
20191205张潇——学习笔记1
一、知识点总结:
第一章:引言
前言:
第一章是本书的引言的部分,讲述了Unix的历史,介绍了Linux的开发及其各种发行版,还解释了Linux的启动过程,描述了Unix/Linux文件系统组织、文件类型和常用的Unix/Linux命令,最后介绍了用户管理和维护Linux系统需执行的一些系统管理任务。
学到了什么?
- 开篇介绍系统编程的作用:是计算机科学和计算机工程教育不可或缺的一部分。
- 这本书的目标:(1)强化学生的编程背景知识、(2)可以应用动态数据结构(包括C结构、指针、链表和链树)、(3)理解进程概念和进程管理、4)尝试使用用户级线程,实现线程同步工具,并通过用户级线程练习并发编程、(5)实现支持并发任务的间隔定时器、(6)使用Linux信号和管道来实现一个进程间通信机制、(7)让学生实现一个与Linux完全兼容的完整EXT2文件系统、(8)可以使用CGI编程来实现一个网络服务器。
- 通过阅览本书的独特之处,感觉到这本书很适用于我们学生群体,既考验了学生的动手实践能力,又考验了小组团队合作能力。
- Unix和Linux历史:Unix系统衍生出了两个系统(BSD伯克利软件发布和System V),BSD是加州大学伯克利分校搞出来的,而System V是AT&T的;Linux系统的组成:(1)Linux内核功能:进程调度:Linux属于抢占式多任务操作系统。计算机只有一个CPU,既然多任务,那只能一个一个来获得CPU的使用权,那谁先谁后呢?这就需要制定规则,这个规则就是“抢占”(我看到有的书中叫做“循环时间共享(SCHED_RR)”)。
- 对于虚拟机上的Linux,我在大一上时候采用的是VirtualBox,但是后来随着用的次数越来越多,我发现它并不是特别好用,时常会出现卡顿的情况,所以这半年打算下载VMware来启动Linux。
- Unix/Linux文件系统组织:文件类型有目录文件、非目录文件(常规文件和特殊文件(字符特殊文件与块特殊文件))、符号链接文件。
- Ubuntu Linux系统管理:(1)用户账户:当用户使用登录名和密码登录后,登录进程将通过获取用户的gid和uid来转换成用户进程,并将目录更改为用户的homeDir,然后执行列出的initialProgram,该程序通常为命令解释程序sh。(2)sudo命令:在Ubuntu里,sudo(“超级用户执行”)允许用户以另一个用户(通常是超级用户)的身份执行命令,为确保用户能够发出sudo,只需在sudoers文件中添加一行:username ALL(ALL) ALL。
第二章:编程背景
前言:
第二章主要讲述了系统编程所需的背景信息:介绍了基于GUI的文本编辑器(这个在大二下学java时有所涉及);展示了如何在命令和GUI模式下使用EMACS编辑器来编辑、编译和执行C语言程序;并且向我们阐述了程序开发的步骤;详细阐释了函数调用惯例和运行时堆栈的使用;展示了C语言程序与汇编代码的链接;学会运用GUNmake工具编写makefile;提及了如何使用GDB调试工具调试C语言程序,并防止出现调试过程中出现的常见错误;复习了C语言中的结构和指针。以及数据结构中的二叉树模拟Unix/Linux文件系统树中的操作等。
学到了什么?
- Linux中的文本编辑器:第二章介绍了三个文本编辑器,有vim、gedit和EMACS。对于vim而言有三种不同的操作模式:命令模式、插入模式和末行模式;gedit是GNOME桌面环境默认的文本编辑器;EMACS(GUN EMACS 2015)可以在很多不同的平台上运行。
- 程序开发:步骤:(1).创建源文件:使用文本编辑器创建一个或多个程序源文件;(2).用gcc把源文件转换成二进制可执行文件;(3).完成gcc三大步骤:1.将C源文件转换为汇编代码文件;2.把汇编代码转换成目标代码;3.执行链接器:将.o文件的所有代码段组合成单一代码段,再将所有数据段组合成单一数据段,最后将所有BSS段组合成单一bss段,用.o文件中的重定位信息调整组合代码段中的指针以及组合数据段、bss段中的偏移量,便于用符号表来解析各个.o文件之间的交叉引用。
- C语言程序变量:全局变量、局部变量、静态变量、自动变量和寄存器变量
- 创建二进制可执行文件的方式有:静态链接和动态链接。其中动态链接的优点是:可减小每个a.out文件的大小;许多执行程序可在内存中共享相同的库函数;修改库函数不需要重新编译源文件。
- 大部分C编译器和链接器可生成多种不同格式的可执行文件:(1)二进制可执行平面文件;(2)a.out可执行文件;(a.out文件的内容包括文件头、代码段、数据段和符号表)(3)ELF可执行文件。
- Makefile:一个make文件由一系列目标项(创建或更新的文件,也可能是make程序要引用的指令或标签)、依赖项和规则(使用依赖项列表构建目标项所需的命令)组成。
- 错误总结:C语言程序中常见的错误:1.未初始化的指针或含有错误值的指针;2.数组下标越界;3.字符串指针和char数组使用不当;4.assert宏
- C语言结构体的属性:(1)定义C语言结构体时,该结构体的每个字段都必须具有一个编译器已知的类型,但自引用的指针除外;(2)每个C语言结构体数据对象都分配了一个连续内存块;(3)一个结构体的大小可以由sizeof(struct type)确定;(4)假设“NODE x,y;”为两个相同类型的结构体;(5)C语言联合体与结构体类似。
- 链表操作:构建、遍历、搜索、插入、删除、重新排序;
- 其中第二章的数组、指针、链表和树的知识是以前学的内容,这里我就不再过多赘述。
最有收获的内容:
看完第一章和第二章内容之后,我对makefile的知识仍然有所不清楚,对于书中讲解的内容很感兴趣,所以我便去查阅了很多资料来进一步了解这方面知识。以下是我的总结:
makefile
1.1Makefile介绍
Makefile的核心是“自动化编程”,简简单单的make命令就可以使很庞大的系统按照我们自定义的依赖规则和执行命令的顺序进行编译。其中Makefile最重要的语法是
target:prerequisites
Command
其中有两条规则:
- 要得到target,需要执行命令command;
- Target依赖prerequisites,当prerequisites中至少有一个文件比target文件更新的时候,command才被执行。
我看到网络上很多人说在Unix下的软件编译,你就得自己写Makefile了,会不会写Makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。确实,Makefile关系到了整个工程的编译规则,一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大地提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
1.2Makefile工作
在默认的方式下,当我们输入make命令时:
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“edit”这个文件,并把这个文件作为最终的目标文件。
- 如果edit文件不存在,或是edit所依赖的后面的 .o 文件的文件修改时间要比edit这个文件新,那么,他就会执行后面所定义的命令来生成edit这个文件。
- 如果edit所依赖的.o文件也存在,那么make会在当前文件中找目标为.o文件的依赖性,如果找到则再根据那一个规则生成.o文件。(这有点像一个堆栈的过程)
- 当然,你的C文件和H文件是存在的啦,于是make会生成 .o 文件,然后再用 .o 文件声明make的终极任务,也就是执行文件edit了。
说明:make会一层一层地去找文件的依赖关系,直到编译出第一个目标文件,在找寻的过程中,如果出现错误,那么make就会直接退出,并报错;make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么make就不工作了。
1.3Makefile使用变量
在 Makefile中的定义的变量,就像是C/C++语言中的宏一样,它代表了一个文本字串,在Makefile中执行的时候其会自动原模原样地展开在所使用的地方。其与C/C++所不同的是,你可以在Makefile中改变其值。在Makefile中,变量可以使用在“目标”,“依赖目标”,“命令”或是 Makefile的其他部分中。变量的命名字可以包含字符、数字,下划线(可以是数字开头),但不应该含有“:”、“#”、“=”或是空字符(空格、回车等)。变量是大小写敏感的,“foo”、“Foo”和“FOO”是三个不同的变量名。传统的Makefile的变量名是全大写的命名方式,但我推荐使用大小写搭配的变量名,如:MakeFlags。这样可以避免和系统的变量冲突,而发生意外的事情,有一些变量是很奇怪字串,如“$<”、“$@”等,这些则是自动化变量。
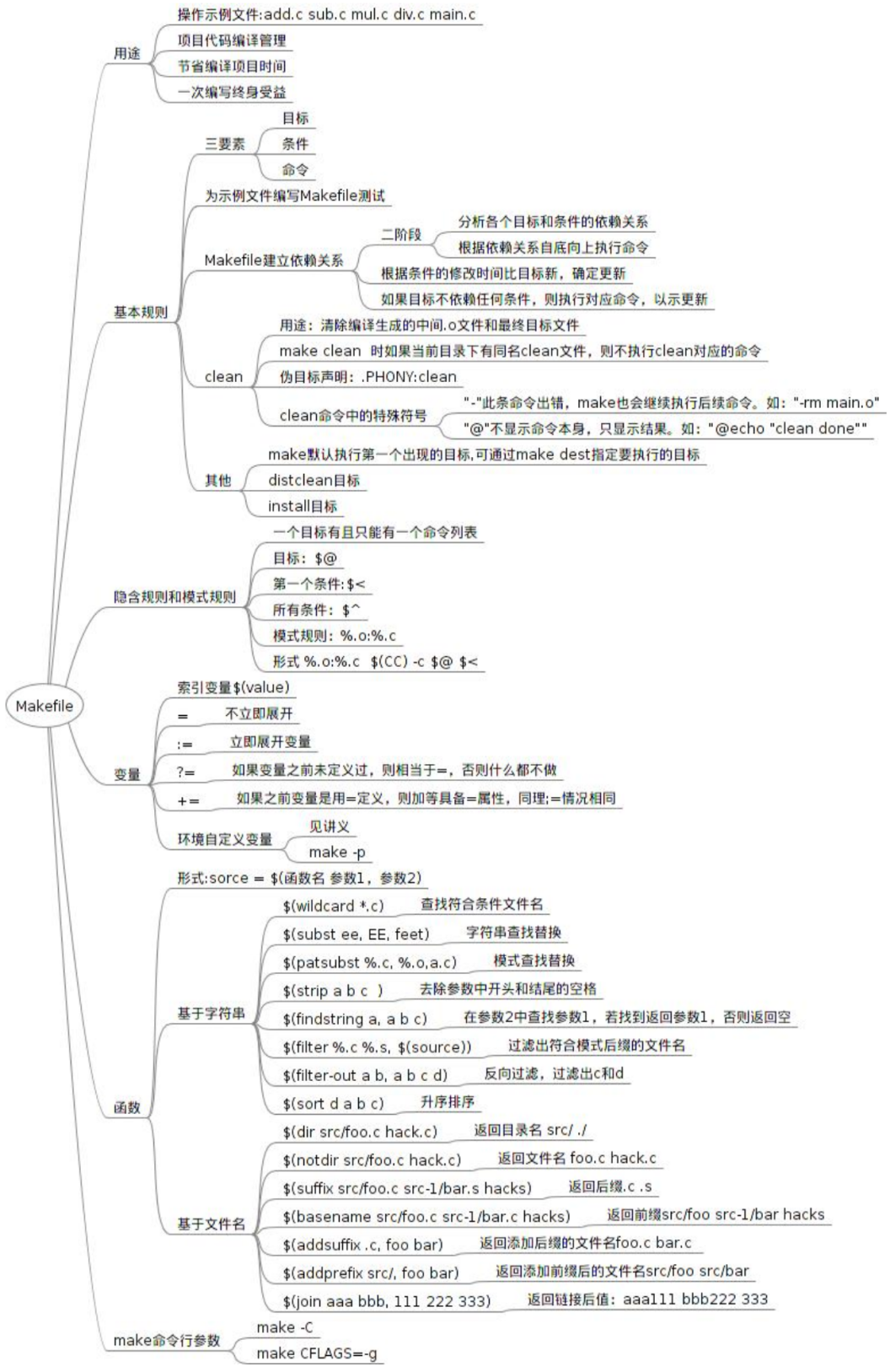
下面附上我在博客园上找到的一张图片,宏观地介绍了Makefile各个方面:
上课老师讲的内容:
快捷键:
Ctrl+alt+T——打开终端;
Ctrl+shift+T——打开另一个终端;
alt+1、2、3——切换界面(一般是界面1用来编写代码、界面2用来编译、界面三用来调试);
gcc+文件名——编译;
!142——显示第142行代码;
history——显示历史命令;
预处理:gcc -E hello.c -o hello.i,gcc -s hello.i -o hello.s;
file:查看文件格式;
二进制文件读写:od -tc-tx4 hello.c;
预处理:gcc -E xx.c-o xx.i;编译:gcc -S xx.c-o xx.s;汇编:gcc -C xx.c-o xx.o;
代码包括:伪代码、产品代码、测试代码;
-L:指定库路径,-l:指定使用哪个库;
gcc src/hello.c -Iinclude;
…………
二、问题与解决思路
我有如下两个问题:
(1)为什么每个C语言程序都必须有一个main()函数?
(2)是否可以使用中序遍历或后序遍历来保存和重构二叉树?
我的解决思路如下:
第一问:
- 通过看书
我知道gcc的编译过程分为三步:
第一步将 *.c 文件分别通过编译器解析成汇编语言*.s。
第二步将 *.s 文件分别通过汇编器生产目标文件*.o 。
第三步将 c.o文件通过链接器合成一个 .out的可执行文件。
当执行.out或者.exe 可执行文件时,程序入口通常是main函数。
- 查阅资料
在 linux 里面,根据TIS 的ELF规范,一个可执行程序,也就是一个可执行的对象文件,它有一个程序进入点,这个进入点不是我们写的 main 函数,而是位于 c 库中的 _start 汇编代码中。在这个汇编代码中,它会去调用我们写的 main C函数,而这个调用是写死的,所以我们没办法不用 main 函数。 实际上,假如你的C程序没用用 main 函数,那用 gcc 链接的时候,将会报错。
- 自我总结
一个程序中,必须要有一个入口函数来告诉链接器指明代码从哪里开始执行。大部分链接器的默认函数入口都是main函数。所以当然也可以告诉链接器,入口函数是不是main函数,而是其他函数。自然而然,这个函数名字只要你愿意,改什么都可以,只需要在链接的时候告诉链接器就可以。所以C程序包括其他高级语言的程序main()函数并不都是必需的,只不过是链接器的默认指明的程序入口是main而已。
第二问:
- 通过看书
重构二叉树目前主要是采取递归的方式,只能通过前序,中序或者后续,中序进行重构,而前序和后序是不能够重构的,因为在得知根节点后只有中序遍历才能确定左子树和右子树的数目。
二叉树的几种遍历
前序遍历:根结点 —> 左子树 —> 右子树
中序遍历:左子树—> 根结点 —> 右子树
后序遍历:左子树 —> 右子树 —> 根结点
层次遍历:只需按层次遍历即可
- 查阅资料
这里我主要以先序和后序遍历重构二叉树介绍:
解题思路是:
(1)首先先序中的第一个元素一定是二叉树的根节点。根据这个根节点找到在中序中的位置,那么这一位置左边的元素全部是二叉树的左孩子,这一节点的所有右边节点全部是二叉树的右孩子。
(2)其次构造右子树和左子树。构造思路是:从先序和中序中找到左子树和右子树的先序和中序序列,然后递归构造,直至所有节点使用完。即得到重构的二叉树。
3.自我总结
通过思考我总结了以下关于如何用中序或者后序遍历来重构二叉树的解题步骤:
1、后序遍历的最后一个节点即为根节点;
2、根据根节点,在中序遍历中找出左子树和右子树,并统计左子树和右子树的个数;
3、递归构建左子树和右子树。
三、实践内容
我实践的内容是设计一个优先队列,并且为这个优先队列设计一个数据结构,该题借鉴于课本课后题,我适当地修改了一下:
说明
一、优先队列的定义:
优先队列是0个或多个元素的集合,每个元素都有一个优先权或值,对优先队列执行的操作有查找、插入一个新元素、删除。
二、我采用了C语言来设计此程序
实现本优先队列的初始化,查找,插入,删除操作,并且控制其查找,插入,删除操作的算法时间复杂度为O(logn)。所以采用堆正好能实现该时间复杂度。相关代码以及图片在附件里:
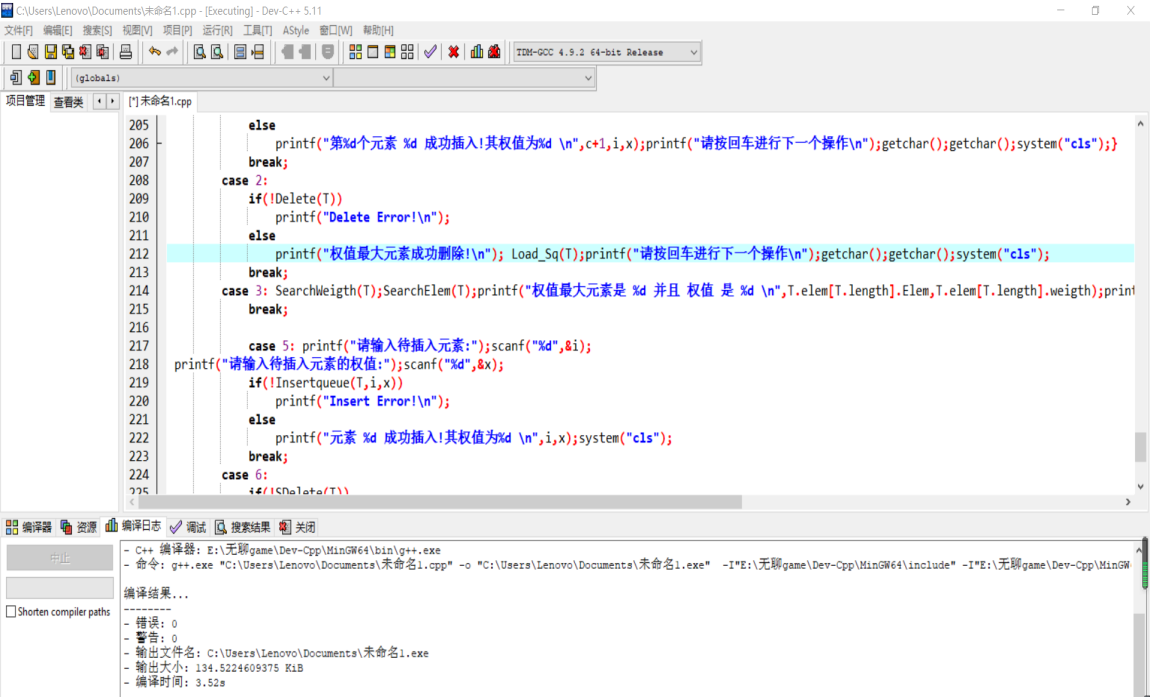
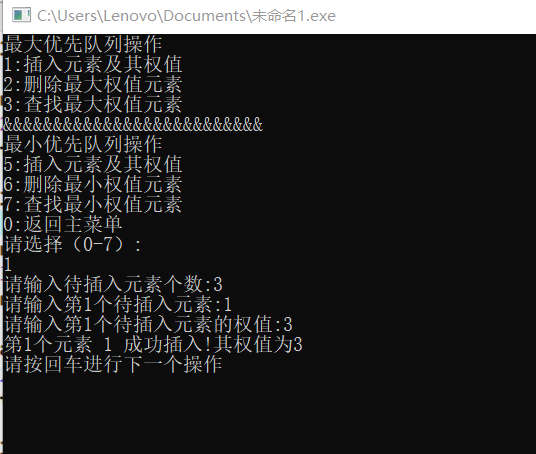
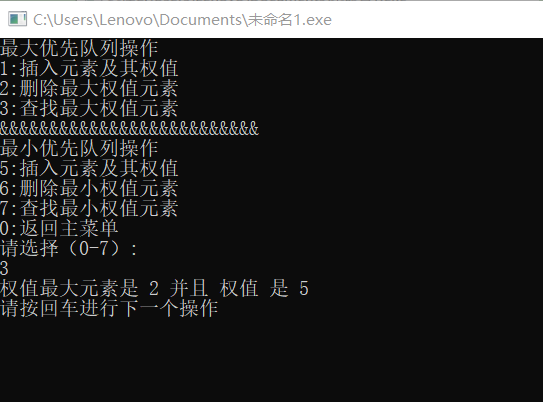
- 最大优先队列操作:先插入三个元素1,2,3,;权值分别为3,5,8;再删除最大权值元素是3,最后通过查找最大权值元素为2,权值为5,如下图:
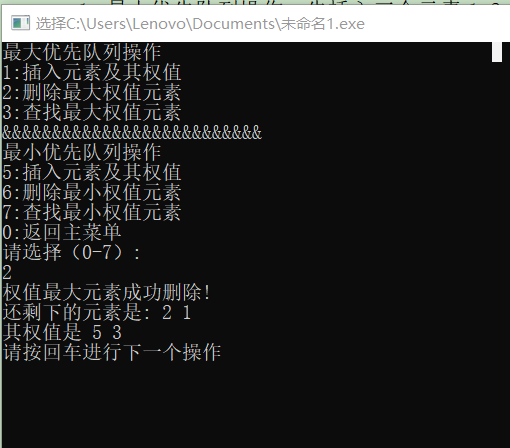
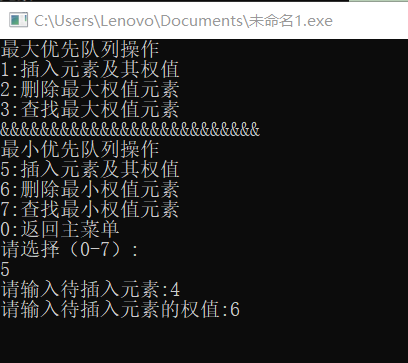
- 最小优先队列操作:先插入两个元素3,2;权值分别为3,5。再删除最小权值元素为3,最后查找最小权值元素为2,如下图:


实践二:
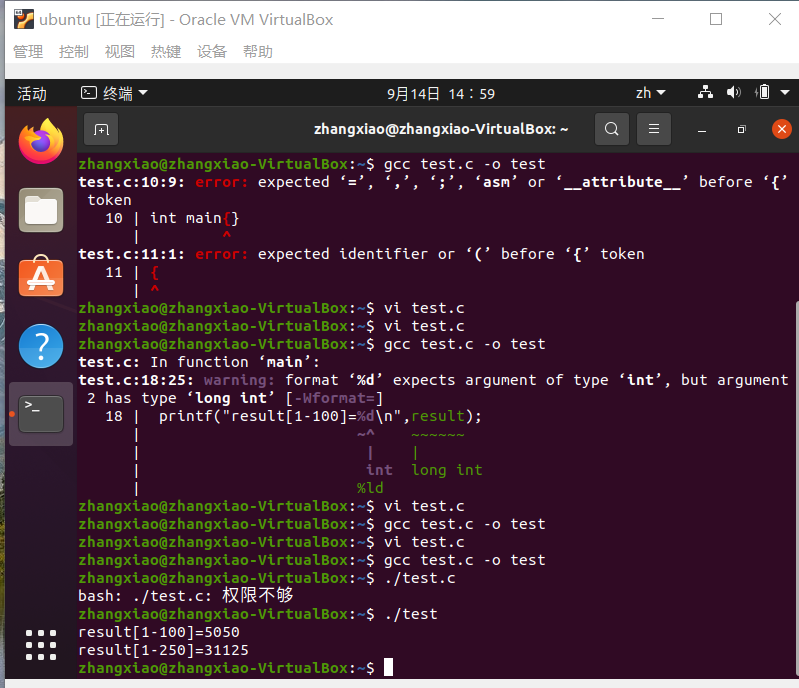
另外有我自己在VirtualBox里实践的一些代码如下图:
代码:
#include <stdio.h>
int func(int n){
int sum=0,i;
for(i=0; i<n; i++)
sum+=i;
}
return sum;
int main(){
int i;
long result =0;
for(i=1; i<=100;i++){
result +=i;
printf("result[1-100] =%ld \n", result );
printf("result[1-250] =%d \n", func(250) );
}

编译过程:

运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号