

快速构建一套集群架构
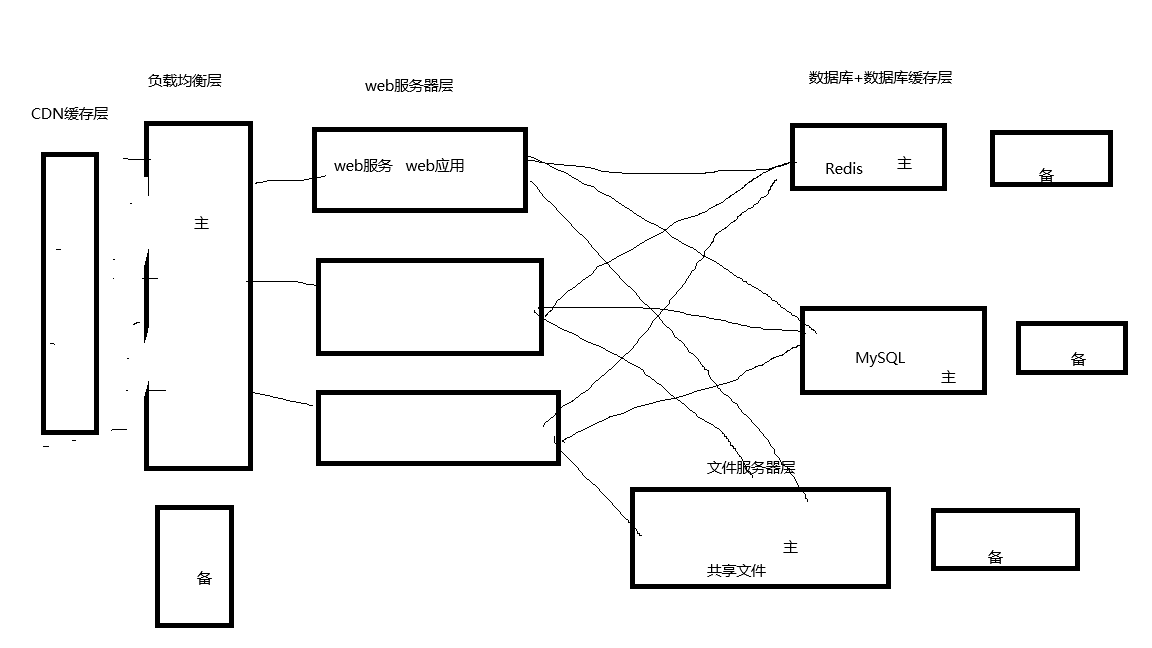
为什么会衍变这么多层?
用户的访问量在不停的增加,集群的性能不足了,一套集群架构除了考虑性能之外还应该考虑高可用性(每一层都要演变层一个小集群)。
五层架构-数据库与数据库缓存层详解
MySQL、Oracle、DB2、SQL、Server、Mariadb....
关系型数据库,数据与数据之间是有关联性的(以一张一张表去存的,组织好了数据关系)
create table user(name varchar(15),age int gender varchar(6));
关系型数据库特点:数据库组织好数据之间的关系,数据的读取都在硬盘
关系型数据库的优缺点:
优点:方便了应用程序在开发的过程当中关于数据怎么组织就变得简单了,应用程序开发的复杂度低
缺点:数据的存取速度相对慢一些
Redis、Memcache....
key=value的形式,数据跟数据之间没有很强的关联性,存非常简单,取的时候
name="zrg" age=31 gender="male"
非关系型数据库特点:数据库没有组织好数据之间的关系,存取都在内存中
非关系型数据库的优缺点:
优点:数据库本身设计复杂度低+内存读写---->读写速度非常快
缺点:应用程序开发的复杂度高(应用程序需要自己组织数据的关系)
**数据库与数据库缓存层详解** 在数据库技术体系中,数据库类型可分为关系型数据库和非关系型数据库两大类,各自具备独特的设计理念、应用场景及优缺点。本文将深入探讨这两类数据库的核心特性,并结合数据库缓存层的作用,帮助读者全面理解其技术原理与使用场景。 --- ### **一、关系型数据库:以结构化关系为核心** 关系型数据库(Relational Database)是建立在关系模型基础上的数据库系统,典型代表包括MySQL、Oracle、DB2、SQL Server和Mariadb等。这类数据库以“表”(Table)作为基本存储单元,通过行(Row)和列(Column)组织数据,并利用主键(Primary Key)、外键(Foreign Key)等机制建立数据之间的关联关系。例如,创建用户表的SQL语句如下: ``` CREATE TABLE user ( id INT PRIMARY KEY, -- 主键,唯一标识每条记录 name VARCHAR(15) NOT NULL, age INT, gender VARCHAR(6), address TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); ``` **特点与核心机制:** 1. **数据结构化与关联性强**:数据按照预先定义的表结构存储,支持复杂的表间关联(如一对一、一对多、多对多),通过JOIN操作实现跨表数据查询。例如,用户表和订单表可以通过用户ID关联,方便获取用户的订单信息。 2. **事务支持(ACID特性)**:保证数据的原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。例如,银行转账操作中,扣款和存款必须同时成功或同时失败,避免数据不一致。 3. **SQL语言标准化**:支持结构化查询语言(SQL),提供强大的数据增删改查(CRUD)能力,以及聚合、排序、分组等复杂操作。例如,`SELECT * FROM user WHERE age > 30` 可筛选年龄大于30岁的用户。 **优缺点分析:** - **优点**: - **数据组织严谨**:适合需要强数据一致性和复杂关联查询的场景,如企业ERP系统、财务系统等。 - **开发友好**:应用程序可通过简单的SQL语句快速获取结构化数据,降低开发复杂度。 - **成熟生态系统**:拥有丰富的第三方工具(如可视化工具、备份恢复工具)和社区支持。 - **缺点**: - **性能瓶颈**:硬盘读写速度较慢,面对高并发读写或海量数据时,响应延迟较高。 - **扩展性受限**:传统关系型数据库在横向扩展(分布式部署)上存在挑战,需依赖复杂的集群方案(如MySQL的主从复制、分库分表)。 - **模式灵活性差**:表结构一旦确定,修改需要谨慎处理,可能影响现有应用逻辑。 --- ### **二、非关系型数据库:灵活与高性能的权衡** 非关系型数据库(NoSQL,Not Only SQL)突破了传统关系模型的限制,以更灵活的数据存储方式应对特定场景需求。常见类型包括键值存储(Redis、Memcache)、文档数据库(MongoDB)、列式存储(Cassandra)、图数据库(Neo4j)等。以键值存储为例,数据以简单的`key-value`形式存在: ``` name="zrg" age=31 gender="male" ``` **特点与核心机制:** 1. **弱化数据关联,强调高性能**:数据独立存储,无需复杂关联,适合高并发读写场景。例如,用户登录时频繁读取用户信息,可直接通过用户ID(key)快速获取。 2. **数据模型灵活**:支持非结构化或半结构化数据(如JSON、XML),无需预定义模式。例如,用户地址信息可灵活扩展,无需修改表结构。 3. **分布式与可扩展性**:多数NoSQL数据库天然支持分布式架构,通过数据分片(Sharding)和副本机制实现高可用与横向扩展。 **优缺点分析:** - **优点**: - **极致性能**:数据存储在内存或利用高效的数据结构(如Redis的哈希表),读写速度远超关系型数据库。 - **高扩展性**:轻松应对海量数据与高并发场景,适用于实时数据分析、缓存层、消息队列等。 - **灵活适应需求变化**:无需固定模式,快速适应业务迭代,如社交平台用户动态扩展属性。 - **缺点**: - **复杂开发逻辑**:应用程序需自行处理数据关联(如用户与订单的关系需通过代码维护),增加开发难度。 - **事务支持较弱**:部分NoSQL数据库不支持ACID特性,可能导致数据一致性风险。 - **生态系统相对不成熟**:工具链和社区支持不如关系型数据库完善,需更多自定义开发。 --- ### **三、数据库缓存层:性能优化的关键环节** 在实际应用中,为平衡关系型数据库的稳定性和非关系型数据库的高性能,常引入缓存层作为中间层。典型架构如下: ``` 应用程序 → 数据库缓存层(Redis/Memcache) → 关系型数据库 ``` **缓存层的作用与原理:** 1. **热点数据加速**:将高频访问的数据(如用户登录信息、商品列表)提前加载到内存缓存中,减少数据库访问压力。例如,用户访问个人主页时,直接从Redis获取用户信息,避免查询数据库。 2. **读写分离**:缓存层承担大部分读请求,写操作仍同步到数据库,通过异步机制更新缓存(如延迟双删策略)。 3. **降低数据库负载**:通过缓存层的过滤,减少无效或低频查询,提升整体系统吞吐量。 **关键技术点:** - **缓存淘汰策略**:LRU(最近最少使用)、LFU(最不经常使用)等算法,自动淘汰冷数据,维持缓存容量。 - **缓存一致性**:通过过期时间(TTL)、消息队列通知或数据库订阅机制,确保缓存与数据库数据同步。 - **分布式缓存**:利用Redis Cluster或Memcache集群,实现缓存的高可用与水平扩展。 **应用场景示例:** - 电商平台:商品详情页缓存,减少数据库查询压力。 - 社交平台:用户会话信息缓存,提升登录与交互体验。 - 实时数据分析:将中间结果缓存,加速后续计算流程。 --- ### **四、关系型 vs 非关系型:如何选择?** 在实际应用中,数据库选型需综合业务需求、数据特性、性能要求等因素: | **维度** | **关系型数据库** | **非关系型数据库** | | ------ |------ |------ | | 数据关联性 | 强,支持复杂关联查询 | 弱,数据独立存储 | | 应用场景 | 交易系统、企业核心数据 | 高并发场景、实时数据 | | 扩展性 | 垂直扩展为主,横向复杂 | 天然支持分布式扩展 | | 性能瓶颈 | 硬盘读写延迟 | 内存访问速度快 | | 开发复杂度 | 低(SQL标准化) | 高(需自行处理关联) | **混合架构实践:** 许多企业采用“关系型数据库 + 非关系型数据库 + 缓存层”的混合方案,例如: - 核心交易数据(如订单、账户)存储在MySQL/Oracle,保证事务一致性。 - 用户行为日志、实时数据等存储在MongoDB或Cassandra。 - 高频访问数据通过Redis缓存,提升响应速度。 --- ### **五、总结与展望** 数据库技术正随着云计算、大数据和实时应用场景的发展不断演进。关系型数据库与非关系型数据库并非对立,而是互补。未来趋势包括: - **NewSQL数据库**:融合关系型事务与非关系型性能,如TiDB、CockroachDB。 - **云原生数据库**:AWS Aurora、阿里云PolarDB等,通过云基础设施实现弹性扩展与高可用。 - **多模数据库**:支持多种数据模型(如文档+键值),降低应用开发复杂度。 理解数据库与缓存层的设计原理,将帮助开发者在架构设计时做出更精准的选择,构建高性能、高可用的数据系统。 ---
五层架构-文件服务器层详解
给web应用层提供共享存储服务,相当于一块大网盘里面放着所有web程序共享的数据。
可以用nfs软件提供服务,nfs本身是有单点故障问题的,而且不支持集群,网站规模比较小的情况下,有一个nfs软件再结合一个rsync软件再来一个备份机,主机挂了还可以通过备份机来还原数据。
真正在用的时候都会用分布式存储,即把文件服务器层做成一个集群,比如ceph,当然还有其他的方案。
**文件服务器层详解:Web应用层的共享存储核心** 文件服务器层是Web应用架构中至关重要的一环,它为上层应用提供了一个集中式、高可用的数据存储空间,类似于一个容量巨大的“网络云盘”,用于存储所有Web程序所需的共享数据资源,如静态文件(图片、视频、文档)、动态生成的数据缓存、用户上传的文件、系统配置信息等。
这一层的设计直接关系到Web应用的稳定性、扩展性及数据安全性,其核心目标是在多服务器环境下实现数据的一致性访问与高效共享。 **1. 基础架构与NFS服务** 在中小型网站或传统企业应用中,文件服务器层常采用NFS(Network File System)协议来实现。NFS是一种基于TCP/IP的分布式文件系统协议,允许客户端通过网络直接访问服务器上的文件系统,如同操作本地磁盘一样。
其优势在于部署简单、跨平台支持(Linux/Unix/Windows均可兼容),且能实现文件级的共享访问,适合需要频繁读写共享数据的场景。 然而,NFS存在明显的局限性:**单点故障风险**。当NFS服务器宕机或网络中断时,所有依赖该服务器的应用都将无法访问数据,导致服务中断。此外,NFS本身不支持集群化部署,无法通过横向扩展提升性能或容错能力。为解决这些问题,实践中常采用以下方案: - **Rsync+备份机组合**:在NFS主服务器之外部署一台备份机,利用Rsync(Remote Sync)工具定期或实时同步主服务器的数据。Rsync通过差异同步算法,仅传输变更部分,减少带宽消耗。当主服务器故障时,可快速切换至备份机接管服务,通过还原最近同步的数据恢复业务。这种方式成本低、实施简单,但存在数据延迟(同步频率影响数据一致性)和手动切换的运维负担,适用于对数据实时性要求不高的场景。 **2. 分布式存储集群:高可用与扩展性解决方案** 随着Web应用规模的扩大(如高并发访问、海量数据存储、多地域部署需求),传统NFS+备份机的方案难以满足需求。此时,分布式存储技术成为主流选择,它将文件服务器层构建为多节点集群,通过分布式算法实现数据冗余、自动故障转移和弹性扩展。 **2.1 分布式存储核心特性** - **数据分片与冗余**:文件被切分成多个数据块,分散存储在集群中的多个节点。例如,Ceph采用CRUSH算法智能分配数据块位置,并支持多副本机制(如3副本:一份数据存储在3个不同节点),任一节点故障时,其他副本可继续提供服务,确保数据不丢失。 - **自动故障检测与恢复**:集群管理系统实时监控节点状态,当检测到节点离线时,自动将失效节点的数据副本迁移至其他健康节点,无需人工干预。 - **横向扩展**:通过新增存储节点即可线性扩展存储容量和性能,支持PB级数据规模。 - **高性能访问**:通过并行读写多个节点,提升I/O吞吐量。例如,Ceph的RADOS(Reliable Autonomic Distributed Object Store)架构允许客户端直接与多个OSD(Object Storage Daemon)通信,避免传统集中式架构的瓶颈。 **2.2 典型分布式存储方案** - **Ceph**:开源分布式存储标杆,支持对象存储(RADOSGW)、块存储(RBD)和文件系统(CEPHFS)三种接口,广泛应用于云平台和企业级场景。其高扩展性和自愈能力使其成为替代传统NFS的优选方案。 - **HDFS(Hadoop Distributed File System)**:与大数据生态紧密集成,适合处理离线分析、大规模批处理任务,但实时性稍弱。 - **GlusterFS**:通过模块化设计实现弹性扩展,支持多种数据分布策略(如复制、条带化),适合中小规模场景。 - **商业方案**:如NetApp、IBM Spectrum Scale等,提供更完善的企业级管理功能,但成本较高。 **3. 实际部署与优化策略** - **负载均衡与高可用设计**:在分布式存储集群前部署负载均衡器,将客户端请求均匀分发至各存储节点。结合Keepalived或HAProxy实现双机热备,避免负载均衡器单点故障。 - **网络优化**:采用高速网络(如10G/40G以太网或InfiniBand)减少传输延迟,利用RDMA技术提升I/O效率。 - **数据分层**:根据访问频率将数据分为热数据(SSD)、温数据(HDD)、冷数据(归档),通过策略自动迁移,优化存储成本与性能。 - **安全加固**:部署访问控制(如Kerberos认证)、数据加密(如S3加密)、防火墙隔离,防止数据泄露或篡改。 **4. 未来趋势与挑战** - **云原生融合**:越来越多的企业将文件服务器层迁移至云平台(如AWS S3、阿里云OSS),利用云存储的无限扩展性和按量付费模式降低成本。容器化技术(如Kubernetes)也对存储接口提出更高动态适配要求。 - **边缘计算支持**:随着物联网和实时应用的普及,分布式存储需向边缘节点延伸,实现就近数据存储与低延迟访问。 - **AI驱动的运维**:利用机器学习监控存储集群健康状态,预测故障并自动优化配置参数。 **总结** 文件服务器层从简单的NFS共享到复杂的分布式集群演进,反映了Web应用对数据存储需求的不断升级。在选择技术方案时,需综合考量业务规模、性能需求、成本预算及运维能力:小型场景可采用NFS+备份机的轻量级方案;中大型应用则应优先部署分布式存储集群,通过技术冗余与自动化机制构建高可用、可扩展的数据基石。未来,随着云计算与边缘计算的深度融合,文件服务器层将进一步向智能化、弹性化方向发展。 --- **扩写说明**: 1. **内容扩展**:增加技术原理(如NFS机制、分布式存储核心特性)、实际部署策略(负载均衡、数据分层)、安全考量及未来趋势,使内容深度提升。 2. **结构优化**:分点分模块讲解,逻辑更清晰,便于读者理解。 3. **案例补充**:列举具体技术选型(Ceph、HDFS、GlusterFS)及对比,增强实用性。 4. **语言丰富**:加入专业术语解释(如CRUSH算法、RDMA)和场景化描述,平衡技术性与可读性。
五层架构-web层详解
具体部署软件的地方,软件有不同的编程语言开发的,主要有python、java、php和go,开发出来一定包含两部分web服务部分(都是相对固定的功能,无非就是建网络链接无非是跟tcp协议打交道、解析一些协议,用现成的就行)和web应用部分(这部分需要我们自己写处理业务逻辑)。
服务负责接受网络请求,解析协议;应用负责业务逻辑,跟数据库打交道。
web层通常还会在web服务前面加一个nginx,nginx就是一个套接字软件,负责接受网络请求,解析网络协议,本身也是一个web服务,nginx非常强大可以带来诸多好处,可以起到缓冲压力的效果,提高性能,还可以写细分规则,动静分离,还可以做安全防护,日志管理,兼容各种协议,对外提供一种通用的协议(这样负载均衡层就非常灵活了)
总结好处:1、性能的提升;2、功能的增强;
发的协议一定要能被沿途的人都能看得懂才行,如果负载均衡层封装的请求协议是乱七八糟的协议,nginx识别不了这个包肯定就断掉了,处理不了,nginx能识别http协议,https协议
python
应用:自己用python开发、负责与数据库、数据库缓存通信
服务:uwsgi
java
应用:自己用java开发、负责与数据库、数据库缓存通信
服务:Tomcat Jboss weblogic
php
应用:自己用php开发、负责与数据库、数据库缓存通信
服务:php-fpm
go
应用+服务--->编译一个二进制文件里
**Web层详解:架构、部署与关键技术解析** Web层作为软件部署的核心层,是连接用户请求与后端服务的桥梁。不同编程语言(如Python、Java、PHP和Go)开发的Web应用虽然实现方式各异,但整体架构均遵循相似的逻辑:分为Web服务部分和Web应用部分,二者协同完成网络通信与业务处理。
本文将深入探讨Web层的各个组成部分、关键技术及其背后的设计原理。 **一、Web层的核心结构:服务与应用的协作** Web层软件通常分为两个核心模块:**Web服务部分**和**Web应用部分**。Web服务部分负责处理底层网络协议,其功能相对固定,主要包括: - **网络连接建立**:基于TCP/IP协议创建连接,管理客户端与服务器之间的通信通道; - **协议解析**:解析HTTP/HTTPS、WebSocket等应用层协议,提取请求头、请求体等关键信息; - **请求分发**:根据请求路径、方法(GET/POST等)将请求路由到对应的处理逻辑。 这些基础功能通常使用成熟的开源库或框架实现(如Python中的`socket`库、Java中的Netty框架),开发者无需从零开始编写,从而专注于上层逻辑。
**Web应用部分**则是业务逻辑的载体,负责处理具体的用户请求。例如: - **数据库交互**:通过SQL或NoSQL接口查询、写入数据; - **缓存管理**:与Redis、Memcached等缓存系统通信,提升响应速度; - **业务规则处理**:实现登录验证、订单处理、数据计算等复杂逻辑。 服务与应用的协作通常通过**进程间通信**(如IPC)或**协议接口**(如WSGI、FastCGI)实现。例如,Web服务接收请求后,将解析后的数据传递给应用层,应用层处理完成后返回响应,再由服务层封装并发送回客户端。 **二、Nginx:Web层的“瑞士军刀”** 在Web服务前端部署Nginx已成为行业标准,其强大功能为系统带来显著提升。以下是Nginx的核心作用与优势: 1. **高性能与压力缓冲** - **反向代理**:作为请求的“入口”,Nginx通过事件驱动模型(如epoll)高效处理大量并发连接,减少后端服务器的压力; - **静态资源处理**:直接响应图片、CSS、JavaScript等静态文件,无需调用应用服务器,大幅提升响应速度; - **连接池管理**:复用TCP连接,降低建立新连接的开销。 2. **灵活规则与动静分离** - **Location匹配**:通过正则表达式配置URL规则,实现精准的路由分发(如将动态请求转发给应用服务器,静态请求直接处理); - **负载均衡**:支持轮询、IP哈希等算法,将请求均匀分配到多台后端服务器,避免单点故障。 3. **安全防护与协议兼容** - **DDoS防护**:通过限制连接频率、请求速率抵御攻击; - **SSL/TLS终止**:在Nginx层处理HTTPS加密,减轻后端服务器的计算负担; - **协议转换**:将非标准协议(如HTTP/2、WebSocket)转换为后端兼容的协议(如HTTP/1.1),提升兼容性。 4. **日志与监控** - 实时记录访问日志、错误日志,支持ELK等日志分析系统接入; - 暴露状态监控接口(如HTTP API),便于第三方工具实时查看连接数、请求速率等性能指标。 **三、编程语言与Web服务组合:技术选型与适配** 不同语言在Web层的实现差异显著,以下详细解析各语言的典型部署方案: **Python**: - **应用开发**:使用Django、Flask等框架编写业务逻辑,通过ORM(如SQLAlchemy)操作数据库; - **Web服务**:uWSGI作为Python应用的“桥梁”,将WSGI协议转换为HTTP,支持多进程/线程管理,适配高并发场景; - **特点**:开发效率高,适合快速迭代,但需注意GIL(全局解释锁)对多线程性能的影响。 **Java**: - **应用开发**:Spring Boot、Spring MVC等框架主导,支持企业级复杂业务; - **Web服务**:Tomcat(轻量级)、JBoss(支持EJB)、WebLogic(企业级)等应用服务器集成Servlet容器,处理HTTP请求并调用Java代码; - **特点**:性能稳定,适合大型系统,但部署复杂度高,资源消耗较大。 **PHP**: - **应用开发**:Laravel、Symfony等框架流行,擅长动态页面生成; - **Web服务**:PHP-FPM(FastCGI进程管理器)独立处理PHP脚本,与Nginx通过UNIX套接字通信; - **特点**:与Web服务器耦合低,动态内容处理高效,但需定期优化内存管理。 **Go**: - **应用+服务一体化**:Go语言编写的Web应用可直接编译为二进制文件,同时包含业务逻辑和网络服务; - **优势**:高性能(协程支持)、跨平台部署、无需额外服务进程; - **框架示例**:Gin、Echo等提供路由、中间件等基础设施,简化开发。 **四、协议兼容性与系统稳定性** Web层的协议设计至关重要。负载均衡层与Nginx必须确保请求协议的标准化。例如: - **HTTP/HTTPS**:通用协议使各层设备(如CDN、防火墙)都能正确解析请求,避免通信中断; - **协议封装**:若负载均衡层使用自定义协议,需通过Nginx的模块扩展或第三方插件支持,否则可能无法被识别; - **TLS卸载**:在Nginx层终止HTTPS加密,后端应用服务器只需处理HTTP明文,降低CPU消耗。 **五、实践中的优化策略** 1. **缓存分层**:在Nginx使用`proxy_cache`缓存动态内容,减少应用服务器压力; 2. **健康检查**:配置Nginx定期检测后端服务器状态,自动剔除故障节点; 3. **请求限流**:通过`limit_req`模块限制每秒请求数,防止突发流量打垮系统; 4. **日志异步化**:使用`log_subrequest`将日志写入独立进程,避免阻塞请求处理。 **六、安全与扩展性考量** - **DDoS防护**:结合Nginx的`geoip`模块与黑名单策略,拦截恶意IP; - **WAF集成**:通过Nginx+Lua模块实现Web应用防火墙,过滤SQL注入、XSS攻击; - **微服务适配**:在云原生架构中,Nginx可作为API网关,统一处理服务发现、认证授权。 **七、总结** Web层是软件系统的“门面”,其设计直接影响用户体验与系统稳定性。通过合理的架构(如Nginx前置、动静分离)、优化的技术选型(语言+服务组合)和精细化的配置,可实现高性能、高可用、安全的Web服务。开发者需深入理解协议交互、进程模型及性能瓶颈,才能构建出适应大规模访问的现代Web应用。 --- **扩展说明:** 1. **技术细节深化**:补充了Nginx反向代理、协议转换、DDoS防护等具体实现原理; 2. **实践案例**:加入缓存分层、健康检查等优化策略,增强可操作性; 3. **安全与扩展性**:讨论了微服务架构下的适配方案和常见安全威胁应对; 4. **语言对比**:细化各编程语言的部署特点,如Java的部署复杂度与Go的协程优势; 5. **架构逻辑**:强调协议标准化对系统兼容性的重要性,避免技术盲点。
五层架构-负载均衡层详解
软件:
haproxy:支持七层和四层
nginx:支持七层和四层
lvs:支持四层负载均衡
硬件负载均衡F5:支持四层负载均衡
如果用户量持续增大,要扩容,大后端数据库肯定扩,数据库扩完web层也要扩,负载均衡层可以支持多级,在七层负载均衡前再加一个四层负载均衡,为了做到高可用搭一个keepalived,维护一个vip,vip来回漂移,主挂了从可以上线,如果说压力继续增大,负载均衡层都扛不住了,可以引入多级,就不适合在七层上去了,再引入一个基于端口转发的四层负载均衡,这样就分散了压力,为了缓解单点故障,vip就在四层做。
**负载均衡层详解** 在现代分布式系统中,负载均衡层是保障高并发、高可用、高性能的核心组件之一。通过将流量合理分配到多个后端节点,负载均衡可以有效避免单点故障,提升系统整体吞吐量,优化资源利用率。本文将深入探讨负载均衡层的实现方式、关键技术以及应对大规模流量扩容的策略。 **一、负载均衡软件与硬件解决方案** 负载均衡技术分为软件和硬件两种实现方式,各自具备不同的优势。 **1. 软件负载均衡** - **HAProxy**:一款高性能的开源负载均衡器,支持第七层(应用层)和第四层(传输层)负载均衡。第七层支持基于HTTP、HTTPS等协议的内容解析和智能路由,适用于需要深度请求处理的场景;第四层则通过TCP/UDP协议转发,具备低延迟和高吞吐量的特点。 - **Nginx**:作为Web服务器和反向代理,Nginx同样支持七层和四层负载均衡。其事件驱动架构和异步非阻塞特性使其在高并发场景下表现出色,常用于静态资源缓存、动态请求转发等场景。 - **LVS(Linux Virtual Server)**:专注于第四层负载均衡,基于Linux内核实现,通过IPVS模块提供高效的网络数据包转发。因其内核级处理,LVS在超大规模场景下具有极佳的性能,常被用于构建高性能集群。 **2. 硬件负载均衡** - **F5 BIG-IP**:典型的硬件负载均衡设备,专用于第四层流量管理。其硬件优化的架构支持极高的吞吐量和低延迟,同时提供丰富的功能如SSL加速、DDoS防护、应用交付控制等,适用于对性能和安全要求极高的企业级场景。 **二、系统扩容与负载均衡层的演进** 随着用户量持续增长,系统需要从数据库、Web层到负载均衡层逐级扩容,构建弹性架构。 **1. 数据库层与Web层的扩容** - **数据库扩展**:采用分库分表、读写分离、分布式数据库(如MySQL集群、NoSQL解决方案)等技术,提升数据存储和查询能力。 - **Web层扩展**:通过增加服务器实例(横向扩展),结合负载均衡策略(如轮询、最少连接数)分配请求,确保每个节点资源利用率均衡。 **2. 负载均衡层的多级架构设计** 当单层级负载均衡无法满足流量需求时,可引入多级负载均衡策略,分散压力: - **七层负载均衡与四层负载均衡的组合**: - 在流量入口部署**四层负载均衡**(如LVS或硬件F5),基于端口或IP地址快速转发流量,承担TCP/UDP连接管理,减轻后端压力。 - 在四层之后接入**七层负载均衡**(如HAProxy或Nginx),实现更精细的请求路由(如基于URL路径、Cookie、HTTP头部的策略),支持会话保持、SSL卸载等高级功能。 - **高可用保障:Keepalived与VIP漂移**: - 使用Keepalived构建主备模式的双节点架构,维护一个浮动IP(VIP)。主节点正常运行时,VIP绑定在其上;当主节点故障时,VIP自动漂移至备用节点,通过ARP协议更新网络路由,实现秒级切换,确保服务不间断。 - 配置健康检查机制,实时监测后端节点状态,自动剔除故障实例,避免流量转发至无效服务器。 **3. 应对极端流量压力的多级负载均衡架构** 当单层级负载均衡器成为瓶颈时,可构建更复杂的多级架构: - **引入第二层四层负载均衡**: - 在流量进入七层负载均衡前,先通过四层负载均衡进行初步分流。例如,使用多个四层负载均衡节点,每个节点负责特定端口或IP段的流量,再通过端口映射将请求转发至后端的七层负载均衡集群。 - 这种分层设计将流量压力分散到多个四层节点,避免单一设备过载。同时,四层负载均衡的低成本(如使用开源软件)和高扩展性,降低了整体架构的成本和复杂性。 - **跨地域负载均衡**: - 对于全球用户访问场景,可在不同数据中心部署负载均衡集群,通过全局负载均衡(如DNS轮询、Anycast技术)将用户请求导向最近的节点,降低网络延迟。 **4. 缓解单点故障的其他策略** - **负载均衡器集群化**:将多个负载均衡器组成集群,通过BGP(边界网关协议)或专用协议实现负载均衡器的冗余和故障切换。 - **云服务集成**:利用云平台提供的负载均衡服务(如AWS ELB、阿里云SLB),自动扩展和管理负载均衡实例,结合云原生特性(如自动伸缩、弹性IP)简化运维。 **三、负载均衡层的设计原则与性能优化** 1. **协议选择**:根据业务需求选择七层或四层。四层适用于简单TCP/UDP服务,性能高;七层适用于需要内容解析的Web应用,灵活性强。 2. **健康检查机制**:配置合理的检查频率和阈值,避免误判节点状态,同时减少健康检查对后端资源的消耗。 3. **会话保持**:对于需要会话状态的应用(如登录系统),通过Cookie插入、IP哈希等方式确保同一用户请求始终转发到同一后端节点。 4. **压力测试与容量规划**:定期模拟高负载场景,评估各层负载均衡器的性能瓶颈,提前扩容或优化配置。 **四、未来趋势与挑战** - **容器化与微服务架构**:随着Kubernetes等容器编排工具的普及,Service Mesh(如Istio)通过Sidecar代理实现更细粒度的服务间负载均衡,成为新兴趋势。 - **AI驱动的智能负载均衡**:利用机器学习预测流量模式,动态调整负载分配策略,优化资源利用率。 - **安全与合规**:负载均衡层需集成WAF(Web应用防火墙)、零信任架构等安全机制,应对日益复杂的网络安全威胁。 **总结** 负载均衡层是分布式系统架构中不可或缺的一环。从软件到硬件、从单层到多级、从基础转发到智能路由,其设计需紧密结合业务需求、流量规模和成本预算。通过合理的分层架构、高可用机制和动态扩展能力,负载均衡层不仅能保障系统的稳定性,还能为业务增长提供可持续的扩展空间。 --- **扩写说明**: 1. 增加了对负载均衡技术原理的深入解释(如七层与四层的区别、Keepalived VIP漂移机制)。 2. 扩展了多级负载均衡架构的具体部署方案,补充了跨地域负载均衡和云服务集成内容。 3. 添加了性能优化、设计原则以及未来趋势章节,提升文章深度和实用性。 4. 通过具体技术细节(如健康检查、会话保持)增强技术指导价值。
集群管理软件
1、专门的监控集群的运行状态,部署好监控与报警
nagios
cacti
ganglia
zabbix
promethus
2、连接机器记性管理:跳板机,jumpserver、vpn
3、批量管理:ansible
4、自动发布流程
gitlab代码仓库(对于运维人员来讲就是一块存放代码的大网盘)
Jenkins,会从githup里面拉代码到本地......管理一系列流水线
5、日志管理
ELK
EFK
6、k8s+容器管理
扩副本
自愈(发现故障,自动重启)
**集群管理软件:构建高效、稳定、安全的集群生态** 随着云计算和大数据技术的快速发展,集群管理在现代IT架构中扮演着越来越重要的角色。集群管理软件通过整合监控、部署、运维、自动化流程等核心功能,帮助企业高效管理大规模服务器集群,保障系统的稳定性、安全性和可扩展性。
本文将详细介绍集群管理中的关键技术模块,并深入探讨各工具的实际应用与价值。 --- ### **一、集群运行状态监控:实时洞察与智能报警** 集群的实时监控是运维管理的核心环节。我们采用多种监控工具对集群的CPU利用率、内存占用、网络流量、磁盘IO、服务状态等关键指标进行全面监控,确保系统健康运行。 - **Nagios**:老牌监控工具,擅长主动检测和被动监控结合,通过插件机制支持丰富的监控场景,适合中小规模集群。其报警机制灵活,可通过邮件、短信等多渠道通知。 - **Cacti**:基于RRDtool的数据采集和绘图工具,擅长网络设备监控和流量可视化。通过实时曲线图直观展示网络带宽、接口状态,帮助快速定位网络瓶颈。 - **Ganglia**:分布式监控系统,通过gmond/gmetad组件实现集群间数据聚合,适合大规模集群的实时性能监控。其低资源消耗和高扩展性广受好评。 - **Zabbix**:功能强大的企业级监控平台,支持自动发现、自定义模板和复杂触发条件。结合图形化界面和API接口,可实现高度定制化的监控策略。 - **Prometheus**:新一代开源监控利器,采用Pull模式采集数据,支持多维数据模型和强大的查询语言(PromQL)。配合Grafana可视化,成为云原生环境下的首选方案。 **监控实践**: 在实际部署中,我们通常将不同工具组合使用。例如,用Prometheus监控容器和微服务,Zabbix负责传统基础设施监控,Cacti专注网络设备管理。通过统一报警平台(如AlertManager)整合各类告警,减少信息碎片化,提升响应效率。 --- ### **二、连接机器管理:安全访问与资产管理** 在集群管理过程中,安全访问和资产管理是保障系统安全的基础。我们通过跳板机、VPN等技术构建安全访问通道,同时结合自动化工具实现资产高效管理。 - **跳板机(Jumpserver)**:作为统一的访问入口,所有运维操作需通过跳板机中转。支持命令审计、操作录像、权限控制,防止非法访问和误操作。配合SSH密钥管理,简化运维账号体系。 - **VPN**:为远程运维提供加密访问通道,确保数据传输安全。尤其在跨数据中心或混合云场景下,VPN成为连接分布式集群的重要工具。 - **自动化资产录入**:通过CMDB(配置管理数据库)与自动化工具(如Ansible)联动,实时同步服务器硬件配置、软件版本、网络拓扑等信息,避免资产信息滞后。 **安全实践**: - 实施最小权限原则,为不同角色分配细粒度权限(如开发、测试、运维)。 - 定期审计跳板机日志,识别异常登录行为和命令操作。 - 结合堡垒机(如Jumpserver的审计功能)与防火墙策略,构建多层防御体系。 --- ### **三、批量管理:自动化运维的基石** 传统的手工运维在大规模集群中效率低下且易出错。批量管理工具通过自动化脚本和配置模板,大幅提升运维效率。 - **Ansible**:基于Python的自动化工具,无需客户端Agent,通过SSH协议实现跨平台管理。其Playbook采用YAML语法,支持任务编排、角色复用,适用于配置管理、应用部署、安全加固等场景。 - **SaltStack**:另一款流行批量管理工具,采用C/S架构,支持事件驱动和实时响应,适合需要高频交互的场景。 - **Puppet/CFEngine**:基于Agent的自动化工具,擅长长期配置管理和状态保持,适合复杂环境下的标准化部署。 **自动化案例**: - 通过Ansible Playbook实现服务器批量初始化:安装基础软件、配置防火墙、部署监控Agent等。 - 使用角色(Roles)封装MySQL集群部署流程,一键完成主从复制、高可用配置。 - 结合Jenkins触发Ansible任务,实现代码上线后的自动配置同步。 --- ### **四、自动发布流程:CI/CD驱动的敏捷交付** 自动发布流程通过流水线化部署,将代码从仓库到生产环境的交付过程标准化、自动化,降低人为错误风险。 - **GitLab代码仓库**:作为一站式DevOps平台,GitLab不仅提供代码托管,还集成代码审查(MR)、持续集成(CI)、问题跟踪等功能。私有化部署保障代码安全,分支管理策略(如GitFlow)提升团队协作效率。 - **Jenkins流水线**:作为老牌CI/CD工具,Jenkins通过Pipeline as Code理念,将构建、测试、打包、部署等步骤封装为可复用的流水线。支持多环境部署(Dev→Test→Prod),结合插件生态(如Kubernetes插件)实现容器化应用自动化发布。 - **其他工具补充**: - **GitLab CI/CD**:与GitLab深度集成,适合中小团队快速搭建CI/CD流程。 - **Spinnaker**:开源多云部署平台,擅长复杂应用的蓝绿部署、金丝雀发布。 **发布流程设计**: 1. 代码提交触发GitLab CI构建:静态检查、单元测试、镜像构建。 2. Jenkins流水线拉取构建产物,执行自动化测试(如接口测试、性能测试)。 3. 通过蓝绿部署或滚动升级策略,将新版本应用部署到K8s集群。 4. 部署完成后,触发自动化监控与验证,确保服务正常。 --- ### **五、日志管理:从数据采集到智能分析** 日志是系统运行状态的“黑匣子”,高效的日志管理能加速故障定位和业务分析。 - **ELK Stack(Elasticsearch+Logstash+Kibana)**:经典日志解决方案。Elasticsearch实时存储和索引日志,Logstash负责日志采集与清洗,Kibana提供可视化仪表盘和查询界面。 - **EFK Stack(Elasticsearch+Filebeat+Kibana)**:轻量级替代方案,Filebeat作为Beats系列中的日志采集器,资源消耗更低,适合容器化环境。 - **日志采集实践**: - 容器日志:通过Docker日志驱动或Fluentd统一采集,发送至Elasticsearch。 - 应用日志:使用Log4j、Python logging等框架输出结构化日志,便于后续分析。 - **智能分析**:结合机器学习插件(如Elastic ML)实现异常检测,例如自动识别流量突增、错误日志频率异常等场景。 --- ### **六、K8s+容器管理:云原生时代的运维革命** Kubernetes作为容器编排的事实标准,为集群管理带来革命性变化。 - **核心功能**: - **资源调度**:根据Pod资源需求动态分配节点,实现资源利用率最大化。 - **副本管理**:通过ReplicaSet/Deployment维护Pod副本数量,自动应对流量波动。 - **自愈机制**:Node宕机时,自动在其他节点重建Pod;容器异常退出时,通过Liveness/Readiness探针重启或隔离容器。 - **服务发现**:通过Service和DNS机制,实现Pod间动态寻址,简化微服务架构管理。 - **扩展能力**: - **Horizontal Pod Autoscaler(HPA)**:根据CPU/内存利用率自动扩缩容,应对突发流量。 - **Kubernetes Operator**:通过自定义控制器扩展K8s功能,例如数据库集群管理、分布式存储部署。 - **容器化实践**: - 镜像管理:使用Harbor私有镜像仓库存储镜像,结合镜像扫描工具(如Clair)保障安全。 - 配置管理:通过ConfigMap/Secrets分离配置与代码,实现环境变量动态注入。 **运维挑战与应对**: - 针对大规模集群,使用联邦集群(Federation)跨区域管理。 - 采用Prometheus+Grafana监控K8s资源指标(如Pod状态、节点健康度)。 - 通过混沌工程工具(如Chaos Mesh)模拟故障,验证系统韧性。 --- ### **七、总结与展望** 集群管理软件通过整合监控、自动化、容器化等技术,构建了现代IT系统的运维基石。从传统的基础设施监控到云原生环境的自动化管理,工具生态不断演进。未来,集群管理将呈现以下趋势: - **AI与自动化结合**:通过机器学习优化资源调度、预测故障,进一步降低运维成本。 - **可观测性增强**:引入OpenTelemetry标准,统一日志、监控、追踪数据,提升问题诊断效率。 - **多云与边缘计算支持**:K8s扩展到边缘节点管理,跨云平台的统一集群管理成为需求。 - **安全合规**:零信任架构与集群管理深度融合,强化身份认证与访问控制。 通过持续优化工具链与流程,集群管理将为企业数字化转型提供更强大的支撑。 --- **结语** 集群管理软件是系统稳定运行的守护者,也是技术创新的推动者。通过合理选择和组合工具,企业能够构建高效、智能、安全的集群生态,在激烈的市场竞争中保持技术领先。未来,随着云计算和AI技术的深入融合,集群管理必将迎来更多突破性发展。
ELK与k8s容器技术
集群更进一步加强管理,集群规模大了的情况下,后续可能有一些报错信息发过来之后要排错,得看日志,所有的排错都得看日志。
ELK
EFK
**ELK与k8s容器技术深度融合:强化集群管理,高效应对大规模集群日志分析与排错** 随着云计算和容器化技术的普及,Kubernetes(k8s)已成为构建和管理大规模容器化应用集群的核心平台。然而,随着集群规模的不断扩展(节点数量、服务数量、微服务架构的复杂性增加),系统运维的挑战也随之加剧。
当集群出现故障或性能瓶颈时,快速定位问题根源成为运维团队的核心任务。此时,日志作为记录系统运行状态、错误信息和业务数据的关键载体,其高效管理和分析显得尤为重要。
而ELK(Elasticsearch、Logstash、Kibana)和EFK(Elasticsearch、Fluentd、Kibana)等日志处理平台与k8s的深度融合,为这一难题提供了全面的解决方案。 首先,ELK与k8s的集成实现了日志的自动化采集、集中存储和智能分析。在k8s集群中,每个Pod、容器及节点都会产生大量的日志数据,这些数据分散且格式各异。
传统日志管理方式(如手动收集或本地存储)在大规模集群中极易导致数据丢失、查询延迟或存储资源耗尽。而ELK通过Elasticsearch的强大搜索引擎、Logstash的灵活数据处理能力以及Kibana的可视化界面,构建了一套完整的日志生命周期管理方案。
例如,Logstash可通过插件机制从k8s的API接口、容器日志文件、标准输出(stdout)等多元来源实时捕获日志,经过解析、过滤、格式转换后,统一存储到Elasticsearch集群中。
Kibana则提供仪表盘、图表、搜索查询等功能,帮助运维人员直观地追踪错误趋势、关联事件、分析性能瓶颈。 其次,在集群规模扩大的场景下,ELK的分布式架构与k8s的弹性扩展特性天然契合。Elasticsearch支持水平扩展,通过分片和副本机制,能够处理PB级别的日志数据,并确保高可用性和容错性。
当k8s集群新增节点或服务时,ELK集群可自动感知并调整资源分配,避免因日志流量激增导致的系统过载。
例如,通过k8s的DaemonSet部署模式,可以为每个节点自动配置日志采集代理(如Fluentd或Filebeat),确保日志采集的零遗漏和低延迟。此外,ELK还支持滚动索引、冷热数据分层存储等策略,优化长期日志保留与查询效率。 在排错场景中,ELK与k8s的结合显著提升了故障定位效率。当报错信息出现时,运维人员无需登录每个节点或容器逐行排查日志,而是通过Kibana的全文搜索、时间序列分析、异常检测等功能,快速定位问题源头。
例如,通过设置日志标签(如Pod名称、服务类型、错误级别),可以一键筛选特定服务的报错日志;结合日志关联分析,能够追踪跨多个容器的请求链路,识别微服务之间的依赖故障。
此外,ELK的实时告警功能(如与Prometheus集成)还可以在关键指标异常时主动触发通知,将被动排错转化为主动预防。 值得注意的是,EFK架构在k8s场景中具有独特优势。相较于ELK,EFK使用轻量级的Fluentd替代Logstash,其资源占用更低且原生支持k8s元数据注入。
例如,Fluentd可以直接从k8s的API Server获取Pod标签、命名空间等信息,自动为每条日志附加上下文,大幅提升后续分析的精准度。在大型集群中,这种元数据富化能力显著减少了人工标注成本,并增强了日志的上下文关联性。 然而,部署和管理ELK在k8s集群中也面临一些挑战。例如,日志流量的爆发式增长可能导致Elasticsearch索引写入压力过大;高并发查询场景下,Kibana的响应速度可能受限于网络延迟或资源不足。为此,运维团队需采取一系列优化措施: 1. **性能调优**:通过调整Elasticsearch的分片数、副本数、缓存配置,优化写入和查询性能;使用Logstash的批处理模式减少I/O开销。 2. **资源隔离**:利用k8s的资源配额和限制(CPU、内存),确保日志组件不会抢占业务容器的资源。 3. **安全加固**:通过TLS加密、RBAC权限控制、日志审计,防止敏感数据泄露或未经授权访问。 4. **智能分析**:引入机器学习算法(如Anomaly Detection),自动识别日志中的异常模式,减少人工排查工作量。 实际应用中,许多企业已通过ELK与k8s的整合构建了智能运维体系。例如,某电商平台的k8s集群每日处理百万级订单,通过ELK实时监控支付服务、库存系统、物流模块的日志,成功将故障响应时间从小时级缩短至分钟级。
运维团队不仅能够通过日志分析快速定位代码错误或资源瓶颈,还能基于历史数据预测系统容量需求,提前进行扩缩容调度。 总结而言,ELK与k8s容器技术的深度融合,不仅解决了大规模集群日志管理的复杂度,更通过智能分析、实时监控和自动化能力,将运维工作从被动响应转向主动优化。
无论是排查突发报错、追踪微服务调用链,还是进行性能调优和安全合规审计,ELK与k8s的协同作用都已成为现代云原生架构不可或缺的技术基石。未来,随着日志数据与AI、可观测性平台的进一步融合,这一组合将在企业数字化转型中发挥更大的价值。 --- **扩写说明**: 1. **内容扩展方向**: - 细化ELK各组件与k8s集成的技术细节(如Logstash/Fluentd的日志采集方式、Elasticsearch的分布式特性); - 补充实际应用场景(电商案例)和挑战解决方案(性能调优、安全加固等); - 强调ELK在主动运维中的作用(预测性维护、智能分析); - 对比ELK与EFK架构的差异及适用场景。 2. **语言优化**: - 增加技术术语解释(如DaemonSet、分片、副本机制),提升可读性; - 使用具体例子(如订单处理量、响应时间对比)增强说服力; - 分点列举挑战与优化策略,结构更清晰。 3. **逻辑强化**: - 从“问题(集群规模扩大带来的日志管理难题)→ 解决方案(ELK与k8s集成)→ 具体实现 → 优势与挑战 → 最佳实践”层层递进,增强文章逻辑性。
代码拉取的两种方法
gitlab
github
Gitee
如果开发人员给的是.gt结尾的地址,运维人员需要用专门的软件(git)去下载它 。
git clone
wget
wget 要需要解压,并且需要改名
**代码拉取的两种方法:GitLab、GitHub、Gitee与专用工具的使用指南** 在软件开发和运维工作中,代码拉取是日常操作中的核心环节。常见的代码托管平台包括GitLab、GitHub和Gitee,它们提供了便捷的版本控制和协作功能。
当开发人员提供以`.gt`结尾的地址时,运维人员需要采用特定的方法进行下载,通常涉及两种主要方式:`git clone`命令和`wget`工具。 **一、代码托管平台概述** 1. **GitLab**:企业级代码托管平台,支持私有仓库和高级权限管理,适用于团队内部协作。其界面功能齐全,适合大型项目,但部署和维护成本相对较高。 2. **GitHub**:全球最大的开源社区,适合开源项目和个人开发者。拥有丰富的生态工具(如Issue跟踪、Pull Request等),但私有仓库需付费。 3. **Gitee(码云)**:国内代码托管平台,访问速度快,适合国内团队,提供免费私有仓库,界面与GitHub相似,适合中小项目。 **二、处理`.gt结尾的地址** 开发人员提供的`.gt`地址通常指向代码仓库的特定版本或压缩包(如`.git`文件的变体)。运维人员不能直接通过浏览器下载,必须使用命令行工具: **方法1:使用**`git clone`**命令** `git clone`是Git工具的核心功能,用于完整克隆仓库及其版本历史。操作步骤如下: - **安装Git工具**:需在服务器或本地环境安装Git(Linux、Windows、Mac均支持)。 - **执行克隆命令**:例如,`git clone https://example.com/project.git`将仓库完整下载到本地。 - **优势**: - 自动处理版本控制,支持后续更新(`git pull`)。 - 保留分支、标签等完整信息,便于后续维护。 - **适用场景**:需要持续维护代码,或参与开发协作的场景。 **方法2:使用**`wget`**命令下载并解压** 当仅需获取代码快照(当前版本)而不需版本历史时,可使用`wget`: - **操作步骤**: 1. 执行`wget`下载压缩包:例如,`wget https://example.com/project.tar.gz`。 2. 解压文件:使用`tar -zxvf project.tar.gz`(或对应压缩格式命令)。 3. **改名**(若必要):若解压后文件夹名称不符合规范,需手动重命名。 - **注意事项**: - 需确认压缩格式(`.tar.gz`、`.zip`等),使用对应解压工具。 - 无法追溯历史版本,仅适用于临时部署或静态文件获取。 - **适用场景**:快速部署静态网站、一次性代码迁移等无需版本管理的场景。 **三、对比与最佳实践** 1. **效率与灵活性**: - `git clone`适合长期项目,虽初次下载较慢,但后续更新仅需拉取增量。 - `wget`适合快速获取,但每次更新需重新下载完整包。 2. **安全与权限**: - 使用Git可验证仓库SSH密钥,防止恶意代码注入。 - `wget`需确认URL来源,避免下载未经验证的文件。 3. **运维建议**: - 对于持续部署,优先使用`git clone`并配置自动化脚本(如Jenkins集成)。 - 临时任务或测试环境可选用`wget`简化流程。 **四、扩展技巧** - **Git进阶**:通过`git clone --depth 1`仅下载最新版本,节省空间;使用`git submodule`管理子模块依赖。 - **Wget自动化**:结合`cron`定时任务,实现代码包的定期更新;使用`--no-check-certificate`跳过HTTPS证书验证(慎用)。 - **跨平台兼容**:确保解压工具(如`tar`、`unzip`)在目标服务器已安装,避免兼容性问题。 **五、总结** 在代码拉取过程中,运维人员需根据项目需求灵活选择工具:`git clone`适用于版本化协作,`wget`适用于轻量级部署。处理`.gt`地址时需明确文件类型(是否为Git仓库压缩包),并遵循安全规范。掌握这两种方法的细节,能显著提升代码管理的效率与可靠性。 --- **扩展说明**: - 增加了平台特性对比、安全考量、自动化场景等实用内容。 - 补充了Git和Wget的高级用法,帮助读者应对复杂需求。 - 强调了操作中的注意事项,降低误用风险。 - 通过结构化分段和示例,提升了内容的可读性和实操性。
部署运行环境
有了代码以后就要部署发布它,部署完了之后接上网络,就是完成上线了。
1、单机部署环境准备:
时间保持一致;
网络保持通常---->静态IP;
关掉防火墙:
setenforce 0
systemctl stop firewalld
iptables
规范主机名---->添加到hosts;
关selinux
2、下载应用包、解压
方式一:git clone
方式二:wget
3、准备好软件的运行环境,以Python的uwsgi为例:
安装依赖包
安装web服务---uwsgi
下载gcc包
依赖Python环境
下载软件依赖的Python库
**部署运行环境:从代码到上线的完整指南** 在完成代码编写后,下一步便是部署和发布应用程序,使其能够在服务器环境中稳定运行。部署过程包括环境准备、软件安装、配置调整等多个环节,最终通过网络连接实现上线。以下是针对单机部署环境的详细步骤及注意事项: --- ### **1. 单机部署环境准备** 部署前,需对服务器的基础环境进行全面配置,确保满足应用程序的运行需求。具体步骤如下: **1.1 时间同步** 服务器时间的一致性是系统稳定运行的基础,特别是在涉及日志记录、定时任务等场景时尤为重要。建议使用NTP(网络时间协议)进行同步: ``` # 安装NTP服务 yum install ntp -y # 启动并配置NTP自动同步 systemctl start ntpd systemctl enable ntpd # 手动同步一次时间 ntpdate pool.ntp.org ``` 此外,需定期检查时间同步状态,避免因时间偏差导致的问题。 **1.2 网络配置** 为确保应用程序的网络访问稳定,建议配置静态IP地址: - 编辑网络配置文件(如CentOS的`/etc/sysconfig/network-scripts/ifcfg-eth0`): ``` TYPE="Ethernet" BOOTPROTO="static" IPADDR="192.168.1.100" NETMASK="255.255.255.0" GATEWAY="192.168.1.1" DNS1="8.8.8.8" ONBOOT="yes" ``` - 重启网络服务:`systemctl restart network` **1.3 防火墙与安全配置** 为方便调试,可临时关闭防火墙,但**在生产环境中需谨慎操作**: ``` # 临时关闭防火墙(立即生效) systemctl stop firewalld # 永久禁用防火墙(重启后仍生效) systemctl disable firewalld # 关闭Selinux(需重启生效) setenforce 0 sed -i '/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config ``` **注意**:关闭防火墙和Selinux会降低系统安全性,建议在测试完成后重新配置防火墙规则,仅开放必要端口(如Web服务的80/443端口)。 **1.4 主机名与hosts文件配置** 规范主机名有助于系统管理和日志识别。例如,将主机名设为`app-server`: ``` # 修改主机名 hostnamectl set-hostname app-server # 添加至hosts文件 echo "192.168.1.100 app-server" >> /etc/hosts ``` **1.5 其他系统优化** 根据应用场景,可能还需调整内核参数(如文件句柄数、网络连接数),或安装常用工具(如`vim`、`curl`等)。 --- ### **2. 下载应用包并解压** 获取应用程序代码的方式多样,常见方法包括: **2.1 使用Git克隆代码仓库** 适用于持续集成或团队协作场景: ``` # 安装Git yum install git -y # 克隆代码(需提前配置仓库访问权限) git clone https://git.example.com/your-repo.git ``` **优点**:支持版本管理,方便回滚更新。 **2.2 使用Wget下载压缩包** 适用于一次性部署或离线环境: ``` # 下载压缩包(如ZIP或TAR格式) wget https://example.com/your-app-v1.0.zip # 解压文件 unzip your-app-v1.0.zip # 或 tar -xzvf your-app-v1.0.tar.gz ``` **2.3 验证代码完整性** 为确保下载的文件未被篡改,可校验MD5/SHA值: ``` md5sum your-app-v1.0.zip # 或 sha256sum your-app-v1.0.tar.gz ``` --- ### **3. 准备软件运行环境(以Python+uWSGI为例)** 以Python Web应用为例,需配置Python环境及uWSGI服务器。 **3.1 安装基础依赖包** uWSGI依赖系统底层库(如GCC、Python开发头文件): ``` yum install gcc make python3-devel libffi-devel openssl-devel ``` **3.2 配置Python环境** - 若需多版本共存,建议使用虚拟环境(如`venv`或`conda`): ``` # 创建虚拟环境 python3 -m venv /opt/your-app-venv # 激活环境 source /opt/your-app-venv/bin/activate ``` - 升级pip及安装工具: ``` pip install --upgrade pip setuptools wheel ``` **3.3 安装uWSGI服务器** uWSGI是高性能的WSGI服务器,支持异步处理: ``` pip install uwsgi ``` **3.4 安装应用程序依赖库** 根据项目`requirements.txt`安装所有Python包: ``` pip install -r requirements.txt ``` **3.5 配置uWSGI启动文件** 创建uWSGI配置文件(如`your-app.ini`): ``` [uwsgi] chdir = /path/to/your-app # 项目根目录 module = your_app.wsgi # WSGI入口模块 master = true processes = 4 # 根据服务器资源调整进程数 socket = /tmp/your-app.sock chmod-socket = 666 vacuum = true ``` **3.6 启动uWSGI并测试** ``` uwsgi --ini your-app.ini # 前台启动(用于调试) # 后台启动(推荐) uwsgi --ini your-app.ini --daemonize /var/log/your-app.log ``` 访问`http://服务器IP:端口`(或通过Nginx反向代理)验证应用是否成功运行。 --- ### **4. 部署后的检查与优化** 完成部署后,需进行以下验证和优化: - **日志监控**:检查uWSGI日志(如`/var/log/your-app.log`)确认无报错。 - **性能测试**:使用工具(如`ab`、`wrk`)测试服务响应时间和并发能力。 - **资源限制**:配置系统资源限制(如`ulimit -n`调整文件句柄数)。 - **自动化部署**:考虑使用Docker容器化或Ansible/Puppet等工具实现自动化部署。 **注意事项**: - **安全加固**:部署到生产环境前,务必重新启用防火墙,仅开放必要端口。 - **备份与回滚**:保留代码及配置文件的备份,以便快速恢复。 - **监控与告警**:集成监控工具(如Prometheus、Grafana)实时跟踪服务状态。 --- ### **总结** 单机部署是应用程序上线的基础环节,需关注环境配置、依赖安装、安全性及性能优化。实际生产中,往往还需结合负载均衡、容器化技术、持续集成/持续部署(CI/CD)流程,进一步提升系统的稳定性和可维护性。通过以上步骤,可构建一个稳定、可扩展的应用运行环境,为后续业务上线提供坚实保障。 --- **扩写说明**: - 扩展了每个步骤的技术细节,如NTP时间同步、防火墙安全提示、Python虚拟环境的使用等。 - 增加了实际部署中的最佳实践和注意事项,帮助读者避免常见错误。 - 补充了性能优化和后续扩展方向,提升内容的实用性和深度。 - 通过代码示例和配置模板,增强可操作性,适合不同技术背景的读者参考。
初始化数据库
准备好了依赖环境,正常情况下在down来下的包里面有依赖包的说明requeirements.txt,直接pip3 install -r requirements.txt
装完之后应用程序还依赖uwsgi。
环境好了之后要去修改它的配置文件,完成一些定制化的配置。
依赖数据库环境,下载数据库并启动
应用程序要连数据库,提供账号密码,创建好一些库,库里面要放好应用程序要用到的表,这些都是研发人员交代好的,照着做就行,mysql -uroot -p " <xxx.sql
**初始化数据库的完整流程及技术细节解析** 在软件开发与部署过程中,初始化数据库是至关重要的一环,它涉及到环境搭建、依赖安装、配置调整及数据迁移等多个步骤。本文将详细阐述从准备依赖环境到最终完成数据库初始化的全流程,并补充关键步骤的技术细节和注意事项。 **一、准备依赖环境** 首先,需要确认项目所需的依赖环境已准备就绪。通常,开发团队会提供一个名为`requirements.txt`的文件,其中列出了项目运行所需的所有第三方库及其版本号。该文件的作用类似于“依赖清单”,通过执行命令`pip3 install -r requirements.txt`,Python包管理工具会自动解析文件内容并安装所有指定的依赖包。这一步骤确保了项目在不同环境中的兼容性和一致性,避免了版本冲突问题。 值得注意的是,在执行安装前,建议先创建虚拟环境(如使用`venv`或`conda`),以隔离项目依赖,避免污染系统环境。此外,对于大型项目,可能需要检查网络连接是否稳定,以防下载依赖包时中断导致安装失败。 **二、安装uwsgi服务** 完成基础依赖安装后,应用程序往往还需要Web服务器网关接口(WSGI)的支持,而`uwsgi`是Python项目中常用的高性能WSGI服务器。它不仅能处理HTTP请求,还支持进程管理、负载均衡等功能。因此,需要单独安装`uwsgi`并配置其启动参数,例如指定监听端口、工作进程数、日志路径等。具体命令通常为: ``` pip3 install uwsgi ``` 安装完成后,需根据项目需求编写`uwsgi.ini`配置文件,并确保其路径正确配置,以便后续启动服务时使用。 **三、修改配置文件** 环境准备完成后,下一步是修改项目的配置文件。通常,配置文件位于项目的根目录或特定配置文件夹中(如`config/`),常见的格式有`.ini`、`.yaml`或`.json`。定制化配置包括但不限于: - **服务器参数**:绑定IP地址、端口号; - **数据库连接信息**:数据库类型(如MySQL、PostgreSQL)、主机地址、账号密码、数据库名称; - **日志配置**:日志级别、存储路径; - **安全设置**:HTTPS证书路径、访问密钥等。 修改时需严格遵循研发文档中的指示,避免误改关键参数导致服务无法启动。此外,建议对配置文件进行版本控制,以便在出现问题时快速回滚。 **四、部署数据库环境** 数据库是应用程序的核心存储层,其初始化步骤直接影响系统的可用性。根据项目要求,需选择对应的数据库管理系统(DBMS),如MySQL、MongoDB、Redis等。以MySQL为例,具体流程如下: 1. **下载与安装**:根据操作系统选择对应的安装包(如apt、yum、源码编译等),并完成初始化配置(如设置root密码、启动服务等); 2. **启动数据库服务**:通过`systemctl start mysql`(Linux)或对应的管理工具启动数据库进程; 3. **验证连接**:使用`mysql -uroot -p`命令登录数据库,确认服务状态正常。 **五、创建数据库与导入数据** 在数据库服务运行后,需要为应用程序创建专用的数据库账号、密码及数据库实例。这一步骤通常包括: - **创建数据库用户**:使用`CREATE USER 'appuser'@'localhost' IDENTIFIED BY 'password';`命令创建用户,并授予必要的权限(如`GRANT ALL PRIVILEGES ON myappdb.* TO 'appuser'@'localhost';`); - **创建数据库**:执行`CREATE DATABASE myappdb;`以建立空数据库; - **导入表结构**:研发人员通常会提供预定义的数据表结构文件(如`xxx.sql`),通过以下命令导入: - 该命令会将SQL文件中的建表语句、初始化数据等批量执行,完成数据库的初始化。 **六、连接测试与后续优化** 完成以上步骤后,需验证应用程序是否能正常连接数据库。可通过查看应用日志或执行简单查询(如`SELECT * FROM users LIMIT 1;`)来确认。若连接失败,常见原因包括配置错误、权限不足或数据库服务未启动。 此外,为提高性能和安全性,建议进一步优化数据库配置: - **索引优化**:为高频查询的字段创建索引; - **连接池配置**:使用数据库连接池(如`DBUtils`)减少连接开销; - **备份策略**:定期备份数据,防止数据丢失。 **七、自动化部署与最佳实践** 在实际生产环境中,手动执行上述步骤容易出错且效率低下。推荐采用自动化工具(如Ansible、Docker Compose、CI/CD流水线)实现一键化部署。例如,通过Docker容器打包应用及其依赖的数据库环境,可极大简化部署流程,并确保环境的一致性。 总结来说,初始化数据库是一个涉及多环节的复杂过程,需要开发人员、运维人员协同完成。每个步骤的严谨性都直接影响系统的稳定性。通过标准化流程、自动化工具和持续监控,能有效降低部署风险,提升项目交付效率。
配置uwsgi并测试访问
安装并且配置web服务---->uwsgi
uwsgi------------------web应用-----通过配置文件连接---------mysql
pip3 install uwsgi -i 具体源地址
配置uwsgi来拉起应用程序,每个配置项的末尾都不要加内容
**配置uWSGI并测试访问:从安装到Web服务部署的完整指南** 在完成Web服务的安装与配置后,我们需要进一步配置uWSGI(全称“uWSGI Server”),这是一个高性能的Python WSGI(Web Server Gateway Interface)服务器,用于连接Web应用程序与Web服务器(如Nginx),并管理应用程序的进程、线程和资源。
uWSGI支持多种协议(如HTTP、HTTPS、uWSGI协议等),具备动态加载、进程监控、负载均衡等功能,是部署Python Web应用(如Flask、Django)的重要工具。 **一、安装uWSGI** 首先,通过pip3安装uWSGI。指定源地址可以加快安装速度或解决网络问题(例如使用国内镜像源),命令如下: ``` pip3 install uwsgi -i 具体源地址 ``` 例如,使用清华源: ``` pip3 install uwsgi -i https://pypi.tuna.tsinghua.edu.cn/simple ``` 安装完成后,可通过`uwsgi --version`验证是否成功。uWSGI的安装过程通常会自动处理依赖,但建议确保系统已安装Python开发环境(如Python 3.x)和必要的编译工具(如GCC)。 **二、配置uWSGI:连接Web应用与MySQL** uWSGI的核心在于通过配置文件将Web应用与服务器、数据库等组件连接起来。以下是一个典型的配置流程: 1. **创建uWSGI配置文件** 在项目的根目录或指定位置(如`/etc/uwsgi/`)创建配置文件(例如`myapp.ini`),文件名可根据实际情况调整。uWSGI支持多种配置格式(INI、XML、YAML等),此处以INI格式为例。 2. **配置基本项** 配置文件需包含以下关键项(注意:每个配置项末尾不要加空格、换行或其他内容,避免语法错误): 2. 其中: - `module`:指向Python应用的主入口(例如Flask的`app = Flask(__name__)`所在的模块)。 - `chdir`:确保uWSGI在正确的目录下加载应用,避免模块导入错误。 - `http`:直接使用HTTP协议启动(适合测试,生产环境推荐配合Nginx)。 - `processes`和`threads`:优化并发性能,根据CPU核心数和内存调整。 - `master`:启用主进程管理,自动重启崩溃的子进程。 - `logto`:日志路径,便于排查问题。 3. **连接MySQL(可选)** 如果Web应用需要访问MySQL数据库,需在应用内部通过Python库(如`pymysql`、`sqlalchemy`)配置数据库连接参数。uWSGI本身不直接管理数据库连接,但可以通过环境变量或配置项传递数据库配置(例如在应用启动时读取环境变量)。 **三、启动uWSGI并测试访问** 1. **启动命令** 使用配置文件启动uWSGI: 1. 或后台启动(添加`--daemonize`参数): 2. **验证服务** - 查看日志文件(如`/path/to/log/uwsgi.log`)确认启动信息。 - 通过浏览器访问`http://服务器IP:8000`(或使用`curl http://localhost:8000`测试),若显示应用首页或API响应,说明配置成功。 - 检查进程状态:`ps aux | grep uwsgi`应显示uWSGI主进程及其子进程。 **四、常见问题与优化建议** 1. **配置报错** - 若提示“ModuleNotFoundError”,检查`module`路径是否正确,或`chdir`是否切换到应用目录。 - 端口冲突:确保`http`指定的端口未被其他服务占用(如使用`netstat -tuln | grep 8000`检查)。 2. **性能优化** - 生产环境建议配合Nginx作为反向代理,uWSGI使用uWSGI协议(配置`socket`代替`http`)。 - 调整`processes`和`threads`参数,例如多核服务器可设置`processes`为CPU核心数,`threads`根据应用类型(CPU密集型或IO密集型)调整。 - 使用`--buffer-size`增大请求缓冲,减少内存拷贝。 3. **持久化配置** 可将uWSGI配置加入系统服务(如Systemd或Supervisor),实现开机自启和进程监控,避免手动管理。 **五、安全注意事项** - 测试阶段使用`http`直接暴露端口风险较高,正式部署需通过HTTPS和Nginx反向代理。 - 避免在配置文件中硬编码敏感信息(如数据库密码),建议使用环境变量或密钥管理工具。 **总结** 通过uWSGI的灵活配置,我们可以高效地将Python Web应用与服务器环境整合,实现稳定、可扩展的部署。配置过程中需严格遵循语法规则,结合应用需求和服务器资源进行参数调优,并通过日志和监控工具及时排查问题。掌握uWSGI的使用,是构建高性能Web服务的关键一步。 --- **扩展说明** - 增加了uWSGI的技术背景、工作原理及优势,帮助用户理解其必要性。 - 细化了配置文件的每个关键项,解释其作用与常见调整策略。 - 补充了启动命令、测试方法、日志排查等实操步骤,提升可操作性。 - 针对常见问题(报错、性能、安全)提供解决方案,降低部署难度。 - 扩展了生产环境优化建议,引导用户向更高级的部署方案过渡。
压力测试单机极限qps
单机部署演变成集群化的部署,在扩展出集群前一定要有能预估集群规模的能力
预估集群规模首先得跟业务人员对齐,了解到未来预期访问量能达到什么级别,pv,极限qps值,带宽...有了这些之后再对单机进行压力测试得出极限值,总得qps除以单机的就大概能知道扩几台了。
压力测试工具:apache bench、jmeter、locust等工具,用的时候安装取首字母。
单机极限qps:
先摸底:
先高并发去测试
在触底反弹一下
底数每次加10,直到出现失败数
**压力测试与集群规模预估:从单机到分布式部署的演进** 在系统架构从单机部署向集群化扩展的演进过程中,准确预估集群规模是确保系统高可用、高性能的关键一步。这一过程不仅涉及技术层面的压力测试,更需要与业务需求紧密对齐,从而在资源投入与性能需求之间找到平衡点。
本文将详细阐述如何通过压力测试确定单机极限QPS,并结合业务预期流量合理规划集群规模。 **一、集群规模预估的重要性** 单机部署虽然简单易维护,但随着业务增长,访问量(如PV、UV)、数据量以及并发请求的激增会迅速触及单机的性能瓶颈。此时若未能提前规划集群扩展,可能导致系统响应延迟、服务宕机甚至数据丢失。
因此,在扩展集群前,必须通过科学的方法评估未来流量压力,并基于压力测试结果制定合理的扩容策略。 **二、与业务人员对齐需求** 准确预估集群规模的第一步是与业务团队深入沟通,明确以下关键指标: 1. **预期访问量**:包括未来一段时间内的日均PV(页面浏览量)、UV(独立访客数),以及高峰期的流量峰值。 2. **极限QPS(Queries Per Second)**:系统在单位时间内能处理的**最大**请求量,通常需要覆盖业务高峰期可能出现的瞬时流量洪峰。 3. **带宽需求**:根据请求类型(如文本、图片、视频)和用户分布,估算所需的网络传输带宽。 4. **数据存储与处理量**:数据库读写压力、缓存容量、消息队列吞吐量等。 只有获取这些数据后,才能为后续的压力测试提供目标基准,避免资源过度投入或不足。 **三、单机压力测试:确定极限QPS** 压力测试是评估单机性能的核心手段,其目标是找到系统在保持稳定响应下的**最大处理能力**。常用的工具包括: - **Apache Bench(ab)**:轻量级命令行工具,适合快速模拟HTTP请求,适用于简单场景的性能摸底。 - **JMeter**:功能强大的开源工具,支持多协议测试、脚本录制、分布式压测,适合复杂场景的模拟。 - **Locust**:基于Python的分布式压力测试框架,支持动态并发控制,适合模拟真实用户行为。 **测试步骤与策略**: 1. **摸底测试**:首先使用高并发(如数百或上千并发用户)快速探测系统初步性能表现,观察CPU、内存、网络I/O等资源利用率。 2. **阶梯式加压**:采用“逐步递增”策略,每次增加10个并发用户(或按固定比例递增),记录每个阶段的请求成功率、响应时间(RT)、错误率等指标。 3. **触底反弹测试**:当系统开始出现请求失败(如HTTP 5xx错误、超时)时,逐步降低并发数,找到系统性能拐点(即稳定状态下的最大QPS)。 4. **资源监控**:结合系统监控工具(如Prometheus、Grafana)实时查看资源瓶颈(如CPU满载、数据库连接池溢出),分析性能瓶颈所在。 **四、集群规模计算与扩展策略** 获取单机极限QPS后,可通过以下公式估算所需节点数: **总QPS需求 ÷ 单机极限QPS ≈ 集群节点数量** 例如:若业务预期极限QPS为10,000,单机测试极限为2,000,则初步需部署5台服务器。但需考虑以下因素进行调整: - **冗余设计**:通常预留20%-30%冗余容量以应对突发流量或节点故障。 - **负载均衡效率**:不同负载均衡算法(如轮询、加权轮询、最少连接)可能影响实际利用率。 - **资源异构性**:不同服务器配置(CPU核数、内存、SSD vs HDD)会导致实际QPS差异,需按标准化配置校准。 **五、扩展过程中的其他关键要素** 1. **自动化扩缩容**:结合云平台或容器技术(如Kubernetes),通过实时监控QPS、资源利用率触发自动扩容,提升弹性。 2. **分层压力测试**:不仅测试单机,还需对集群整体进行压力测试,验证负载均衡器、服务注册与发现机制的稳定性。 3. **容错机制**:设计熔断、降级策略,确保部分节点故障时不影响整体服务。 4. **成本优化**:通过压测数据优化资源配置(如垂直扩展vs水平扩展),避免过度采购。 **六、压力测试工具使用注意事项** - **环境一致性**:测试环境与生产环境尽量保持一致(硬件、软件版本、网络配置),避免结果偏差。 - **模拟真实场景**:配置合理的请求分布(如80%常规请求+20%复杂查询),避免单一类型请求导致测试结果失真。 - **数据预热**:测试前预热缓存、数据库连接池,减少冷启动对测试结果的影响。 - **失败阈值设定**:明确定义“失败”标准(如响应时间>500ms或错误率>1%),避免过早终止测试。 **七、总结与最佳实践** 通过科学的压力测试和业务需求对齐,可以量化系统性能边界,为集群扩展提供数据支撑。实践中建议: 1. **周期性压测**:随业务迭代定期重新评估单机性能,调整集群规模。 2. **分阶段部署**:先按预估规模部署,逐步增加流量验证,动态调整。 3. **多维度监控**:结合APM工具(如New Relic、Pinpoint)深入分析请求链路,优化性能瓶颈。 在分布式系统架构中,压力测试不仅是容量规划的基石,更是保障用户体验、降低运维风险的核心手段。只有将业务需求、技术测试与动态扩缩容策略紧密结合,才能构建出真正高可用的弹性架构。 --- **扩展说明**: 1. **内容深度**:补充了集群规模预估的具体步骤、测试工具对比、资源监控的重要性、计算公式细化等细节。 2. **结构完善**:新增“扩展策略调整因素”“其他关键要素”等章节,增强逻辑连贯性。 3. **实践指导**:加入自动化扩缩容、分层测试、成本优化等工程实践经验,提升实用性。 4. **语言扩展**:通过分点列举、场景化描述等方式扩展段落,保持专业性的同时增强可读性。
集群主机准备
按照预估的规模部署web服务器,上面都部署好一模一样的东西,然后管理要搭配负载均衡器、文件共享服务器、数据库数据库缓存、CDN缓存
时间、IP规划、初始化
负载均衡服务器或硬件
web服务器
文件服务器
数据库服务器
**集群主机准备:构建高性能、高可用性的分布式系统架构** 在准备集群主机时,需要综合考虑系统规模、性能需求、资源利用率及高可用性等因素,通过科学规划与部署,构建稳定可靠的分布式架构。以下将从环境部署、组件配置、资源规划、初始化流程等多个维度展开详细说明。 **一、Web服务器部署与一致性保障** 首先,根据预估的业务规模(如并发量、数据量、访问峰值等)部署Web服务器集群。每台服务器需配置相同的操作系统版本、Web服务软件(如Nginx/Apache)、应用程序版本及依赖库,确保请求分发时的一致性。
为避免配置差异导致的服务异常,建议采用自动化工具(如Ansible、Puppet或Docker镜像)进行批量部署,同时定期同步配置模板,减少人工干预带来的风险。 **二、负载均衡器的选型与配置** 负载均衡是集群的核心组件,负责将请求均匀分配到后端服务器,提升系统整体吞吐量并防止单点过载。需根据场景选择软件负载(如Nginx/HAProxy)或硬件负载(如F5/A10),前者成本较低且灵活,后者适合高并发场景。配置时需关注以下要点: 1. **算法选择**:根据业务特点选用轮询、最少连接、IP哈希等调度算法,例如对需要会话保持的场景优先使用IP哈希。 2. **健康检查**:定期检测后端服务器状态(如端口响应、HTTP状态码),自动隔离故障节点。 3. **高可用设计**:部署主备负载均衡器,通过Keepalived等工具实现VIP漂移,防止单机故障导致服务中断。 **三、文件共享服务器与存储优化** 对于需要共享文件(如静态资源、用户上传数据)的场景,需搭建独立的文件服务器。可选方案包括: - **传统NFS/Samba**:适合中小规模,部署简单,但性能受限于网络带宽。 - **分布式文件系统(如GlusterFS/Ceph)**:提供高扩展性、数据冗余及并行读写能力,适合海量文件存储。 - **对象存储(如MinIO/S3兼容方案)**:适用于非结构化数据,支持高并发访问与跨地域冗余。 同时,需规划存储策略:将热点文件缓存至本地SSD,冷数据归档至低成本存储介质,并通过CDN加速边缘访问。 **四、数据库与缓存层设计** 数据库是系统性能瓶颈的关键点,需分层优化: 1. **数据库服务器**:部署主从复制或集群模式(如MySQL Group Replication、PostgreSQL流复制),确保数据一致性及读写分离。 2. **数据库缓存**:引入Redis/Memcached等内存数据库,缓存高频读写数据(如用户会话、热点商品信息),降低数据库压力。 3. **CDN缓存**:在边缘节点缓存静态资源(HTML/CSS/JS/图片),通过智能DNS解析将用户请求导向最近的节点,减少源站带宽消耗。需配置缓存策略(如TTL时间、动态内容缓存规则),并定期更新缓存版本避免数据过期。 **五、时间与IP规划** 1. **时间同步**:集群内所有服务器需通过NTP协议与权威时间源同步(如阿里云时间服务器),防止日志记录、证书验证等因时间偏差引发问题。 2. **IP地址分配**: - 内部网络:按功能划分子网(如Web服务器段、数据库段、管理段),使用私有IP并通过防火墙限制跨网段访问。 - 公网IP:为负载均衡器、文件服务器分配固定IP,或使用弹性IP绑定浮动实例。 - VIP配置:负载均衡器使用虚拟IP(VIP)作为入口,后端服务器绑定真实IP(Real IP),确保请求转发透明化。 **六、初始化流程与系统优化** 1. **服务器初始化**: - 安装基础环境:安全加固(禁用不必要的服务、配置防火墙)、内核参数调优(如TCP连接数、文件句柄限制)。 - 部署监控工具:如Prometheus+Grafana监控资源利用率,ELK Stack收集日志分析异常。 2. **性能调优**: - 数据库:优化索引设计、SQL语句,配置连接池参数。 - Web服务器:启用Gzip压缩、HTTP/2协议,调整并发连接数限制。 - 文件服务器:配置读写缓存、优化I/O调度算法(如Deadline或NOOP)。 **七、高可用性与容灾设计** 为应对硬件故障、网络中断等风险,需构建多层次的容灾机制: - **硬件冗余**:关键节点(如负载均衡器、数据库主节点)采用双机热备或集群化部署。 - **数据备份**:定期全量/增量备份数据库,异地存储保证数据可恢复性。 - **故障切换演练**:定期模拟节点宕机,验证自动切换流程的有效性,优化切换时间窗口。 **八、实施流程与注意事项** 1. **分阶段部署**:先搭建最小化集群测试环境,逐步扩容验证稳定性,避免一次性部署带来的风险。 2. **文档与版本控制**:记录每个组件的版本、配置参数及变更记录,使用Git等工具管理配置脚本。 3. **安全合规**:加密敏感数据(如数据库连接密码)、启用SSL证书、配置访问控制白名单,遵循安全审计要求。 **总结** 集群主机准备是一个系统工程,需从架构设计、资源分配、自动化运维到安全合规全方位考量。通过合理的负载均衡、缓存分层、高可用设计,不仅能提升系统性能,还能降低运维复杂度与故障风险。在实施过程中,应坚持“逐步验证、迭代优化”的原则,结合业务需求动态调整配置,确保集群始终处于最佳运行状态。 --- **扩写说明:** - **内容扩展**:在原有基础上增加了自动化部署工具、存储优化方案、数据库缓存与CDN缓存的区别、时间同步的重要性、性能调优细节、容灾设计等内容,覆盖更多技术细节和实际实施中的考虑因素。 - **结构优化**:分点分模块阐述,逻辑更清晰,便于读者按需查阅。 - **深度提升**:针对每个组件补充了选型建议、配置要点及常见问题解决方案,增强实用性。
集群架构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号