day20-自定义分页
一、前言
我们知道后端数据库里面的数据需要往前端放,之前我们都是很少一部分数据,那如果我们的数据多了怎么办,比如说有1000条,或者10000条以上的数据,那怎么办呐?那我们是不是需要对这些数据做一下分页,然后又多少数据,我们根据这些数据,我们分成多少页,这个是我们经常看到的,所以我们今天就来学习一下自定义分页的功能。
二、自定义分页
2.1、urls.py的代码
说明:先创建url,通过project.urls.py创建url
from django.urls import path
from app01 import views
urlpatterns = [
path('user_list/',views.user_list)
]
三、在前端实现方式
3.1、views.user_list代码实现
说明:思路就是获取当前页,然后获取切片的开始值和结束值
li = list()
for i in range(100):
li.append(i)
def user_list(request):
# data = li[0:10]
# data = li[10:20]
current_page = request.GET.get("p",1) #获取当前页,没有就默认是第1页
current_page = int(current_page)
start = (current_page-1) * 10 #开始位置
end = current_page * 10 #结束位置
data = li[start:end] #获取当前页的数据列表
return render(request,'user_list.html',{'li':data})
3.2、templates的user_list.html的代码:
<body>
<ul>
{% for item in li %}
<li>{{ item }}</li>
{% endfor %}
</ul>
<div>
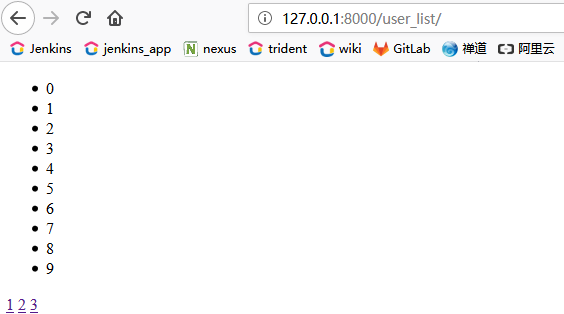
<a href="/user_list/?p=1">1</a>
<a href="/user_list/?p=2">2</a>
<a href="/user_list/?p=3">3</a>
</div>
</body>
效果图:
四、后端实现方式
4.1、views.user_list代码实现
说明:利用取模的方式,来判定页数
li = list()
for i in range(100):
li.append(i)
def user_list(request):
current_page = request.GET.get("p",1)
current_page = int(current_page)
start = (current_page-1) * 10
end = current_page * 10
data = li[start:end]
#获取总页数
all_count = len(li)
count,y = divmod(all_count,10) #返回商和余数,商是页数,余数是是否有最后一页
if y:
count += 1
page_list = list()
#利用后端往前端放
for i in range(1,count+1):
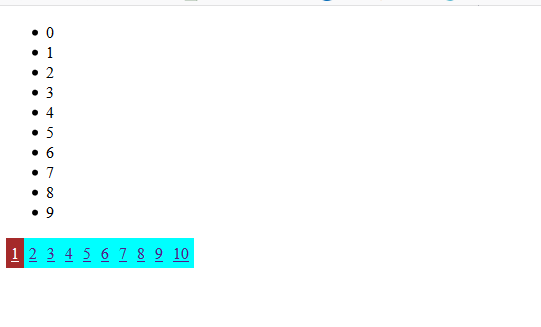
if i== current_page: #判断是否是当前页
temp = '<a class="page active" href="/user_list/?p=%s">%s</a>'%(i,i)
else:
temp = '<a class="page" href="/user_list/?p=%s">%s</a>'%(i,i)
page_list.append(temp)
page_str = ''.join(page_list) #拼凑
from django.utils.safestring import mark_safe
page_str = mark_safe(page_str) #防止xss攻击,否则前端不识别html
return render(request,'user_list.html',{'li':data,'page_str':page_str})
4.2、templates的user_list.html的代码:
<head>
<style>
.pagination .page{
display: inline-block;
padding: 5px;
background-color: cyan;
}
.pagination .page.active{
background-color: brown;
color: white;
}
</style>
</head>
<body>
<ul>
{% for item in li %}
<li>{{ item }}</li>
{% endfor %}
</ul>
<div class="pagination">
{{ page_str }}
</div>
</body>
效果如图:
五、xss攻击
在上面的view.user_list的代码发现这么一小段代码:
from django.utils.safestring import mark_safe page_str = mark_safe(page_str) #防止xss攻击,否则前端不识别html
这边有的同学就有疑问了,那我把这段代码去掉如何呢?就是直接把代码放到前端,那我们看view.user_list设置为这样的代码:
def user_list(request):
current_page = request.GET.get("p",1)
current_page = int(current_page)
start = (current_page-1) * 10
end = current_page * 10
data = li[start:end]
#从后端往前端放,直接把html的文本放到前端去
page_str = """
<a href="/user_list/?p=1">1</a>
<a href="/user_list/?p=2">2</a>
<a href="/user_list/?p=3">3</a>
"""
return render(request,'user_list.html',{'li':data,'page_str':page_str})
templates的user_list.html的代码:
<body>
<ul>
{% for item in li %}
<li>{{ item }}</li>
{% endfor %}
</ul>
<div>
{{ page_str }} #直接拿后端发过来的代码
</div>
</body>
效果如图:
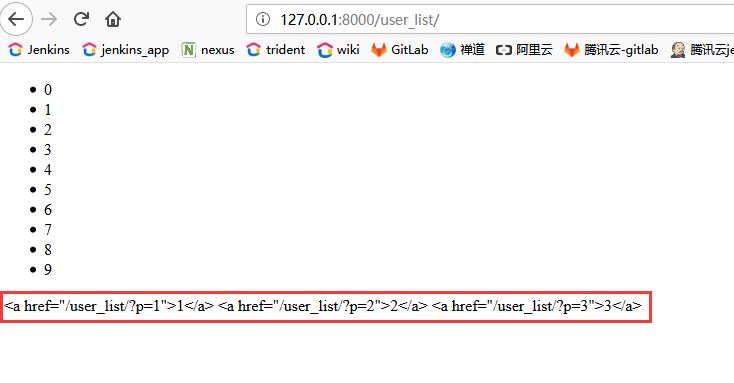
看到了吧?这边没有解析,那这个是为什么呢?
答:这边就要谈到XSS攻击了,就是说,在默认情况下,django认为所有的在页面上显示的字符串,都是不合法的,如果说这里边你想让它显示,你得说这是安全的,我让它显示,它才能显示,前端需要加上safe,后端需要经过make_safe处理。很多情况下,如果我们默认它安全的话,那如果有人瘫痪你的网站轻而易举,比如说,我在你的评论去输入一个死循环的script,那每次有人点进去就会进入一个死循环,当然这是一个最简单的攻击,还有其他攻击等等。
如何解决呐?这边有两种方式:
①前端通过safe处理
{{ page_str|safe }}
②通过后端make_safe处理,前端就不要动了
#后端
from django.utils.safestring import mark_safe
page_str = mark_safe(page_str) #防止xss攻击,否则前端不识别html
#前端
{{ page_str }} #正常取值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号