

进程管理下
一些特殊进程:
僵尸进程:所有的Linux系统的进程在死之前都会进入僵尸进程这个状态。因为父进程和子进程的运行都是并发运行的,不一定谁先运行完;
操作系统怎么处理运行完了的进程?有两种方式,第一种运行完把进程的所有信息都删掉,另外一种方式是运行完后不要把这个进程的所有东西都删掉,把它的一些存在过的证据(例如pid)留一点下来,此时的这种状态就是僵尸状态。
linux操作系统为什么这样做?就是为了给父进程提供一种便利。
僵尸进程过多的处理方式:
找到父进程杀掉:
先找到PPID:
ps -elf |grep Z
然后根据PPID杀掉:
kill-9 PPID号
杀完之后它们的PPID都会变成1,很会1就会回收掉它们。
孤儿进程:子进程没死,父进程死了。变成孤儿会被1号进程收养,我们一般都指的是用户态的进程,内核态的进程不归我们管,我们是在操作系统之上起各种应用程序,所以说我么用户态的进程死掉之后都会被1号进程(用户态的老祖宗)接管。
守护进程:不需要交互而且是在后台运行的进程。


僵尸进程、孤儿进程与守护进程:Linux系统中的进程状态与处理机制 在Linux操作系统中,进程管理是系统资源调度的核心部分。当进程终止时,其状态转换并非直接消失,而是会经历特定的中间状态,其中“僵尸进程”和“孤儿进程”是两个关键概念,而“守护进程”则体现了进程在后台运行的独特模式。本文将深入探讨这些状态的产生原因、处理方式及其系统设计的逻辑。 一、僵尸进程:进程终结后的“残留证据” 所有Linux系统的进程在终止前都会进入僵尸进程(Zombie Process)状态。由于父进程和子进程并发运行,无法确定谁先结束,因此操作系统需要一种机制来确保父进程能够获取子进程的退出状态。当子进程运行完毕时,操作系统并不会立即删除其所有信息,而是保留部分关键数据(如PID、退出代码、运行时间等),使其处于僵尸状态。这种设计的目的在于为父进程提供便利:父进程可以通过wait()或waitpid()系统调用读取子进程的退出状态,从而了解其执行结果(如是否成功、错误代码等)。若子进程直接删除所有信息,父进程将无法获取这些关键数据,导致进程管理出现信息断层。 僵尸进程的存在本身不会占用大量系统资源(仅保留少量元数据),但若父进程未及时调用wait()处理子进程,导致大量僵尸进程堆积,可能会耗尽系统的PID资源(PID是有限的整数),进而影响新进程的创建。因此,僵尸进程过多通常意味着程序设计存在问题或父进程异常终止。 二、处理僵尸进程:从根源解决父进程问题 当系统中僵尸进程过多时,需要从根源解决问题——即找到并处理其父进程。具体步骤如下: 1. 查找僵尸进程的父进程ID(PPID):使用命令ps -elf | grep Z,筛选出状态为“Z” (僵尸)的进程,并查看其PPID列。 2. 终止父进程:通过kill -9 PPID号强制结束父进程。此时,原本属于该父进程的所有僵尸子进程将失去归属,系统会将它们的PPID自动改为1(即init进程,系统的初始化进程)。 3. 由init进程回收资源:init进程作为所有用户态进程的老祖宗,会定期检查并回收孤儿进程和僵尸进程的资源,从而释放PID等系统资源。 需要注意的是,直接杀死父进程可能影响其他正常子进程,因此需确认父进程是否确实无必要继续运行。此外,更稳妥的方式是修复父进程的代码,使其正确调用wait()函数处理子进程,避免僵尸进程的产生。 三、孤儿进程:父进程终止后的“收养机制” 与僵尸进程相反,“孤儿进程”是指子进程仍在运行,但其父进程已终止的情况。此时,子进程会被init进程(PID为1)收养,成为init的子进程。系统会自动将孤儿进程的PPID改为1,并由init负责其生命周期管理。孤儿进程本身并非问题,因为init会确保它们正常退出并回收资源。用户态进程(即普通应用程序)死掉后,都会被init接管,而内核态进程(如系统核心模块)则由内核直接管理,不归用户态的init处理。 四、守护进程:后台服务的核心形态 守护进程(Daemon Process)是Linux系统中一类特殊进程,其特点为: ● 后台运行:脱离终端控制,不接收用户交互; ● 独立于会话和终端:即使用户退出登录,守护进程仍继续运行; ● 长期服务:常用于系统服务(如网络服务、日志管理、定时任务等)。 守护进程通常通过编程实现,需遵循特定的创建规则:如脱离控制终端、重定向标准输入输出到文件、进入后台运行等。例如,常见的守护进程包括sshd(SSH服务)、crond(定时任务)、syslogd(日志服务)等。它们独立运行,确保系统功能的持续可用性,且不占用用户界面资源。 五、系统设计逻辑与资源管理 Linux进程状态设计反映了资源管理的权衡: ● 僵尸进程的存在牺牲了部分资源(PID等元数据)换取信息完整性,确保父进程能获取子进程结果; ● 孤儿进程的收养机制保障系统稳定性,避免无主进程成为资源黑洞; ● 守护进程则通过独立化设计,满足后台服务的需求。 开发者在编写程序时,需注意正确处理子进程退出(如显式调用wait()),避免僵尸进程堆积;同时,设计守护进程时需遵循规范,确保其独立性和可靠性。 总结 理解僵尸进程、孤儿进程与守护进程,不仅有助于排查系统资源问题(如PID耗尽、内存泄漏),还能提升程序设计的健壮性。Linux通过精巧的进程状态转换和收养机制,实现了资源的高效管理与服务的持续运行,为多任务系统提供了稳定基础。
管理进程
1、修改进程的优先级
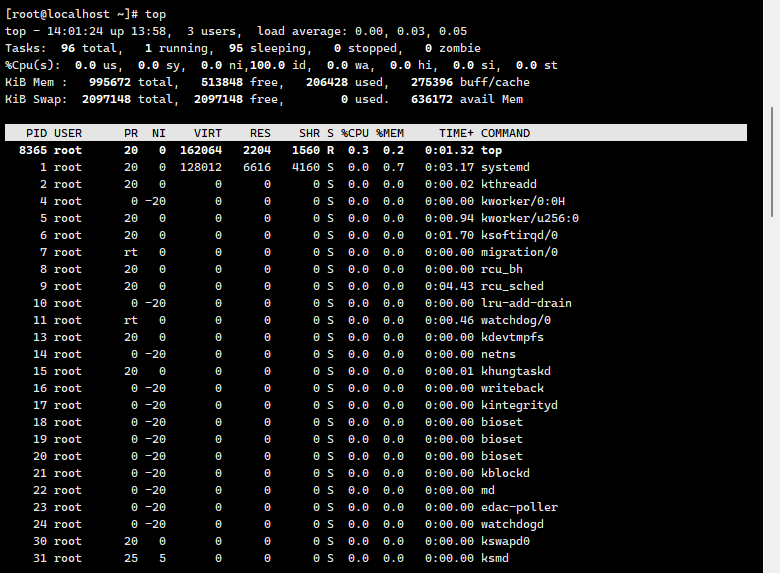
在top命令中我们看到进程有NI值,这是跟进程的优先级有关系的。优先级高代表操作系统会尽可能多的把CPU给这个进程用,也就能尽快的运行完。
跟优先级指标有关的指标有两个:
PR:是在内核态里面用的一个值,一个进程在运行过程中涉及内核态和用户态的切换。
NI:是用户态的一个值。
区别:我们能操作的是都是用户态的东西。PR值=20+NICE值。PR值是真正能决定进程优先级的,这个值的特点是值越小优先级越高,对应的NI值也是值越小优先级越高(范围是-20到+19)。
对一个新起的进程这么修改:
nice -n 数字 command
如果是一个已经起来的进程:
renice number PID
**进程优先级调整与top命令中的NI值解析** 在Linux系统的性能监控工具top中,进程列表中的NI(Nice值)是一个关键指标,它直接关联到进程的调度优先级。优先级高的进程会被操作系统优先分配CPU时间片,从而更快地完成计算任务。理解并合理调整进程优先级,对于优化系统资源分配、提升关键任务的执行效率至关重要。本文将深入解析进程优先级的概念、相关指标以及调整方法。 **1. 进程优先级与NI值的关系** 进程优先级由两个核心指标决定:**PR(Priority,优先级)****和****NI(Nice值)**。 - **PR值(内核态优先级)**:由内核直接管理,用于决定进程在调度队列中的位置。PR值越小,优先级越高。例如,PR值为0的进程比PR值为20的进程更可能被优先调度。 - **NI值(用户态优先级)**:用户可以通过命令修改的数值,范围从-20到+19。NI值越小(如-20),优先级越高;反之,NI值越大(如+19),优先级越低。 - **PR与NI的关系**:PR值实际由NI值推导而来,公式为 **PR = 20 + NI**。因此,调整NI值会直接影响PR值,进而影响调度顺序。 **2. 内核态与用户态的切换** 进程在执行过程中会频繁切换状态,包括内核态和用户态: - **内核态**:进程执行系统调用或访问受保护资源时进入的状态,此时操作系统接管控制权,优先级由PR值决定。 - **用户态**:进程执行普通任务的状态,优先级受NI值影响。 由于用户只能操作用户态下的参数(如NI),因此调整NI值成为控制进程优先级的有效手段。 **3. 调整进程优先级的方法** (1)**启动进程时指定优先级**: 使用`nice`命令,例如: ``` nice -n 10 command ``` 将命令`command`的NI值设置为10(优先级较低),适用于不希望该进程占用过多CPU资源的场景。 (2)**修改已运行进程的优先级**: 通过`renice`命令,例如: ``` renice +5 1234 ``` 将PID为1234的进程NI值调整为+5,降低其优先级。 **4. 优先级调整的实际应用场景** - **高负载系统优化**:当服务器运行多个任务时,可通过降低非核心进程的NI值(如日志记录、备份任务),确保关键服务(如数据库、Web服务器)获得更多CPU资源。 - **实时任务调度**:对于需要低延迟的应用(如音视频处理),将NI值设为负数(如-10)可显著提升响应速度。 - **资源公平分配**:避免单个进程垄断CPU,通过动态调整NI值平衡不同任务的资源占用。 **5. 注意事项与潜在风险** - **过度提升优先级可能导致问题**:若将关键进程的NI值设得太低(如-20),可能导致其他进程长时间无法获得调度,甚至造成系统“饿死”现象。 - **普通用户权限限制**:默认情况下,普通用户只能将NI值调高(降低优先级),而无法调低(提升优先级),除非使用`sudo`或具备特殊权限。 - **系统稳定性**:频繁或不合理地调整优先级可能影响整体性能,需结合监控工具(如top、htop)实时观察系统负载。 **6. 扩展知识:Linux调度策略与优先级** 现代Linux内核采用CFS(完全公平调度器),其优先级机制不仅依赖NI值,还结合进程的历史执行情况、实时性需求等因素。此外,实时进程(如RT优先级)拥有比普通进程更高的调度优先级,适用于硬实时应用场景。
2、进程信号管理
有一条kill命令,从字面意思上来看好像是杀掉的意思,但这条命令准确的意思是给进程发信号。
什么叫发信号呢?是linux系统提供的一个非常强大的功能,对于已经启动起来的那一堆进程我们想要去干预这些进程的运行,可以用kill命令给他们发信号。其实是给操作系统发信号。
kill-9就是干死的意思。
信号有不同的种类,可以用不同的方式去发,其实意思都是一样的。可以用kill -l 去看有哪些信号。

[root@localhost ~]# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX
kill命令通常都要配合ps、pstree等命令来找到对应的进程的PID。
也可以pkill后跟进程名字,不过不建议这么操作。
**Linux中的kill命令:进程信号管理的核心工具** 在Linux系统中,`kill`命令常被误解为“杀死进程”的简单工具,但实际上,它的核心功能是通过发送信号(Signal)来管理进程的行为。这一机制是操作系统提供的一项强大功能,允许用户或系统对已启动的进程进行干预,从而控制其运行状态、资源分配或执行特定的操作。理解`kill`命令的本质,首先需要明确“信号”的概念。 **信号机制:进程通信与控制的桥梁** 信号是Linux系统中进程间通信(IPC)的一种重要方式,它允许一个进程向另一个进程发送预定义的“消息”,接收方进程根据信号类型采取相应的动作。例如,当用户按下Ctrl+C时,终端会向前台进程发送`SIGINT`信号(中断信号),导致进程终止。这种机制使得系统能够灵活地响应用户需求或处理异常情况,而无需直接终止进程。 **kill命令的本质:发送信号而非“杀死”** `kill`命令的语法通常为`kill [信号编号] [进程PID]`,其真正作用是向指定PID的进程发送指定的信号。默认情况下,如果不指定信号编号,`kill`会发送`SIGTERM`(15号信号),提示进程优雅地退出。而`kill -9`(发送`SIGKILL`信号)则是一种强制终止手段,该信号无法被进程捕获、忽略或阻塞,会立即结束进程,常用于处理无法响应其他信号的“顽固”进程。 **信号类型与常用命令** Linux系统定义了多种信号,可通过`kill -l`命令查看完整列表。常见的信号包括: - **SIGTERM(15)**:终止信号,请求进程正常退出。进程收到后有机会清理资源、保存状态,属于“优雅终止”。 - **SIGKILL(9)**:强制终止信号,立即杀死进程,不给予任何处理机会。常用于系统资源紧张或进程无响应时。 - **SIGINT(2)**:中断信号,通常由用户输入(如Ctrl+C)触发,用于终止前台进程。 - **SIGHUP(1)**:挂断信号,常用于通知守护进程重新加载配置。 - **SIGSTOP(19)**:暂停进程,进程会进入停止状态,可通过`SIGCONT`恢复。 - **SIGCONT(18)**:恢复被暂停的进程。 **进程与信号的交互:捕获、忽略与默认行为** 进程对信号的处理方式分为三种: 1. **默认行为**:大多数信号(如`SIGTERM`)有系统定义的默认动作(如退出),除非进程明确修改。 2. **捕获**:进程可通过编程(如使用`signal()`或`sigaction()`函数)自定义信号处理函数,例如忽略用户的中断请求。 3. **忽略**:进程可选择完全忽略某些信号(但`SIGKILL`和`SIGSTOP`无法被忽略)。 **kill命令的实战技巧** - **配合ps、pstree定位进程**:使用`ps -ef`或`pstree`查找进程PID后,再通过`kill`发送信号。例如:`kill -15 $(pgrep nginx)`可终止所有Nginx进程。 - **慎用pkill**:`pkill`通过进程名匹配并发送信号,但可能误杀同名进程,建议优先使用PID精确控制。 - **处理僵尸进程**:若进程异常终止但未释放资源,可使用`kill -9`强制清理父进程,但需谨慎避免影响其他进程。 - **系统维护场景**:例如,通过`kill -HUP 1`(向init进程发送SIGHUP)通知系统重新加载所有配置,或在容器环境中优雅重启服务。 **注意事项与风险提示** 虽然`kill`命令功能强大,但误用可能导致严重后果: - 误杀系统关键进程(如`init`或`sshd`)可能导致系统崩溃或服务中断。 - 使用`kill -9`前应确认进程状态,避免破坏未保存的数据或导致资源泄漏。 - 在多用户环境下,需确保具有足够的权限(如root)才能终止其他用户的进程。 **总结** `kill`命令作为Linux进程管理的核心工具,通过信号机制实现了对进程生命周期的精细控制。理解信号类型、进程响应方式以及合理使用命令参数,既能高效管理系统资源,又能避免因误操作引发的问题。掌握这一工具,是运维和开发人员必备的技能之一。
3、前后台进程管理
可以把一个进程放到后台里面去(&)。
jobs 单指查看自己用&符号加进后台的程序的编号,NGINX都是自己自带&的。
fg 把加入后台的明命令拿回前台。fg后面%跟编号。
前台运行的程序按Ctrl+z 暂停住(就跑到后台去了),然后jobs查看一下它的编号,然后bg %他的编号又能运行起来。
针对这种自己嫁到后台的程序,可以用kill %编号 这个编号就是用jobs查看到的编号。
**前后台进程管理:深入解析与实践技巧** 在Linux或类Unix系统的进程管理中,前后台切换是高效处理多任务的核心机制之一。通过灵活控制进程的执行状态,用户可以更便捷地管理系统资源,尤其是在服务器运维、开发调试或长时间运行任务时,前后台管理显得尤为重要。 首先,将进程放入后台运行的基本方式是使用“&”符号。例如,执行命令 `my_program &` 时,程序会立即启动并在后台运行,释放终端控制权供用户执行其他操作。值得注意的是,某些服务程序(如NGINX)在启动时通常会自带“&”参数,自动进入后台运行,以避免占用前台界面。这种设计允许服务在后台持续提供服务,而无需用户手动干预。 要查看当前用户通过“&”放入后台的进程列表,可以使用 `jobs` 命令。该命令会列出所有后台作业的编号(Job ID)及其状态(如运行、暂停、完成)。每个作业都有一个唯一的编号,便于后续操作。例如,当系统中有多个后台任务时,通过 `jobs` 可以清晰识别各进程的ID,从而进行精准管理。 将后台进程调回前台运行的命令是 `fg`,其语法为 `fg %编号`。例如,若 `jobs` 显示作业编号为2的进程处于后台,执行 `fg %2` 即可将其恢复至前台。这一操作常用于需要与进程交互(如输入命令参数)或监控其输出的情况。 此外,对于前台运行的进程,用户可以通过按下 `Ctrl+Z` 组合键将其暂停并转入后台。此时,进程的状态变为“停止”(Stopped),但仍存在于系统中。通过 `jobs` 查看后,可使用 `bg %编号` 命令让暂停的进程继续在后台运行。例如,当需要临时中断一个耗时任务但又不想终止它时,这一组合操作尤为实用。 针对后台进程的管理,`kill` 命令是关键工具。通过 `kill %编号` 可以终止指定的后台进程。但需注意,`kill` 默认发送的是 `SIGTERM` 信号(优雅终止),若进程无响应,可改用 `kill -9 %编号` 强制终止(发送 `SIGKILL` 信号)。不过,频繁使用强制终止可能导致资源未释放或数据损坏,应谨慎操作。 **进阶技巧与注意事项**: 1. **进程状态跟踪**:结合 `ps` 或 `top` 命令可查看更详细的进程信息,例如PID(进程ID)、资源占用等,辅助判断进程状态。 2. **持久化后台进程**:使用 `nohup my_program &` 可让进程忽略终端挂断信号,即使在用户注销后仍持续运行。 3. **会话管理工具**:`screen` 或 `tmux` 提供更强大的前后台控制,允许创建多个会话并在其间切换,适合复杂场景。 4. **资源管理**:后台进程可能持续占用CPU或内存,需定期监控(如 `top`)并调整优先级(如 `nice` 命令)以避免系统负载过高。 **实际应用场景举例**: - **服务器部署**:启动服务(如数据库、Web服务器)时通常置于后台,确保终端可继续执行其他配置任务。 - **数据备份**:运行耗时的备份脚本(如 `tar -czf backup.tar.gz /data &`),利用后台执行避免终端阻塞。 - **调试与恢复**:暂停前台程序(Ctrl+Z)后,可检查日志或修改配置,再通过 `bg` 恢复执行,减少重启成本。 总之,前后台进程管理是系统交互的基础技能,掌握其机制与工具组合,能显著提升多任务处理的灵活性和效率。但需注意,合理分配进程资源并规范终止操作,才能保障系统稳定运行。
4、HUP信号
HUP信号有两种作用:
1、当终端关闭之后,跟这个终端有关系的所有进程都会收到一个HUP信号,收到之后这些进程默认的都会关闭。
2、捕获信号,平滑重启,在不关掉进程的情况下让他能够加载我们的进程的配置文件。
怎么实现呢?首先这个进程本身代码里面得支持这件事(捕获信号),然后我们就朝着这个进程发HUP信号。
**HUP信号:机制、作用与实现方式** HUP信号(Signal HUP,即“Hangup”信号)在UNIX和类UNIX系统中扮演着重要角色,其独特的设计使其兼具“终端关联管理”与“进程动态配置”两大功能。以下将深入解析其原理与实现细节。 **一、作用解析** 1. **终端关闭后的进程管理** 当用户关闭终端(如SSH会话、控制台窗口等)时,系统会向该终端所属的所有进程发送HUP信号。这一机制的核心在于维护会话与进程的生命周期关联:默认情况下,进程接收到HUP信号后,会触发终止操作(类似于收到SIGTERM信号)。这种设计避免了终端关闭后遗留“孤儿进程”,确保系统资源被及时释放。例如,当用户退出命令行界面时,后台运行的脚本或工具会自动停止,避免资源占用。 2. **平滑重启与配置重载** 然而,HUP信号的另一项关键能力在于“非中断式重启”。许多服务进程(如Web服务器、数据库代理等)支持通过捕获HUP信号,实现配置文件的动态加载。具体流程为:进程接收到HUP后,先保存当前状态(如连接数、日志位置),然后重新解析配置,最后恢复运行。这一过程无需彻底停止服务,避免了业务中断。例如,修改Nginx配置后,管理员只需发送HUP信号,即可使其加载新配置而无需重启服务。 **二、实现机制与技术细节** 1. **进程内部支持** 要实现HUP信号的处理,进程必须显式注册信号捕获机制。在C语言中,通常使用`signal()`函数或更现代的`sigaction()`来定义HUP的处理逻辑。例如,代码中需包含类似结构: ``` void handle_hup(int signo) { // 处理逻辑:重新加载配置、打印日志等 } // 注册HUP信号处理函数 signal(SIGHUP, handle_hup); ``` 2. **信号发送方式** 向进程发送HUP信号的方法多样: - 命令行工具:使用`kill -HUP <PID>`或`pkill -HUP <进程名>`直接发送。 - 脚本控制:在Shell脚本中嵌入信号发送命令,实现自动化重启。 - 编程接口:如Python的`os.kill(pid, signal.SIGHUP)`。 3. **高级应用场景** - **守护进程设计**:许多后台服务(如Supervisor、Systemd)利用HUP信号实现“受控重启”,通过配置文件指定信号行为。 - **容器化环境**:Docker等平台支持通过HUP触发容器内服务的配置刷新,适应动态环境变更。 **三、注意事项与最佳实践** - **信号处理安全性**:捕获HUP时需确保进程状态一致性,避免因并发操作导致数据损坏。 - **默认行为覆盖**:若进程未捕获HUP,系统将执行默认终止操作。因此,关键服务必须显式处理该信号。 - **日志记录**:在HUP处理函数中记录状态变更,便于排查配置加载错误。 **四、与其他信号对比** HUP与SIGTERM、SIGINT等信号存在明确分工: - SIGTERM:请求进程终止(可被忽略或延迟处理)。 - SIGINT(Ctrl+C):用户中断请求,通常用于前台进程。 - HUP:专注于终端关联与配置重载,功能更垂直。 --- **总结** HUP信号通过灵活的捕获机制,兼顾了终端管理的高效性与服务动态调整的实用性。理解其底层逻辑,有助于开发人员构建更健壮的进程,系统管理员实现更平滑的服务运维。无论是避免资源泄露,还是零宕机配置更新,HUP信号都是UNIX系统中不可或缺的工具。
5、控制进程脱离当前终端运行
有4种方式:
第一种在命令前加nohup,就是让我这个进程起来之后忽略hup信号。
第二种在命令前加setsid
第三种把命令用括号括起来,而且在命令末尾加&。
控制进程脱离当前终端运行的四种方法 在Linux或类Unix系统中,当需要让进程在后台持续运行,即使终端关闭或用户注销后仍不中断,可以采用以下四种方法。这些技术不仅适用于日常操作,也在服务器管理、自动化脚本编写中至关重要。以下将详细阐述每种方法的原理、使用场景及注意事项。 第一种方法:使用nohup命令 nohup(no hangup的缩写)是脱离终端运行的基础工具。其核心原理是让进程忽略SIGHUP信号(即终端挂断信号)。当终端关闭时,系统通常会向相关进程发送SIGHUP,导致进程终止,但nohup会阻止这一行为。使用方式很简单:nohup 命令参数 & 例如:nohup python script.py &。此时进程会在后台运行,并将输出默认写入nohup.out文件(可自定义路径)。需要注意的是,nohup虽能防止进程因终端关闭而终止,但进程仍可能受系统资源限制或人为干预的影响。此外,日志管理需手动处理,适用于简单后台任务。第二种方法:使用setsid命令 setsid通过创建新的会话(session)使进程完全脱离当前终端控制。新会话的进程成为会话组长,不再属于原终端的进程组,因此终端关闭不会影响它。语法为:setsid 命令参数 例如:setsid python script.py。与nohup不同,setsid不提供日志重定向功能,需额外配合输出重定向(如> log.txt)。此方法适用于需要彻底独立运行且无需交互的进程,但需注意进程PID管理,因为脱离终端后只能通过系统命令(如ps、kill)控制。 第三种方法:括号+&组合 这种方法利用shell的作业控制机制。将命令用括号包围,并在末尾加&,例如:(命令参数) & 如:(python script.py &) 。括号创建子shell,子shell中的命令作为后台作业运行。终端关闭时,子shell终止,但子shell中的进程因成为孤儿进程而被init(PID 1)接管,继续运行。不过,这种方式依赖shell的作业管理,若shell本身被强制终止,进程可能受影响。此外,日志默认输出到终端,需手动重定向。第四种方法:使用disown命令(补充扩展) 除了上述三种,还可以利用disown命令将已启动的前台进程转为后台独立运行。例如,先启动进程:python script.py,然后按Ctrl+Z暂停,再执行:bg %1 # 将暂停的进程放入后台 disown %1 # 从作业列表中移除,使其脱离终端 此时进程即使终端关闭也不会终止。disown的优势在于可动态转换现有进程,但需依赖交互式操作,且无法自动处理日志。其他补充工具:screen/tmux 虽然不属于直接的方法,但screen和tmux提供了更强大的终端复用功能。它们通过创建虚拟终端会话,允许进程在独立环境中运行,即使物理终端断开,会话仍保留。例如:screen -S session_name # 创建会话 命令参数 # 在会话中执行 Ctrl+A+D # 分离会话 这种方式适合需要长期管理多个后台任务或远程服务器运维的场景。总结与注意事项适用场景选择:简单任务用nohup;彻底独立用setsid;动态转换用disown;复杂管理用screen/tmux。日志管理:务必处理输出,避免占用系统资源或丢失关键信息。进程监控:使用ps -ef、top、pgrep等命令跟踪后台进程状态。安全性:脱离终端的进程可能更难管理,需确保权限和资源限制。通过以上方法,可以灵活实现进程的后台运行与终端解耦,提升系统运维的可靠性与效率。
6、HUP信号实现NGINX平滑重启
平滑重启的过程我们一NGINX为例:
首先给NGINX的master进程发一个HUP信号(前提是NGINX源代码里面已经针对HUP信号做过处理了),然后正在干活的进程接着干,针对干完活的进程就关掉重启。
systemctl restart nginx 本质也是先stop再start,这样关掉重启是相当于粗暴的把进程干掉,然后重新加载配置文件,而平滑重启是一点一点更新。
因为nginx要一直一个服务,平滑重启可以让用户感觉不到。
nginx的日志文件/var/log/nginx/access.log
nginx的配置文件/etc/nginx/nginx.conf
**HUP信号实现NGINX平滑重启** 在探讨平滑重启的过程时,我们以NGINX为例进行详细说明。平滑重启的核心在于通过发送特定的信号,实现服务配置更新的同时保持业务连续性,避免因服务中断而影响用户体验。下面将详细阐述HUP信号在NGINX平滑重启中的实现机制及其优势。 首先,需要明确HUP信号的作用。当向NGINX的master进程发送HUP信号时(前提是NGINX源代码中已对该信号进行正确处理),master进程会接收到这一指令,并启动一系列协调操作。此时,正在处理请求的worker进程会继续完成当前任务,而已经完成任务的worker进程则会逐步退出,并由master进程重新启动新的worker进程。新进程会加载最新的配置文件,从而完成配置的平滑更新。这种机制确保了在配置更新过程中,用户请求仍能被正在运行的进程处理,避免了因直接终止进程导致的服务中断。 相比之下,使用`systemctl restart nginx`命令进行重启时,系统会先停止所有NGINX进程,再重新启动。这种方式虽然简单,但属于“硬重启”,可能导致短时间内服务不可用,尤其是在高并发场景下,用户可能会感受到短暂的访问延迟或失败。而平滑重启通过“渐进式”的进程替换,实现了配置更新与服务可用性的平衡,特别适合需要持续提供服务的生产环境。 在实际应用中,平滑重启的场景十分广泛。例如,当需要修改NGINX的配置文件(如`/etc/nginx/nginx.conf`)以调整服务器参数、增加新的虚拟主机或优化性能配置时,通过平滑重启可以避免因手动终止服务而导致的业务中断。此外,日志文件(如`/var/log/nginx/access.log`)的轮转操作也常结合平滑重启进行,确保日志切割时不会丢失正在写入的请求记录。 平滑重启的具体过程可进一步分解为以下几个步骤: 1. **信号接收**:master进程捕获HUP信号。 2. **配置解析**:master进程读取并验证新的配置文件,若存在语法错误会拒绝加载,从而保障重启的安全性。 3. **进程协调**:通知当前空闲的worker进程优雅退出,同时创建新的worker进程加载新配置。 4. **请求过渡**:新进程接管新请求,旧进程继续处理未完成的任务直至结束。 5. **资源回收**:旧进程完全退出后,系统释放其占用的资源(如内存、文件句柄等)。 值得注意的是,平滑重启依赖于NGINX的进程管理机制。master进程作为控制核心,负责监控worker进程的状态并协调重启流程。此外,配置文件中的一些参数(如`worker_processes`、`daemon`等)可能会影响平滑重启的行为,管理员需根据实际需求进行调整。 对于运维人员而言,平滑重启不仅提升了系统的稳定性,还简化了维护流程。例如,当服务器需要升级NGINX版本或修复安全漏洞时,通过平滑重启可以在不中断服务的情况下完成更新,极大地降低了运维风险。同时,结合监控工具(如Prometheus或Nginx内置的Status模块),可以实时跟踪重启过程中进程数量、请求处理速度等指标,确保操作的成功与安全。 总结来说,HUP信号驱动的NGINX平滑重启通过精细的进程管理和配置加载机制,实现了服务更新与可用性的完美兼容。这种机制在保障用户体验的同时,为系统维护提供了更大的灵活性,是现代高可用架构中不可或缺的技术手段。通过理解其工作原理,运维人员可以更好地应对各种配置变更场景,构建更健壮的服务环境。
**HUP信号的作用与实现机制:进程管理中的平滑重启与终端控制** HUP(Hangup)信号在Linux进程管理中扮演着关键角色,其作用主要体现在两个方面:终端管理中的进程终止,以及服务程序的平滑重启。本文将详细解析HUP信号的原理、实现方式,并结合NGINX实例探讨平滑重启的技术细节。 **一、HUP信号的双面作用** 1. **终端关闭时的进程终止** 当用户关闭终端(如SSH会话或命令行窗口)时,系统会向与该终端关联的所有进程发送HUP信号。默认情况下,收到HUP信号的进程会终止运行,这是为了防止进程在终端消失后成为“孤儿进程”继续运行。例如,当用户退出SSH连接时,所有未通过后台机制运行的命令(如未加`nohup`或`&`)都会收到HUP并退出。 2. **平滑重启:捕获信号加载新配置** HUP信号的另一重要作用是允许程序捕获该信号,并执行自定义逻辑。许多服务程序(如NGINX、Apache等)会捕获HUP信号,触发“平滑重启”:在不中断服务的情况下,重新加载配置文件,更新运行参数。这种机制避免了服务中断,确保用户体验连续。 **二、进程脱离终端控制的四种方法** 为了让进程在终端关闭后继续运行(忽略HUP信号),可采用以下四种方式: **第一种:nohup命令** `nohup`(no hangup)命令用于启动进程时忽略HUP信号。例如: ``` nohup./myprogram & ``` 进程启动后,即使终端关闭,进程仍会继续运行,并将日志输出到`nohup.out`文件。这是后台运行服务程序的常用方式。 **第二种:setsid命令** `setsid`创建一个新的会话,使进程脱离当前终端的控制。例如: ``` setsid./myprogram ``` 该进程将成为新会话的首进程,不再属于原终端的进程组,因此不会收到HUP信号。常用于编写守护进程或服务脚本。 **第三种:括号加&(作业控制)** 通过括号将命令分组,并在末尾加`&`,例如: ``` (./myprogram ) & ``` 这种方式将命令作为后台作业运行,并创建新的进程组。由于进程组脱离了终端,因此HUP信号不会影响它。但需要注意,这种方式仅适用于简单命令,复杂脚本可能需要额外处理。 **第四种:使用进程管理工具(如systemd)** 现代系统常用systemd管理服务,通过配置`systemd`单元文件,可以指定进程忽略HUP信号,或使用其他重启策略。例如: ``` # 在systemd服务配置中指定忽略HUP [Service] KillSignal=SIGINT ``` 此配置使服务在收到HUP时忽略,转而使用`SIGINT`终止。 **三、HUP信号实现NGINX平滑重启** NGINX的平滑重启机制是其高可用性的核心之一。当需要更新配置(如修改端口、添加虚拟主机)时,平滑重启可确保服务不间断: 1. **原理流程** - 向NGINX的master进程发送HUP信号。 - master进程解析新配置,启动新的worker进程(加载最新配置)。 - 原有worker进程继续处理未完成请求,直至当前连接全部处理完毕。 - 旧worker进程在完成所有任务后优雅退出,新进程接管服务。 2. **对比传统重启(systemctl)** - `systemctl restart nginx`:直接停止所有进程,再重新启动,可能导致短暂服务中断。 - 平滑重启:通过分阶段替换进程,确保请求零丢失。 3. **实际应用示例** 修改NGINX配置后,执行: ``` kill -HUP $(cat /run/nginx.pid) ``` 或直接使用: ``` nginx -s reload ``` (内部实现也是发送HUP信号) 此时,NGINX日志(如`/var/log/nginx/access.log`)会记录重启过程,而用户访问几乎无感知。 **四、平滑重启的技术优势与场景** - **服务高可用**:避免因配置更新导致服务中断,适用于Web服务器、数据库等关键服务。 - **资源优化**:减少因进程重启带来的资源消耗(如内存、CPU瞬时高峰)。 - **灰度更新**:通过逐步替换进程,实现配置的“灰度发布”,降低风险。 **五、NGINX配置与日志管理** 平滑重启依赖于配置文件和日志的正确管理: - **配置文件**:主配置文件`/etc/nginx/nginx.conf`定义全局参数,各模块配置可位于子目录(如`/etc/nginx/conf.d`)。 - **日志文件**:访问日志(`access.log`)记录请求详情,错误日志(`error.log`)帮助排查问题。 - **PID文件**:`/run/nginx.pid`保存master进程ID,是发送HUP信号的目标。 **总结** HUP信号作为进程管理与服务运维的关键工具,通过终端控制与平滑重启的双重机制,实现了进程生命周期的灵活管理。无论是开发守护进程,还是运维高可用服务,HUP信号的捕获与处理都是不可或缺的技术环节。通过理解其原理并结合具体工具(如NGINX的平滑重启),可以大幅提升系统的稳定性与用户体验。
7、查看网络状态
netstat先看它是哪个包产生的:
[root@localhost ~]# which netstat /usr/bin/netstat [root@localhost ~]# rpm -qf /usr/bin/netstat net-tools-2.0-0.25.20131004git.el7.x86_64
如果没有的话需要安装一下:
[root@localhost ~]# yum install net-tools -y
使用 netstat 命令查看网络状态时,有几个关键选项值得深入理解。每个选项可以单独或组合使用,帮助用户获取更精准的网络连接和端口信息。以下是各选项的详细说明:
-a(显示所有连接和监听端口)
该选项会列出系统当前所有的网络连接,无论处于何种状态(如已建立连接、监听中、等待关闭等)。它不仅显示已建立的TCP和UDP连接,还会列出所有正在监听的端口(即服务等待客户端连接的端口)。例如,在排查网络服务是否启动时,通过 `-a` 可快速确认服务器上哪些端口处于开放状态。
-t(仅显示 TCP 连接)
专注于TCP协议相关的连接信息。当需要分析TCP会话(如HTTP、SSH、FTP等基于TCP的应用)时,此选项非常有用。例如,检查某个服务器是否接收到大量TCP连接请求,或者识别是否存在异常的TCP连接状态(如大量SYN_RECV可能暗示端口扫描攻击)。
-u(仅显示 UDP 连接)
与 `-t` 类似,但仅显示UDP协议的数据。UDP常用于流媒体、实时通信(如VoIP)或广播服务,使用 `-u` 可快速定位基于UDP的通信问题。例如,检查DNS服务器(通常使用UDP端口53)是否正常工作,或排查视频会议软件的网络连接情况。
-l(显示监听状态的端口)
仅展示当前系统中处于“监听”(LISTEN)状态的端口。这些端口对应着服务器上已启动的服务(如Web服务器监听80端口,SSH服务监听22端口)。通过 `-l` 可以确认哪些服务正在等待客户端连接,是排查服务启动失败或端口冲突的重要工具。
-p(显示进程信息)
结合端口和连接信息,显示对应的进程ID(PID)和进程名称。当发现某个端口异常时,通过 `-p` 可以快速定位到具体的进程,判断是否为合法服务或恶意程序。例如,发现某个未知进程占用了敏感端口,可进一步调查其安全性。
-n(以数字形式显示地址和端口)
禁用主机名和端口名称的解析,直接以IP地址和端口号显示结果。这有两个优势:1. 加速输出,避免因DNS解析延迟导致的命令执行缓慢;2. 当系统无法解析主机名时(如网络故障或本地 hosts 文件错误),仍能获取准确信息。例如,在分析日志或快速排查问题时,数字格式更直观。
实际使用中的组合技巧:
netstat -anptu:综合显示所有TCP/UDP连接、监听端口、进程信息,并以数字格式输出,常用于全面诊断网络状态。
-netstat -ln | grep 80:查找所有监听80端口的服务(如Web服务器),结合管道过滤特定端口信息。
netstat -p | grep 12345:通过进程号反向查找该进程使用的网络连接,帮助分析程序行为。
注意事项:
在某些现代系统中(如Linux),netstat 已逐渐被更强大的 `ss` 命令替代,但 netstat 的选项逻辑仍被广泛使用。理解这些选项有助于快速掌握网络诊断的基本方法。
[root@localhost ~]# netstat -tunalp Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 867/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1022/master tcp 0 52 192.168.1.67:22 192.168.1.38:5712 ESTABLISHED 8304/sshd: root@pts tcp6 0 0 :::22 :::* LISTEN 867/sshd tcp6 0 0 ::1:25 :::* LISTEN 1022/master udp 0 0 0.0.0.0:68 0.0.0.0:* 1153/dhclient udp 0 0 127.0.0.1:323 0.0.0.0:* 537/chronyd udp6 0 0 ::1:323 :::* 537/chronyd
Proto(协议类型)
该列标识连接的传输层协议,常见值包括TCP、UDP、UNIX(本地进程间通信)。TCP代表面向连接的可靠传输,而UDP则为无连接模式,适用于实时性要求高的场景。协议类型直接影响后续各列数据的解读方式。
Recv-Q(接收队列)与 Send-Q(发送队列)
这两个字段分别显示接收和发送缓冲区的当前队列长度。数值非零时可能暗示问题:例如,Recv-Q持续增长可能表明应用程序未及时读取数据,导致积压;Send-Q高值可能反映对端处理缓慢或网络拥堵。在服务器高负载时,队列监控是性能调优的重要依据。
Local Address(本地地址)与 Foreign Address(远程地址)
这两列共同定义连接的唯一性。本地地址包含IP和端口号(如`192.168.1.100:8080`),而远程地址对应对端的IP和端口。通过IP可判断连接是来自本地网络还是外部,端口号则帮助识别具体服务(如80为HTTP,443为HTTPS)。例如,大量来自同一远程IP的连接可能提示攻击或异常流量。
State(连接状态)
这是核心字段,反映TCP连接的生命周期阶段。常见状态包括:
LISTEN:服务等待客户端连接
ESTABLISHED:活跃数据传输中,表示正常连接。
TIME_WAIT:主动关闭方在结束后的等待状态,防止旧数据干扰新连接。大量TIME_WAIT可能需调整系统参数。
SYN_SENT/SYN_RECV:TCP三次握手过程中的中间态,若长时间停留可能表明握手失败。
CLOSE_WAIT:被动关闭方未释放资源,常提示应用程序存在资源泄漏问题。
PID/Program name
显示占用该连接的进程ID及名称(如`httpd`、`sshd`)。通过PID可追踪具体服务或进程,快速定位异常连接的来源。例如,发现恶意程序占用的端口时,可直接终止进程或排查漏洞。
查看端口:
[root@localhost ~]# lsof -i:22 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 867 root 3u IPv4 20117 0t0 TCP *:ssh (LISTEN) sshd 867 root 4u IPv6 20126 0t0 TCP *:ssh (LISTEN) sshd 8304 root 3u IPv4 96935 0t0 TCP localhost.localdomain:ssh->192.168.1.38:5712 (ESTABLISHED)
8、高并发情况下服务器状态分析
**使用netstat命令查看网络状态:选项解析与高并发服务器分析** 在网络管理和系统运维中,`netstat`是一个强大的工具,用于实时查看系统的网络连接状态、端口监听情况、协议统计等信息。通过不同的选项组合,可以深入分析服务器在高并发场景下的性能瓶颈和潜在问题。下面详细解释各个选项的含义,并结合高并发环境下的服务器状态分析进行说明。 **netstat命令常用选项解析:** 1. **-a(all)**:显示所有连接和监听端口。无论是TCP、UDP还是其他协议,所有当前活跃或监听状态的连接都会被列出。在高并发场景中,此选项有助于全面了解服务器开放的端口和连接总数,识别是否存在异常连接或端口占用情况。 2. **-t(TCP)**:仅显示TCP相关的连接信息。当服务器主要处理TCP协议时(如Web服务、数据库连接等),该选项能过滤掉UDP等其他协议的数据,聚焦关键信息。 3. **-u(UDP)**:仅显示UDP相关的连接。适用于分析基于UDP的应用,如DNS查询、流媒体传输等。 4. **-l(listening)**:显示处于监听状态(LISTEN)的端口。这些端口表示服务器正在等待客户端连接,是判断服务是否启动、端口配置是否正确的重要依据。在高并发下,确保关键服务端口(如80、443、3306等)处于监听状态至关重要。 5. **-p(program)**:显示与连接相关的进程信息(PID和进程名称)。通过此选项,可以快速定位占用端口的进程,识别哪些服务正在处理网络请求,帮助排查进程资源占用过高或异常连接的问题。 6. **-n(numeric)**:以数字形式显示地址和端口,而不是解析为主机名或服务名。在高并发环境中,禁用反向解析(DNS查询)能显著提升命令执行速度,避免因解析延迟导致信息滞后。 **netstat命令输出示例与关键字段分析:** ``` Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 192.168.1.100:80 192.168.1.200:50000 ESTABLISHED 1234/nginx tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 4567/mysqld udp 0 0 0.0.0.0:53 0.0.0.0:* LISTEN 789/dnsmasq ``` - **Proto**:协议类型(TCP/UDP)。 - **Recv-Q/Send-Q**:接收和发送队列长度。高数值可能表明数据传输延迟或缓冲区溢出。 - **Local Address**:本地IP+端口,标识服务监听地址或已建立连接的本地端。 - **Foreign Address**:远程IP+端口,显示连接的对端信息。 - **State**:连接状态(ESTABLISHED、LISTEN、TIME_WAIT、CLOSE_WAIT等),反映TCP连接生命周期的关键阶段。 - **PID/Program name**:进程ID和名称,帮助关联网络活动与具体服务。 **高并发情况下服务器状态分析:** 在高并发场景中,服务器需要处理大量并发请求,网络连接的动态变化会直接影响系统性能。通过netstat结合上述选项,可以分析以下关键指标: 1. **监听端口状态**:使用`netstat -lntup`查看所有监听端口。若关键服务端口未处于LISTEN状态,可能意味着服务未启动或配置错误。 2. **连接状态分布**:重点关注TCP状态(如ESTABLISHED、SYN_RECV、TIME_WAIT)。例如: - **ESTABLISHED**数量过高:可能超出服务器处理能力,需优化进程并发处理能力或引入负载均衡。 - **TIME_WAIT过多**:通常由TCP连接快速释放导致,可通过调整内核参数(如`net.ipv4.tcp_tw_reuse`和`net.ipv4.tcp_tw_recycle`)缩短TIME_WAIT持续时间。 - **SYN_RECV堆积**:可能遭遇SYN flood攻击或服务器TCP三次握手处理能力不足。 3. **队列长度(Recv-Q/Send-Q)**:若队列持续非零,说明存在数据积压,可能因进程处理速度慢或网络带宽瓶颈。 4. **进程关联分析**:通过`-p`选项定位高连接数的进程,结合`top`或`htop`查看其CPU、内存占用,判断是否存在资源耗尽风险。 **优化与故障排查实践:** - **性能优化**:在高并发环境下,定期使用`netstat -ant | grep ESTABLISHED | wc -l`统计活跃连接数,配合系统负载监控工具(如`sar`)评估服务器容量。 - **故障排查**:若发现大量`CLOSE_WAIT`状态,可能暗示应用程序未正确关闭连接,需检查代码逻辑或进程是否存在异常。 - **安全分析**:通过`netstat -an`识别外部IP的异常连接模式,辅助入侵检测或DDoS攻击防护。 **总结:** netstat是服务器运维的核心工具之一,尤其在处理高并发场景时,它提供了网络状态的实时快照。通过灵活组合选项,运维人员不仅能诊断当前问题,还能通过趋势分析预见潜在风险。然而,在超高负载环境下,建议使用更高效的替代工具(如`ss`命令)以减少系统资源消耗。此外,结合内核参数调优、进程管理策略和分布式架构设计,才能构建真正稳定、高性能的高并发服务系统。
9、proc文件系统
这不是磁盘文件系统,这是一个虚拟的文件系统,用来放跟运行相关的状态有CPU、内存、还有进程的一些相关信息。df查看的是硬盘的文件系统,这个得看mount。
[root@localhost ~]# df 文件系统 1K-块 已用 可用 已用% 挂载点 devtmpfs 487116 0 487116 0% /dev tmpfs 497836 0 497836 0% /dev/shm tmpfs 497836 7804 490032 2% /run tmpfs 497836 0 497836 0% /sys/fs/cgroup /dev/sda3 18351104 1833756 16517348 10% / /dev/sda1 508580 127060 381520 25% /boot tmpfs 99568 0 99568 0% /run/user/0 [root@localhost ~]# mount sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=487116k,nr_inodes=121779,mode=755) securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel) devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000) tmpfs on /run type tmpfs (rw,nosuid,nodev,seclabel,mode=755) tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb) configfs on /sys/kernel/config type configfs (rw,relatime) /dev/sda3 on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota) selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime) systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=31,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=13600) hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,seclabel) debugfs on /sys/kernel/debug type debugfs (rw,relatime) mqueue on /dev/mqueue type mqueue (rw,relatime,seclabel) fusectl on /sys/fs/fuse/connections type fusectl (rw,relatime) /dev/sda1 on /boot type xfs (rw,relatime,seclabel,attr2,inode64,noquota) tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=99568k,mode=700) binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)
proc文件系统并非传统的磁盘文件系统,而是一个虚拟的文件系统,用于存储与系统运行状态相关的实时信息。它通过内核将系统核心数据以文件的形式暴露给用户空间,使得用户能够方便地获取和监控系统资源的使用情况、进程状态以及硬件配置等关键信息。与传统文件系统不同,proc文件系统中的文件并不存储在磁盘中,而是由内核动态生成,实时反映当前系统的运行状态。 当使用df命令时,我们通常查看的是硬盘上的文件系统,包括各个分区的挂载点、总容量、已用空间、剩余空间等统计信息。df(disk free)专注于磁盘相关的文件系统,如ext4、XFS等,帮助用户了解存储设备的利用率。而要了解proc文件系统的信息,则需要通过mount命令进行查看。这是因为proc作为一个虚拟文件系统,需要被挂载到系统的特定目录(通常是/proc)才能被访问。通过执行mount命令,可以列出系统中所有已挂载的文件系统,其中会显示proc的位置(如/proc on /proc type proc (rw,relatime)),明确其作为虚拟文件系统的类型与挂载参数。 进一步来看,proc文件系统的设计使得系统管理员和开发人员能够直接读取或写入相关文件来交互式地管理系统。例如,/proc/cpuinfo提供了CPU的型号、核心数、频率等硬件信息;/proc/meminfo则展示了内存的总量、已用内存、缓存、交换分区等详细统计数据;而/proc目录下以数字命名的子目录(如/proc/1234)则对应各个进程的详细信息,包括进程ID、状态、打开的文件描述符等。这种机制使得调试系统性能、排查进程问题变得直观高效,无需依赖复杂的工具即可获取核心数据。 需要注意的是,由于proc文件系统的虚拟性,其内容会随着系统运行动态变化。例如,当有新进程启动或终止时,对应的进程目录会动态创建或删除;当内存使用量变化时,/proc/meminfo中的数据也会实时更新。因此,它为用户提供了一个动态观察系统状态的窗口,与传统磁盘文件系统的静态数据存储形成了鲜明对比。 总结来说,df与mount在文件系统管理中的分工明确:df聚焦于物理或逻辑磁盘的存储信息,而mount则揭示了包括proc在内的所有文件系统挂载情况。理解proc文件系统的特性,不仅有助于深入掌握Linux系统的底层架构,还能在实际运维中提供强大的诊断与监控能力。
[root@localhost ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 座: 1 NUMA 节点: 1 厂商 ID: GenuineIntel CPU 系列: 6 型号: 151 型号名称: 12th Gen Intel(R) Core(TM) i5-12400F 步进: 2 CPU MHz: 2496.000 BogoMIPS: 4992.00 超管理器厂商: VMware 虚拟化类型: 完全 L1d 缓存: 48K L1i 缓存: 32K L2 缓存: 1280K L3 缓存: 18432K NUMA 节点0 CPU: 0 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 arat umip pku ospke gfni vaes vpclmulqdq movdiri movdir64b md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities
[root@localhost ~]# uptime 21:52:39 up 21:49, 2 users, load average: 0.00, 0.01, 0.05
10、进程间通信
进程他们彼此的内存空间物理层面就是隔离的。
可以通过共享内存进行通信,管道就是一种
tee命令搭配管道符号用,可以把左边这些命令的结果既输出到终端当中去还给你定向到一个文件里面去,如果追加就是tee -a
xargs命令,特点是让原本不支持管道的命令支持管道。
**进程间通信:打破内存隔离的桥梁与实用工具** 进程间通信(Inter-Process Communication, IPC)是操作系统中不同进程之间进行数据交换和信息交互的核心机制。在现代多任务系统中,每个进程都拥有独立的内存空间,这种物理层面的隔离确保了进程间的安全性与稳定性。例如,一个崩溃的进程不会直接影响其他进程的数据,但这也为进程协作带来了挑战。为了实现跨进程的数据传输,系统提供了多种通信手段,其中共享内存和管道是最为典型的方法。 **共享内存:高效的数据共享方式** 共享内存允许两个或多个进程映射同一块物理内存区域,从而直接读写数据。这种方式避免了传统通信方式中的数据复制开销,因此具有极高的效率。例如,在实时数据处理或高性能计算场景中,多个进程可以通过共享内存实现高速的数据同步。但共享内存也引入了新的问题:由于多个进程可同时访问同一内存块,必须通过同步机制(如互斥锁、信号量)来避免竞态条件和数据不一致。Linux系统提供了`shmget`、`shmat`等系统调用,支持创建和管理共享内存区域。 **管道:连接命令的流水线** 管道(Pipe)是一种基于文件描述符的通信机制,它将一个进程的标准输出与另一个进程的标准输入连接起来,形成“数据流水线”。在Linux Shell中,管道符号`|`的应用极为广泛,例如命令链`cat file.txt | grep "keyword" | wc -l`可以将文件内容过滤后统计匹配行数。管道的特点是单向、先进先出(FIFO),适合处理流式数据。值得注意的是,无名管道通常用于父子进程间通信,而有名管道(FIFO)则允许不相关的进程通过文件系统进行通信。 **tee命令:分流输出的多面手** `tee`命令是管道中的“分水岭”,它能够将数据流同时输出到多个目标。例如,命令`ls -l | tee output.log`会将`ls`的结果既显示在终端,又保存到`output.log`文件中。若需追加而非覆盖原有文件内容,可使用`tee -a file.txt`选项。此外,`tee`命令默认会缓冲数据,但在需要实时响应的场景(如日志监控),可以通过`-i`参数禁用缓冲,确保数据即时写入。这一特性使其在调试和日志记录中尤为实用。 **xargs:让非管道命令拥抱流式处理** 许多命令(如`rm`、`mkdir`)本身不支持管道输入,但通过`xargs`可以将其转换为流式处理的工具。例如,删除大量文件时,直接使用`ls | rm`会报错,而`ls | xargs rm`则能将文件列表作为参数传递给`rm`。`xargs`的核心是将标准输入分割成多个命令行参数,并批量执行。通过`-n`选项可控制每次传递的参数数量,避免因参数过长导致命令失败。例如`find. -type f | xargs -n 10 rm`每次仅删除10个文件,有效管理资源。 **其他进程通信机制:多样化的选择** 除了共享内存和管道,现代系统还支持更丰富的IPC手段: - **消息队列**:进程通过发送和接收消息(Message)进行通信,适合异步、松耦合的场景。 - **信号量(Semaphore)**:用于进程同步,控制对临界资源的访问,例如多线程中的锁机制。 - **套接字(Socket)**:不仅支持网络通信,还可通过本地套接字实现同一主机上的进程间通信,常见于分布式系统架构。 - **信号(Signal)**:用于进程间的简单事件通知,如`SIGINT`(终止信号)或自定义信号处理。 **实际应用与总结** 进程间通信的多样性使得开发者可以根据场景选择最优方案。例如,共享内存适用于需要高速共享大量数据的场景,而消息队列更适合构建解耦的分布式系统。命令行工具如`tee`和`xargs`则降低了管道使用的门槛,使得复杂的任务处理变得灵活高效。理解这些机制不仅有助于编写更健壮的软件,还能提升系统运维和脚本编写的效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号