
数据采集技术第二次作业
作业①:
题目:在中国气象网爬取给定城市集的7日天气预报,并保存在数据库中。输出信息如下:
| 序号 | 地区 | 日期 | 天气 | 温度 |
| 1 | 北京 | 7日(今天) | 晴间多云 | 31℃/17℃ |
| 2 | 北京 | 8日(明天) | 多云转晴 | 34℃/20℃ |
| 3 | 北京 | 9日(后天) | 晴转多云 | 36℃/22℃ |
| 4 | …… | …… | …… | …… |
完整代码:码云作业1
1.解题过程:
1.1:主函数部分
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
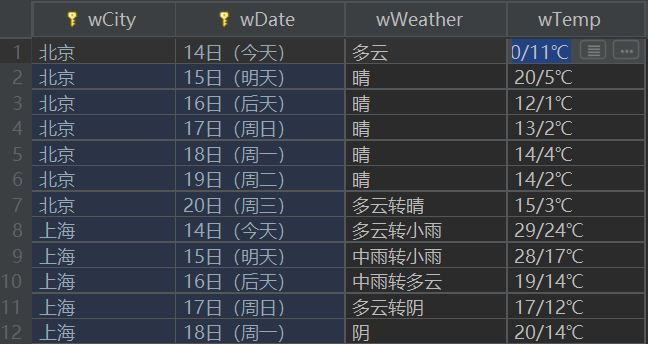
print("completed")1.2:建立并保存数据库
class WeatherDB:
#打开数据库
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
#创建格式
except:
self.cursor.execute("delete from weathers")1.3:获取网页
class WeatherForecast:
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)#发送请求
data = data.read().decode('utf-8')#解析代码
soup = BeautifulSoup(data, "lxml")1.4:根据网页信息编写爬取代码
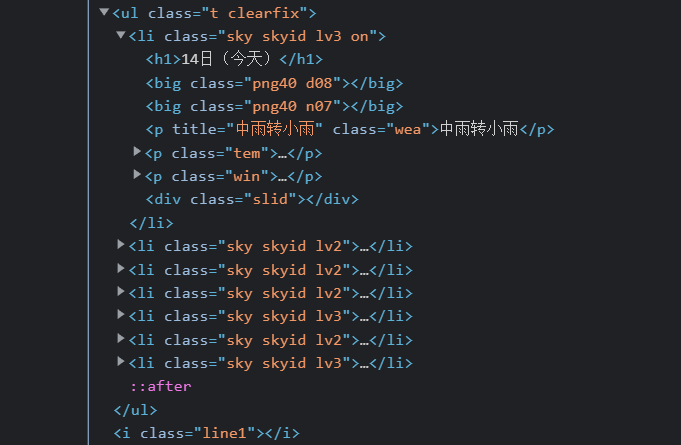
for li in lis:
try:
date = li.select('h1')[0].text #日期
weather = li.select('p[class="wea"]')[0].text # 天气
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text #温度
self.db.insert(city, date, weather, temp)
#插入至数据库weathers.db加入数据库代码如下:
#加入元组
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",(city, date, weather, temp))
except Exception as err:
print(err)1.5:输出信息
#打印数据
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
i=1#序号
tplt = "{:4}\t{:10}\t{:14}\t{:24}\t{:16}"
print(tplt.format("序号","地区", "日期", "天气信息", "温度"))
#输出格式
for row in rows:
print(tplt.format(i,row[0], row[1], row[2], row[3]))
i+=1 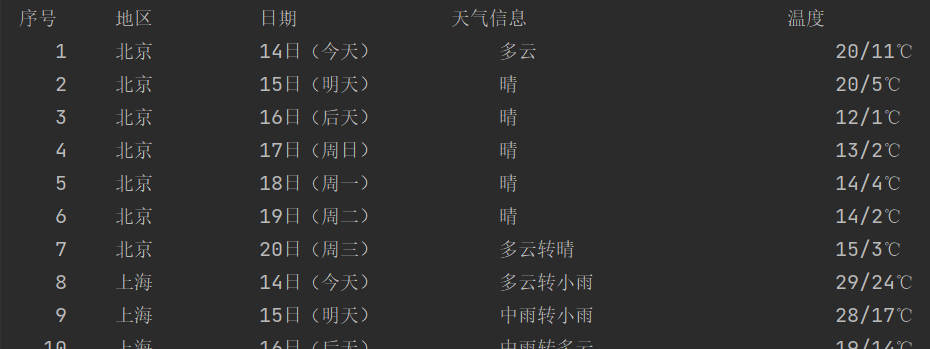
2.心得体会
本实验让我进一步巩固了对BeautifulSoup库的理解和使用,并接触了数据库的建立和使用。
作业②:
题目:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。参考链接
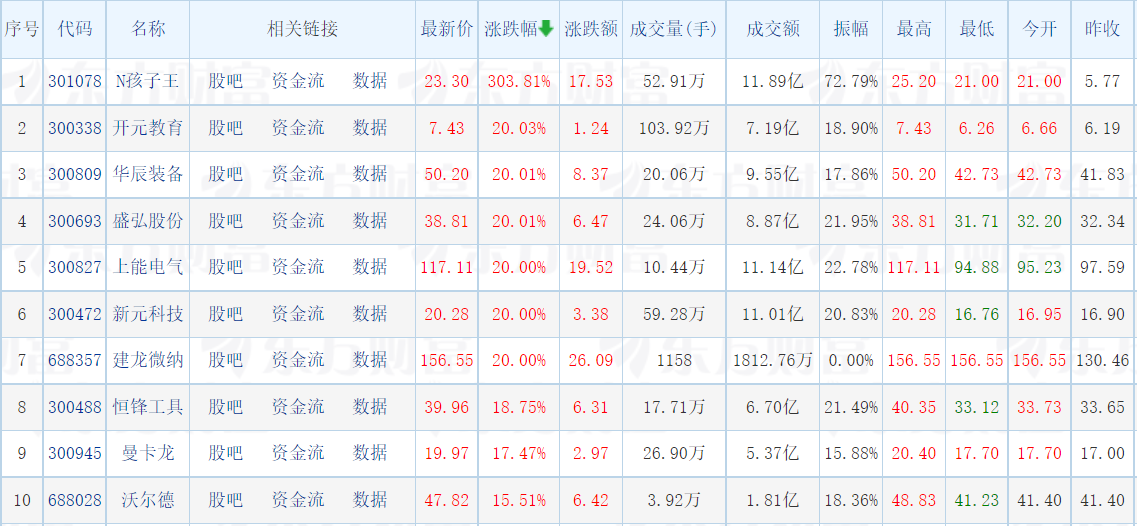
输出信息如下:
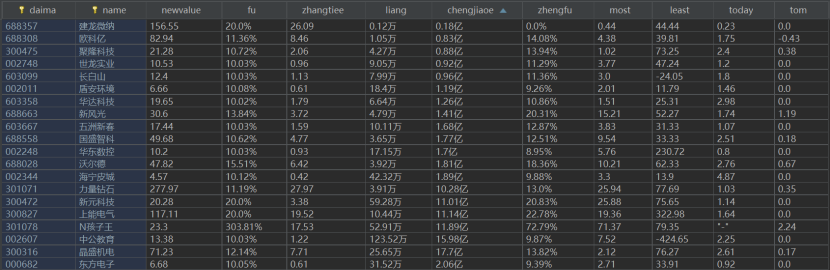
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.3% | 32.0 | 28.08 | 30.2 | 17.55 |
| …… | …… | …… | …… | …… | …… | …… | …… | …… | …… | …… | …… | …… |
完整代码:码云作业2
1.解题过程:
1.1:主函数部分
ws = share()
ws.process()
print("completed")1.2:建立并保存数据库
class shareDB:
#打开数据库
def openDB(self):
self.con=sqlite3.connect("share.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table share (daima varchar(10),name varchar(16),newvalue varchar(12),fu varchar(32),zhangtiee varchar(10),liang varchar(16),chengjiaoe varchar(16),zhengfu varchar(10),most varchar(10),least varchar(10),today varchar(10),tom varchar(10),constraint pk_weather primary key (daima,name))")
#创建格式
except:
self.cursor.execute("delete from share")1.3:获取网页
class share:
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36"}
def forecastCity(self):
for i in range(1, 3):
url = "http://84.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124028409701949327015_1634088183070&pn=" + str(i) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1634088183071"
reponse = requests.get(url, headers=self.headers)#发送请求
result = reponse.text1.4:根据网页信息编写爬取代码
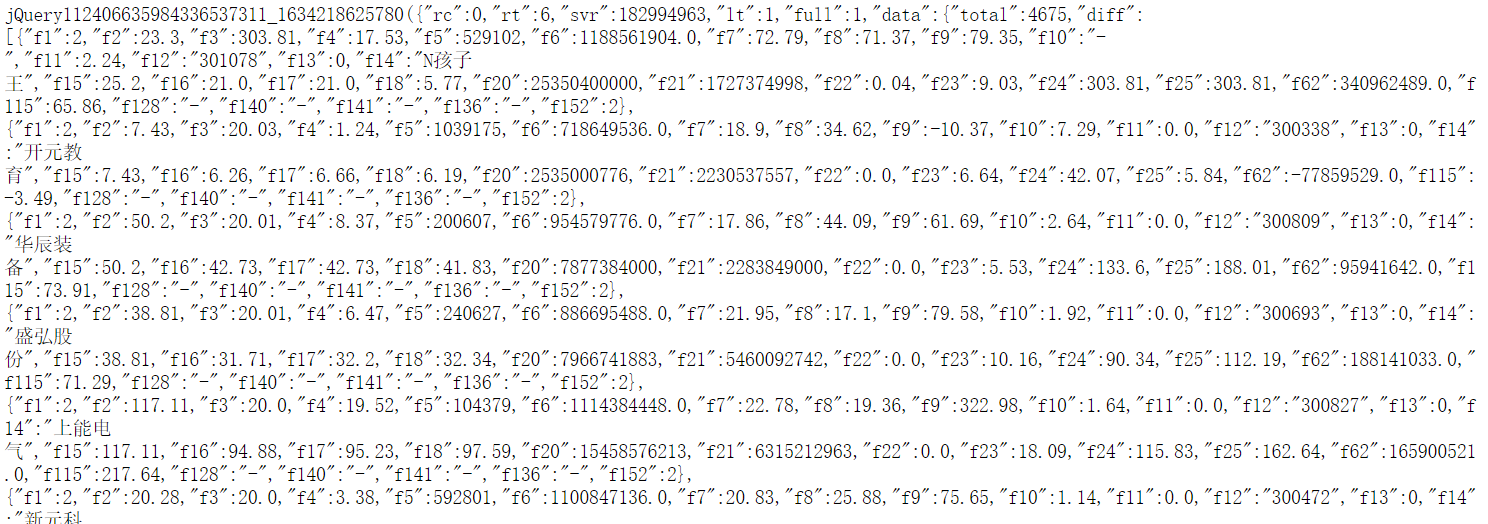
for item in re.findall(r"\{\"f1(.*?)\}", result, re.S):
sdaima = re.findall(r"f12\":\"(.*?)\"", item)#股票代码
sname = re.findall(r"f14\":\"(.*?)\"", item)#股票名称
snewvalue = re.findall(r"f2\":(.+?),", item)#最新报价
sfu = re.findall(r"f3\":(.*?),", item)#涨跌幅
szhangtiee = re.findall(r"f4\":(.*?),", item)#涨跌额
sliang = re.findall(r"f5\":(.*?),", item)#成交量
schengjiaoe = re.findall(r"f6\":(.*?),", item)#成交额
zhengfu = re.findall(r"f7\":(.*?),", item)#振幅
smost = re.findall(r"f8\":(.*?),", item)#最高
sleast = re.findall(r"f9\":(.*?),", item)#最低
stoday = re.findall(r"f10\":(.*?),", item)#今开
stom = re.findall(r"f11\":(.*?),", item)#昨收
self.db.insert(sdaima[0], sname[0], snewvalue[0], sfu[0]+"%", szhangtiee[0], str(round(float(sliang[0])/10000,2))+"万", str(round(float(schengjiaoe[0])/100000000,2))+"亿",szhengfu[0]+"%", smost[0], sleast[0], stoday[0], stom[0])
#加入元组1.5:输出信息
#打印数据
def show(self):
self.cursor.execute("select * from share")
rows = self.cursor.fetchall()
i=1
tplt = "{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}"
print(tplt.format("序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"))
#设置输出格式
for row in rows:
print(tplt.format(i,row[0], row[1], row[2], row[3],row[4], row[5], row[6], row[7],row[8], row[9], row[10], row[11],chr(12288)))
i+=1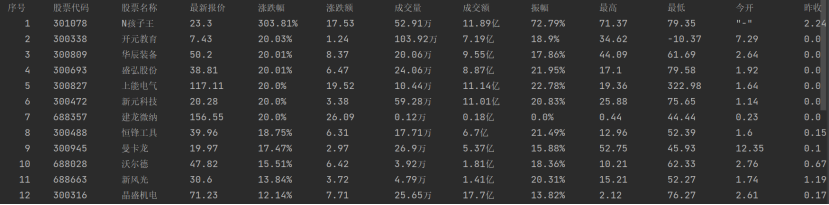
2.心得体会
本实验用f12获取股票这种动态数据的信息,与以往的在html中直接爬取都有所不同。
作业③:
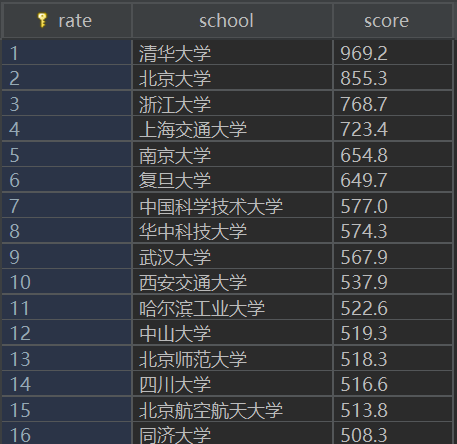
题目:爬取中国大学2021主榜所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api。
输出信息如下:
| 排名 | 学校 | 总分 |
| 1 | 清华大学 | 969.2 |
完整代码:码云作业3
1.解题过程:
1.1:主函数部分
ws = school()
ws.process()
print("completed")1.2:建立并保存数据库
class schoolDB:
#打开数据库
def openDB(self):
self.con=sqlite3.connect("school.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table school (rate varchar(10),school varchar(10),score varchar(10),constraint pk_school primary key (rate))")
# 创建格式
except:
self.cursor.execute("delete from school")1.3:获取网页
class school:
def fore(self):
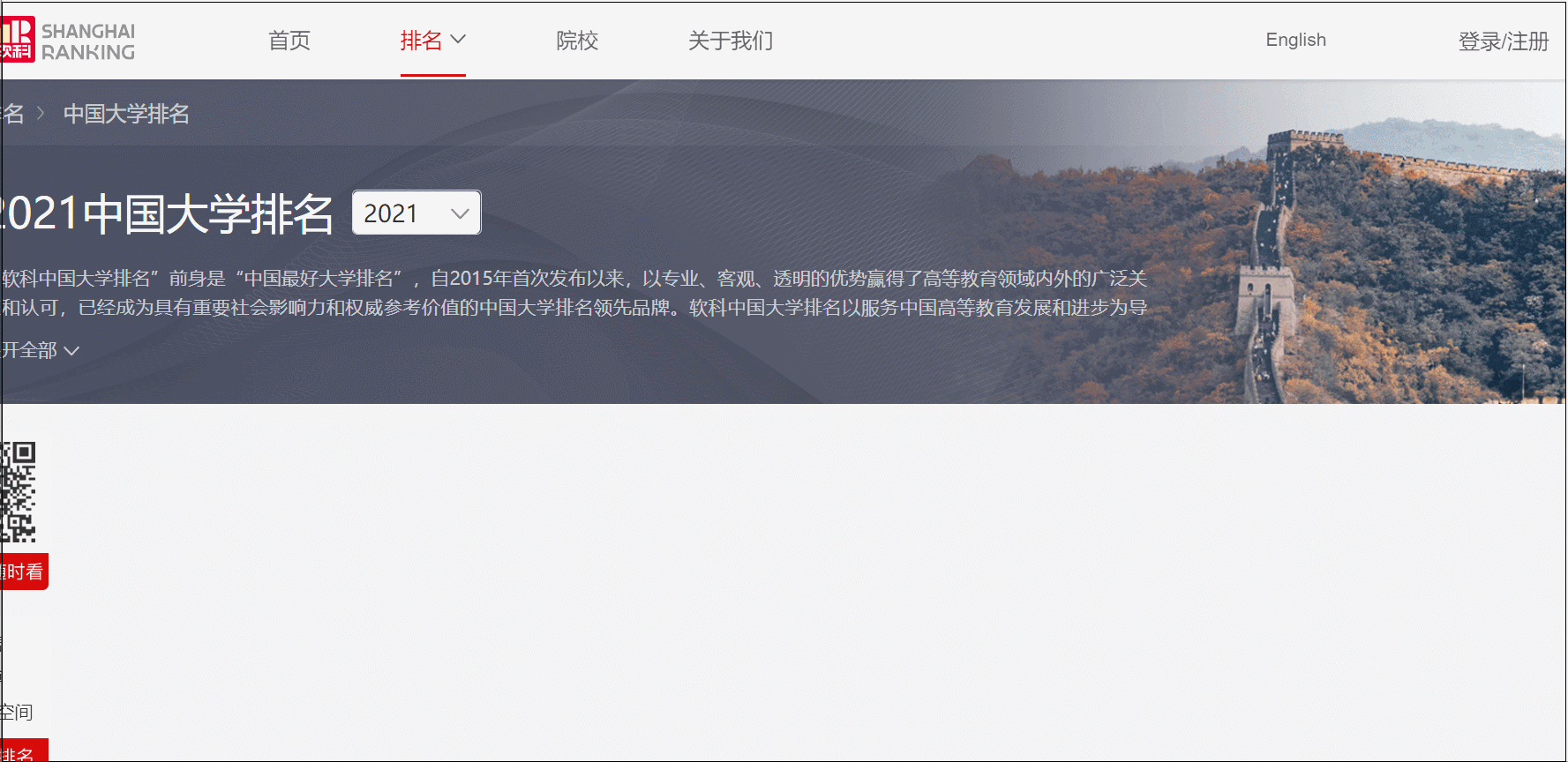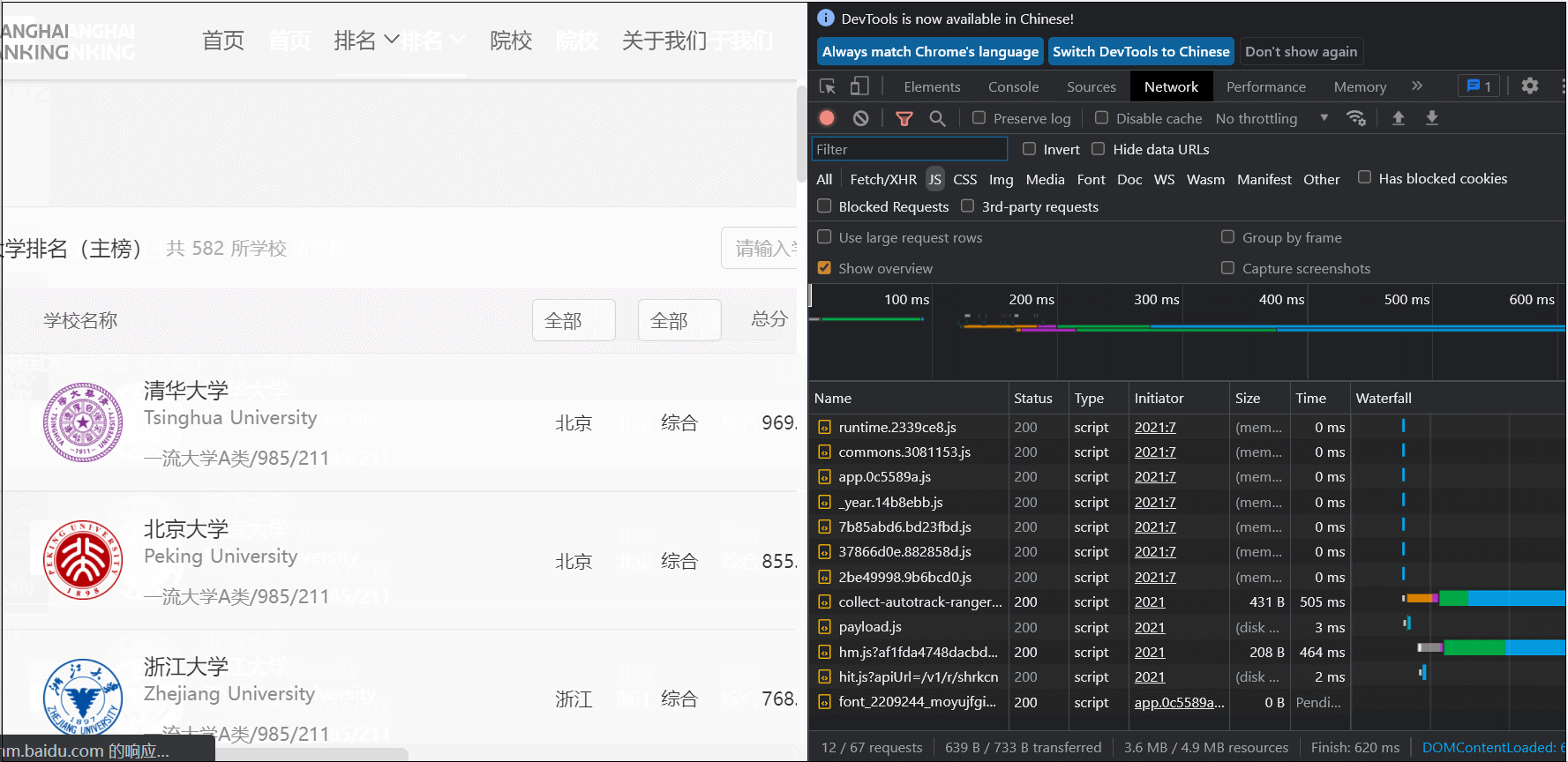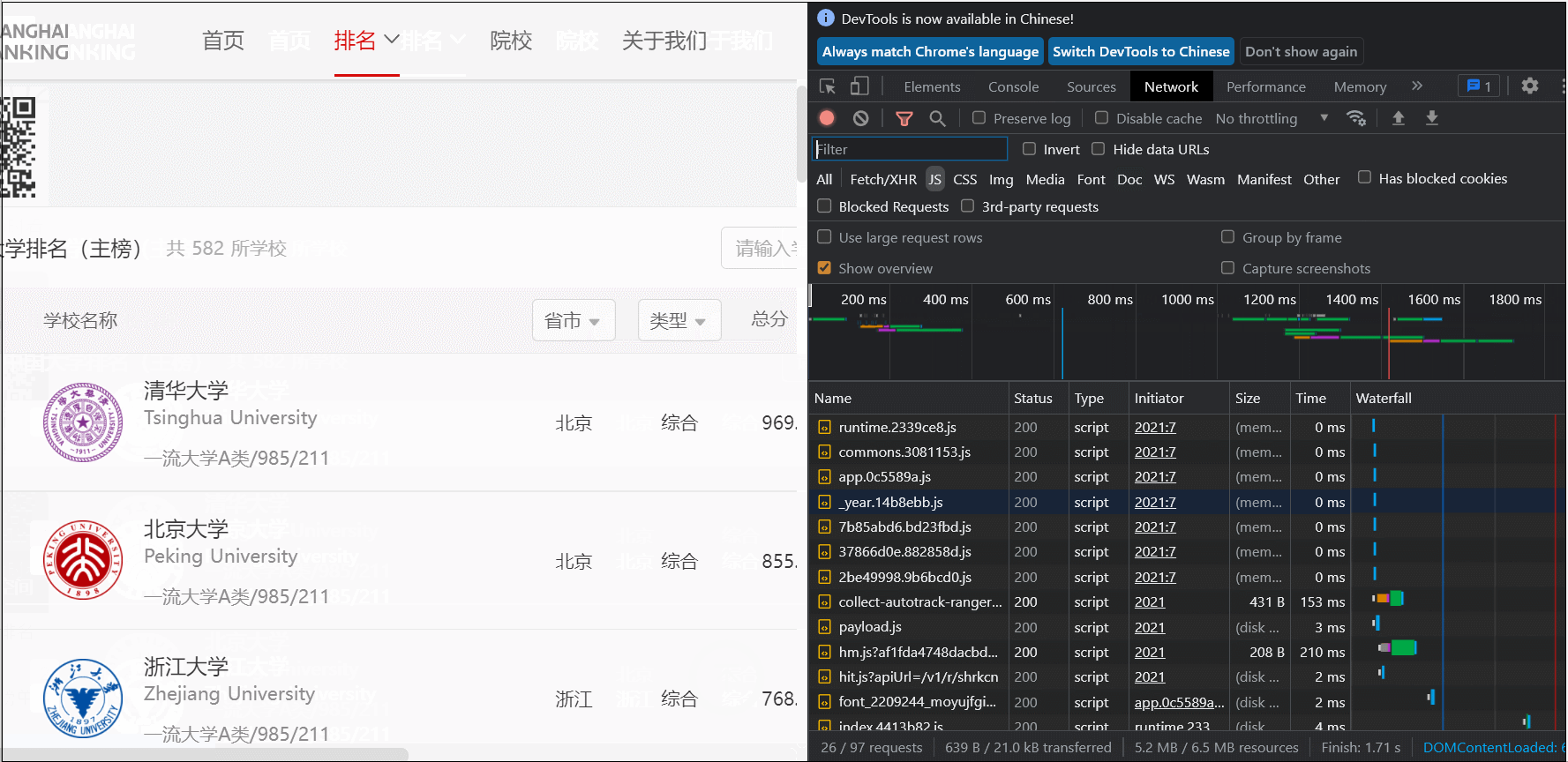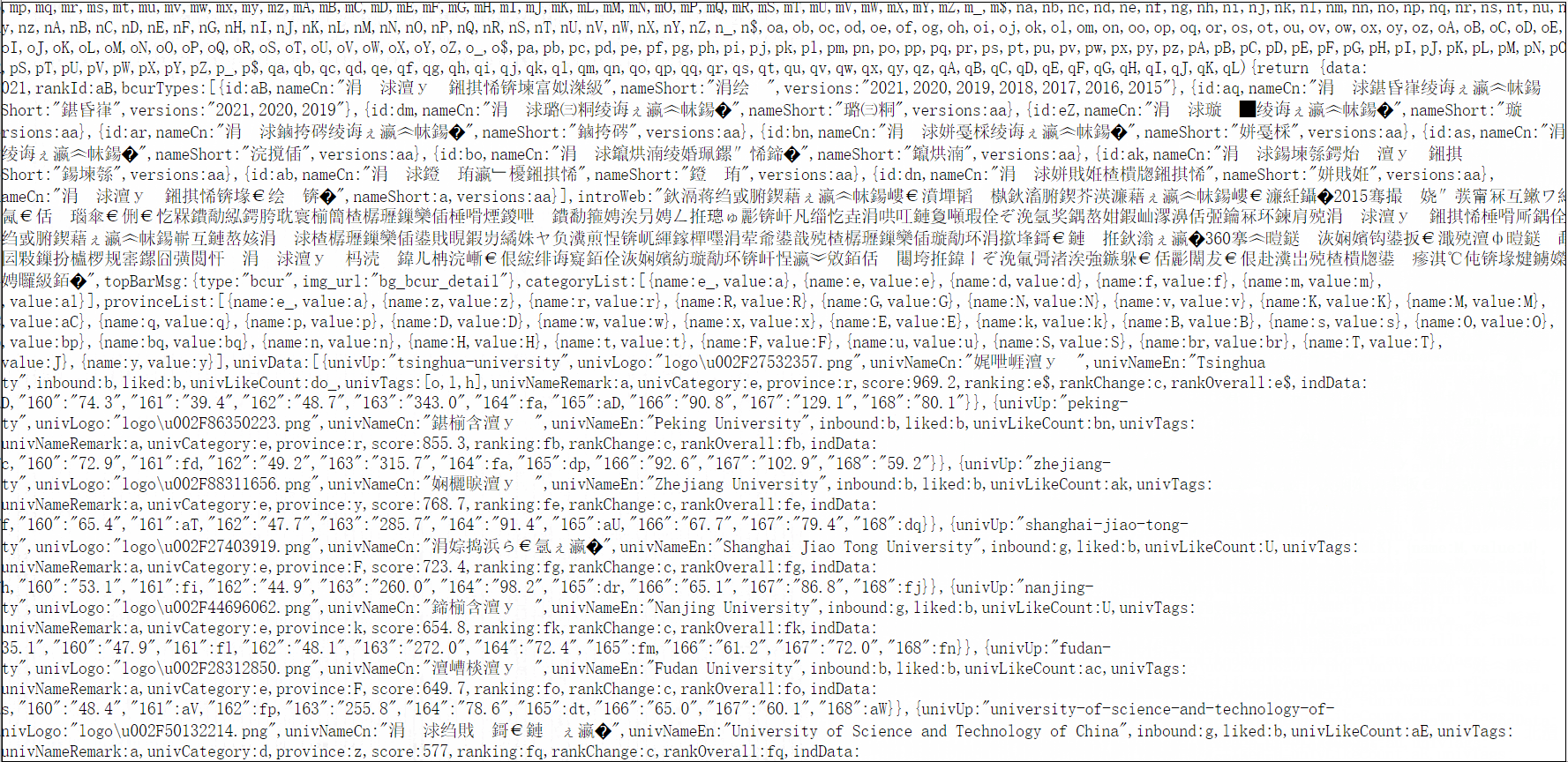
url = "https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/2021/payload.js"
reponse = requests.get(url) # 发送请求
result = reponse.text1.4:根据网页信息编写爬取代码
i=1
for item in re.findall(r"univUp(.*?)}", result, re.S):
school = re.findall(r"univNameCn:\"(.*?)\"", item)
score = re.findall(r"score:(.*?),", item)
self.db.insert(i, school[0], score[0])#加入元组
i+=11.5:输出信息
#打印数据
def show(self):
self.cursor.execute("select * from school")
rows = self.cursor.fetchall()
tplt = "{0:^8}\t{1:{3}^15}\t{2:<15}"
print(tplt.format("排名","学校", "总分",chr(12288)))
#设置输出格式
for row in rows:
print(tplt.format(row[0], row[1], row[2],chr(12288)))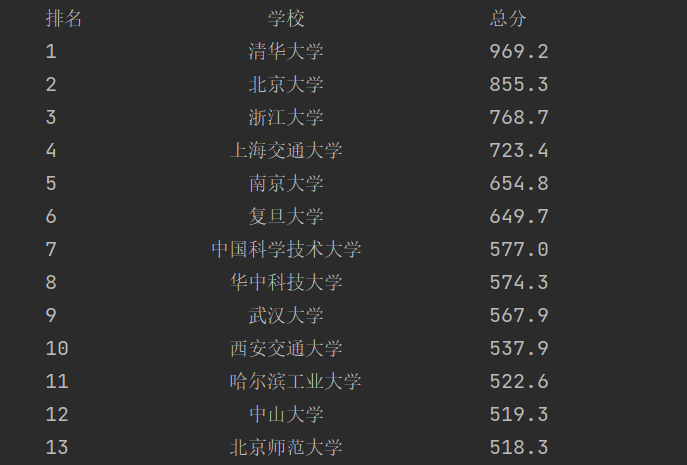
2.心得体会
本实验我进一步掌握f12抓包操作,而且在过程中要注意存入数据库的数据是否有缺少的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号