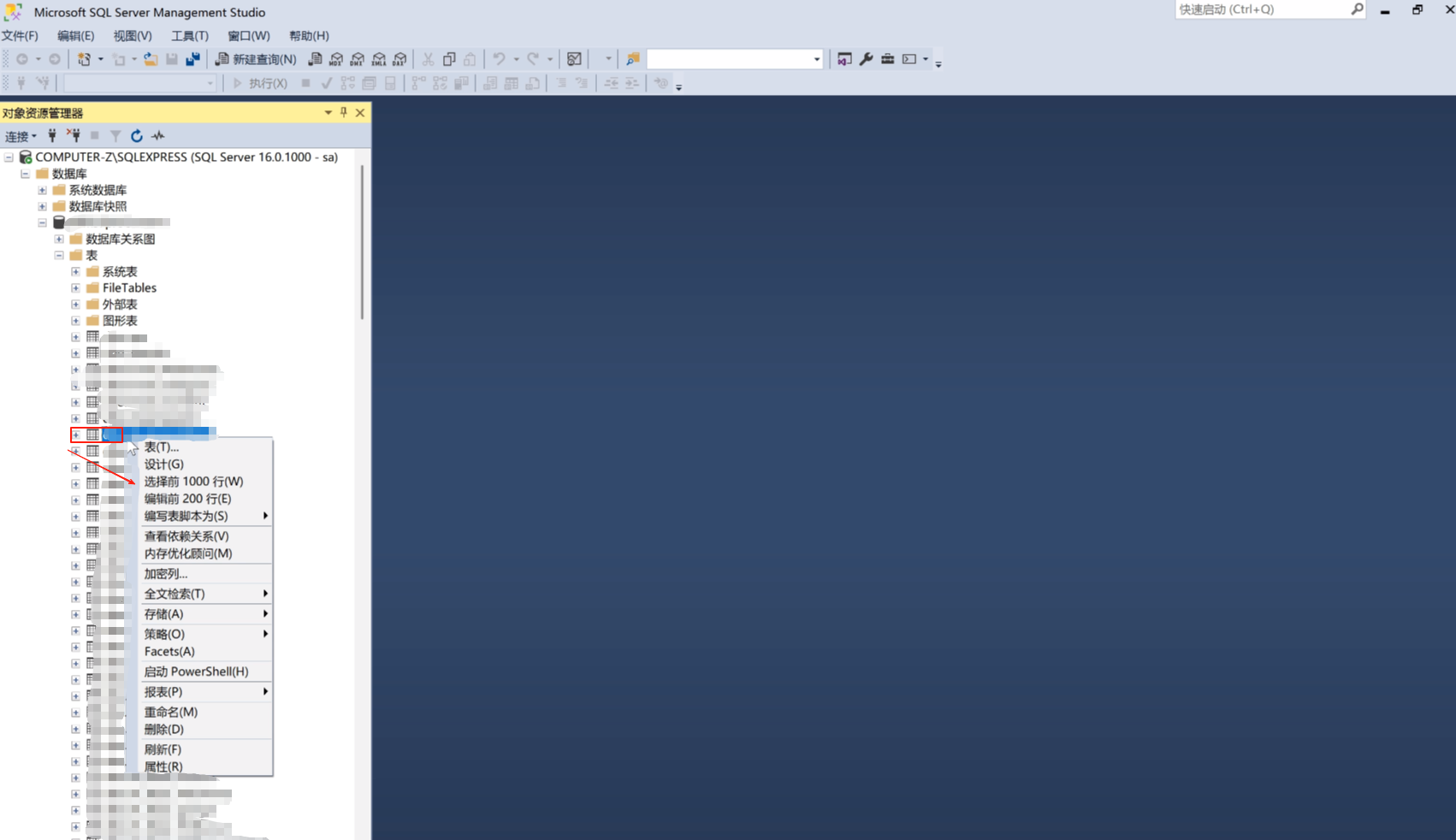
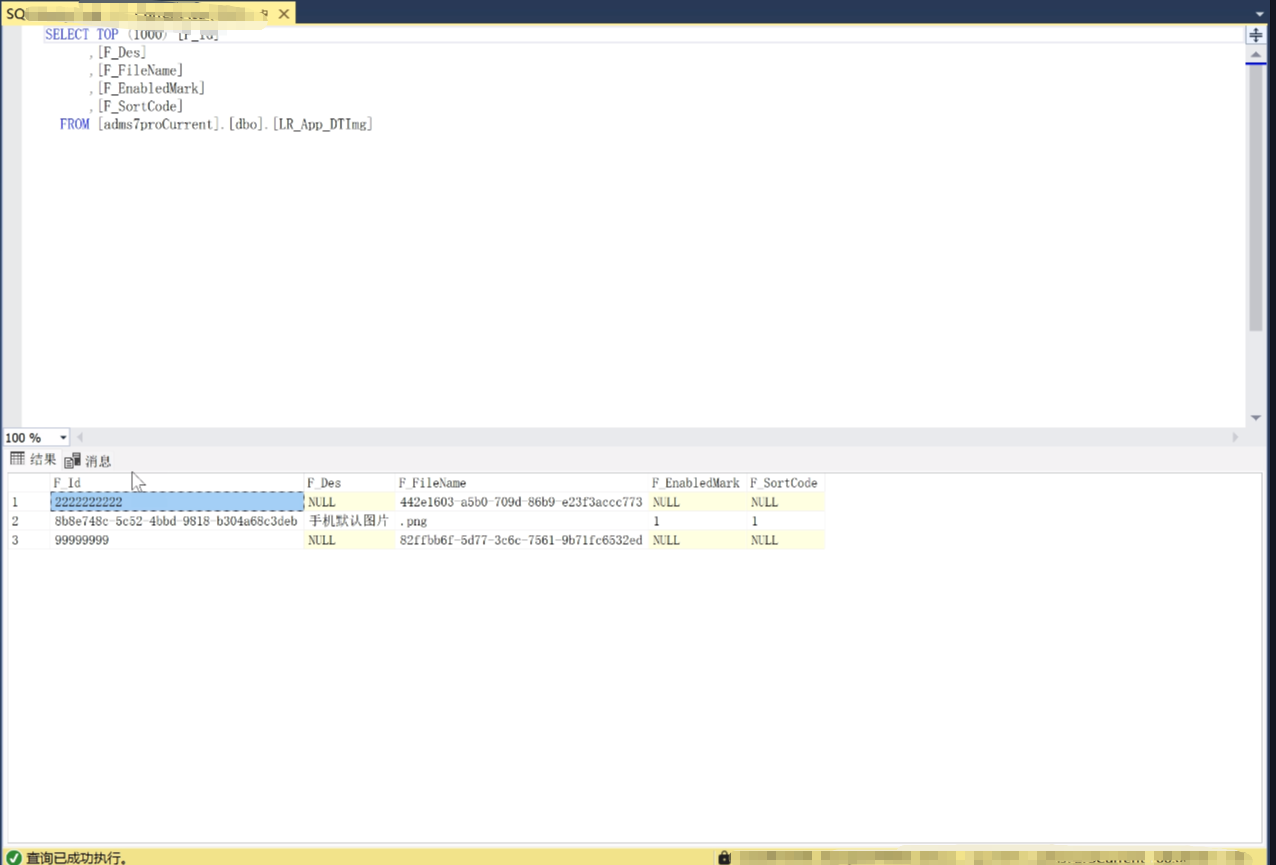
我们点击 选择前1000行 来看一下

这就是查询了,
上面是自动生成的SQL语句
下面,这跟Excel基本没区别。
现在咱们做一个测试库
鼠标右键点击数据库
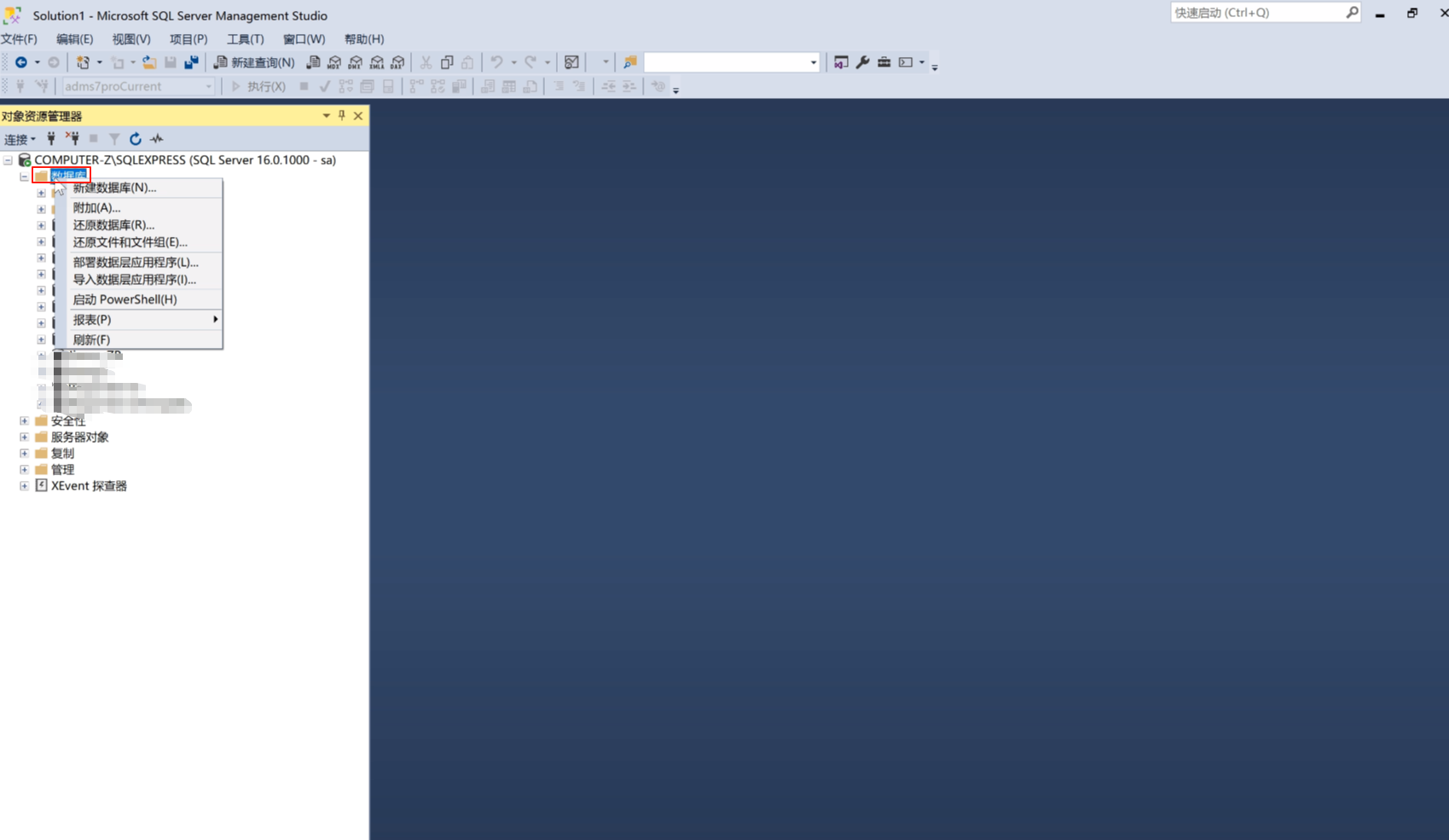
点击新建数据库,
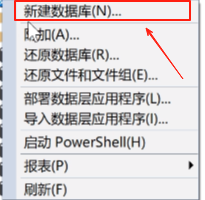
数据库名称
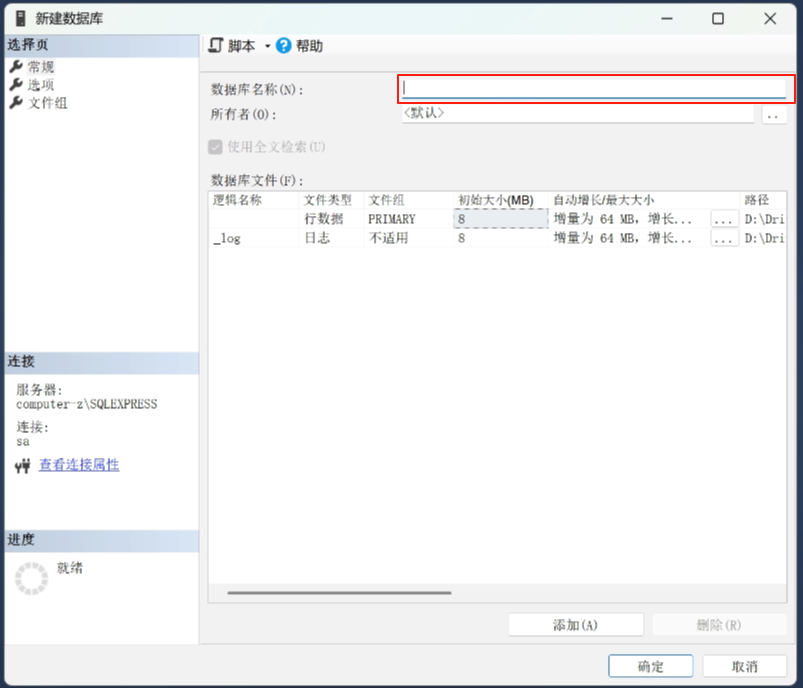
写好名称之后点击确认

这就有了数据库

这些文件都是空的,自动生成的,没东西。这就相当于文件夹,里面没有东西。
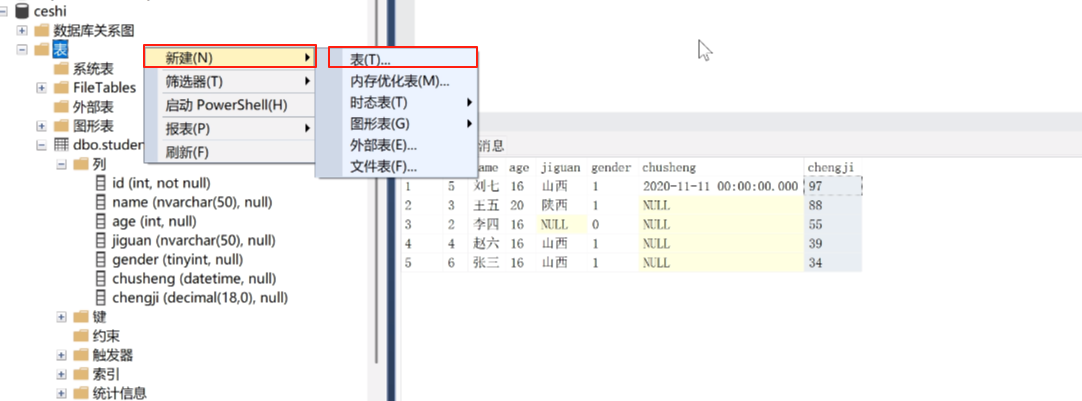
最主要是表。鼠标右键点击表,然后点击新建,点击表。
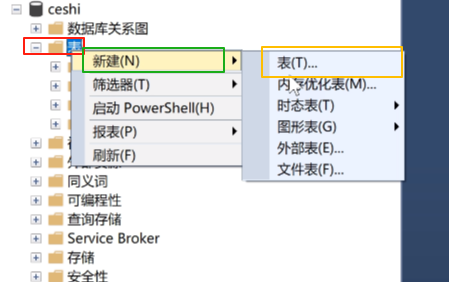
然后就出来表了
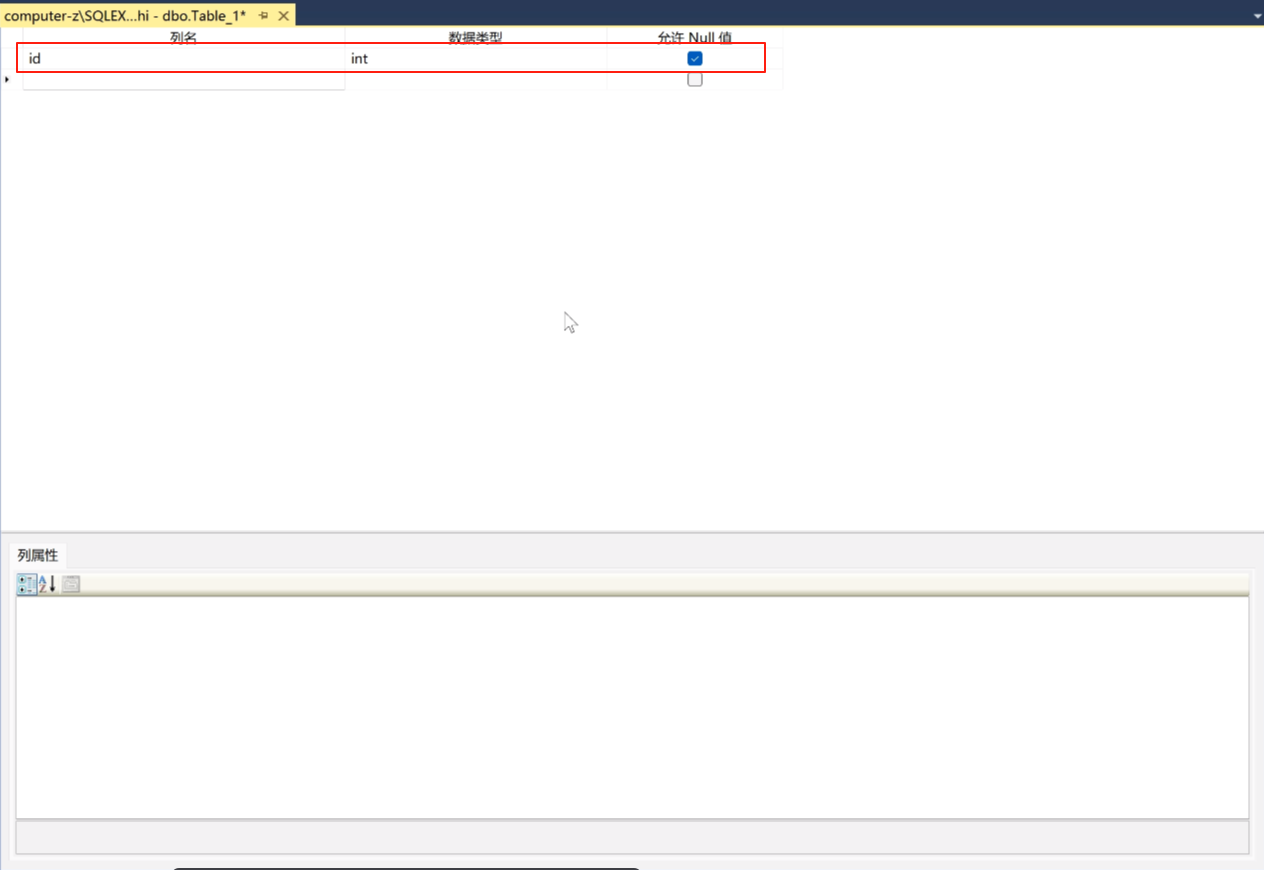
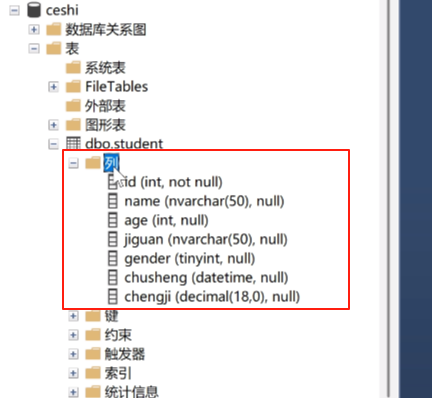
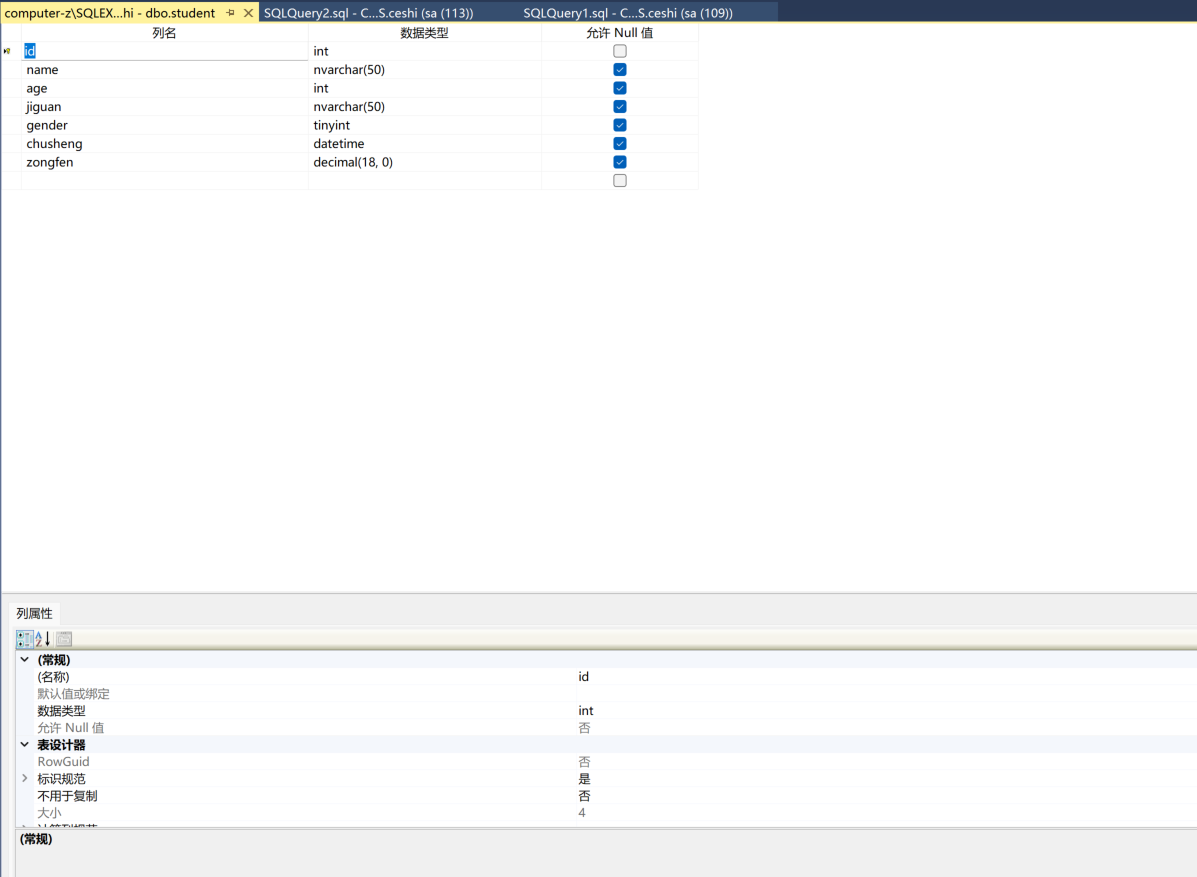
一个数据库表。一般包括,id(最主要的就是id,id必须得有)
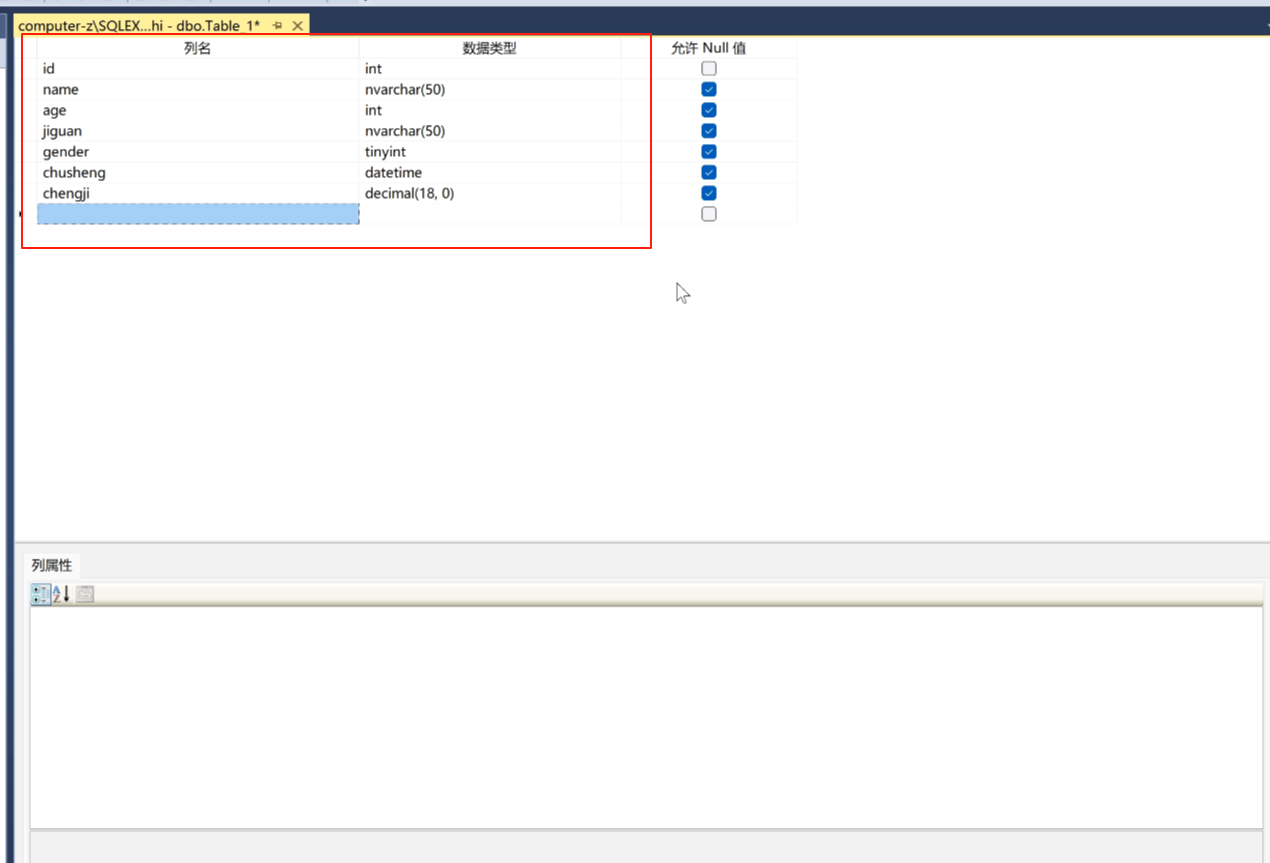
说几个常用的
float是浮点型,他也是代表小数。
decimal(18,0)精度比较强,比如用一个价格就用decimal,精度比较高的。比如经纬度。
上面这两个都可以代表小数。decimal精度高一点基本不会失真。失真就是算错了。一般都用float,除了钱用decimal。
tinyint应该就是0 1
text大字符,比如博客园标题,内容,内容存下来太长了,就用text
nvarchar只要是字符串就用这个。
datetime日期加时间,前面是日期后面是时间。
date是日期
char(10)是一个单字符的
bit是一个字节类型的

在增加一个比如名字name,名字是字符串,字符串就用nvarchar(50)
年龄age年纪是数字,用int
籍贯jiguan,籍贯也是字符串,nvarchar(50)
男女性别gender就是布尔型的了用tinyint
出生日期chusheng可以用datetime
成绩chengji是一个可以为小数点的数字,就用decimal(18,0)
然后这个允许为空,不打勾就是这个字段必须有值。
允许null值就是可以不填。如果不允许就是必须得填。
id必须得是有值的,而且还不能重复,要通过id来索引的,来查。

怎么来判断她不能重复?一般在程序里面判断。
数据库里面的这个id可以这样
点这一行
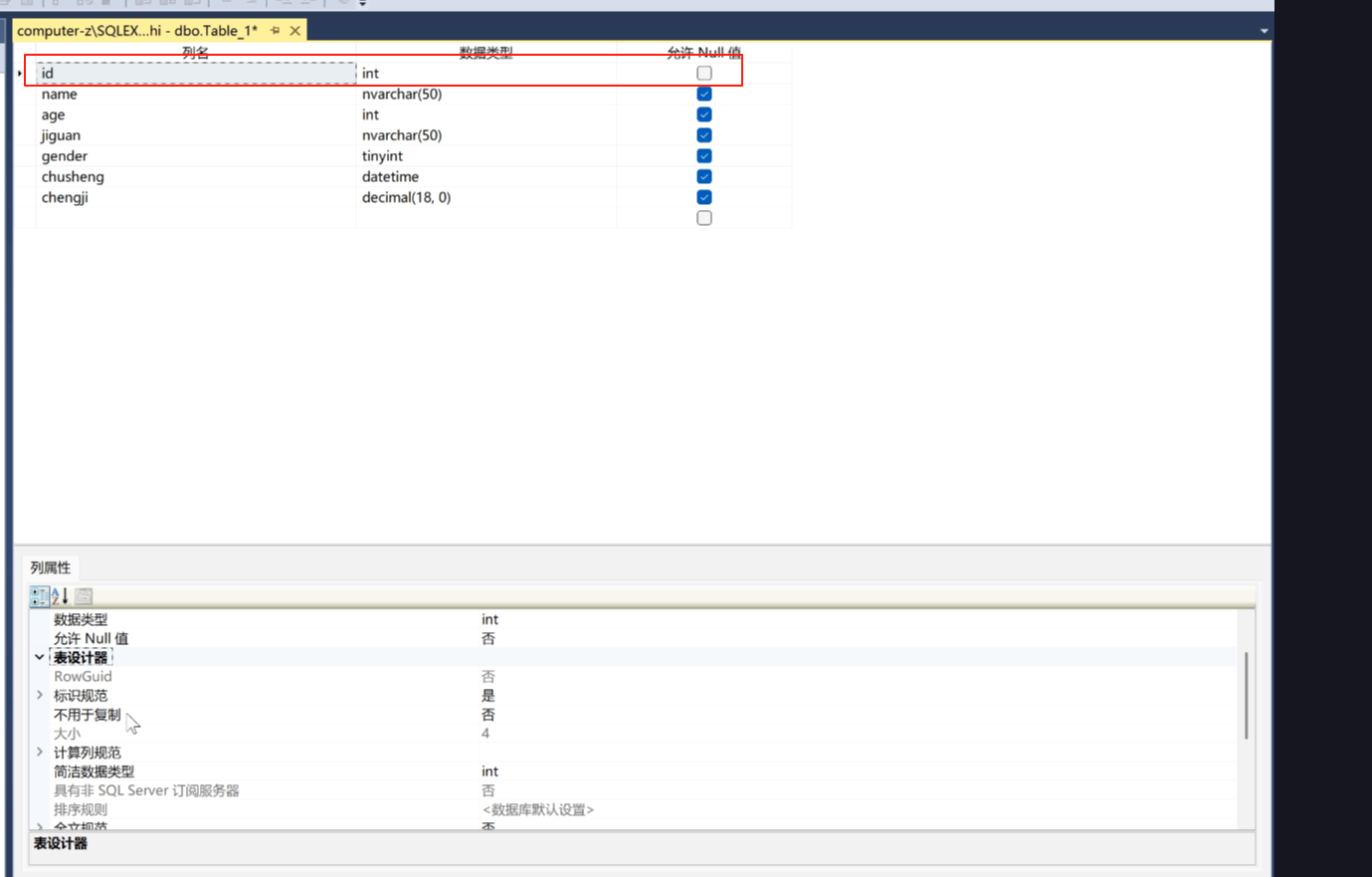
点表设计器
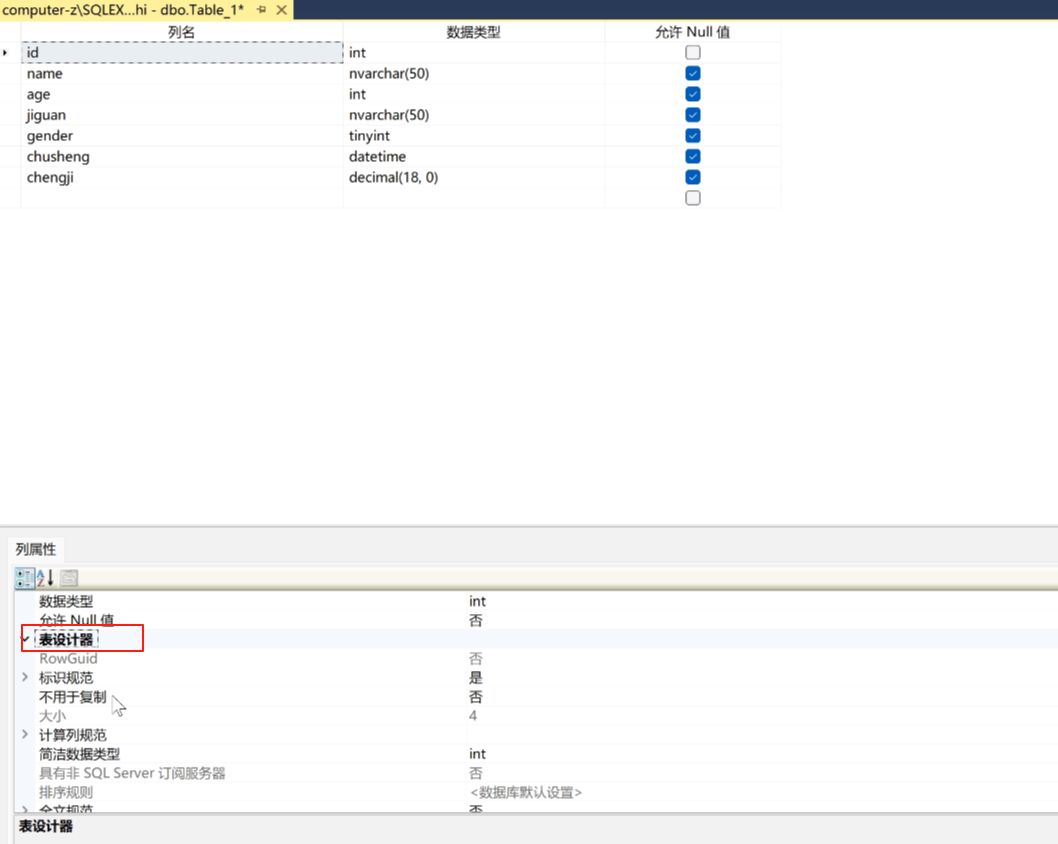
点表示规范
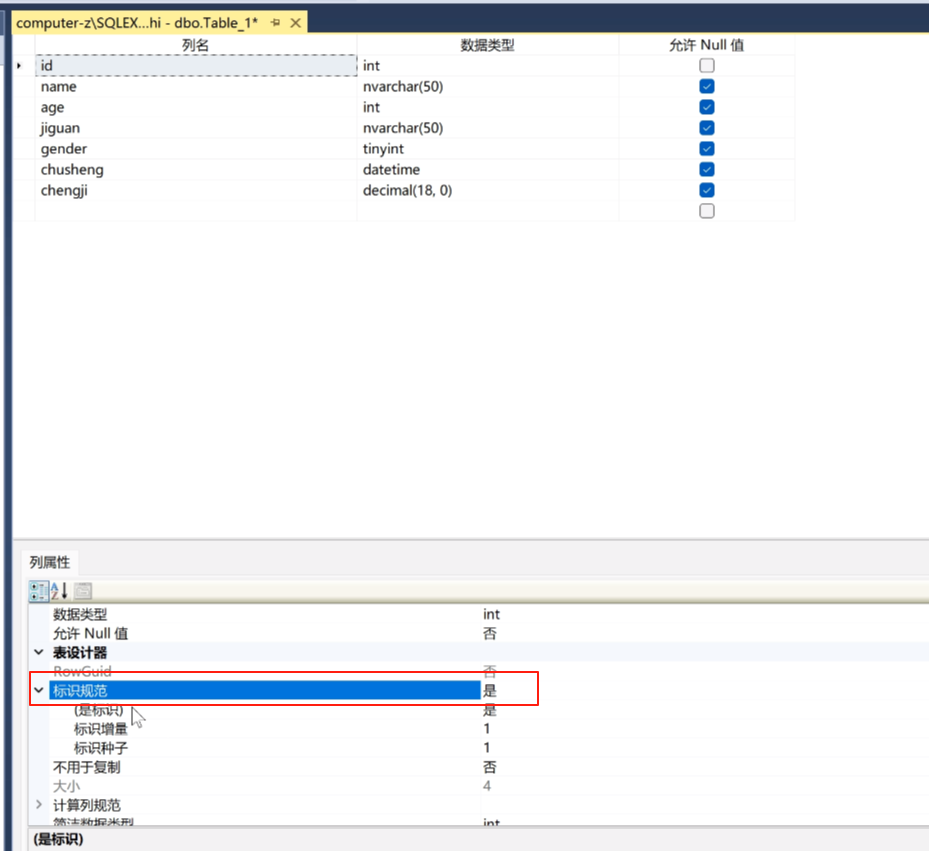
让她自动生成。点击标识规范,标识增量1,标识种子1。
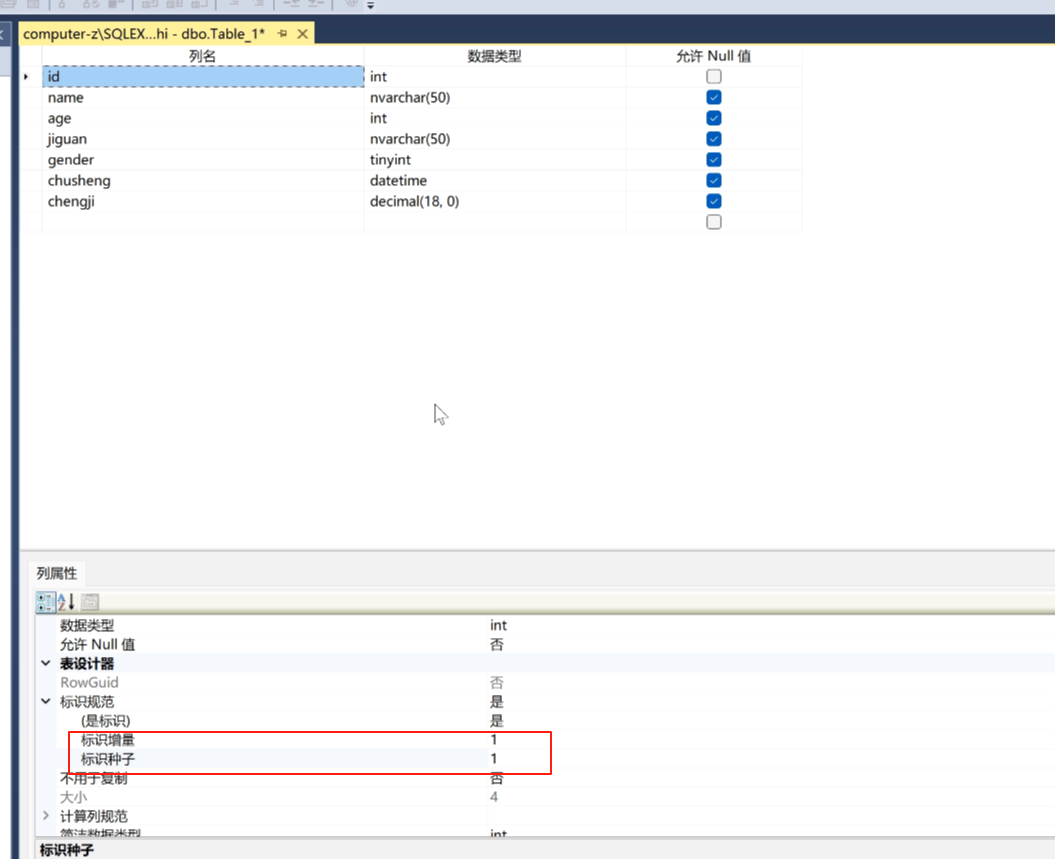
这里的表示种子双击这里。可以改变是否。
然后保存
输入名字点确认
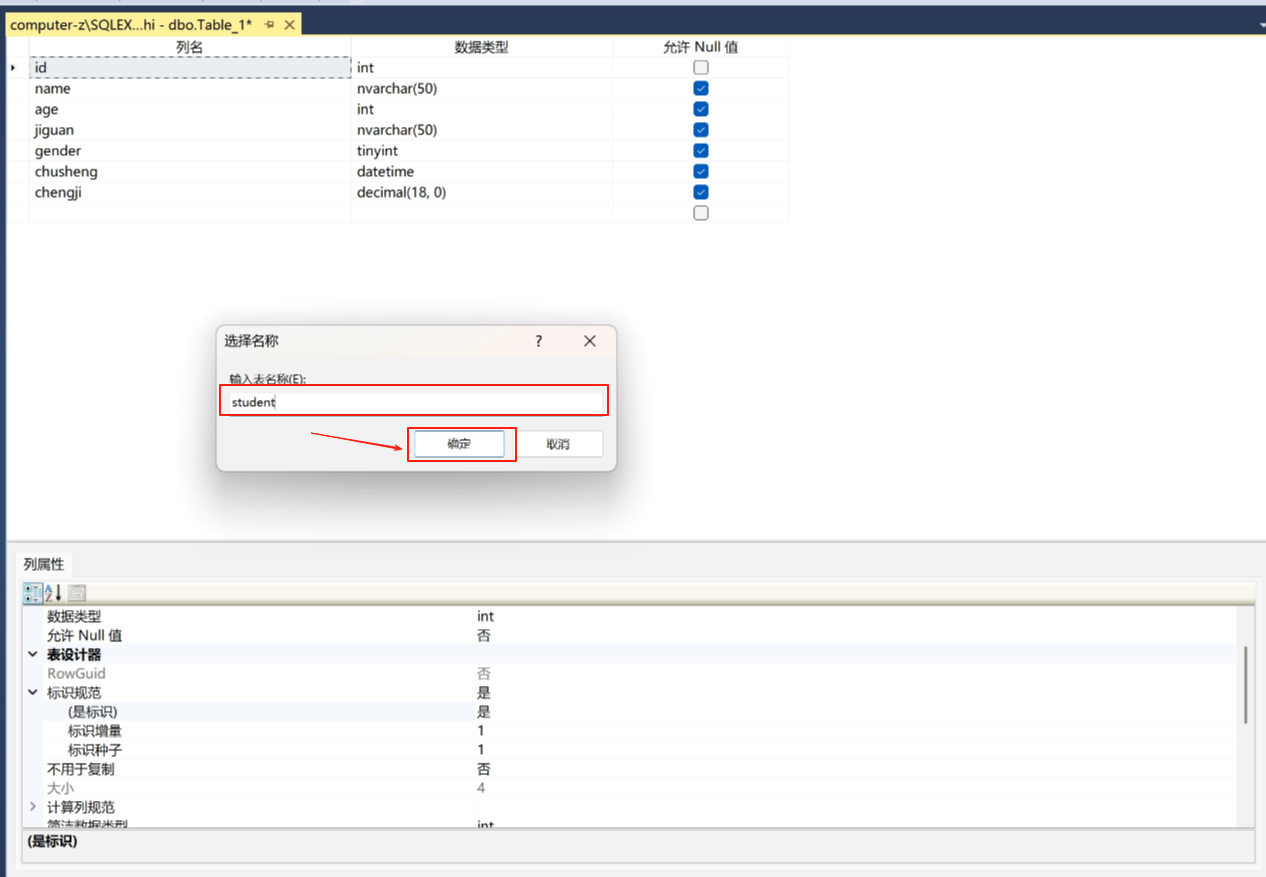
这样一张表就建好了。
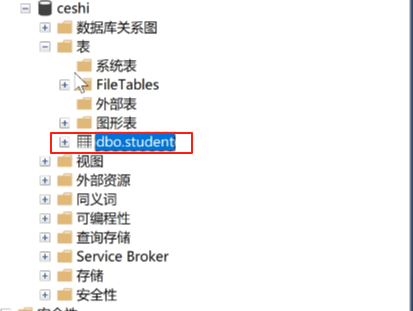
他有这些东西
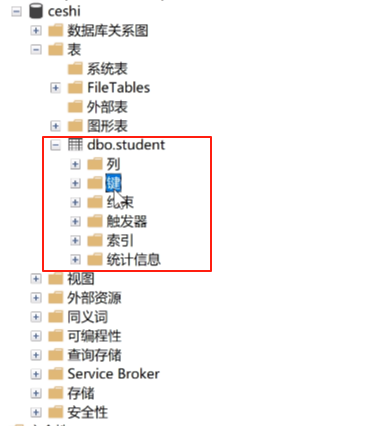
这些都不用管,主要看列。这个表有这么多列。
鼠标右键点击表,点 设计
又可以打开这个页面了,可以改。
右键,选择前1000行
你就可以把这个想象成一个Excel。这里一行都没有数据。
右键,编辑前200行
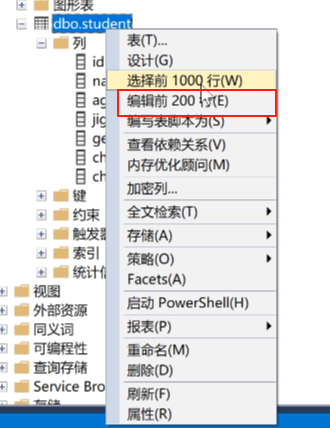
可以在这里编辑数据了,这里的id就自己出来了。
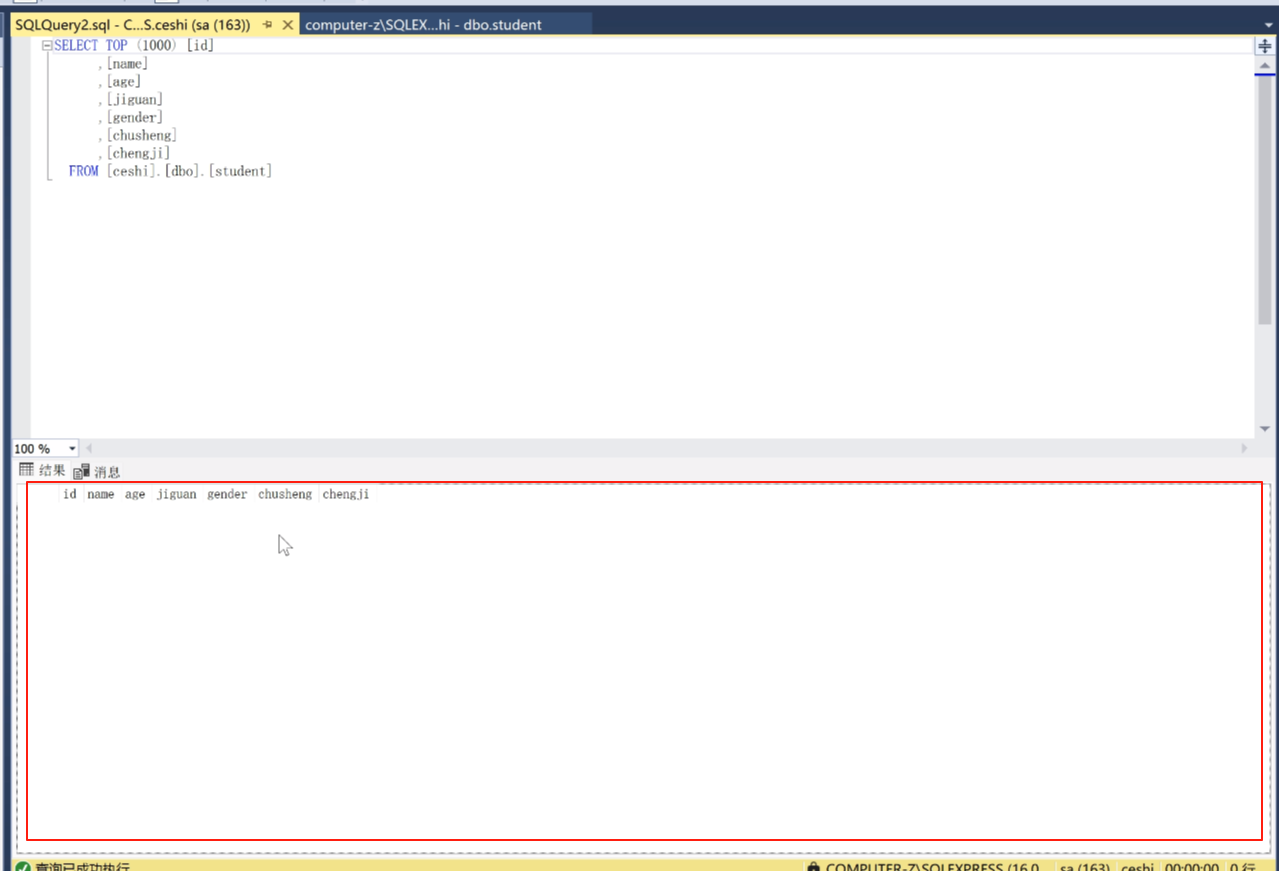
然后看这里,编写脚本为(s),CREATE到(c),新查询编辑器窗口
就是这个,生成sql语句了。
这是创建表,创建表的语句就是这个。
就是刚才是点击鼠标右键创建。我们现在也可以写这个创建,用这个语句。
关闭所有的表之后,点击新建查询。
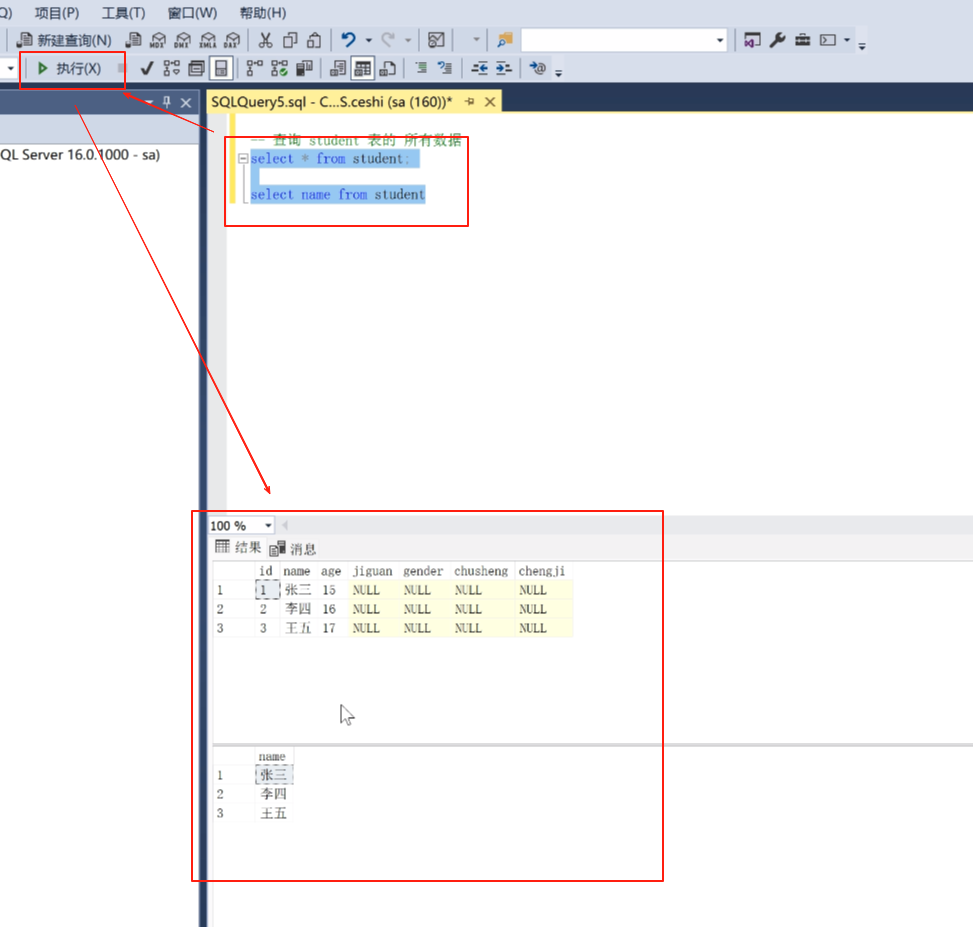
我们现在查询student表的所有数据。
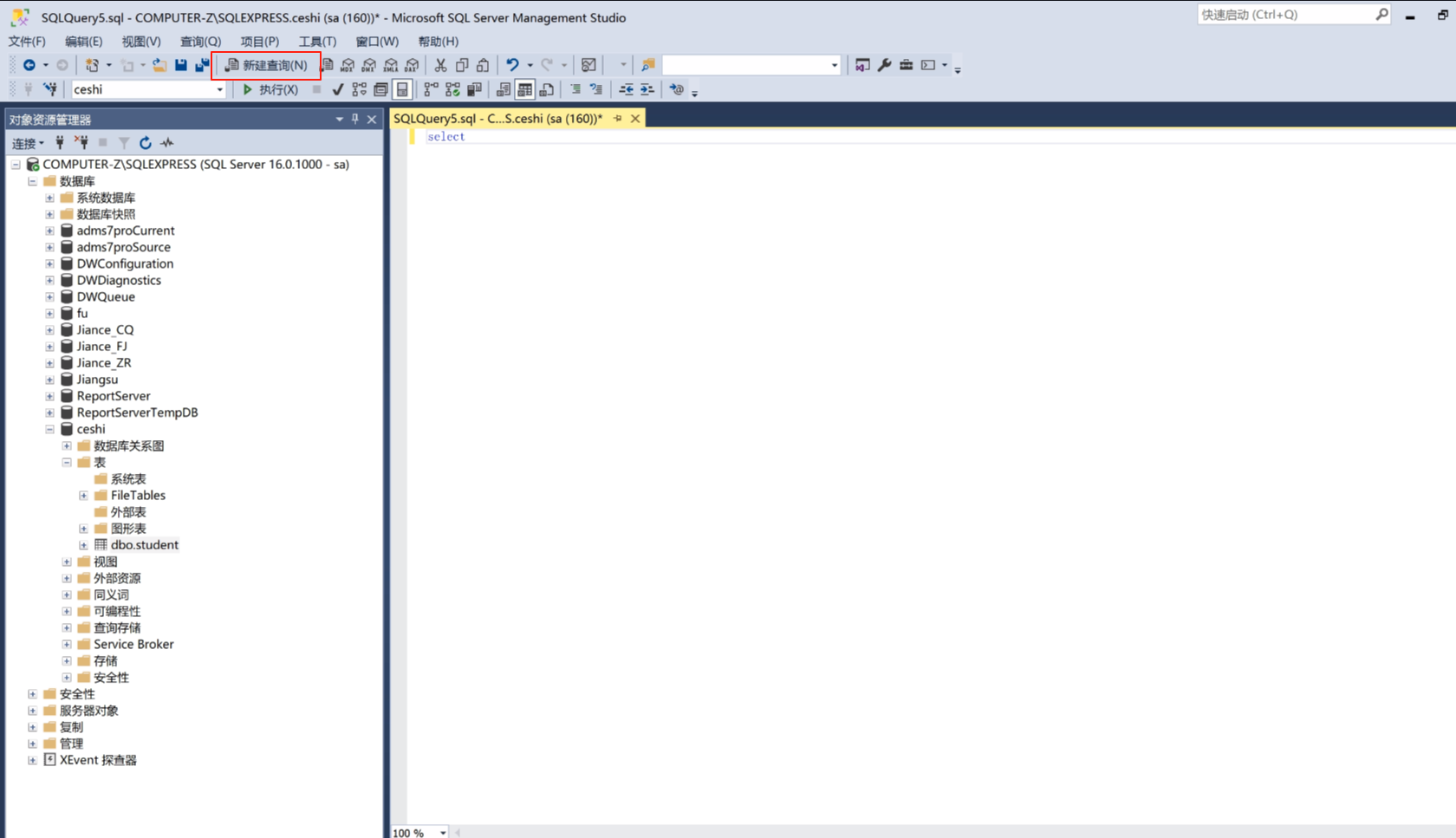
关键词是sclcct , *代表所有的字段,from从哪,从这个表里面student。
写好了之后点击执行,就可以看到查询结果了。
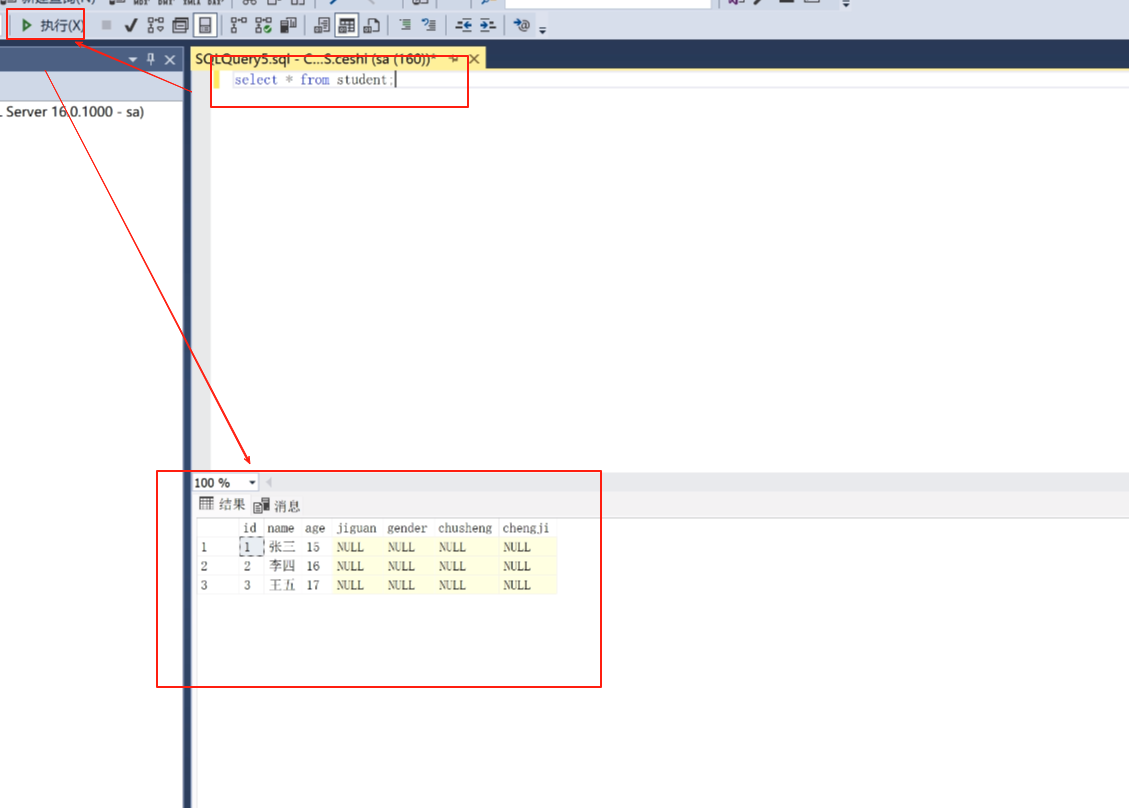
查询student表的name列
然后我如果只想查name这一行
select name from student ;
写上之后选中然后点击执行。
这里多行可以选中一起点执行,这里每一行之间一定要加上 ;
可以看到效果
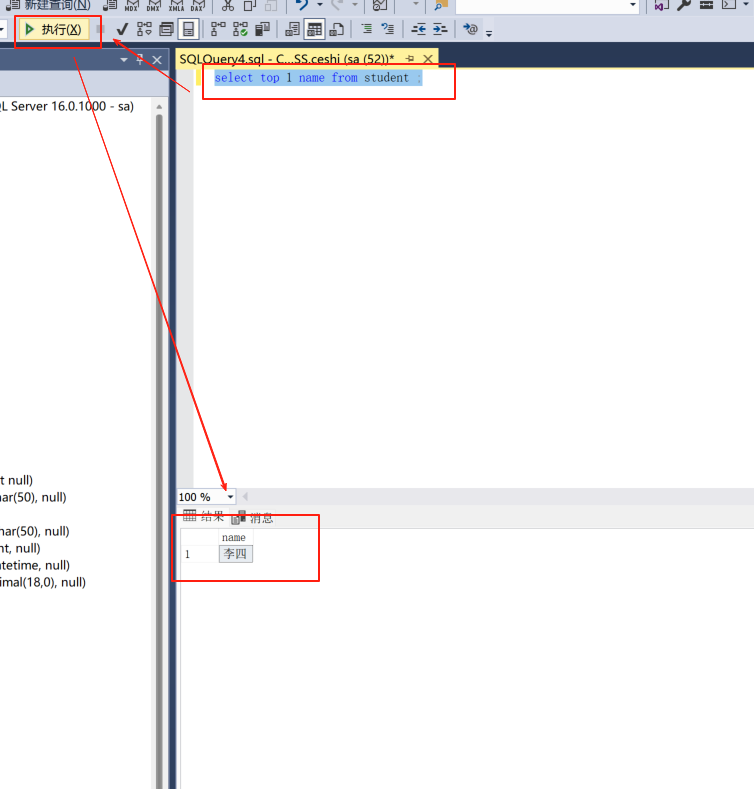
我只查询第一行人的名字。
select top 1 name from student ;
top 最上面,从顶部。1代表查1个。
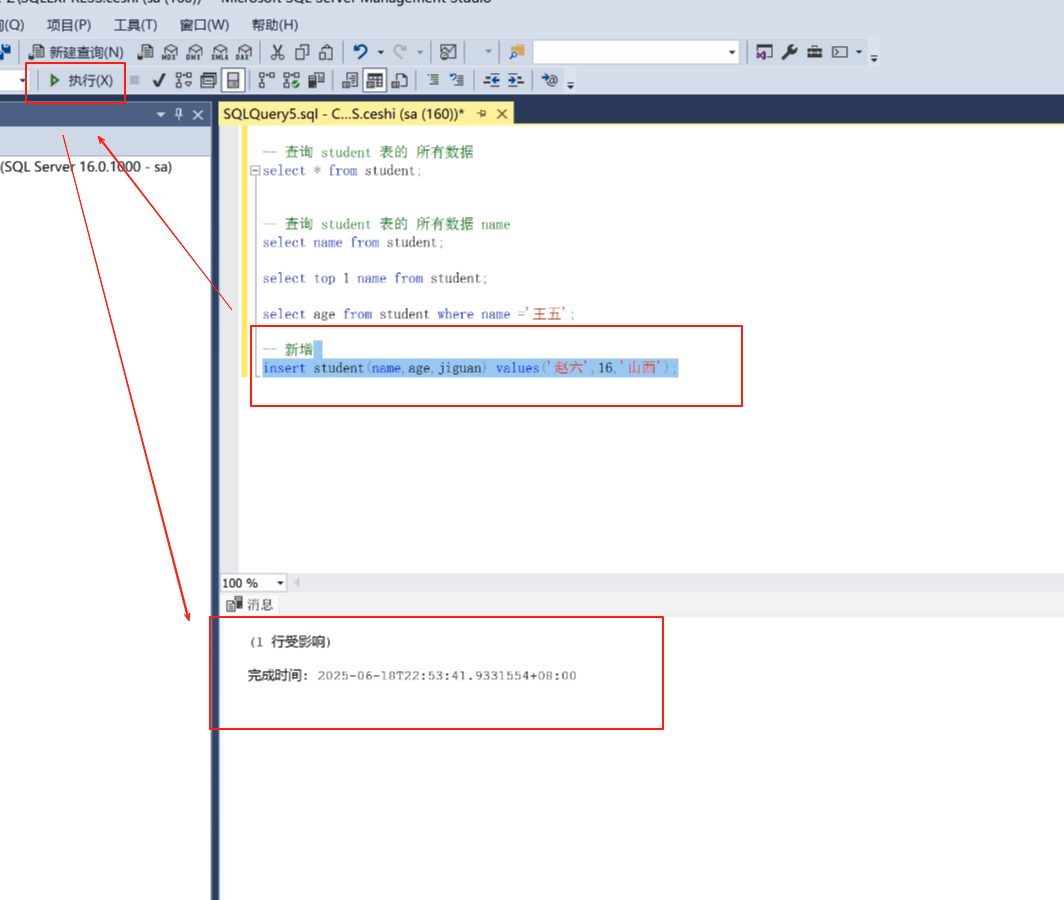
我想知道王五的年龄
select age from student where name=‘王五’;
where 代表条件。

insert 就是新增
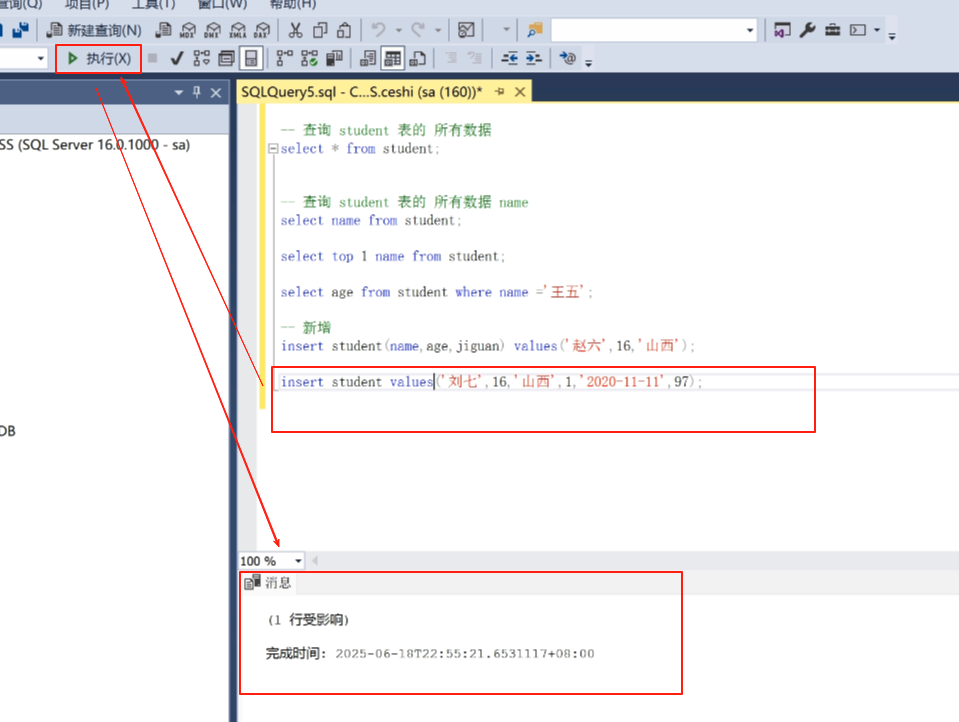
insert student (name,age,jiguan)values(‘赵六’,‘16’,‘山西’);
写完,选中点击执行,也可以选中点击F5快捷执行。![]()
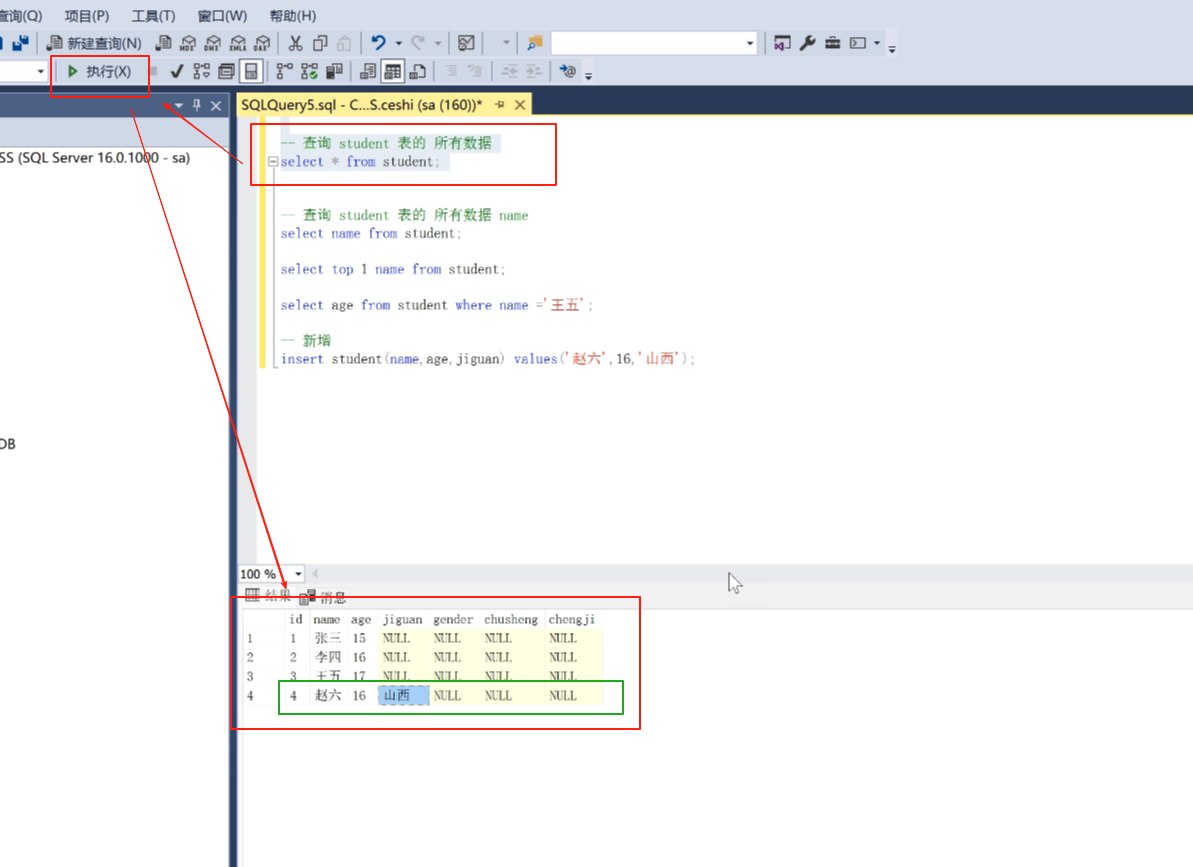
新增完成之后我们点击一下查询看看效果
可以看到赵六增加上来了。
还有一种是不写列的名字,把所有列的值都写上去。
注意出生年月必须用 - 链接 ,因为之前设置的格式,没写时间会默认给一个时间。
修改
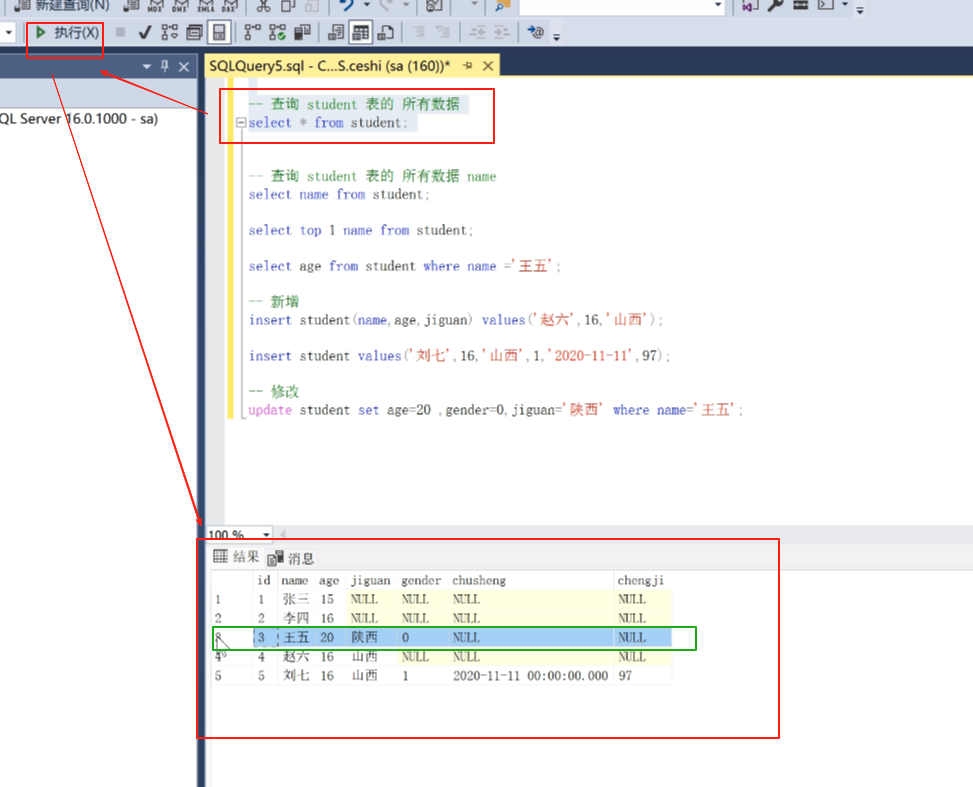
假如王五写的不全
update student set age=20,gender=0,jiguan=‘陕西’ where name=‘王五’ ;
update 一定要注意家where条件,要不然就会把所有的都改掉。而且没有返回,执行就是执行了。所以很危险,这里一定要注意。
一般我们都用id改,这里就先用名字来改了。
注意这里的规则:0代表女的,1代表男的。 1代表是,0代表否。
update 修改。
set 设置。

然后我们在查询一下,可以看到,改好了。
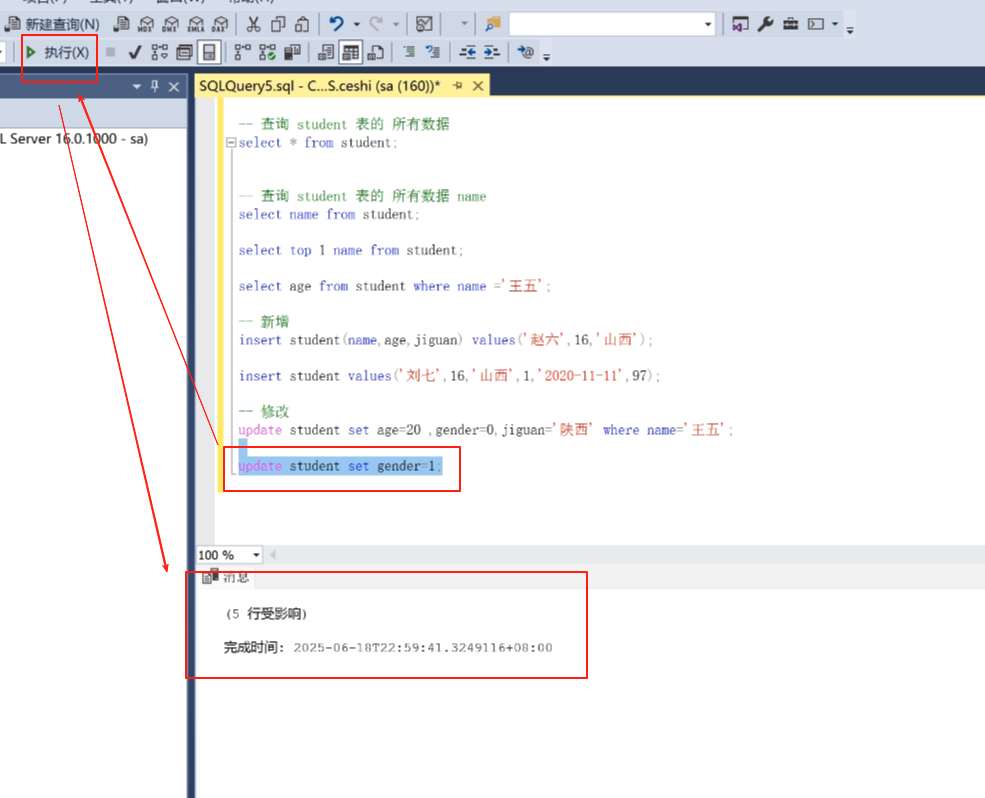
现在我们继续在改一下,
假如现在这个表全是女的,就有一个是男的。
update student set gender=1;
就这样没有加where条件,全改了。
然后我们再来查询一下
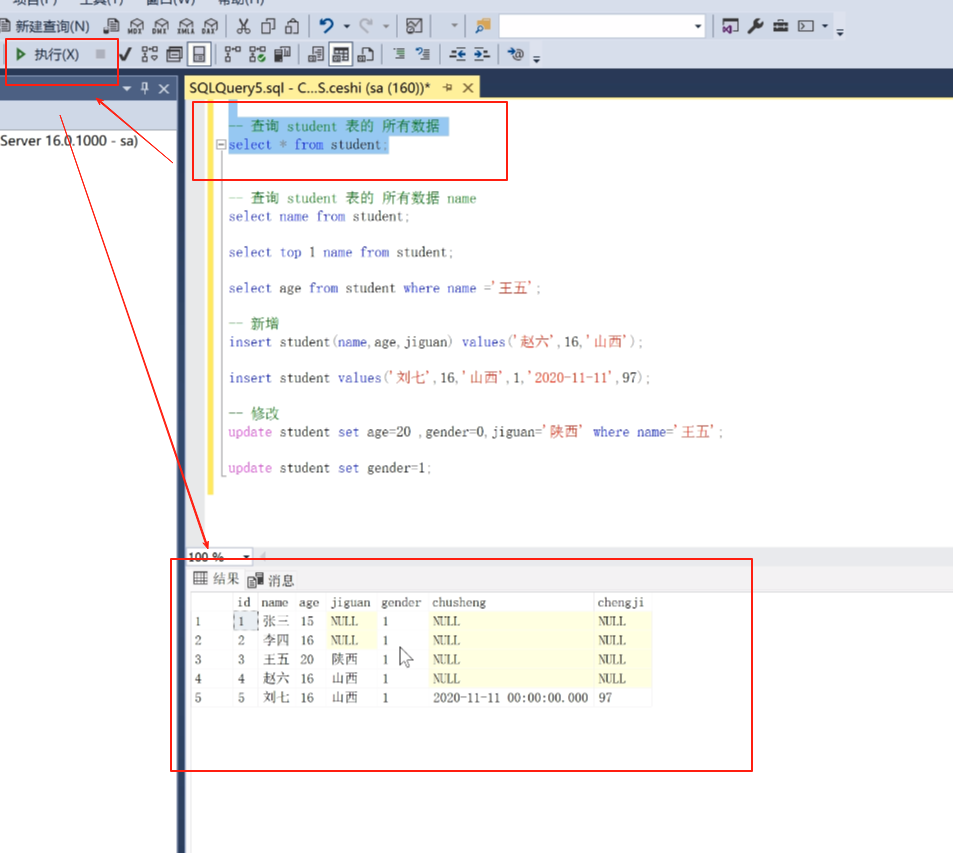
然后在单独的把那个男生改一下
假如李四就是那个男生。
update student set gender=0 where name ='李四' ;
写完之后点击执行。
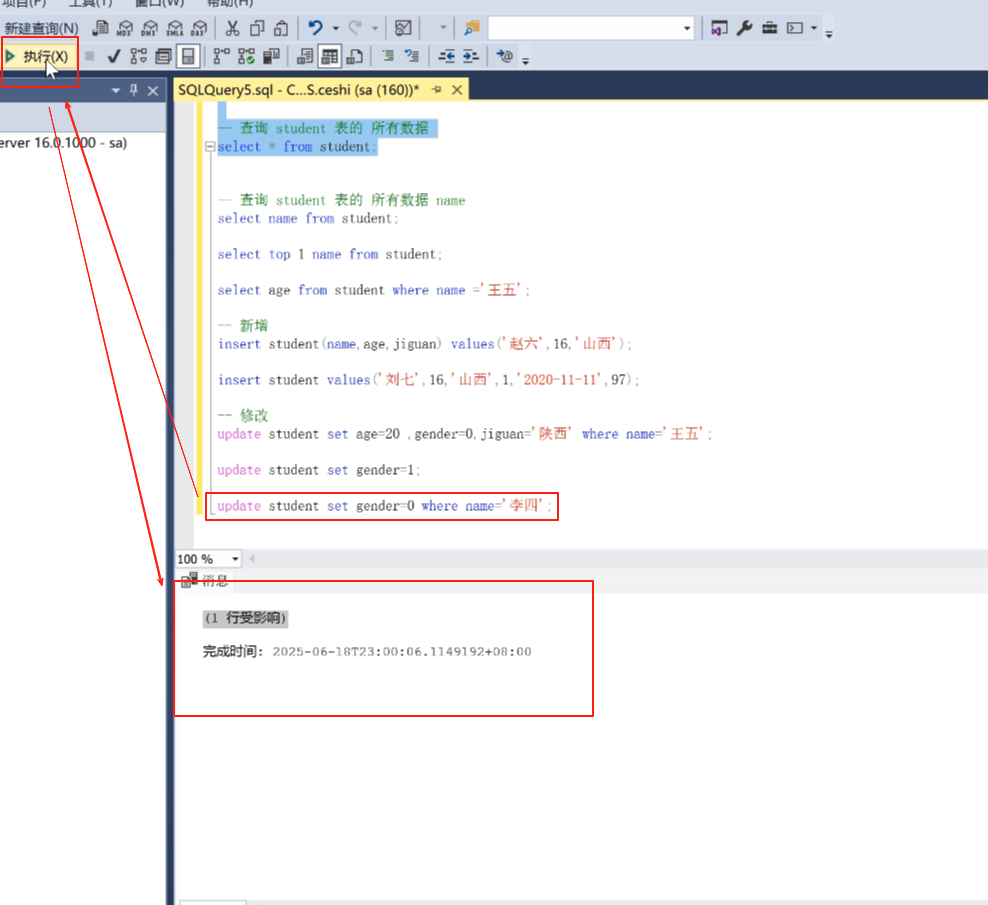
然后点击查询可以看到改好了。

删除,删除这个表里面的张三。
delete student where name =‘张三’;
写完之后,执行。
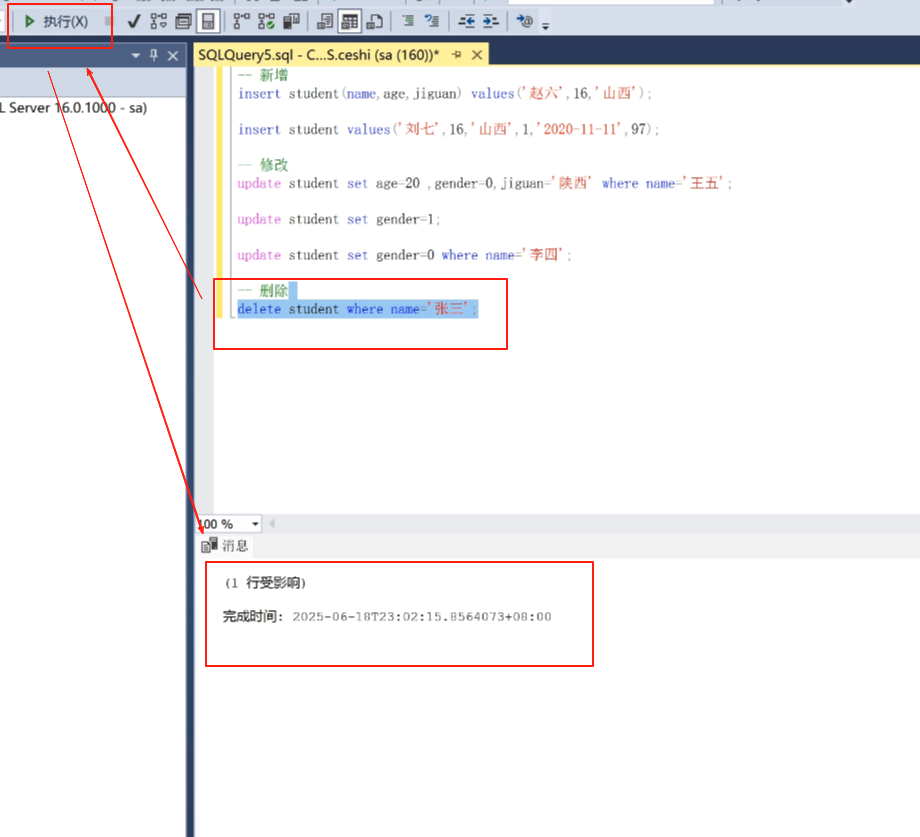
查询一下所有的,张三这行就没有了。而且没有恢复,再来就是新人了。
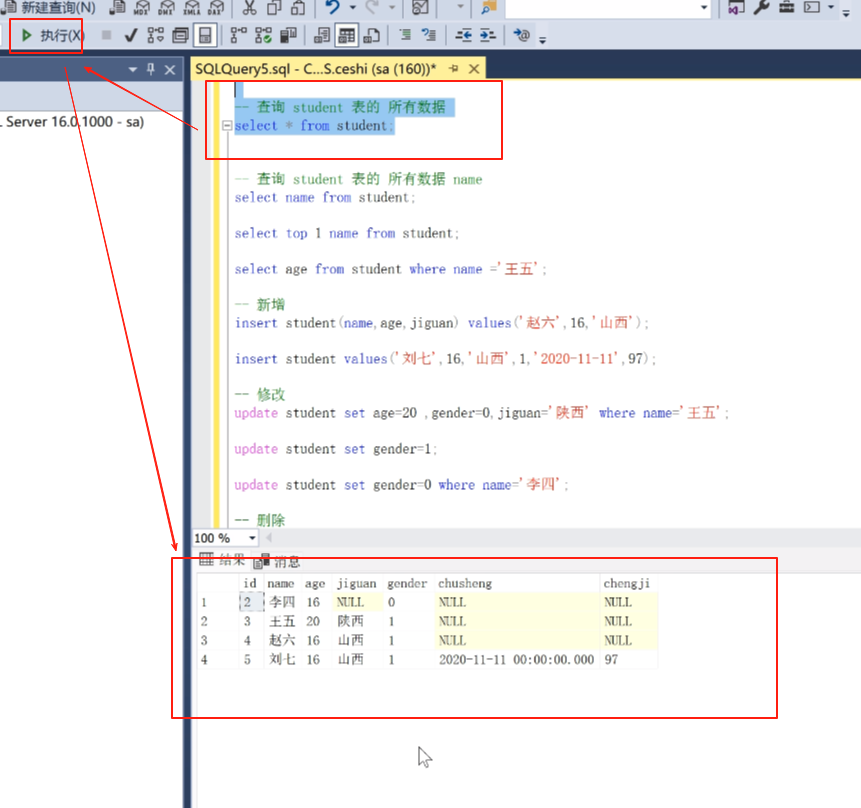
在来的时候也可以指定她的id
insert student (id,name,age,jiguan)values (1,‘张三’,‘16’,‘山西’);
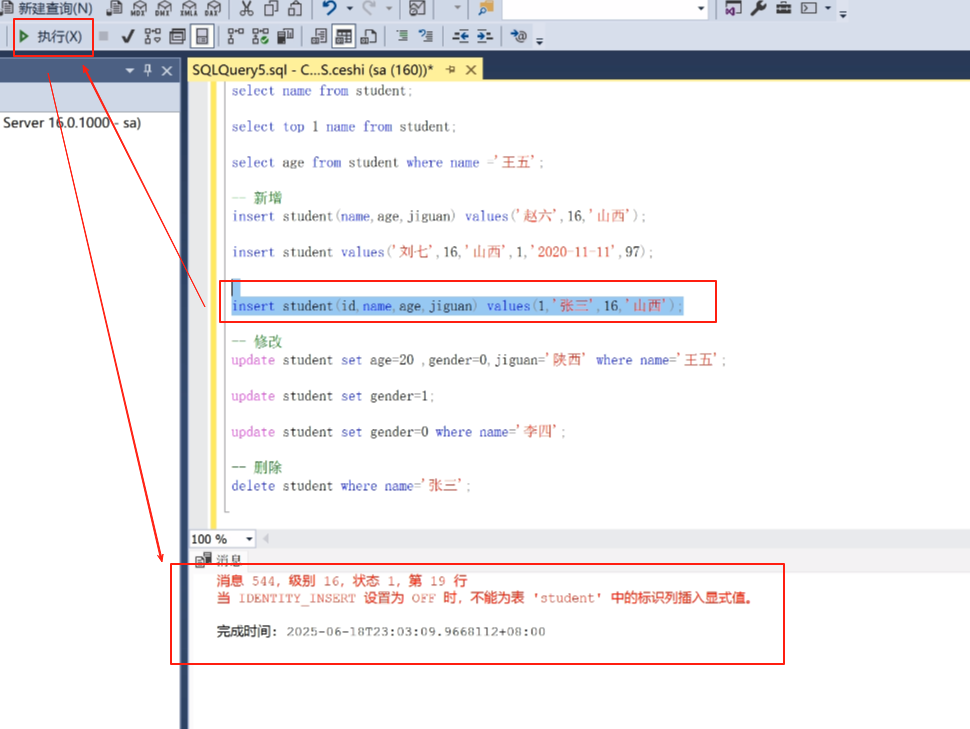
可以看到这里有问题,我们后面可以进行调整一下,这里先不说了。
如果直接新增这个张三可以看到,id是6了。
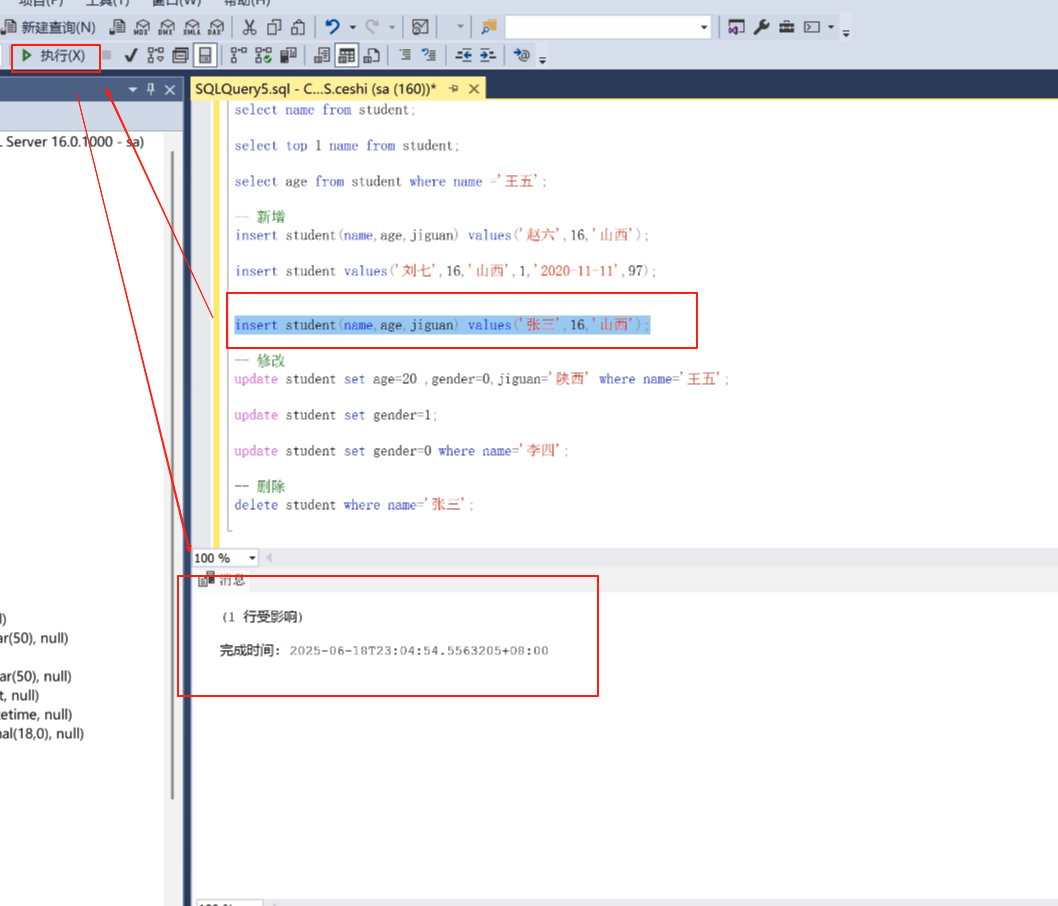
查询一下
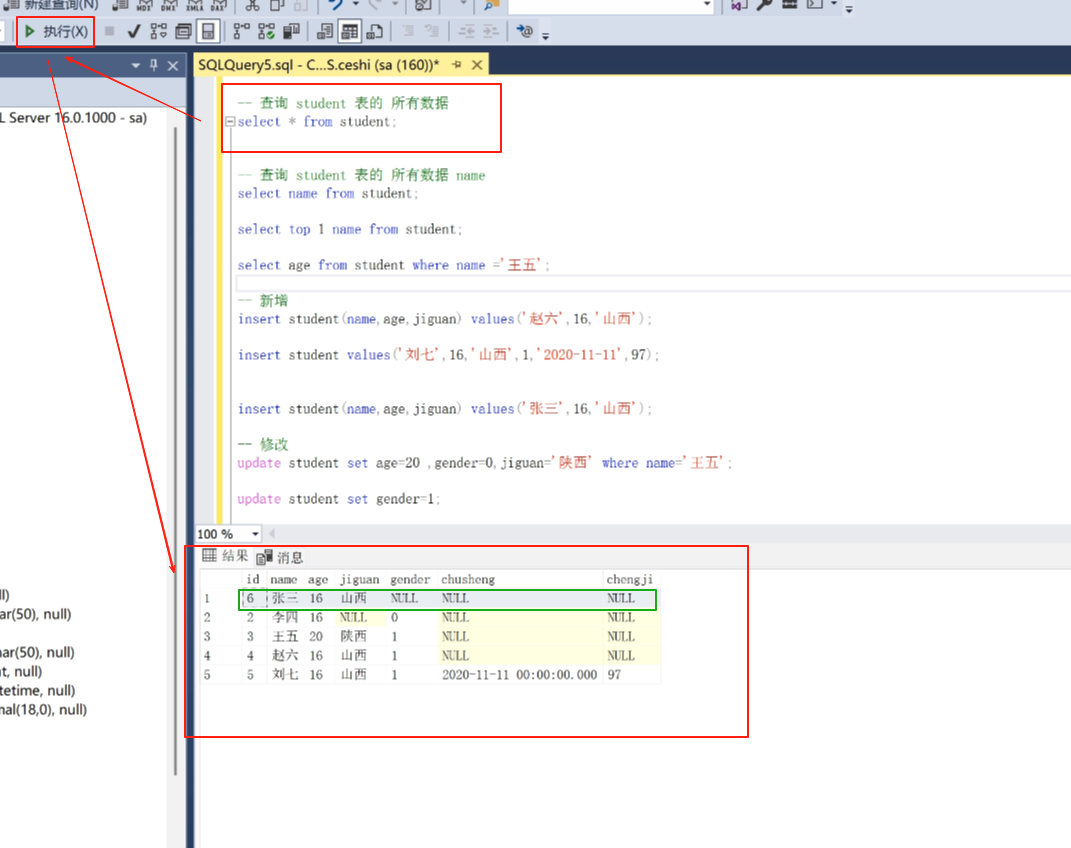
这里我想让他按id排序
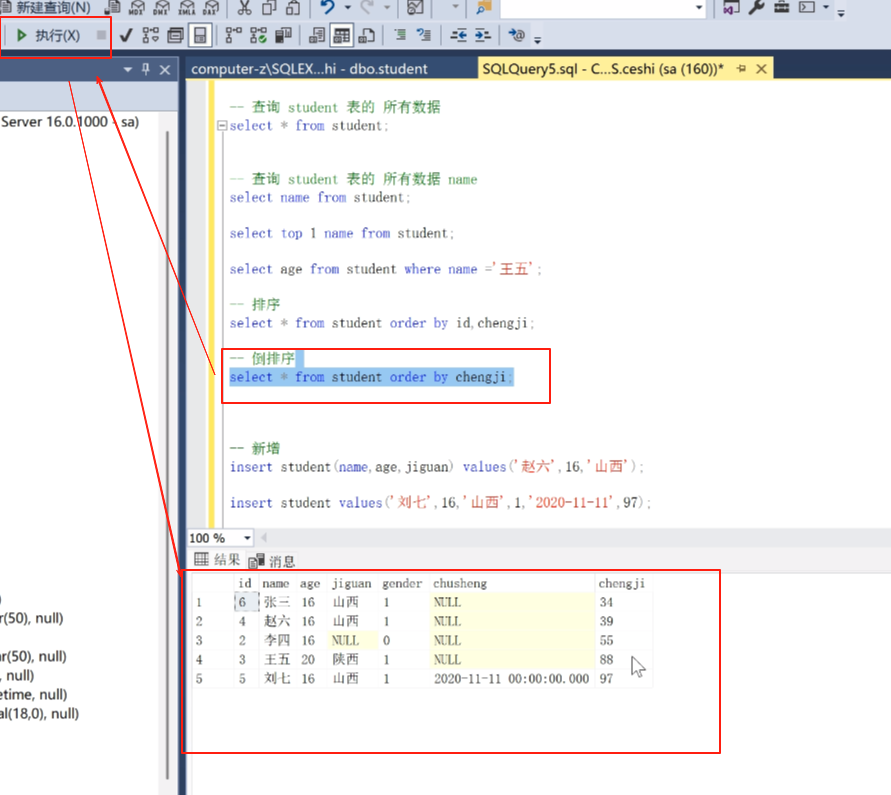
select * from student order by id ;
order by 排序。
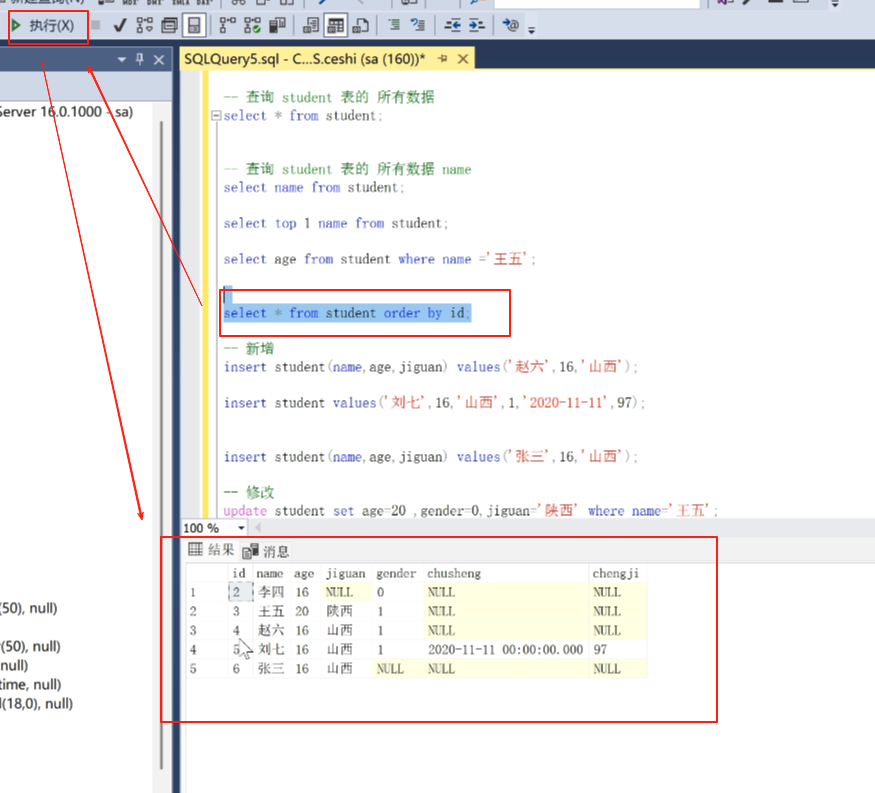
假如我们有两个叫张三的,
那如果我们让他先按id排序,再按成绩排序就可以:
select * from student order by id,chengji ;
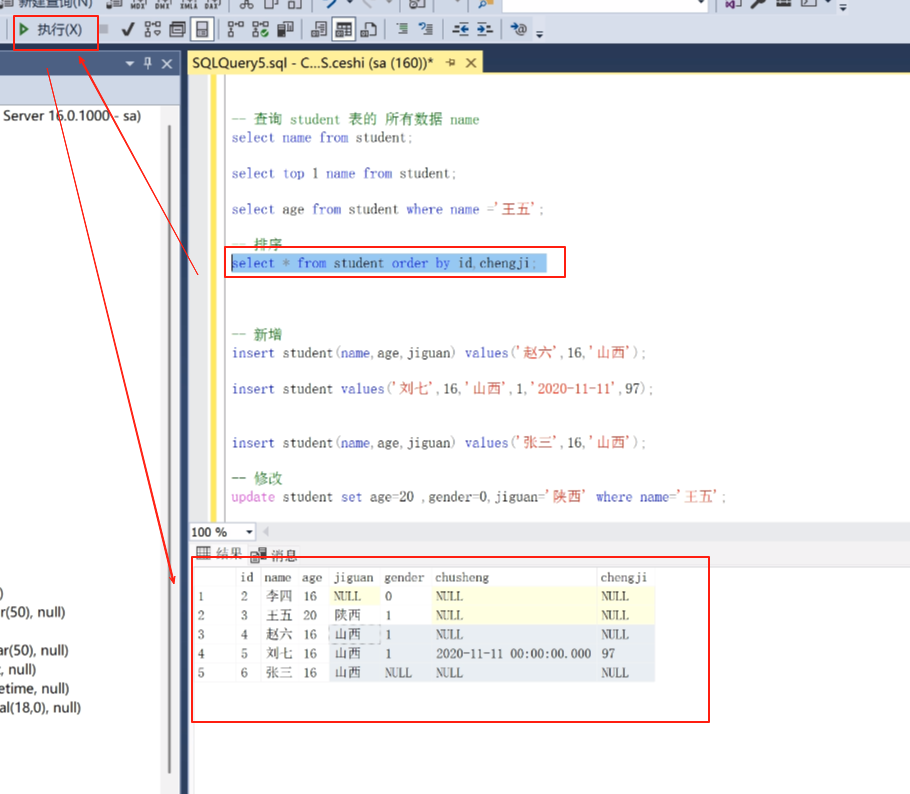
我们现在完善下这个表里面的成绩。这里写完之后按↑或者↓的箭头换一行就可以保存了。

或者点这个就可以保存了
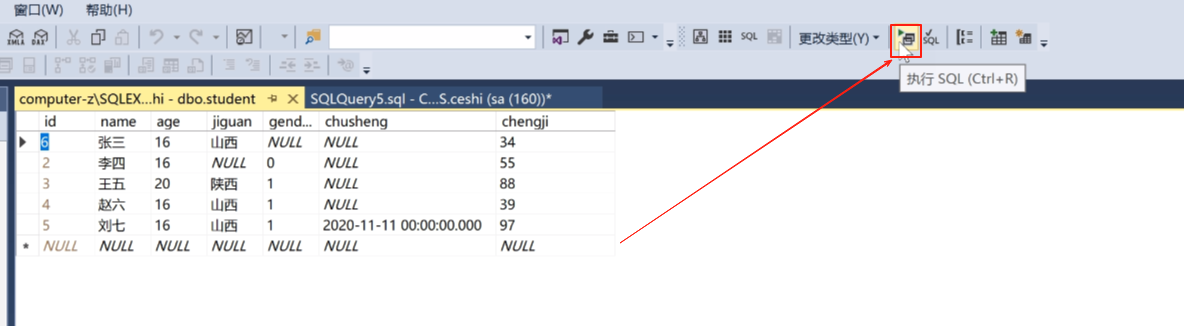
那如果要按成绩倒排序就这样写
select * from student order by chengji desc ;
desc 倒排序。
写完之后点击执行。
这时候我们扩展一下,新建一个各个学科分数表。
这里必须要有id int
这里我们加一个学科 xueke navarchar(50)
加一个总分 fenshu decimal(18,0)
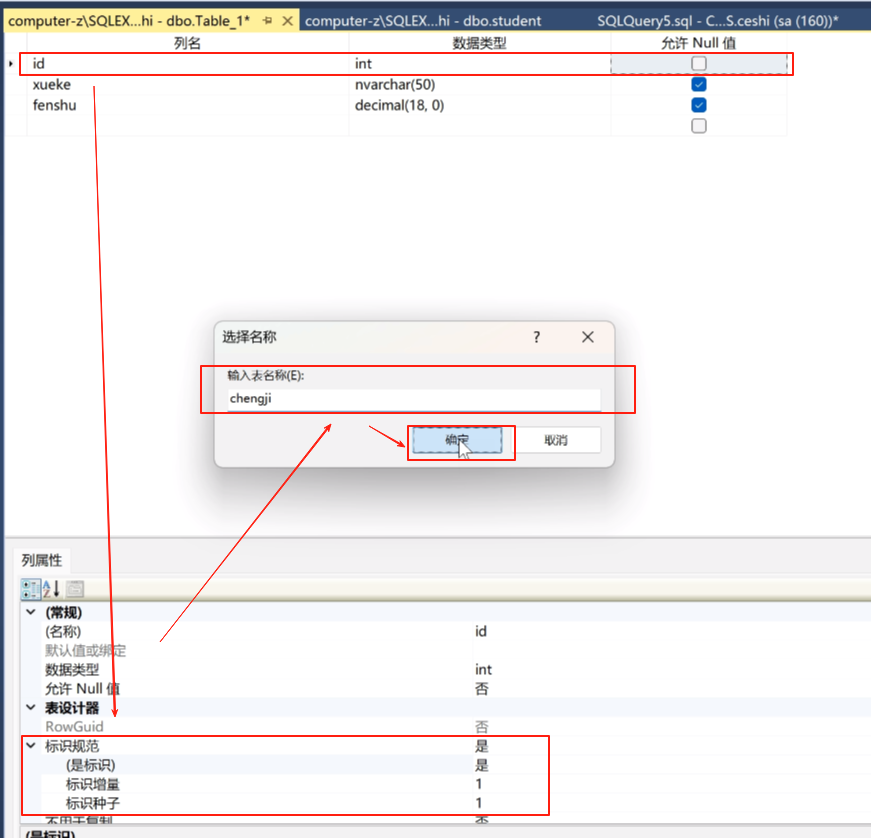
再加一个student int
会报错
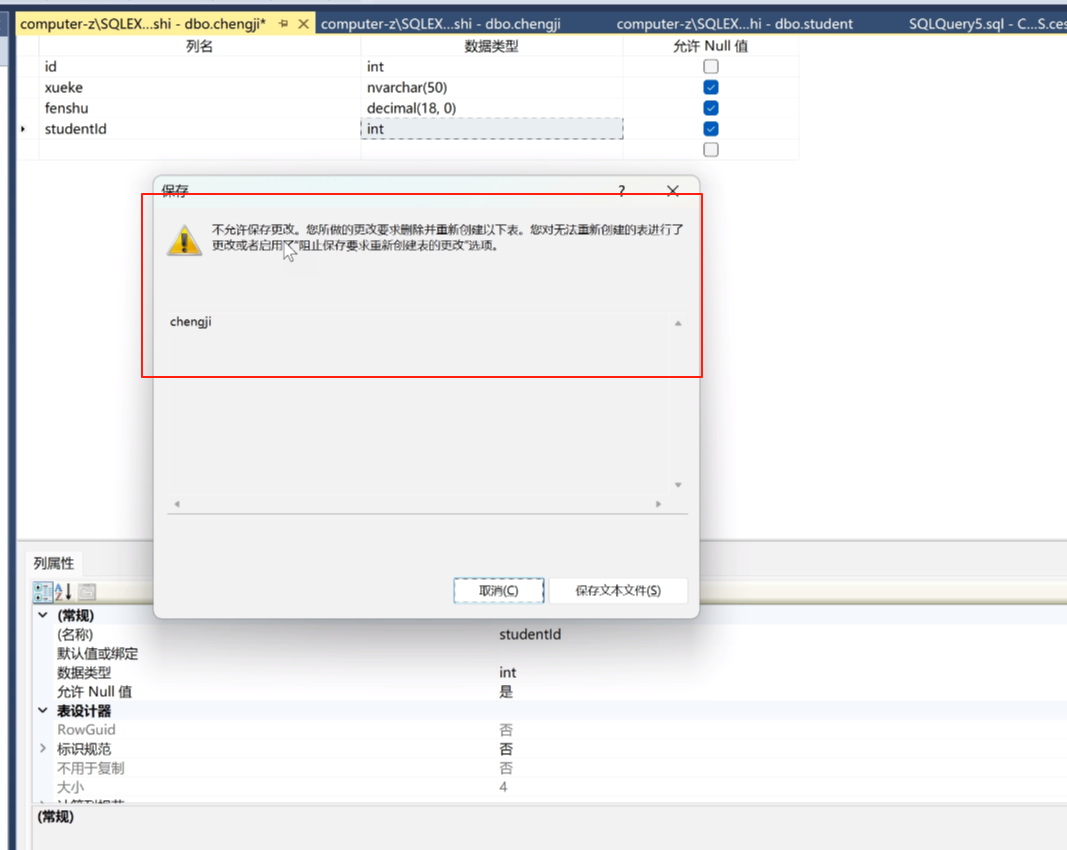
这时候我们来解决一下这个问题
点击工具里面的选项。

找到设置器,然后把这个不打勾,点确定就可以保存了。
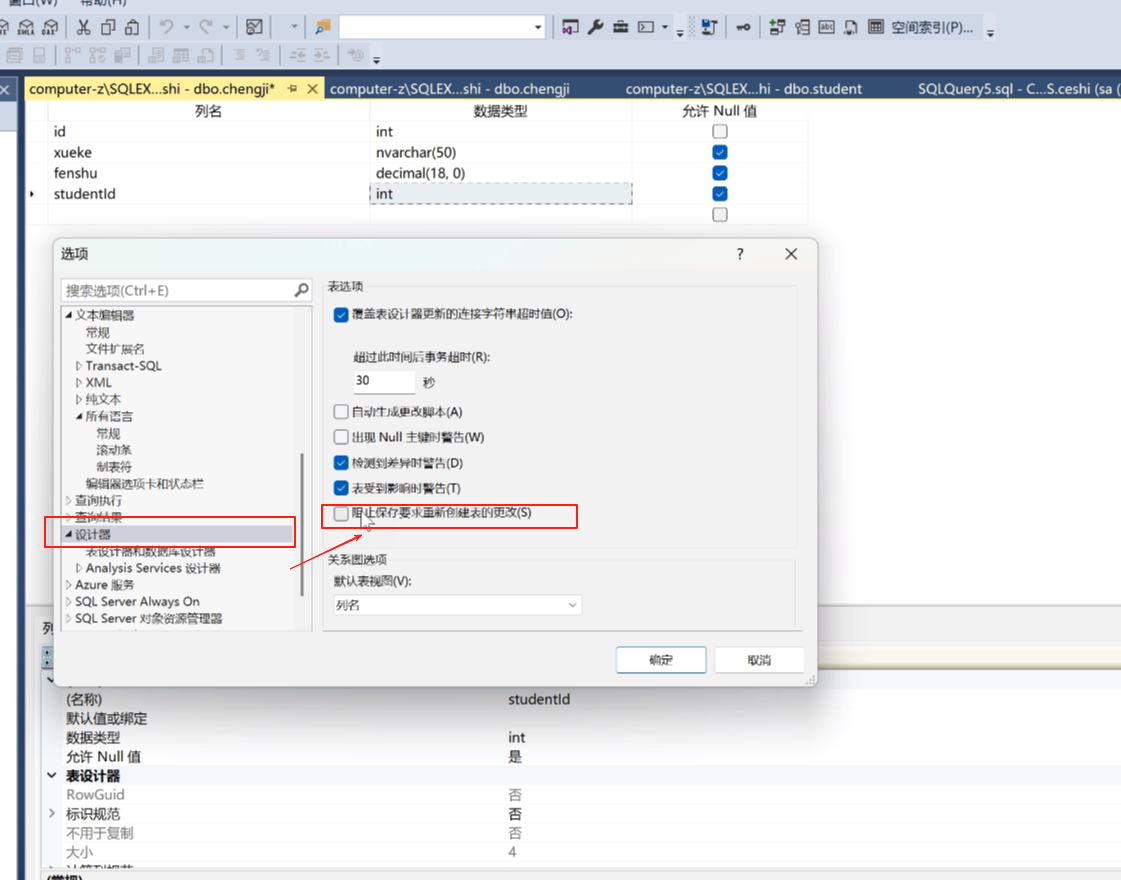
然后点着这个小三角把这一行的信息网上拽,放到上面去。保存一下。
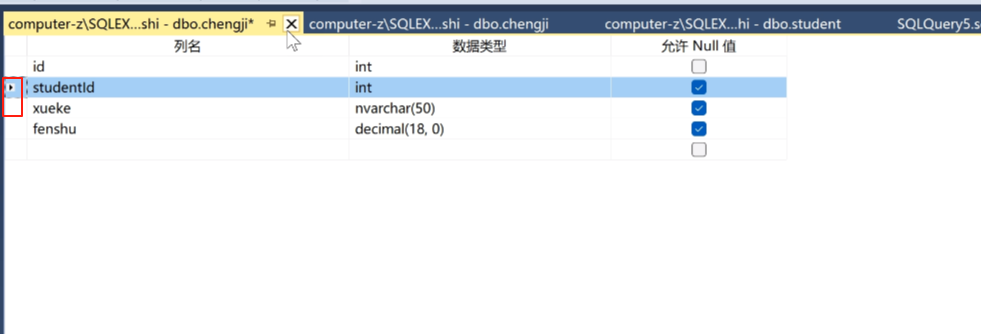
然后 刷新一下这个表就出来了。
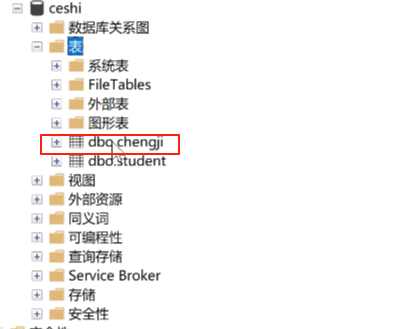
然后把student表里的chengji改成zongfen。
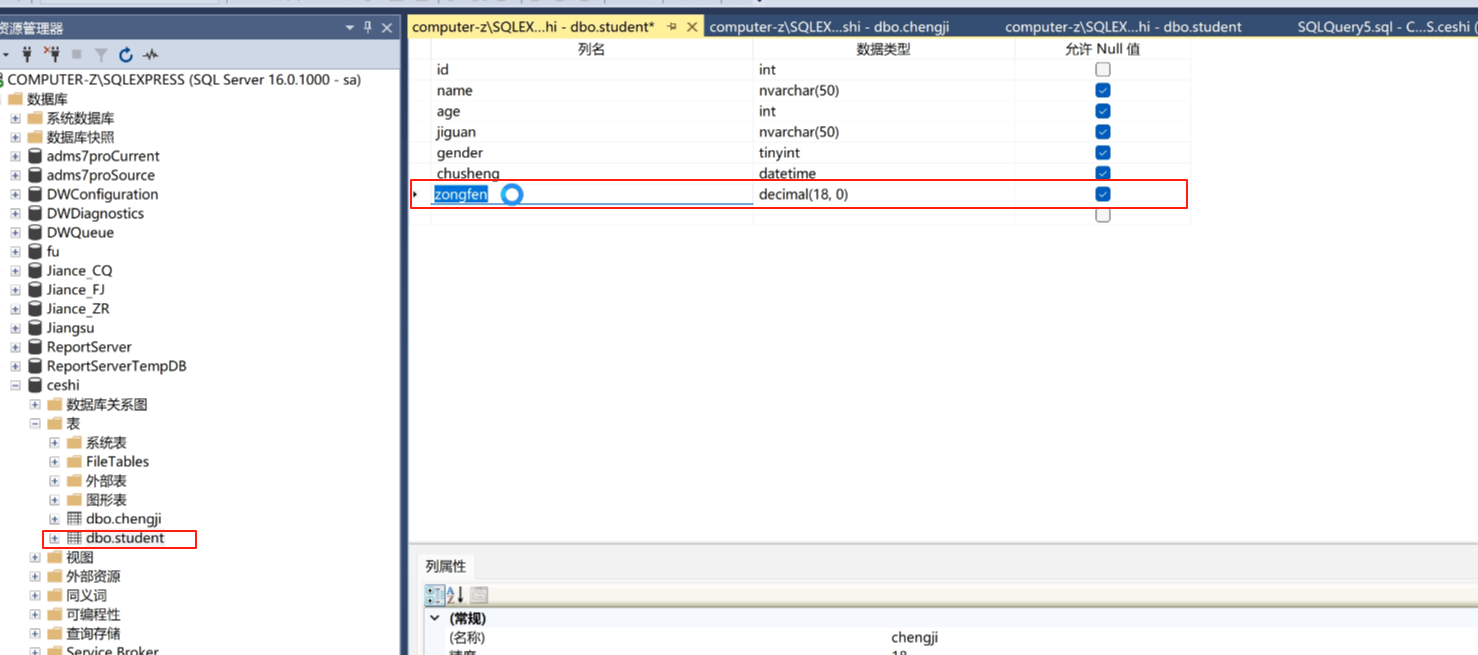
然后我们继续在操作,给chengji这个表里面赛一点数据。这里直接这样放数据了。
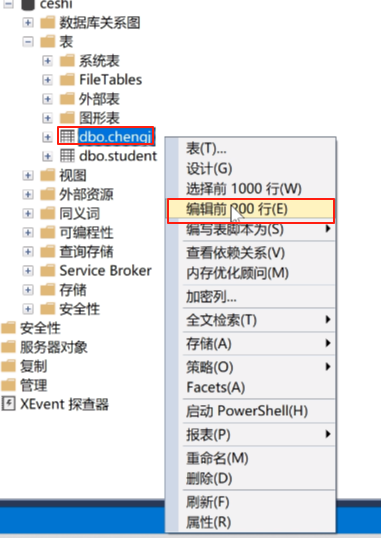
就可以在这里输入一些信息了,输入完了点击这个执行。
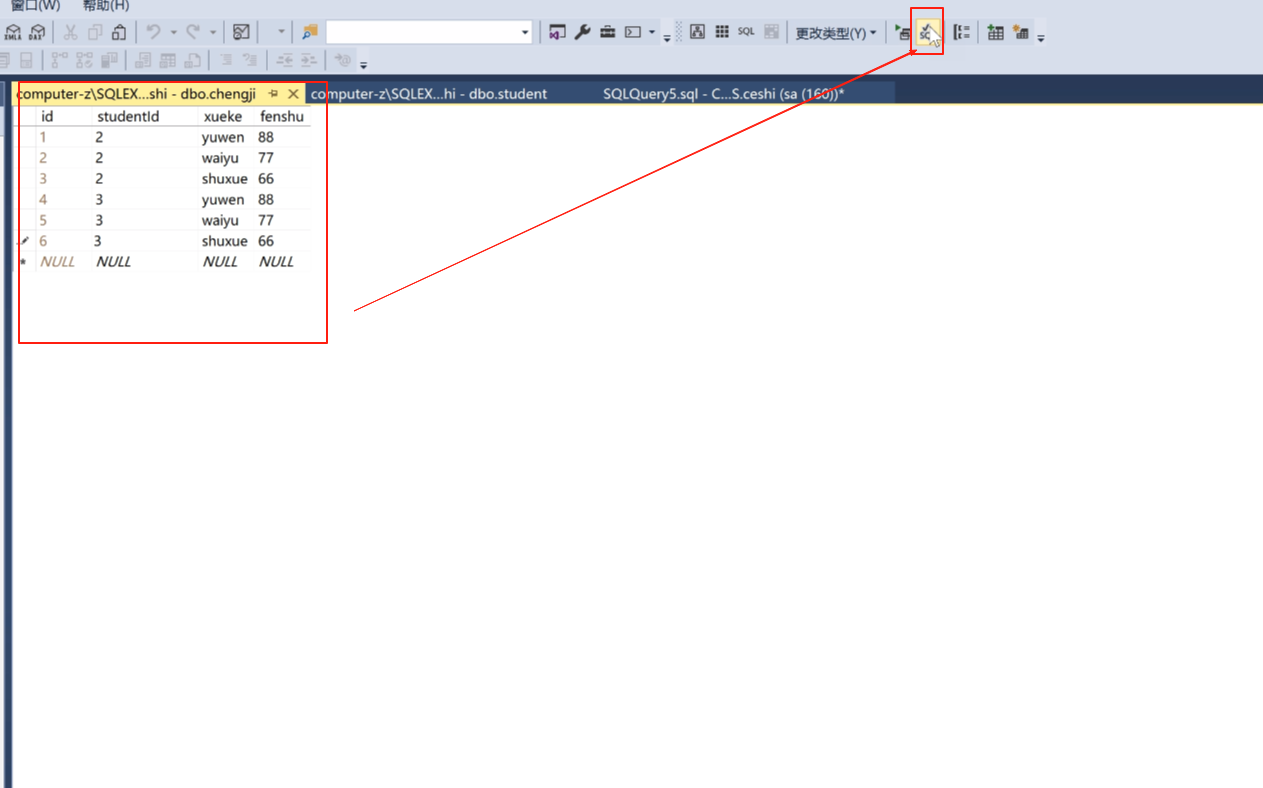
然后 成绩这个表
select * from chengji ;
查询成绩这个表,输入完了点击执行
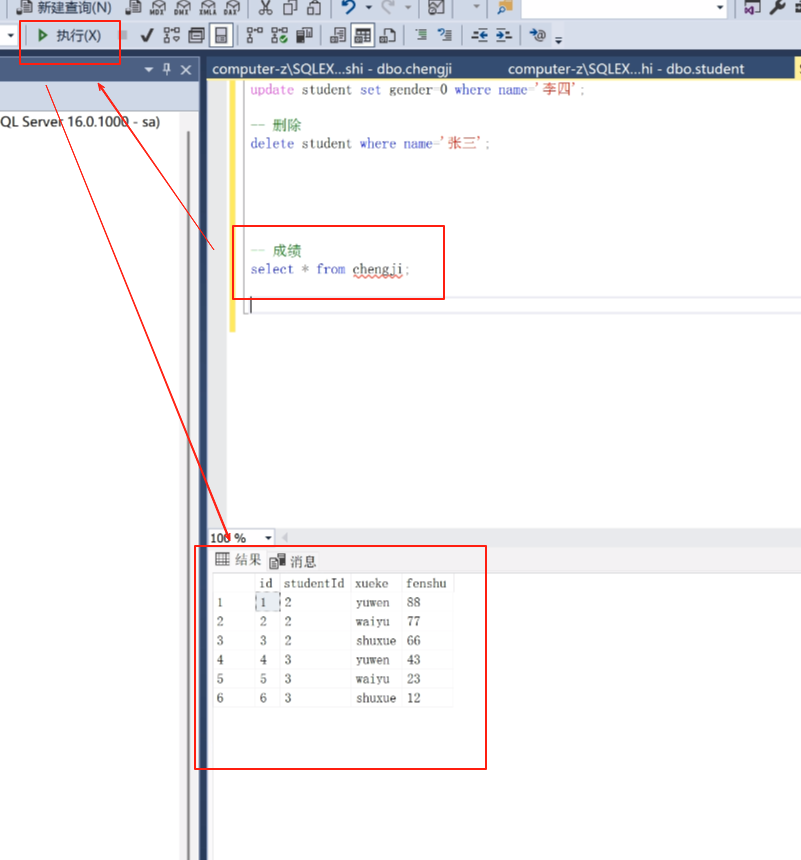
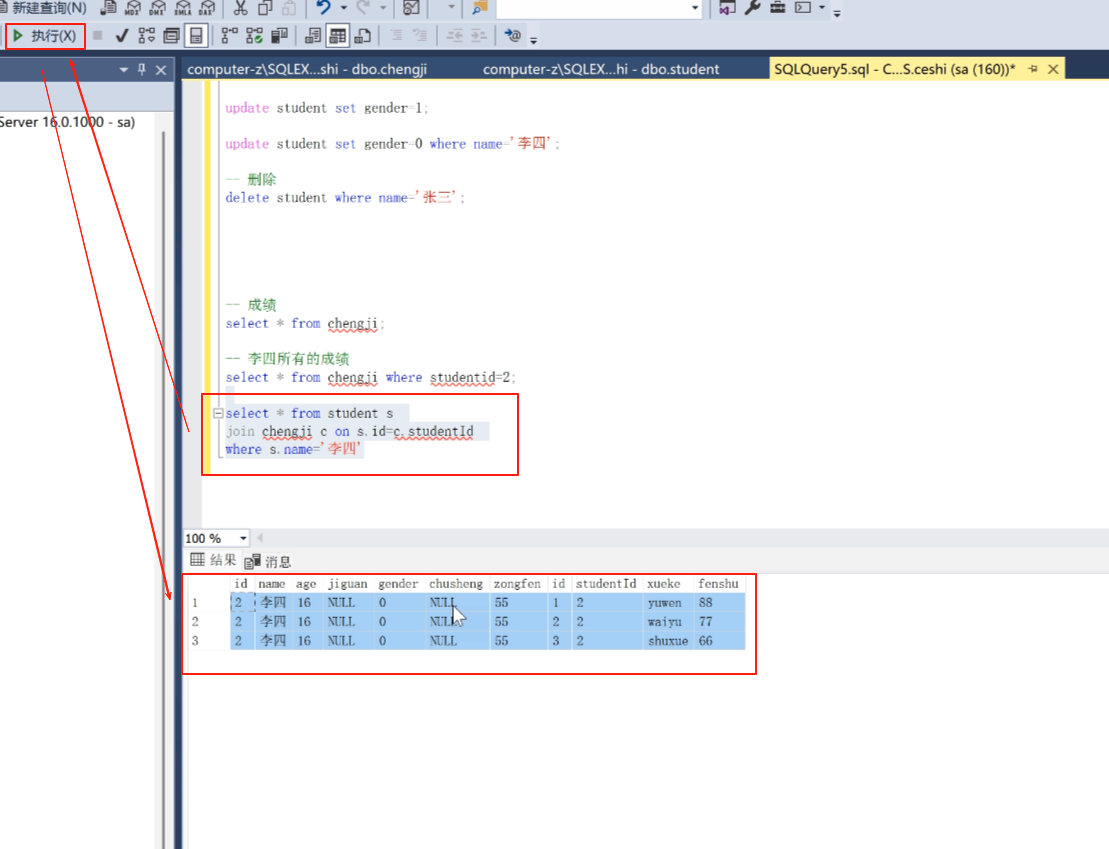
然后我要查李四的所有成绩
select = from chengji where studentid=2;
select * from student s 这里给student表起了一个别名。可以换行。
join chengji c on s.id =c.studentId 这里也给chengji 表起了一个别名。 join 联查,on条件
where s.name=‘李四’ 这里我就找到李四这个人了。
select * from student s
join chengji c on s.id =c.studentId
where s.name=‘李四’ ;
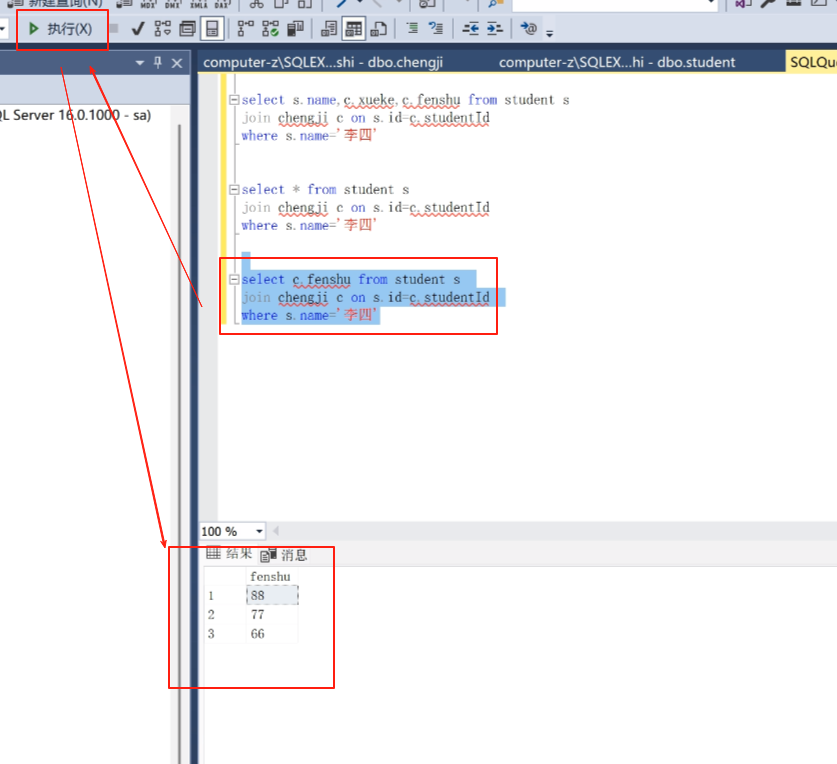
select c.fenshu from student s
join chengji c on s.id =c.studentId
where s.name=‘李四’ ;
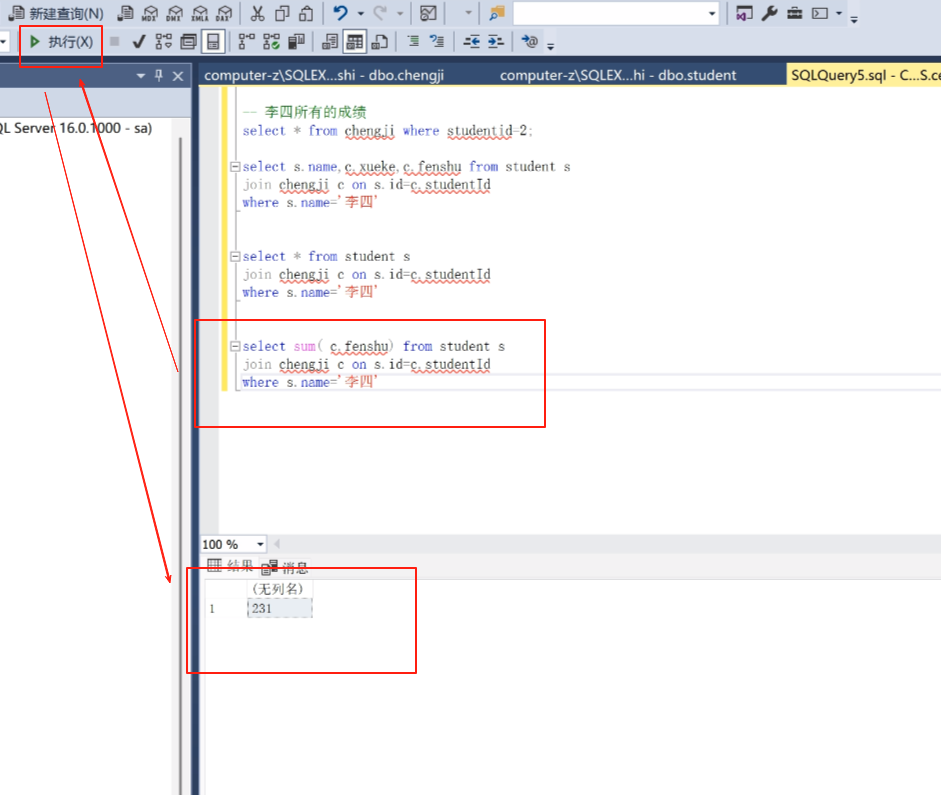
现在查李四的总分
select sum( c.fenshu) from student s
join chengji c on s.id =c.studentId
where s.name=‘李四’ ;
现在查全班同学的总分
select sum( c.fenshu)/count(1) from student s count(1)就是行数,有几行。
join chengji c on s.id =c.studentId
where s.name=‘李四’ ;
这样就拿到了平均数了。但是这样是把所有的学科都平均了。没有说拿到的是总分。

这是从结果表里面查的。
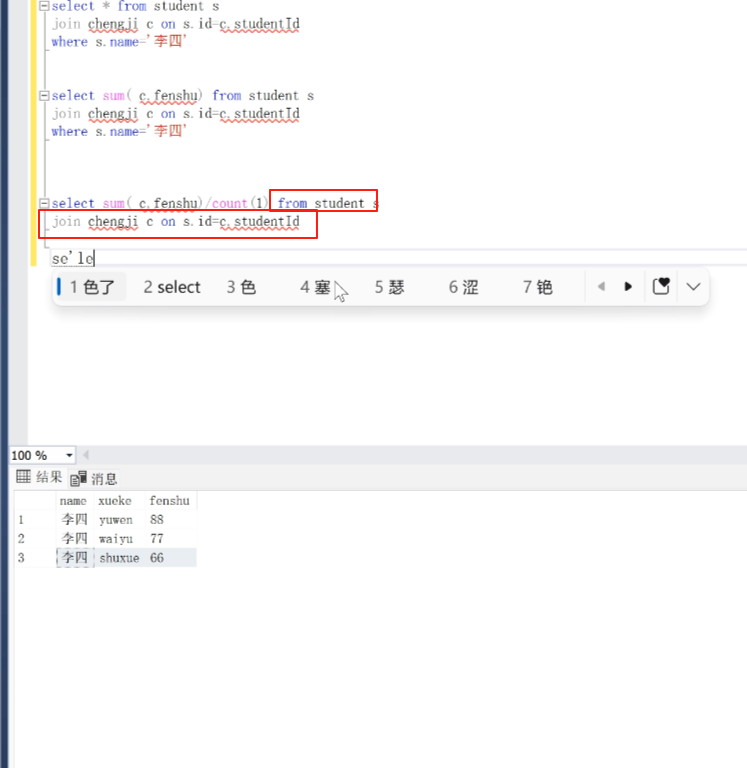
可以看到李四和王五的,有6行,也就是这个 count(1)是6

如果我们要算语文的平均分
select sum( c.fenshu)/count(1) from student s
join chengji c on s.id =c.studentId
where xueke=‘yuwen’ ;

所有人 总分平均分
现在两表联查
select from student s join chengji c on s.id =c.studentId
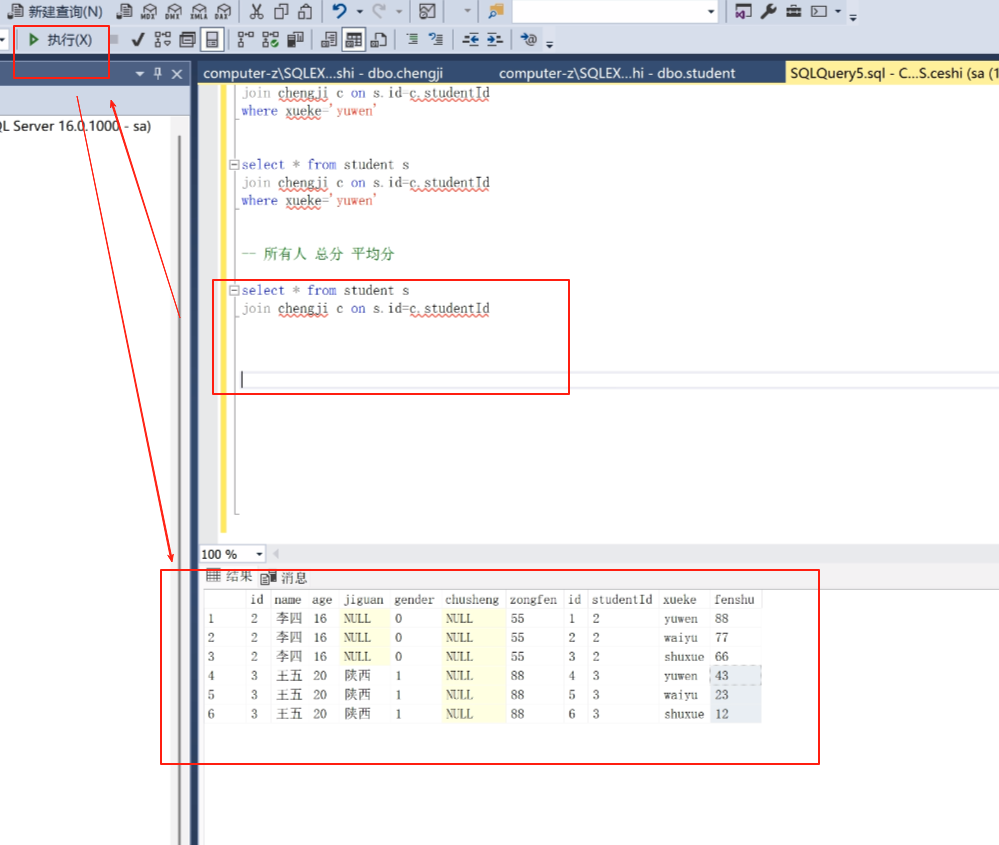
现在分组,按id分组。
select s.id from student s s.id 是分组之后查什么东西,查s.id
join chengji c on s.id =c.studentId
group by s.id 按学生表里面的id分组。
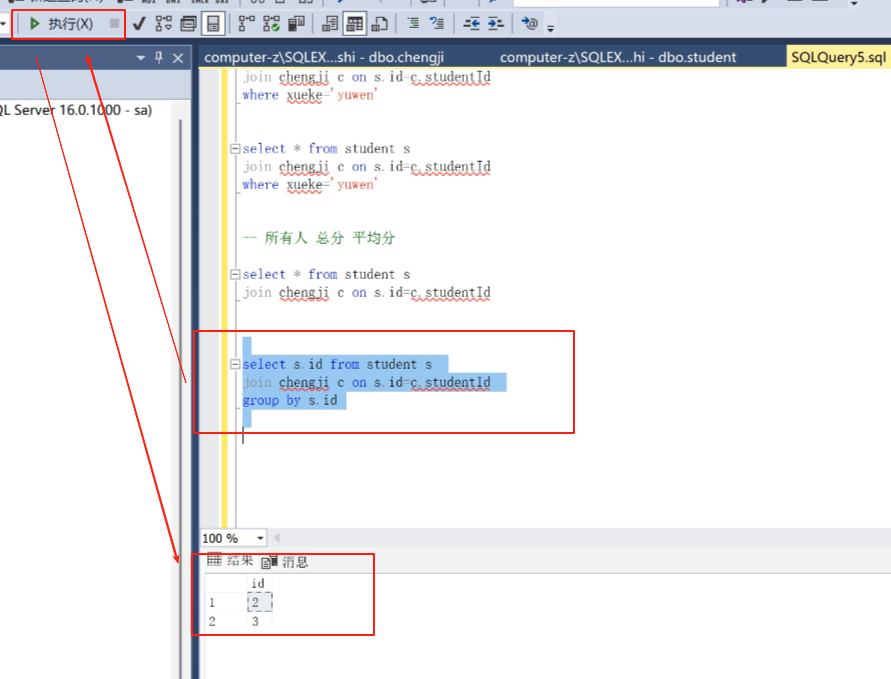
这个时候我还想要2的总分和3的总分。
select s.id ,sum(c.fenshu) from student s
join chengji c on s.id =c.studentId
group by s.id

这里面写的数据是为了方便让我们查数据,后端要写一个和这个功能一样的方法。
join就是两边都有才查的,
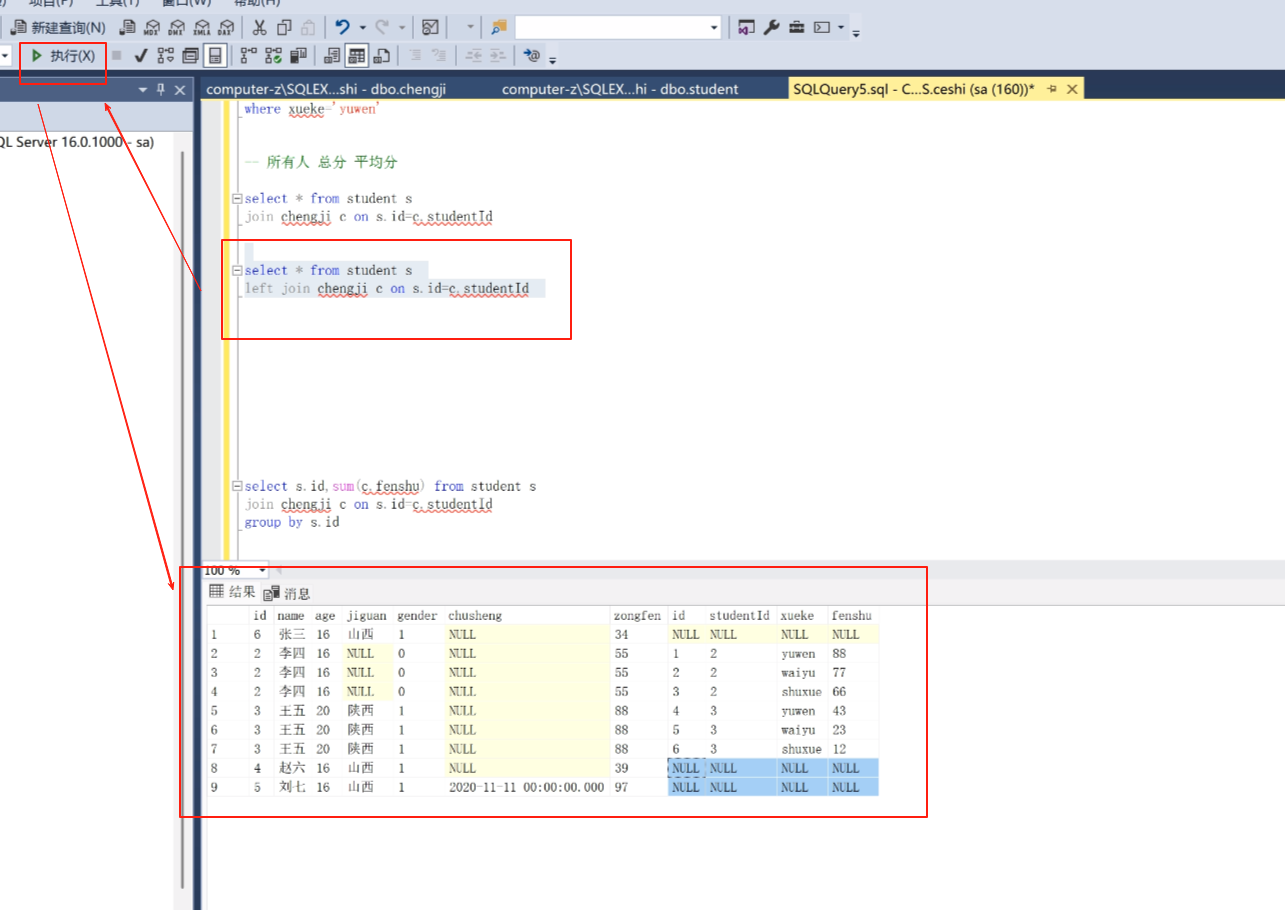
left join就是按左边的对齐
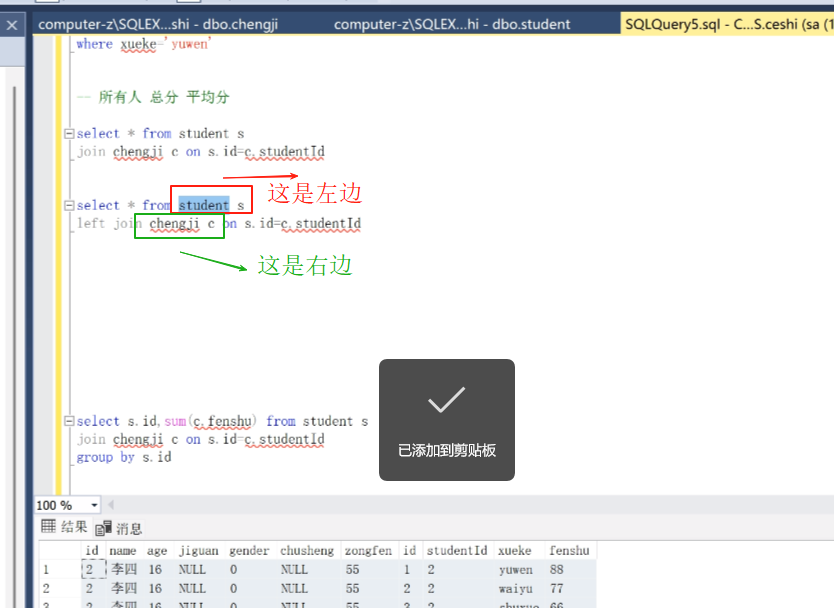
可以看到左边的肯定会有,右边的没有就给null
right join 按右边对齐
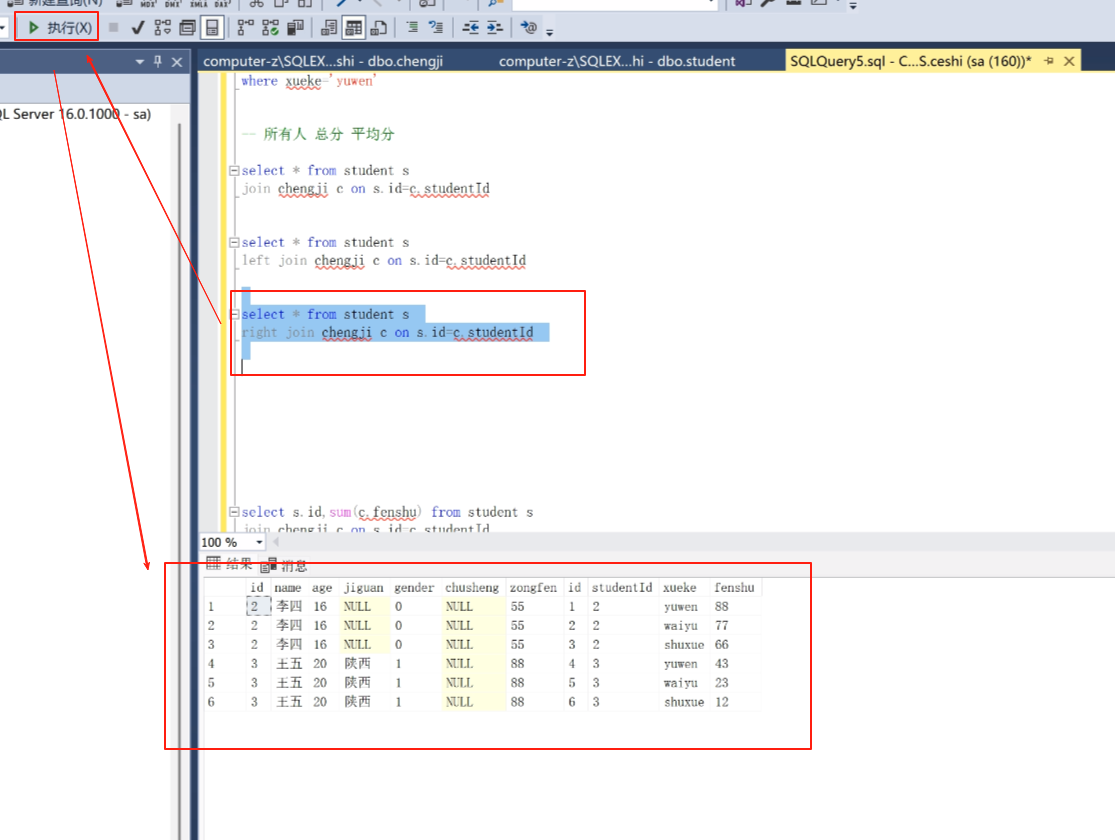
full join 全对齐
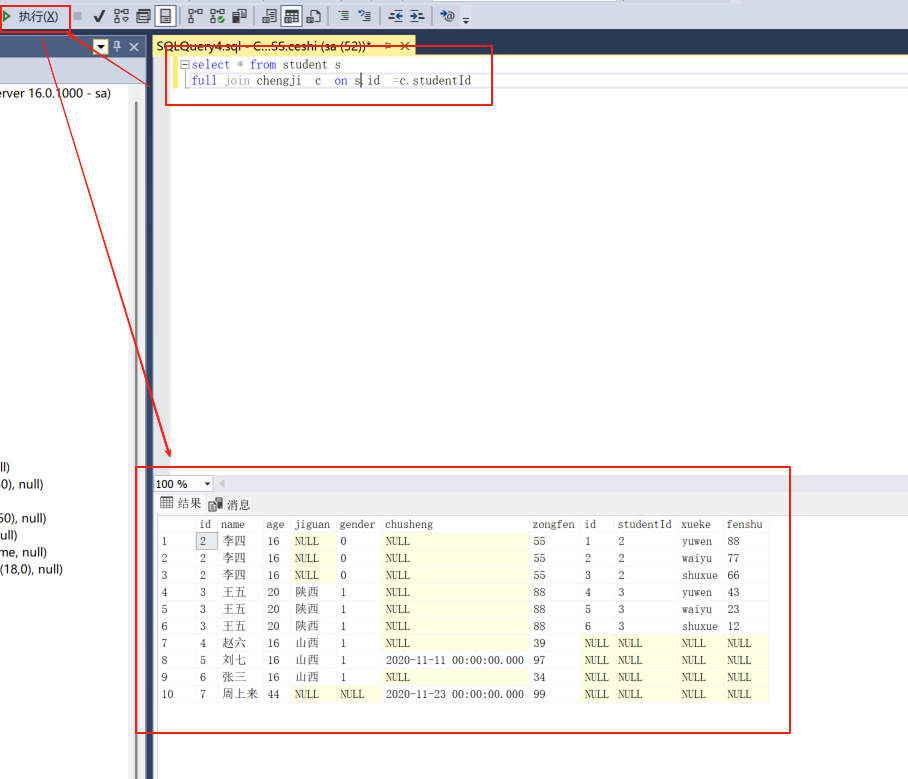
select * from student s
INNER join chengji c on s.id =c.studentId

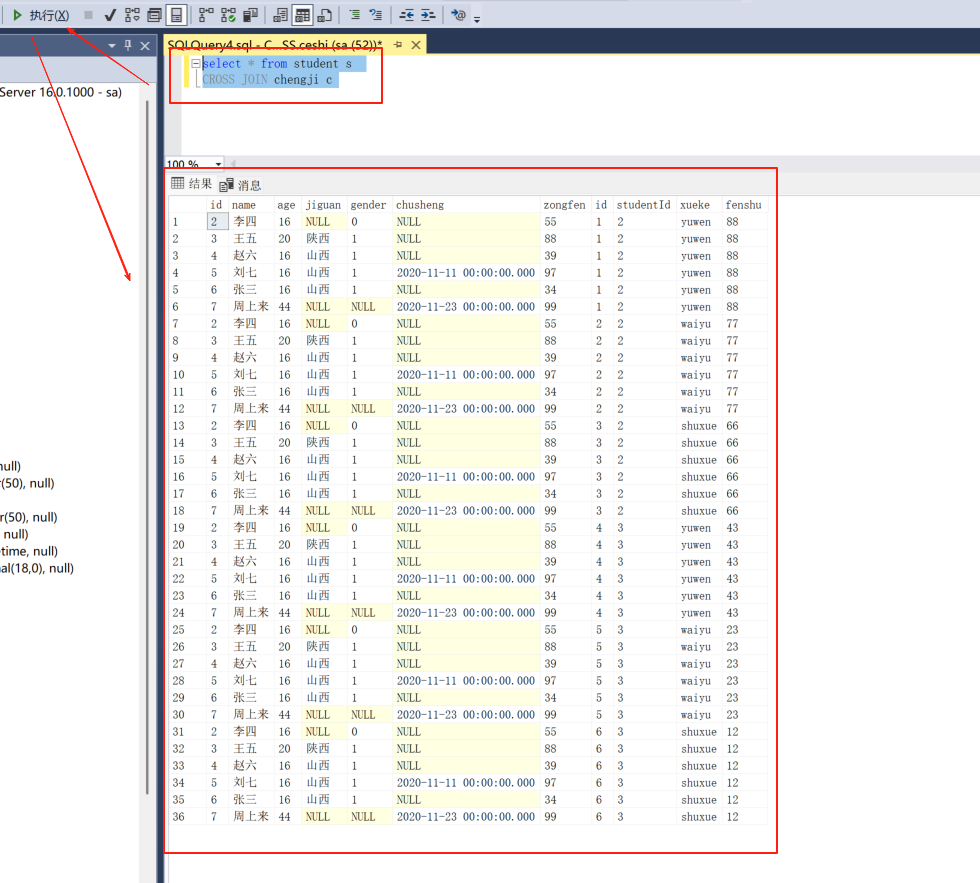
select * from student s
CROSS JOIN chengji c
| 连接类型 | 对齐逻辑 | 结果集包含内容 |
|---|---|---|
| RIGHT JOIN | 以右表为基准,左表匹配右表数据 | 右表全部行 + 左表匹配行(无匹配时左表字段为 NULL) |
| LEFT JOIN | 以左表为基准,右表匹配左表数据 | 左表全部行 + 右表匹配行(无匹配时右表字段为 NULL) |
| INNER JOIN | 只保留两表中匹配的行(交集) | 两表满足连接条件的共同行 |
| FULL JOIN | 左表和右表的并集(极少数据库支持) | 左表全部行 + 右表全部行(无匹配字段为 NULL) |
| CROSS JOIN | 两表的笛卡尔积(无过滤条件) | 左表每行与右表每行组合,结果行数 = 左表行数 × 右表行数 |
每个表都需要主键。
我们需要设一个主键,右键点击然后设为主键。
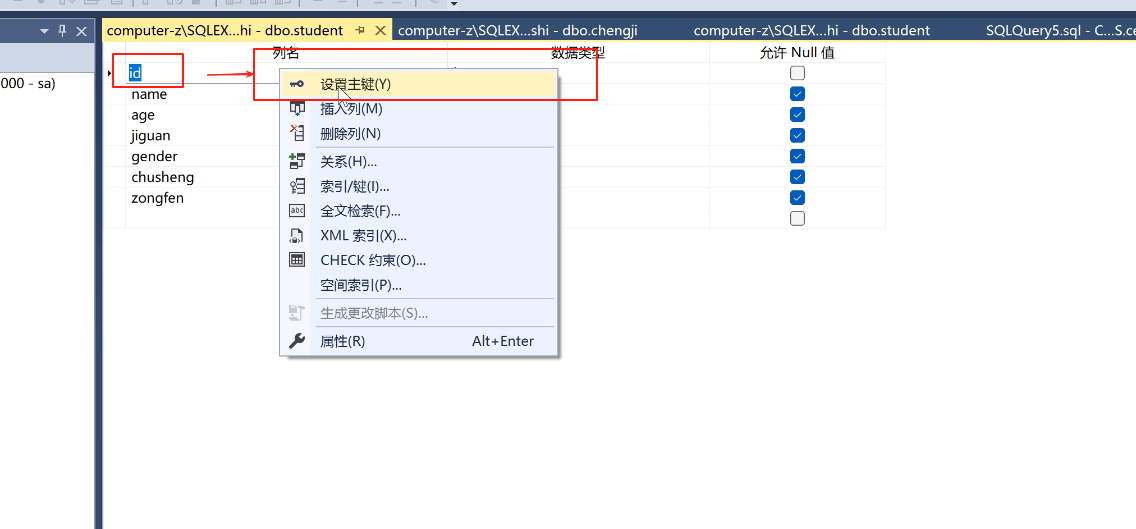
前面这里有一个标识可以看见,然后保存一下。

这里我们写的可以ctrl+s保存


 浙公网安备 33010602011771号
浙公网安备 33010602011771号