
数据采集技术第四次作业
作业①:
题目:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;用Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据。
候选网站:当当图书网 ,关键词自由选择。
完整代码:码云作业1
1.解题过程:
1.1 items.py部分:
class BookItem(scrapy.Item):
title = scrapy.Field() # 书籍名称
author = scrapy.Field() # 作者
date = scrapy.Field() # 日期
publisher = scrapy.Field() #出版社
detail = scrapy.Field() #描述
price = scrapy.Field() # 价格1.2 run.py部分:
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())1.3 mySpider.py部分:
1.3.1开始信息:
class MySpider(scrapy.Spider):
name = "mySpider"
key = '数据采集' #关键词
source_url='http://search.dangdang.com/' #网址
def start_requests(self): #开始函数
url = MySpider.source_url + "?key=" + MySpider.key
yield scrapy.Request(url=url, callback=self.parse)1.3.2解析网址:
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data) 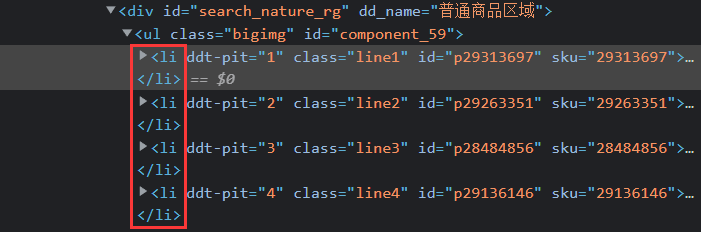
可以看到每一本书的全部信息存放在一个li标签中:
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")1.3.3根据网页信息编写xpath代码:
for li in lis:
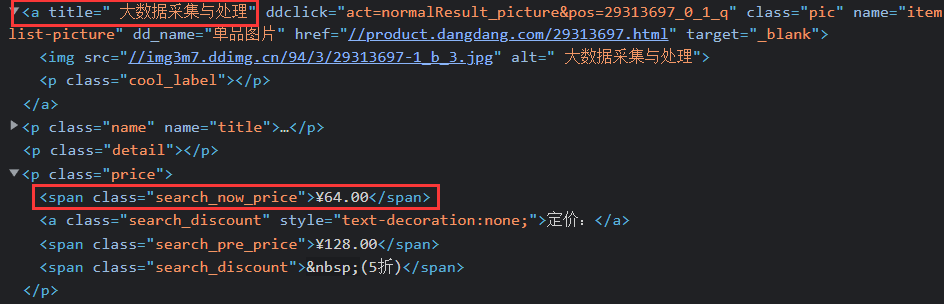
title = li.xpath("./a[position()=1]/@title").extract_first() #爬取书籍名称
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()#爬取价格
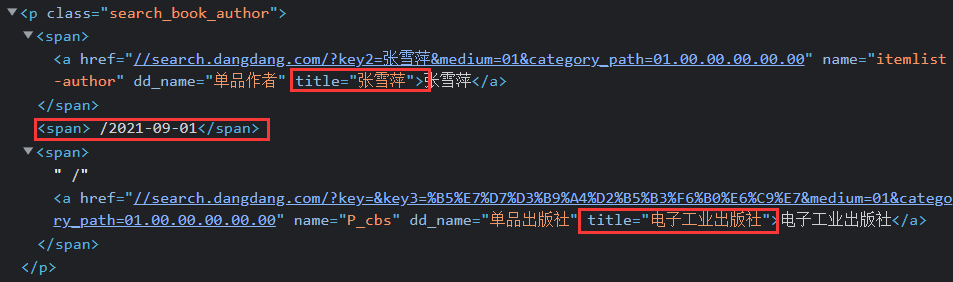
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()#爬取作者
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()#爬取日期
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()#爬取出版社
detail = li.xpath("./p[@class='detail']/text()").extract_first()#爬取描述
# detail有时没有,结果None
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item翻页操作:
![]()

link = selector.xpath("//div[@class='paging']//li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)1.4 setting.py部分:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
}#设置请求头
AUTOTHROTTLE_ENABLED = True
ITEM_PIPELINES = {
'demo4.pipelines.BookPipeline': 300,
}#打开pipelines1.5 pipelines.py部分:
1.5.1创建数据库,写入数据库,关闭数据库:
#打开数据库的方法
def openDB(self):
self.con = sqlite3.connect("books.db")
self.cursor = self.con.cursor() # 创建一个游标对象
try:
self.cursor.execute(" create table books (bTitle varchar(512) primary key,bAuthor varchar(256),bPublisher varchar(256),bDate varchar(32),bPrice varchar(16),bDetail text )")# 创建格式
except Exception as err:
print(err) #插入数据的方法
def insert(self, Title,Author,Publisher,Date,Price,Detail):
try:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values (?,?,?,?,?,?)",(Title,Author,Publisher,Date,Price,Detail))
except Exception as err:
print(err) #关闭数据库的方法
def closeDB(self):
self.con.commit()
self.con.close()1.5.2open_spider函数在开始执行项目时会执行一次:
def open_spider(self, spider):
print("opened")
self.db = bookDB()
self.db.openDB()1.5.3插入数据操作并输出:
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
#插入操作
self.db.insert(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"])
except Exception as err:
print(err)
return item1.5.4close_spider类在结束项目时会执行一次,断开数据库链接。
def close_spider(self, spider):
self.db.closeDB()
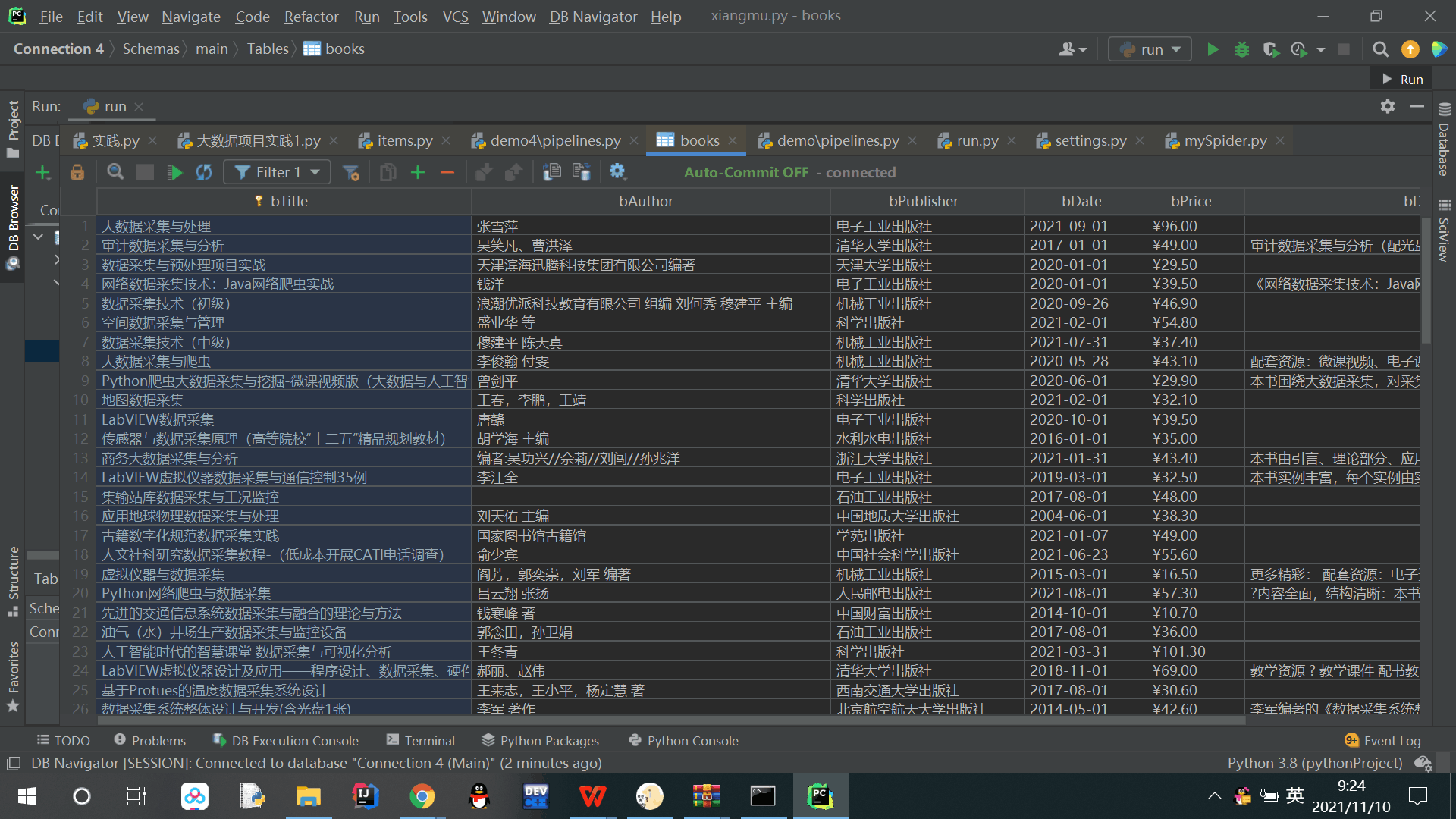
print("closed")输出结果:

2.心得体会:
通过本次实验巩固了Scrapy框架的使用,更加熟悉翻页操作以及将数据保存到数据库的操作。
作业②:
题目:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网
输出信息:
| Id | Currency | TSP | CSP | TBP | CBP | Time |
| 1 | 港币 | 86.60 | 86.60 | 86.26 | 85.65 | 15:36:30 |
| 2 | …… | …… | …… | …… | …… | …… |
完整代码:码云作业2
1.解题过程:
1.1 items.py部分:
class CmbItem(scrapy.Item):
currency = scrapy.Field()#交易币
units = scrapy.Field()#交易币单位
coin = scrapy.Field()#基本币
tsp = scrapy.Field()#现汇卖出价
csp = scrapy.Field()#现钞卖出价
tbp = scrapy.Field()#现汇买入价
cbp = scrapy.Field()#现钞买入价
date = scrapy.Field()#时间1.2 run.py部分:
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())1.3 mySpider.py部分:
1.3.1开始信息:
class MySpider(scrapy.Spider):
name = "mySpider"
url='http://fx.cmbchina.com/hq/'#网址
def start_requests(self):
yield scrapy.Request(url=MySpider.url, callback=self.parse)1.3.2解析网址:
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data) 
lis = selector.xpath("//div[@id='realRateInfo']/table/tr[position()>1]")1.3.3根据网页信息编写xpath代码:
for tr in lis:
currency = tr.xpath("./td[1]/text()").extract_first()#交易币
units = tr.xpath("./td[2]/text()").extract_first()#交易币单位
coin = tr.xpath("./td[3]/text()").extract_first()#基本币
tsp = tr.xpath("./td[4]/text()").extract_first()#现汇卖出价
csp = tr.xpath("./td[5]/text()").extract_first()#现钞卖出价
tbp = tr.xpath("./td[6]/text()").extract_first()#现汇买入价
cbp = tr.xpath("./td[7]/text()").extract_first()#现钞买入价
date = tr.xpath("./td[8]/text()").extract_first()#时间
item = CmbItem()
item["currency"] = currency.strip() if currency else ""
item["units"] = units.strip() if units else ""
item["coin"] = coin.strip() if coin else ""
item["tsp"] = tsp.strip() if tsp else ""
item["csp"] = csp.strip() if csp else ""
item["tbp"] = tbp.strip() if tbp else ""
item["cbp"] = cbp.strip() if cbp else ""
item["date"] = date.strip() if date else ""
yield item1.4 setting.py部分:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
}#打开请求头
AUTOTHROTTLE_ENABLED = True
ITEM_PIPELINES = {
'demo5.pipelines.CmbPipeline': 300,
}#打开pipelines1.5 pipelines.py部分:
1.5.1创建数据库,写入数据库,关闭数据库:
#打开数据库的方法
def openDB(self):
self.con = sqlite3.connect("cmbchina.db")
self.cursor = self.con.cursor() # 创建一个游标对象
try:#创建表
self.cursor.execute(" create table cmbchina (交易币 varchar(12) primary key,交易币单位 varchar(12),基本币 varchar(12),现汇卖出价 varchar(20),现钞卖出价 varchar(20),现汇买入价 varchar(20),现钞买入价 varchar(20),时间 varchar(20))")# 创建格式
except Exception as err:
print(err) #插入数据的方法
def insert(self, currency,unit,coin,tsp,csp,tbp,cbp,date):
try:#插入操作
self.cursor.execute("insert into cmbchina (交易币,交易币单位,基本币,现汇卖出价,现钞卖出价,现汇买入价,现钞买入价,时间) values (?,?,?,?,?,?,?,?)",(currency,unit,coin,tsp,csp,tbp,cbp,date))
except Exception as err:
print(err) #关闭数据库的方法
def closeDB(self):
self.con.commit()
self.con.close()1.5.2open_spider函数在开始执行项目时会执行一次:
def open_spider(self, spider):
print("opened")
self.db = cmbDB()
self.db.openDB()1.5.3插入数据操作并输出:
def process_item(self, item, spider):
try:
print(item["currency"],item["units"],item["coin"],item["tsp"],item["csp"],item["tbp"],item["cbp"],item["date"])
#输出操作
self.db.insert(item["currency"], item["units"], item["coin"], item["tsp"],
item["csp"], item["tbp"], item["cbp"], item["date"])
#插入操作
except Exception as err:
print(err)
return item1.5.4close_spider类在结束项目时会执行一次,断开数据库链接。
def close_spider(self, spider):
self.db.closeDB()
print("closed")输出结果:

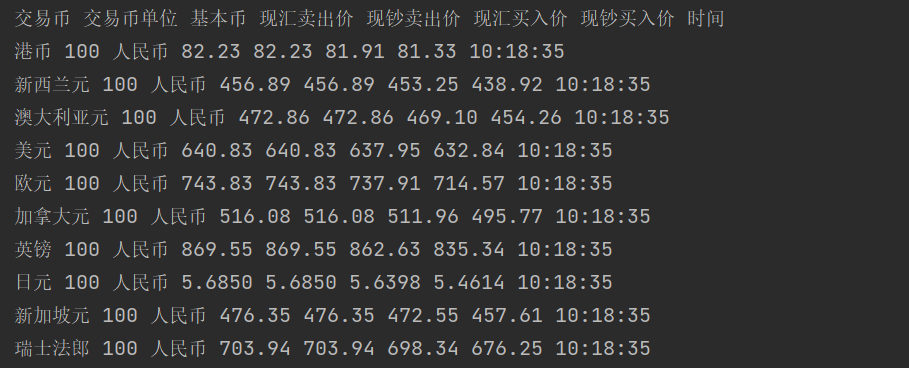
2.心得体会:
此题与第一题相比较简单,并且少了翻页操作。
需要注意的是在定位时要忽略tbody标签。
作业③:
题目:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网
输出信息:数据库存储和输出格式如下,由同学们自行定义设计表头:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 成交量 | 最高 | 最低 | 今开 | 昨收 |
| 1 | 688093 |
N世华 |
28.47 | 62.22% | 26.13万 | 32.0 | 28.08 | 30.2 | 17.5 |
| 2 | …… | …… | …… | …… | …… | …… | …… | …… | …… |
完整代码:码云作业3
1.解题代码:
1.1准备工作
def startUp(self, url):
chrome_options = Options()
# chrome_options.add_argument("——headless")
# chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(chrome_options=chrome_options)
#声明配置的浏览器
try:
self.con = sqlite3.connect("shares.db")#连接数据库
self.cursor = self.con.cursor()
#创建表
self.cursor.execute("create table shares (股类 varchar(20),序号 varchar(20), 股票代码 varchar(30),股票名称 varchar(30),最新报价 varchar(32),涨跌幅 varchar(12),成交量 varchar(12),最高 varchar(12),最低 varchar(12),今开 varchar(12),昨收 varchar(12))")
except Exception as err:
print(err)
self.driver.get(url)![]()
1.2查看网站信息,编写爬取代码。
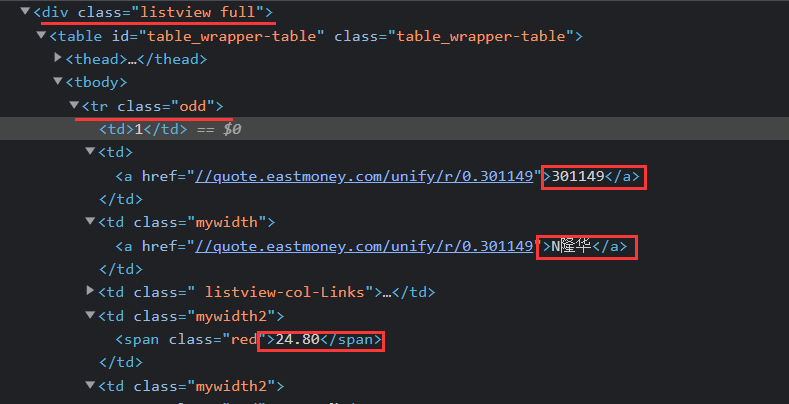
爬取股票类型时,定位如下位置:
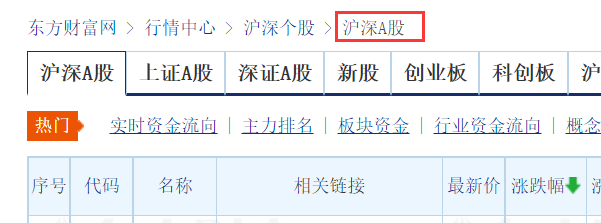
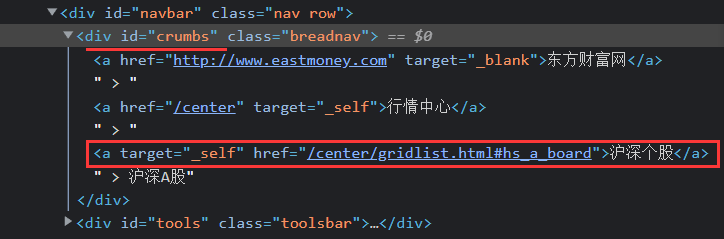
对应的网页信息如下:
总体代码:
lis = self.driver.find_elements_by_xpath("//div[@class='listview full']/table/tbody/tr")
type= self.driver.find_element_by_xpath("//div[@id='crumbs']").text.split(" ")[-1]
# 获得股票类型
# 共有三类:即沪深A股、上证A股、深证A股。
for li in lis:
td=li.find_elements_by_xpath("./td")
code = td[1].text #爬取股票代码
name = td[2].text # 爬取股票名称
price = td[4].text # 爬取最新报价
fu = td[5].text # 爬取涨跌幅
number = td[7].text # 爬取成交量
most = td[9].text # 爬取最高
least = td[10].text # 爬取最低
today = td[11].text # 爬取今开
yesterday = td[12].text # 爬取昨收
self.No = self.No + 1
if self.No%40==0:
break
no = str(self.No)
while len(no) < 4:
no = "0" + no # 序号格式化
self.insertDB(type,no,code,name,price,fu,number,most,least,today,yesterday) # 插入操作1.3插入函数:
def insertDB(self, type,no,code,name,price,fu,number,most,least,today,yesterday):
#插入操作
try:
sql = "insert into shares (股类,序号,股票代码,股票名称,最新报价,涨跌幅,成交量,最高,最低,今开,昨收) values (?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (type,no,code,name,price,fu,number,most,least,today,yesterday))
except Exception as err:
print(err)1.4在股票类型跳转操作时,使用函数实现鼠标点击。
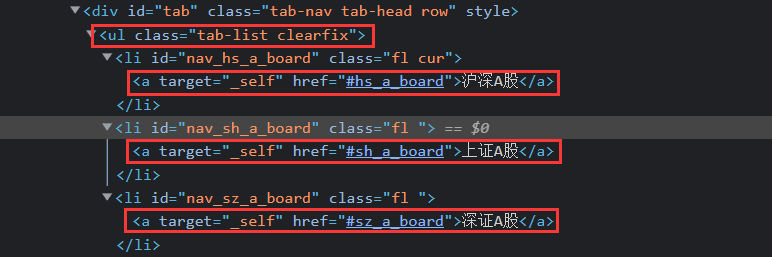
在翻页时会出现点击位置被覆盖从而点击错误,故采用
self.driver.execute_script("arguments[0].click();", nextshare)获取到元素后又短暂的一瞬间该元素是无法点击的,也可以理解为元素还没有加载完毕,此时可以强制等待。
time.sleep(2)if self.No % 40 == 0:# 三个股类的跳转操作
self.No = 0
self.num+=1
if self.num<4: #股类数量
try:
nextshare = self.driver.find_element_by_xpath(f"//ul[@class='tab-list clearfix']/li[position()={self.num}]/a")
self.driver.execute_script("arguments[0].click();", nextshare)
time.sleep(2) # 强制等待
self.processSpider()
except Exception as err:
print(err)
else:
return True # 在三个股类中跳转,超过即返回函数1.5同一种股票内的翻页操作:
![]()
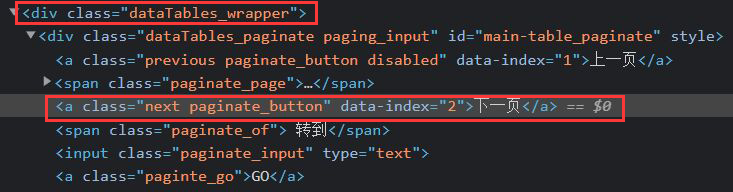
# 翻页操作
try:
nextPage = self.driver.find_element_by_xpath("//div[@class='dataTables_wrapper']//a[@class='next paginate_button']")
time.sleep(1) # 强制等待
nextPage.click() # 鼠标点击
self.processSpider()
except:
print("over")1.6函数的显示功能
def showDB(self):
#显示功能
try:
con = sqlite3.connect("shares.db") #连接数据库
cursor = con.cursor()
cursor.execute("select 股类,序号,股票代码,股票名称,最新报价,涨跌幅,成交量,最高,最低,今开,昨收 from shares")
#查询数据库
rows = cursor.fetchall()
#输出
for row in rows:
print(row[0], row[1], row[2], row[3], row[4],row[5],row[6],row[7],row[8],row[9],row[10])
con.close()
except Exception as err:
print(err)1.7函数的退出功能
def closeUp(self):#关闭
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)1.8输出结果:(每类股票爬取39个)
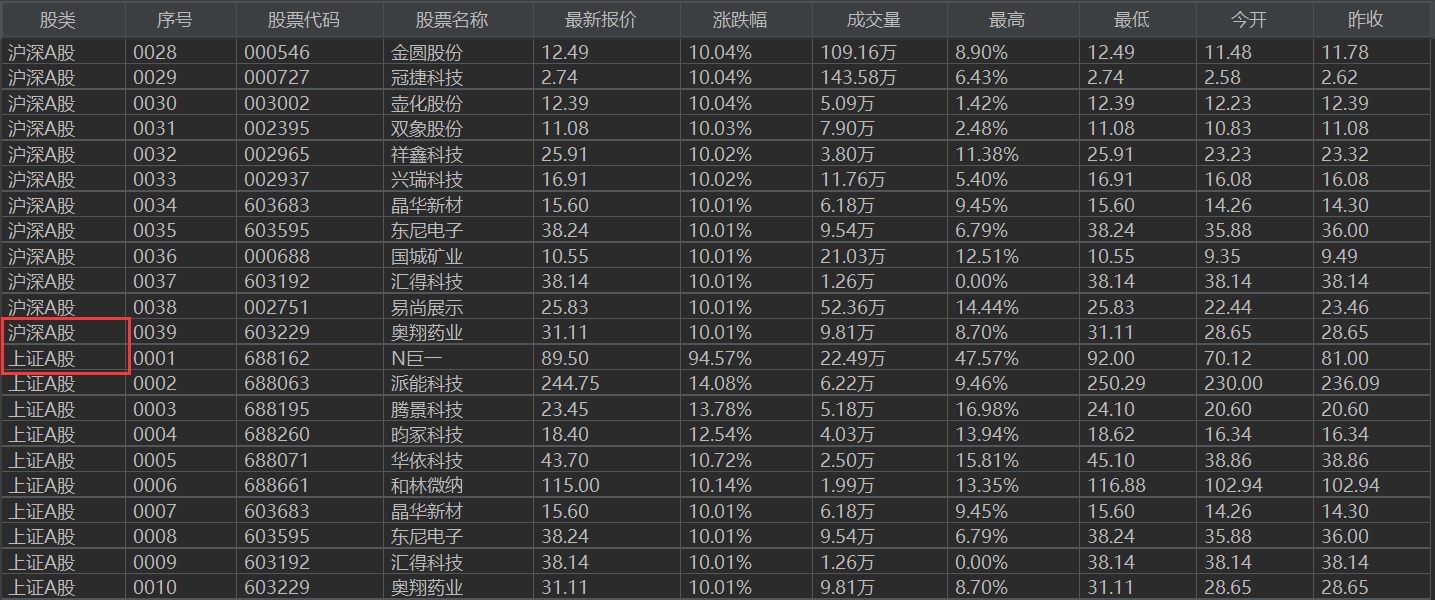
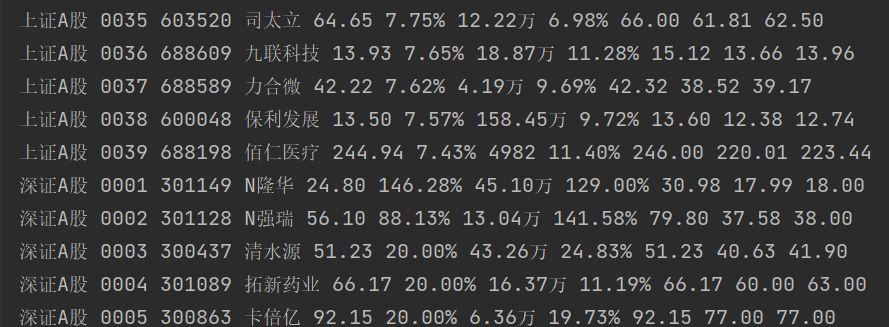
2.心得体会
(1) 通过本实验巩固了巩固了Selenium爬取网页的方法,并且更加熟悉了如何通过模拟浏览器鼠标点击行为进行翻页、切换页面操作。
(2)
问题:股票类型跳转时点击操作出现:
Message: element click intercepted:并且我尝试后发现如果没有翻页的话便不会出现此问题。
解决:查询后发现应该是翻页时会出现点击位置被覆盖从而点击错误,故加上了
self.driver.execute_script("arguments[0].click();", nextshare)
time.sleep(2)之所以加上time.sleep(2)是考虑到元素获取短暂的一瞬间还没有加载完毕。
(3)还有就是在find_element_by_xpath和find_elements_by_xpath之间要注意区分,不然会报错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号