

DS博客作业01-线性表
0.PTA得分截图

1.本周学习总结
1.1 总结线性表内容
-
什么是线性表?
-
定义:
线性表是具有相同特性的数据元素的一个有限序列。 -
线性表一般表示:
(a1,a2,a3...ai..an)
这里a1为表头元素,an为表尾元素。 -
线性表特征:
1.元素个数n——表长度; n=0——空表
2.1<i<n时
a[i]的直接前驱是a[i-1],a[1]无直接前驱
a[i]的直接后继是a[i+1],
a[n]无直接后继 -
3.元素同构,且不能出现缺项
-
-
线性表的抽象数据类型描述
ADT List
{
数据对象D={ai|ai∈Elemset, i=1,2, . n, n≥0}
数据关系: R={<ai-1, ai>|ai-1,ai∈D, i=2, .., n}
基本操作:
InitList (&L) :构造一个空的线性表L
DestroyList (&L) :销毁线性表L占用内存空间
ListEmpty(L):若线性表L为空表,则返回TRUE,否则返回FALSE
ListLenght(L):返回线性表L数据元素个数
GetElem(L, i, &e):用e返回线性表L中第i个数据元素的值
LocatElem(L,e):返回L中第一个值域与e相等的逻辑位序。若这样的元素不存在,则返回值为0。
ListInsert(&L, i,e) :
ListDelete(&L, i, &e) :
}
//采自数据结构课堂派课件《第二章线性表--顺序表-预习》
- 顺序表:
- 存储结构:把线性表中的所有元素按照顺序存储方法进行存储的结构成为顺序表。
- 特点:
1、实现逻辑上相邻——物理地址相邻
2、实现随机存取 - 顺序表定义:
#define MaxSize 50
typedef int ElemType; //ElemType栈区类型实际上是int
typedef struct{
ElemType data[MaxSize]; //存放顺序表中的元素
int length;//顺序表的长度
}SqList; //SequenceList,顺序表
这里数组的大小要大于等于线性表的长度,也就是MaxSize
- 顺序表插入
在L->data的第i个位置插入e元素
![]()

实现代码:
bool ListInsert(List &L, int i, ElemType e)
{
int j;
if (i<1||i>L- > length+1)
return false;//参数错误时返回false
i-; //将顺序表逻辑序号转化为物理序号
for (j=L->length; j>i;j--) //将data[i.. n]元素后移一个位置
L->data[j]=L->data[j-1];
L->data[i]=e;//插入元素e
L-> | ength++; //顺序表长度增1
return true;//成功插入返回true
顺序表插入的时间复杂度为:0(n)
- 顺序表删除
删除第i个元素:
![]()
实现代码:
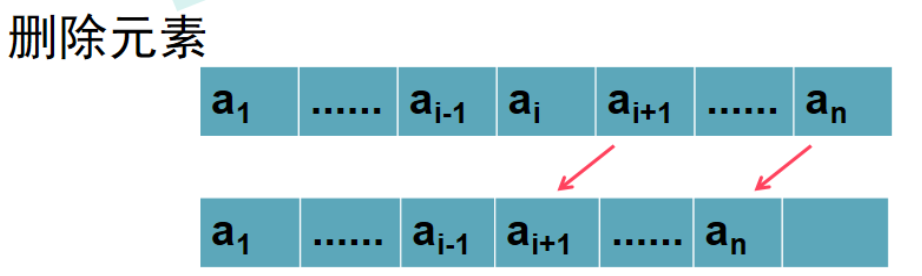
bool ListDelete(List &L,int i,ElemType &e)
{
if (i<1 ||i>L->length) //删除位置不合法
return false;
i-- ;/ /将顺序表逻辑序号转化为物理序号
e=L->data[i] ;
for (int j=i;j<L->length-1;j++)
L->data[j]=L->data [j+1];
L->length--; //顺序表长度减1
return true ;
}
顺序表删除的时间复杂度为:0(n).
- 链表——线性表的链式存储
- 结构体定义:
typedef struct LNode
{
EIemType data;//数据域
struct LNode *next;//指针域
}LNode,*LinkList;
- 头指针、头结点
以线性表中第一个数据元素a1的存储地址作为线性表的地址,称作线性链表的头指针。有时为了操作方便,在第一个结点之前虛加一个“头结点”,以指向头结点的指针为链表的头指针。 - 在链表中设置头结点的好处:
1.便于首元结点的处理
首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其它位置一致,无须进行特殊处理;
2.便于空表和非空表的统一处理
无论链表是否为空,头指针都是指向头结点的非空指针,因此空表和非空表的处理也就统一了。 - 链表的头插法——新增节点从链表头部插入
- 基本图示:
![]()
- 实现代码:
- 基本图示:

//将数组a中的元素赋值到链表L中,采用头插法所用代码
void CreateListF(LinkList &L,ElemType a[],int n)
{
int i;
L=new LNode;
L->next=NULL;
LinkList nodePtr;
for(i=0;i<n;i++)
{
nodePtr=new LNode;
nodePtr->data=a[i];
nodePtr->next=] L->next;
L->next= nodePtr;
}
}
这里链表每个节点务必都是动态申请,C语言中动态申请用malloc,而C++语法中用new,new的用法比malloc更简单,更容易使用,比如上述代码的nodePtr=new LNode;在C语言中相当于nodePtr=(LinkList)malloc(sizeof(LNode));
创建链表的时间复杂度:O(n)。
头插法建链表样例:jmu-ds-头插法建链表
- 链表的尾插法——新增节点从链表尾部插入
- 图示:
![]()
新节点插到当前链表的表尾上必须增加一个尾指针TailPtr,使其始终指向当前链表的尾节点。 - 实现代码:
- 图示:

void CreateListR(LinkList &L,ElemType a[],int n)
{
int i;
LinkList nodePtr,tailPtr;
L=new LNode;
L->next=NULL;
tailPtr=L;//尾指针
for(i=0;i<n;i++)
{
nodePtr= new LNode;
nodePtr->data=a[i];
tailPtrPtr->next=nodePtr;//尾部插入新结点
tailPtr=nodePtr;
}
nodePtr->next= NULL;
}
尾插法创建链表的时间复杂度:O(n),与头插法一样。
尾插法创建链表样例:jmu-ds-尾插法建链表
-
链表的插入
在链表L的指针p后面插入一个s所指向的结点
![]()
- 实现代码
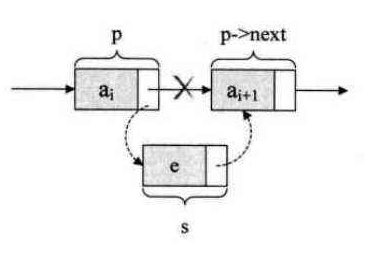
void LinkInsert(LinkList &L,LinkList &s,LinkList &p)
{
s->next=p->next;
p->next=s;
}
时间复杂度为O(1)。
-
链表的删除
删除在链表的第i个结点
![]()
- 实现代码

bool ListDelete(LinkList &L,int i)
{
int j=0;
LinkList p=L,s,q;
while(p&&j<i-1)
{
p=p->next;j++; //p->next为第i个位置
}
if(p==NULL)
return false;
q=p->next;//储存要删除的结点,后续delete掉
p->next=q->next;//改变指针关系,
delete q;
return true;//删除成功
}
时间复杂度为:O(1)。
- 有序单链表数据插入、删除,有序表合并
- 有序单链表数据插入
将元素e插入链表L:
- 有序单链表数据插入
void ListInsert(Linklist &L,int e)
{
LinkList pre=L,p;
while (pre->next!=NULL && pre->next->data<e)
pre=pre->next;//查找插入节点的前驱结点pre
p=new LNode;//创建存放e的数据结点*p
p->data=e;
p->next=pre->next;//在pre结点之后插入p结点
pre->next=p;
}
时间复杂度为O(1)。
- 有序单链表数据删除
在链表L中将数据元素为e的结点删除:
void ListDelete(LinkList& L, ElemType e)
{
LinkList NodePtr = L;
LinkList temp=NULL;
if (NodePtr->next==NULL)return;
while (NodePtr->next)
{
if (NodePtr->next->data == e)
{
temp = NodePtr->next;//储存要删除的结点,后续delete
NodePtr->next = NodePtr->next->next;
delete temp;
return;
}
NodePtr = NodePtr->next;
}
}
时间复杂度为O(1)。
有序链表插入删除PTA样例: jmu-ds-有序链表的插入删除
-
有序表合并
- 有序顺序表合并
设计思想:同时扫描2个有序顺序表LA和LB,比较LA,LB中元素,较小的元素插入合并链表LC,重复这个过程直到一个有序表扫描完毕。剩下的有序表元素都插LC。
操作代码:
void UnionList(SqList LA, SqList LB, SqList &LC)
{
int i=0,j=0,k=0://i、 j分别为LA、LB的下标,k为LC中元素个数
LC= new SqList; //建立有序顺序表LC
while (i<LA->length && j<LB->length)
{
if (LA->data[i]<LB->data[j])//LA元素较小,存入LC
{
LC->data[k++]=LA->data[i++];
}
else if(LA->data[i]>LB->data[j])//LB元素较小,存入LC
{
LC->data[k++]=LB->data[j++];
}
else if(LA->data[i]==LB->data[j])//LA与LB元素相等,存入LC,LA与LB均移入下一个项
{
LC->data[k++] = LB->data[j++];
i++;
}
}
while (i<LA->length) //LA尚未扫描完,将其余元素插入LC。
{
LC->data[k++]=LA->data[i++];
}
while (j<LB->length) //LA尚未扫描完,将其余元素插入LC。
{
LC->data[k++]=LB->data[j++];
}
LC->lenth=k;
}
时间复杂度为O(m+n)。(m+n)为两顺序表的元素个数之和。
- 有序链表合并
设计思路:
重建IA链表保存为C,p指针保存LA原始链表。
同时遍历LA,LB链表,较小元素插入链表LC。直到某个链表扫描完毕。链表有剩元素继续插入LC中。
操作代码:
void MergeList(LinkList& L1, LinkList L2)
{
LinkList ptr1=L1;
LinkList ptr2=L2;
LinkList temp;
while (ptr1->next && ptr2->next)
{
if (ptr1->next->data > ptr2->next->data)
{
temp = ptr2->next->next;
ptr2->next->next=ptr1->next;
ptr1->next = ptr2->next;
ptr2->next=temp;
}
else if (ptr1->next->data < ptr2->next->data)
{
ptr1 = ptr1->next;
}
else if (ptr1->next->data == ptr2->next->data)
{
ptr2 = ptr2->next;
}
}
if (ptr1->next == NULL)
{
ptr1->next = ptr2->next;
}
}
时间复杂度:O(m+n)。(m+n)为两顺序表的元素个数之和。
有序链表插入样例:jmu-ds-有序链表合并
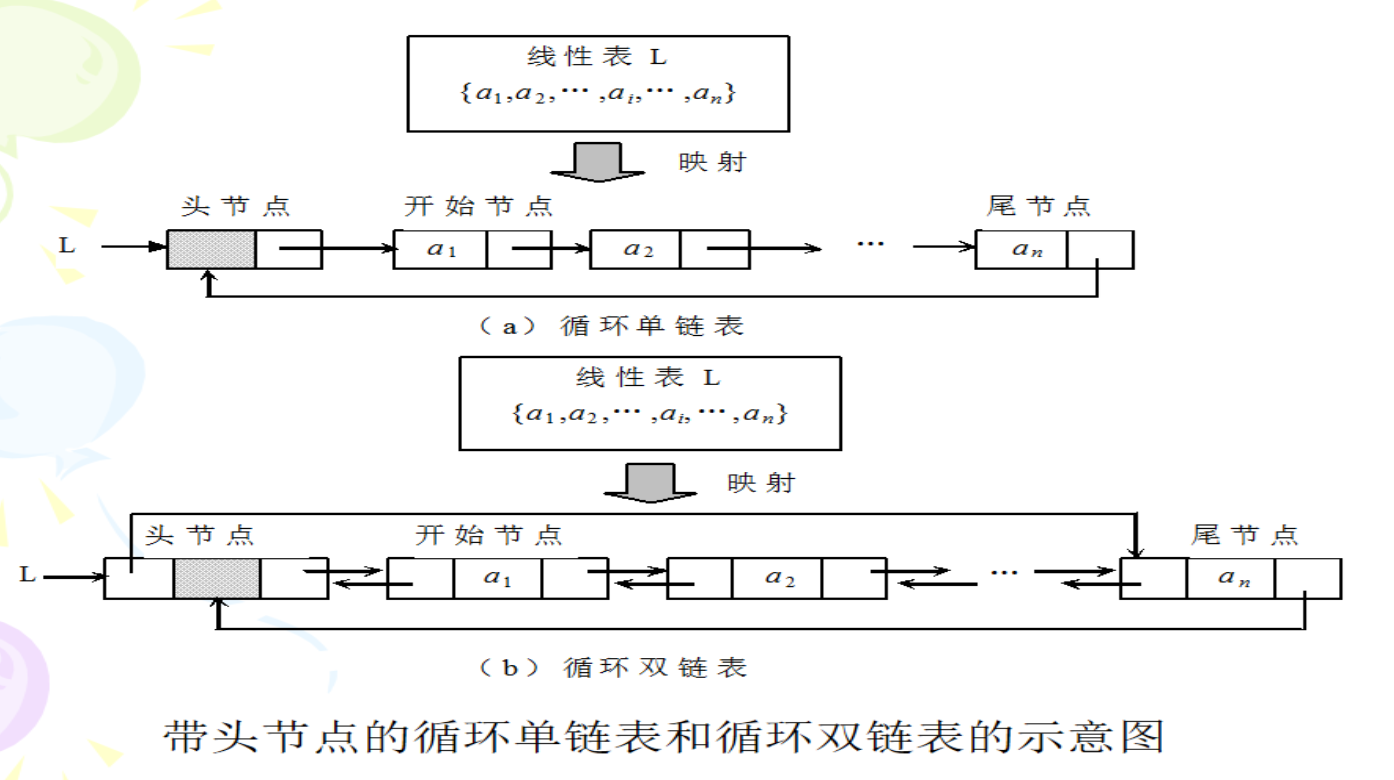
- 循环链表、双链表结构特点
- 双链表
双链表每个节点有2个指针域,一个指向后继节点,一个指向前驱节点。
类型定义如下:
- 双链表
typedef struct DNode
{
ElemType data ;
struct DNode *prior ;//指向前驱节点
struct DNode*next ;//指向后继节点
} DLinkList ;

双链表优点:
从任一结点出发可以快速找到其前驱结点和后继结点;从任一结点出发可以访问其他结点。
- 循环链表
循环单链表:将表中尾结点的指针域改为指向表头结点,整个链表形成一个环。由此从表中任一结点出发均可找到链表中其他结点。
循环条件:p->next!=L;
2.PTA实验作业
2.1.题目1:顺序表操作集
2.1.1代码截图:

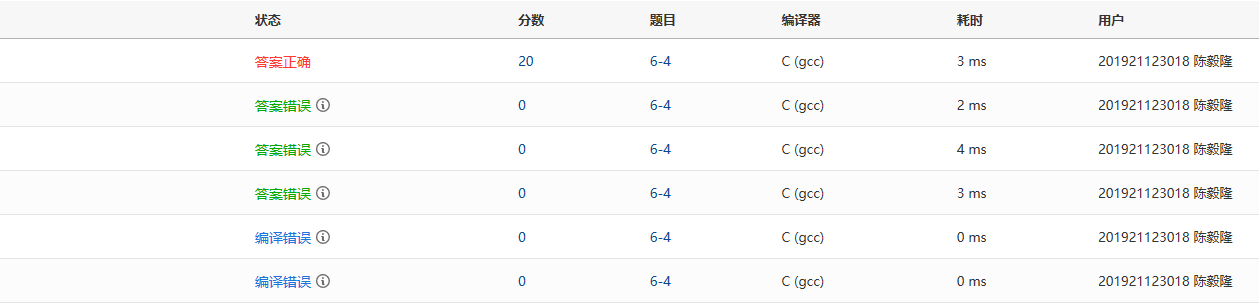
2.1.2本题PTA提交列表说明
PTA提交列表:
列表说明:
- Q1、Q2:编译错误:本题题目使用C语言,我用了C++语言提交,导致编译错误
以后要多区别这两个:
![]()
![]()
- Q3、Q4:答案错误:
Insert()函数编写错误。
判断参数P是否指向非法位置时错误
错误代码:

if (P<0 || P>MAXSIZE)
{
printf("ILLEGAL POSITION");
return false;
}
这是P插入位置已经超过最大长度时的判断条件
但是如果数组还没有到达最大长度,却插入非法,那这里的MAXSIZE应该修改为L->last,才符合题意。
即修改后的正确代码:
if (P<0 || P>L->Last)
{
printf("ILLEGAL POSITION");
return false;
}
- Q5答案错误:
Delete()函数编写错误
与Q3、Q4一样,是判断条件的错误
错误代码:
if (P < 0 || P >= MAXSIZE)
{
printf("POSITION %d EMPTY", P);
return false;
}
这是P删除位置已经超过最大长度时的判断条件,但是如果数组还没有到达最大长度,却删除非法,那这里的MAXSIZE应该修改为L->last,才符合题意。
与Q3、Q4一样,是判断条件的错误,而且错误是思路是一样的,这个地方错了两遍。
即修改后的正确代码:
if (P < 0 || P >= L->last)
{
printf("POSITION %d EMPTY", P);
return false;
}
2.2.题目2:jmu-ds-链表分割
2.2.1代码截图:
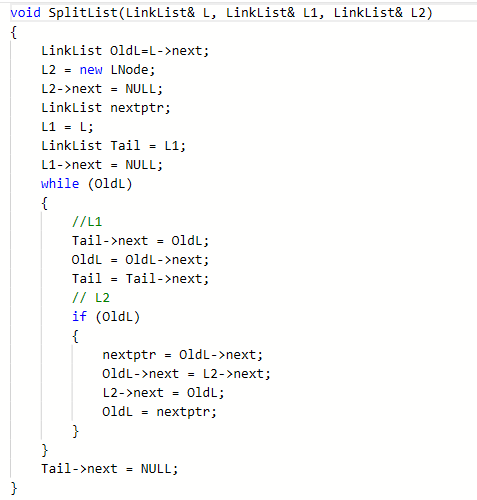
2.2.2本题PTA提交列表说明

提交列表说明:
-
Q1:多种错误:
审题错误,题目使用CreateListR尾插法建立初始链表,再进行操作,我在调试中使用了头插法建立链表,使得排序错乱。进而影响SplitList函数内容
解决:修改建链表函数,使之为尾插法建链表。并对SplitList函数进行修改 -
Q2:多种错误:
第一个错误:L1、L2分割错误。L1应该用尾插法建链表,L2应该用头插法建链表,我却对L1使用头插法建链表,对L2使用尾插法建链表,操作相反。在操作中将L1改为L2,L2改为L1即可。
第二个错误:链表终止条件缺漏,在L1建立一个结点之后,应该在L2建立结点之前判断L是否到达空节点,于是加入判断条件,使L2建立结点有一个前提条件:
if (OldL)
{
nextptr = OldL->next;
OldL->next = L2->next;
L2->next = OldL;
OldL = nextptr;
}
2.3.题目3:一元多项式的乘法与加法运算
3.阅读代码
3.1 题目及解题代码
解题代码:

3.1.1 该题的设计思路
历遍链表进行操作

时间复杂度:O(n)。
空间复杂度:O(1)。
3.1.2 该题的伪代码
定义dummy,dummy->next指向head;//其实此处的dummy就相当于带头结点链表的头指针了
定义pre=dummy;
定义cur=head;
定义tail=dummy;
while(1)//循环,在tail到达尾指针时break
{
int count=0计数,cout到k,循环k次
tail=pre;
while(tail不为尾指针且count<k)
{
tail=tail->next; //移动tail,退出循环后tail指向待反转链表的末尾节点
count++;
}
if(tail==NULL)
break;//已经历遍链表,退出循环
while(pre的next不为tail时)
{
cur=pre->next;//(1)
pre->next=cur->next; //(1) 步骤(1):将cur从链表中切出来
cur->next=tail->next;//(2)
tail->next=cur; //(2) 步骤(2):将cur添加到tail后
}
pre=head;//修改pre为head,为下一轮循环做准备
tail=head;//修改tail为head,为下一轮循环做准备
head=pre->next;//head指向新的待翻转的链表头
}
返回dummy->next;//即新链表
3.1.3 运行结果



3.1.4分析该题目解题优势及难点。
- 优势:历遍链表,简单粗暴。
思路明确,将有n个结点的链表,按每k个结点一次划分。 - 难点:
1、这个题目所操作的链表为不带头节点的链表,操作将较为繁琐。
2、并且历遍链表要准确判断每个指针的关系,这道题出现了5个指针,都在动态的变化,要明确结点现有位置、后继位置,才能成功完成题给要求,要求灵活使用指针,难度较大。
3.2 题目及解题代码
题目:

解题代码:

3.2.1 该题的设计思路
将单链表连接成循环链表,再进行移动。

时间复杂度:O(N)。
空间复杂度:O(1)。
3.2.2 该题的伪代码
if空链表或者k=0,则return head;
定义指针tail=head;
定义size记录链表长度
while(tail不为尾节点)
{
size++;
移动tail为tail->next;
}
if(k被size整除)return head;
tail->next=head;//首尾相连,形成环形链表
引入m=size-k%size;//tail移动m步,可到达新头节点的前驱节点
tail移动m步
定义新头节点res=tail->next;
tail->next置为空指针,断开环形链表;
返回新头节点res;
3.2.3 运行结果
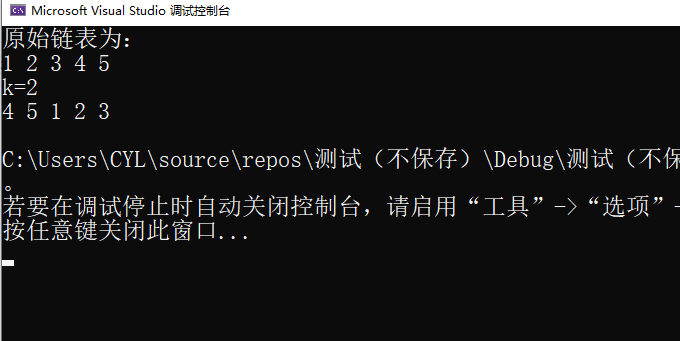

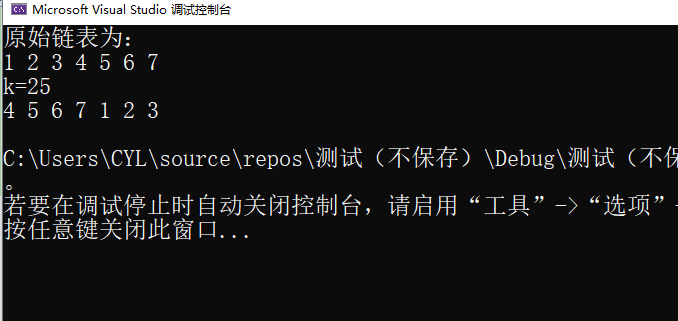
3.2.4分析该题目解题优势及难点。
- 解题优势:
代码简短,逻辑清晰。
构造循环链表,灵活处理单链表。 - 难点:
关于循环链表的处理,有些同学可能会不熟悉
以及tail的移动个数,要考虑k大于size的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号