

shell编程6之sed、awk
sed
sed简介
sed全称(stream editor)流式编辑器,工作原理是:sed命令在执行的时候会启动一个进程,启动一个进程会开辟一个内存空间,这个内存空间叫模式空间(指的是字符串里写的正则表达式以及匹配到了干什么事),这个空间申请好了就是专门读进来一行内容用正则表达式匹配一下它,匹配成功了干什么事,先定位(行号定位或者正则定位)后操作(命具体令p,d,s命令还需要写左斜杠把谁换成什么)。
sed的全称是stream editor,即流式编辑器。其工作原理如下:
当执行sed命令时,会启动一个独立的进程,而这个进程会开辟一块特定的内存空间,这块空间被称为模式空间。
模式空间内包含了用户指定的正则表达式以及匹配成功后需要执行的操作。
一旦这个空间准备就绪,sed就会逐行从输入中读取内容,然后利用其中的正则表达式进行匹配。
如果匹配成功,sed会根据预先设定的定位方式(如行号定位或正则表达式定位)来确定操作的位置,最后执行相应的操作(比如p命令用于打印,d命令用于删除,s命令用于替换,在使用s命令时还需要通过左斜杠来指定替换的具体内容,将匹配到的文本替换为所需内容)。
sed命令
基本语法:在命令行指定sed命令
sed [OPTIONS]... 'COMMAND' [FILE]...
或者:将sed命令写到一个文件中并将其文件名作为参数
sed [OPTIONS] -f SCRIPTFILE [FILE]...
p命令:打印
d命令:删除
s命令:替换语法
[address]s/pattern/replacement/flags
sed -r 's/^([a-zA-Z]+)([0-9]+)/\2\1/' a.txt
i:忽略大小写
sed 's/Zrg/root/i' a.txt
e命令:连接多个规则
!命令:反向选择
r命令:读
sed '2r b.txt' a.txt
w命令:写
a命令:追加
sed常用选项
-i 把原本流出到屏幕的内容覆盖写回源文件,通常写sed命令的时候,通常先不加-i,先看看输出的结果是什么,这些结果如果符合预期再加-i把结果扔到源文件里面去。
在使用sed命令时,选项中的一项重要功能是-i。这个选项的作用是将原本应该输出到屏幕的内容直接覆盖写回到源文件中。在实际操作过程中,为了确保命令执行的结果符合预期,通常建议先不加-i选项进行测试。通过这样的初步测试,用户可以观察输出的结果是否与需求相符。如果结果符合预期,再使用-i选项将修改结果写入源文件,这样可以避免因误操作而导致的文件内容被错误修改的风险。
-n 取消默认的流出
-f 指定sed脚本文件名
-e 可以连接多个规则,如果不用-e,多个规则只需要用分号分隔开也行
sed '1p;2d' a.txt sed -e '1p' -e '2d' a.txt
-r 启用扩展的元字符(正则表达式)。
sed -rn '/a?bc/p' a.txt
sed正则定位
行号定位可以直接写具体的第几行,也可以指定范围用逗号隔开起始行,$代表最后一行。
如果行号定位于正则定位结合使用,匹配成功一次就结束。
/ /可以用 ##或者 @@代替,但是需要给它们转义一下
模式空间和保持空间
保持空间是在模式空间处理数据的过程当中临时保存数据。
h命令:把模式空间的数据覆盖到保持空间。
H命令:把模式空间的数据追加到保持空间。
g命令:把保持空间里的数据覆盖到模式空间。
G命令:把保持空间里的数据追加到模式空间。
awk
awk非常擅长处理有固定格式的文本文件。
awk的语法:
awk命令后面跟-F制定分隔符 再跟引号里面写模式和操作,模式就是定位分两种,行号定位和正则定位,操作要写在花括号内,最后是要操作的文件。
当然还可以把模式和操作写到一个文件里面,然后再命令行awk -f 后面跟写的文件名 再跟要操作的文件。
awk 是一种功能强大的文本处理工具,特别适合处理具有固定格式的文本文件。其语法结构灵活且高效,使得用户在处理数据时能够迅速得到所需结果。 在使用 awk 时,其基本语法包括:首先通过 -F 参数指定输入文本中的分隔符,这有助于 awk 正确地划分数据字段。 随后,用户可以在单引号或双引号内定义模式和操作。 模式用于定位需要处理的文本行,可以基于行号或正则表达式进行定位。 一旦定位到目标行,操作部分将在花括号内执行,这些操作可以包括打印、修改、计算等。 除了在命令行中直接指定模式和操作外,awk 还允许用户将复杂的模式和操作写到一个独立的脚本文件中。 通过使用 -f 参数,后面跟上脚本文件的名称,再指定要处理的文本文件,用户可以方便地执行预先编写好的 awk 脚本。 这种方式不仅提高了代码的可读性和可维护性,还能在处理大型文本文件时显著提高效率。 总之,awk凭借其灵活的模式匹配和强大的数据处理能力,成为文本处理领域不可或缺的工具。无论是简单的数据提取还是复杂的数据转换,awk 都能帮助用户快速、有效地完成工作。
awk工作原理 :
首先上来先运行GEGIN里面的操作
读一行内容开始处理的时候,读一行交给花括号里来处理,在交给花括号处理的时候会讲读入的那一整行内容赋值给$0。
然后将以分隔符分开的第一段内容赋值给$1,第二段给$2,以此类推最多支持100个字段
然后会把分割的段数赋值给NF,NR是行号。
这些内置变量生成好之后就开始执行花括号里的命令,比如print、
等所有都处理完之后再运行END里的操作。
awk工作原理 : 首先,当awk程序启动时,会先执行BEGIN块中的操作,这部分操作通常用于初始化变量或设置程序的状态。
接着,awk开始逐行读取输入数据,每当读入一行时,便会执行相应的模式匹配与动作。 在处理每一行时,awk会将整行内容赋值给内置变量$0这使得用户可以方便地访问整行的文本。
随后,awk根据指定的分隔符(默认为空格)将这一行分割成多个字段,并将第一个字段赋值给$1,第二个字段赋值给$2,依此类推。𝑎𝑤𝑘支持最多100个字段,每个字段可以通过相应的变量名来访问,awk支持最多100个字段,每个字段可以通过相应的变量名来访问。
例如,$3表示第三段内容。 除了字段变量,awk还提供了其他内置变量,如NF和NR。
NF表示当前行被分割后的字段数量,而NR则表示当前处理的行号。这些内置变量在处理数据时非常有用,可以帮助用户进行条件判断和循环控制。 当内置变量生成完毕后,awk便开始执行花括号{}中的命令。这些命令可以是对数据的各种处理操作,如打印输出(print)、条件判断(if-else)、循环控制(for、while)等。花括号中的命令是awk程序的核心部分,用户可以根据具体需求编写相应的处理逻辑。 在所有行都处理完毕后,awk会执行END块中的操作。这部分操作通常用于输出最终结果、清理资源或进行其他收尾工作。通过BEGIN、模式匹配与动作、以及END这三个部分的协调工作,awk能够灵活而高效地处理各种文本数据。
awk格式化输出
awk -F: '{printf "用户名是: %s uid是: %s\n",$1,$3}' /etc/passwd
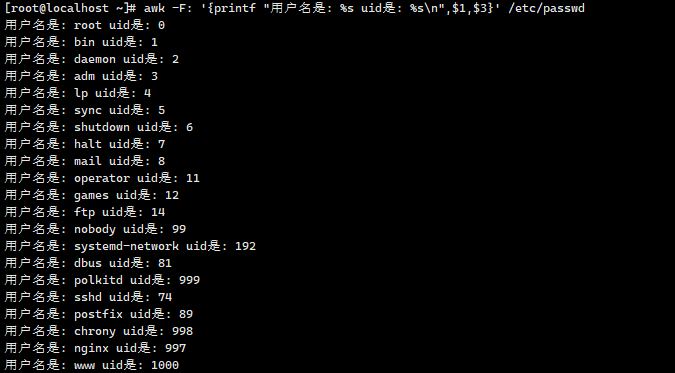
模式(pattern)与动作(action)
模式可以用正则匹配也可以用行号匹配还可以二者结合使用去匹配整行或匹配一行的某个字段。
行号是NR:比如'NR>=1 && NR==5',默认就是一整行。
比较表达式:
条件表达式:
算术运算:
awk流程控制
制作系统服务
[root@localhost ~]# systemctl status network ● network.service - LSB: Bring up/down networking Loaded: loaded (/etc/rc.d/init.d/network; bad; vendor preset: disabled) Active: active (exited) since 五 2025-06-20 12:12:51 CST; 1 weeks 0 days ago Docs: man:systemd-sysv-generator(8) 6月 20 12:12:51 localhost.localdomain systemd[1]: Starting LSB: Bring up/down networking... 6月 20 12:12:51 localhost.localdomain network[784]: 正在打开环回接口: [ 确定 ] 6月 20 12:12:51 localhost.localdomain network[784]: 正在打开接口 ens33: [ 确定 ] 6月 20 12:12:51 localhost.localdomain systemd[1]: Started LSB: Bring up/down networking. [root@localhost ~]# systemctl start network [root@localhost ~]# systemctl stop network
systemctl 管理服务好处是:所有的服务(进程)被systemctl管理起来更统一。
如果是yum安装的NGINX默认就会加到systemctl里面被它管理起来,但是源码安装的不行
源码安装的怎么统一的被systemctl管理起来?往systemctl命令的配置文件里面加一些配置,配置文件是/usr/lib下的或者是/lib目录下的systemd文件,这个文件里有两个目录system和user,我们是往system目录里面加东西,system是系统服务不用登录用户就能启动服务,而user里面放的是一些用户服务需要登录。
往system目录里加什么东西呢?它里面有两种文件,一种是.target结尾的,另一种是.service结尾的,我们主要关注.service文件。我们要把源码安装的软件(程序)被systemctl统一管理起来,我们就往/usr/lib/systemd/system目录下放一个.service结尾的文件。
这个文件里面些什么呢?三大块东西:第一块[Unit],第二块[Service],第三块[Install]。
**使用systemctl统一管理服务的优势与源码安装服务的配置方法** 使用systemctl管理服务的核心优势在于其统一性和便捷性。通过systemctl,所有系统服务(进程)被集中管理,用户可以通过统一的命令接口实现服务的启动、停止、重启、状态查询等操作,极大地简化了系统运维的复杂性。
例如,当通过yum或rpm等包管理工具安装NGINX时,安装程序会自动将NGINX注册为systemctl管理的服务,这意味着用户可以直接使用`systemctl start nginx`、`systemctl status nginx`等命令进行操作,无需额外配置。
然而,对于通过源码编译安装的软件(如手动编译安装的NGINX、MySQL或其他自定义程序),默认情况下它们并不会自动被systemctl识别和管理。此时,需要手动进行配置,将其纳入systemctl的统一管理框架。 要实现这一目标,关键在于理解systemd的配置文件结构和配置文件的创建。systemd作为Linux系统的初始化系统和服务管理器,其配置文件主要存放在`/usr/lib/systemd/system`和`/lib/systemd/system`目录下(不同发行版可能略有差异)。
这两个目录中,`/lib/systemd/system`通常存放系统自带的系统服务配置,而`/usr/lib/systemd/system`则常用于存放第三方或用户自定义的服务配置。此外,还有`/etc/systemd/system`目录,用于覆盖或修改默认配置(优先级最高)。 在配置源码安装的服务时,我们需要在`/usr/lib/systemd/system`(或根据需要选择其他目录)下创建以`.service`为后缀的配置文件。
例如,为源码安装的NGINX创建一个名为`nginx.service`的文件。这个文件采用INI格式,分为多个配置块,其中最关键的是三大块:[Unit]、[Service]、[Install]。
每个配置块负责不同的功能,下面将详细解析。 **1. [Unit]配置块:服务的基本信息和依赖关系** [Unit]部分定义了服务的基本属性和与其他服务的依赖关系。常见的参数包括: - **Description**:服务的描述信息,便于管理员识别服务用途。 - **After**:指定服务启动的顺序,例如`After=network.target`表示该服务在network服务启动后启动。 - **Requires**:声明服务依赖的其他服务,若依赖的服务未启动,当前服务将无法启动。 - **Wants**:类似于Requires,但依赖关系较弱,即使依赖服务未启动,当前服务仍可尝试启动。 例如: ``` [Unit] Description=NGINX Web Server After=network.target Requires=network-online.target ``` **2. [Service]配置块:服务的具体运行参数** [Service]部分是核心,用于定义服务的启动、停止命令、运行类型等。关键参数包括: - **Type**:服务类型,常见值有: - `simple`(默认):服务进程直接由systemd启动。 - `forking`:服务进程启动后会通过fork创建子进程,父进程退出,子进程继续运行(如传统SysVinit脚本)。 - `oneshot`:服务执行一次性任务,完成后立即退出。 - **ExecStart**:启动服务的命令,可包含参数。 - **ExecStop**:停止服务的命令。 - **PIDFile**:指定进程ID文件路径,systemd通过该文件监控进程状态。 例如: ``` [Service] Type=forking ExecStart=/usr/local/nginx/sbin/nginx ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/bin/kill -s QUIT $MAINPID PIDFile=/usr/local/nginx/logs/nginx.pid ``` **3. [Install]配置块:服务的安装与关联** [Install]部分指定服务如何被systemctl启用或禁用。主要参数为: - **WantedBy**:将服务添加到指定的目标单元(target),例如`multi-user.target`(系统默认运行级别)。 - **RequiredBy**:不推荐使用,用于强制指定依赖关系。 例如: ``` [Install] WantedBy=multi-user.target ``` **完整示例:NGINX的.service配置文件** ``` [Unit] Description=NGINX Web Server After=network.target Requires=network-online.target [Service] Type=forking ExecStart=/usr/local/nginx/sbin/nginx ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/bin/kill -s QUIT $MAINPID PIDFile=/usr/local/nginx/logs/nginx.pid [Install] WantedBy=multi-user.target ``` **配置完成后,需执行以下步骤使配置生效**: 1. 保存配置文件(如`/usr/lib/systemd/system/nginx.service`)。 2. 运行`systemctl daemon-reload`命令重新加载systemd配置。 3. 使用`systemctl enable nginx`将服务设置为开机自启。 4. 通过`systemctl start nginx`启动服务,并可用`systemctl status nginx`验证状态。 **注意事项与最佳实践**: - **权限与路径**:确保`.service`文件权限为644,属主为root。所有命令路径需使用绝对路径,避免因环境变量问题导致启动失败。 - **日志与错误排查**:若服务无法启动,可查看systemd日志(如`journalctl -u nginx`)或进程日志(如NGINX的error.log)定位问题。 - **多实例管理**:若需部署多个实例,可通过参数传递(如`ExecStart=/path/to/binary --config /path/to/config-$i`)结合实例标识实现。 - **兼容性考虑**:不同版本的systemd可能对参数支持有差异,建议参考官方文档或发行版文档调整配置。 **systemd的优势与系统管理扩展**: 除了统一服务管理,systemd还提供诸多高级特性,如: - **并行启动**:通过依赖关系定义,实现服务按顺序并行启动,缩短系统启动时间。 - **服务状态跟踪**:精确记录服务启动、停止、重启的每个阶段状态。 - **资源隔离**:通过cgroup集成,控制服务的内存、CPU等资源限制。 - **系统快照与恢复**:支持将系统状态保存为快照,便于故障恢复或调试。 通过合理配置systemd,管理员可以构建高效、可靠的服务管理体系,显著提升系统稳定性和运维效率。无论是系统服务还是自定义应用,纳入systemctl管理后,都将受益于其强大的生命周期管理和自动化能力。
[Unit] Description=NGINX Web Server After=network.target Requires=network-online.target [Service] Type=forking ExecStart=/usr/local/nginx/sbin/nginx ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/bin/kill -s QUIT $MAINPID PIDFile=/usr/local/nginx/logs/nginx.pid [Install] WantedBy=multi-user.target
journalctl -xe
进程锁
具体在开发shell脚本过程中用不上,单纯只是为了理解锁文件的概念,使用系统当中可能会碰到这种lock文件,要知道它的作用是什么。
同一时间只允许脚本运行一次怎么实现?
原理很简单,我们在每次启动这个脚本的时候在脚本里用echo命令把获取到自己的pid号 $$直接写到一个文件里 >/tmp/my.lock,这样永久保存以后,下次再启动的时候,检测这个文件,根据这个文件存在与否来决定这个脚本允不允许再次启动。完善一下是根据pid是否存在。
#!/bin/bash lock_file=/tmp/my.lock #先检测锁文件存不存在 if [ -f $lock_file ]; then echo "锁文件存在,本次启动失败!" pid=`cat $lock_file` ps $pid &>/dev/null if [ $? -eq 0 ]; then exit else rm -rf $lock_file fi fi #锁文件不存在 echo $$ > $lock_file echo "启动了,pid为:$$" #释放掉锁文件 rm -rf $lock_file
**锁文件在Shell脚本中的作用及同一时间仅允许脚本运行一次的实现原理** 在开发Shell脚本的过程中,尽管有时可能不会直接应用锁文件的概念,但理解其作用对于系统管理和脚本健壮性至关重要。锁文件(Lock File)是一种用于控制资源访问的机制,通常用于确保同一时间只有一个进程或脚本能够执行关键操作,避免并发冲突或数据损坏。在系统运维中,常见的锁文件应用场景包括系统服务启动、资源抢占、定时任务排他执行等。了解锁文件的工作原理,有助于我们更好地维护脚本的可靠性。 **锁文件的作用解析** 锁文件的核心思想是通过文件的存在性作为“互斥锁”(Mutex)的标记。当脚本需要执行独占性操作时,首先检查指定路径下是否存在锁文件。若文件不存在,则创建锁文件并执行后续逻辑;若文件已存在,说明有其他进程正在执行,当前脚本应退出或等待。这种机制避免了多个实例同时修改同一文件、访问共享资源或执行冲突操作,从而保证数据一致性和系统稳定性。 **同一时间仅允许脚本运行一次的实现方法** 实现该功能的基本原理是利用进程ID(PID)作为锁文件的唯一标识。具体步骤如下: 1. **创建锁文件**: 脚本启动时,通过`echo $$ > /tmp/my.lock`将当前进程的PID写入临时文件(如`/tmp/my.lock`)。`$$`是Shell中获取当前进程PID的内置变量,因此该操作会将PID永久保存到文件中。 2. **检测锁文件**: 在脚本执行逻辑前,首先检查锁文件是否存在。例如使用`[ -f /tmp/my.lock ]`判断文件是否已存在。若存在,则进一步检查文件中的PID对应的进程是否仍在运行。 3. **验证进程状态**: 由于仅通过文件存在性判断可能不够准确(例如脚本异常退出后锁文件残留),需通过`kill -0 $PID`(或`ps -p $PID >/dev/null 2>&1`)尝试向PID发送信号。若命令返回0,说明进程活跃,脚本应退出;若返回非0,则可能是残留的锁文件,可以安全删除并继续执行。 4. **释放锁文件**: 脚本正常退出前,应删除锁文件以释放资源,避免后续执行受阻。通常使用`rm -f /tmp/my.lock`在脚本末尾或退出逻辑中删除文件。 **完整示例代码**: ``` #!/bin/bash # 锁文件路径 LOCK_FILE="/tmp/my.lock" # 检查锁文件是否存在 if [ -f "$LOCK_FILE" ]; then # 读取锁文件中的PID PID=$(cat "$LOCK_FILE") # 验证PID对应的进程是否存活 if kill -0 "$PID" 2>/dev/null; then echo "脚本已运行(PID: $PID),本次执行终止!" exit 1 else # 进程不存在,可能是残留锁文件,删除后继续执行 rm "$LOCK_FILE" echo "清理残留锁文件,本次PID: $$" fi fi # 创建新的锁文件 echo $$ > "$LOCK_FILE" # 执行脚本核心逻辑... echo "脚本正在执行..." # 脚本结束前释放锁文件 rm "$LOCK_FILE" echo "脚本执行完毕,锁文件已释放。" ``` **注意事项与优化** - **锁文件路径选择**:通常存放于临时目录(如`/tmp`)或脚本专用目录,避免与其他程序冲突。 - **进程验证的重要性**:仅检查文件存在性可能导致误判,必须通过PID验证进程状态。 - **锁文件命名规范**:建议包含脚本名称或功能标识,例如`my_script.lock`,便于排查。 - **错误处理**:若脚本异常退出,锁文件可能残留。可设置信号捕获(如`trap "rm $LOCK_FILE" EXIT`)确保退出时释放锁。 - **高并发场景**:若需支持高并发控制,建议使用`flock`命令(Linux特有)实现更可靠的文件锁机制,例如: **应用场景扩展** 锁文件不仅用于脚本单次运行控制,还可用于: - 系统服务启动:防止重复启动守护进程。 - 数据库备份脚本:避免多个实例同时读写数据库。 - 资源抢占任务:确保同一资源仅被一个进程使用。 - 定时任务排他:结合cron,防止任务重叠执行。 **总结** 通过锁文件机制,Shell脚本能够有效地实现互斥执行,确保系统资源的安全性和操作的一致性。理解其原理和实现细节,有助于开发更健壮、可靠的脚本程序。在实际应用中,需结合具体场景考虑锁文件的路径、进程验证、错误处理等细节,以确保机制的可靠性和灵活性。 ---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号