
总结下参与以及看到的一些好的业务设计的 pattern
B端C端进行分离:
单场景业务应用表:业务表进行分离
对于B端系统来说,如发钱系统,B端需要存储 订单id、是否发放成功、通知状态等信息,有可能还会有发放失败,审核驳回等无用数据记录,但是对于C端用户界面来说往往比较简单、可能就是需要 用户、时间、金钱等信息,数据量少的时候在一张数据表存储是可以的,但是数据量越来越大的时候会有很多无用信息,同时C端查询也会受到影响,影响具体如扫描字段过多,无用字段过多等。
依赖多个数据表进行大数据量扫表:离线数据和在线数据进行拆库隔离
为什么需要进行拆库隔离:
-
大量的扫表查询影响buffer pool 的缓存命中率,影响C端用户的查询
依赖多张数据表进行扫表查询 select * from A where id >= a and id <= a+3000;
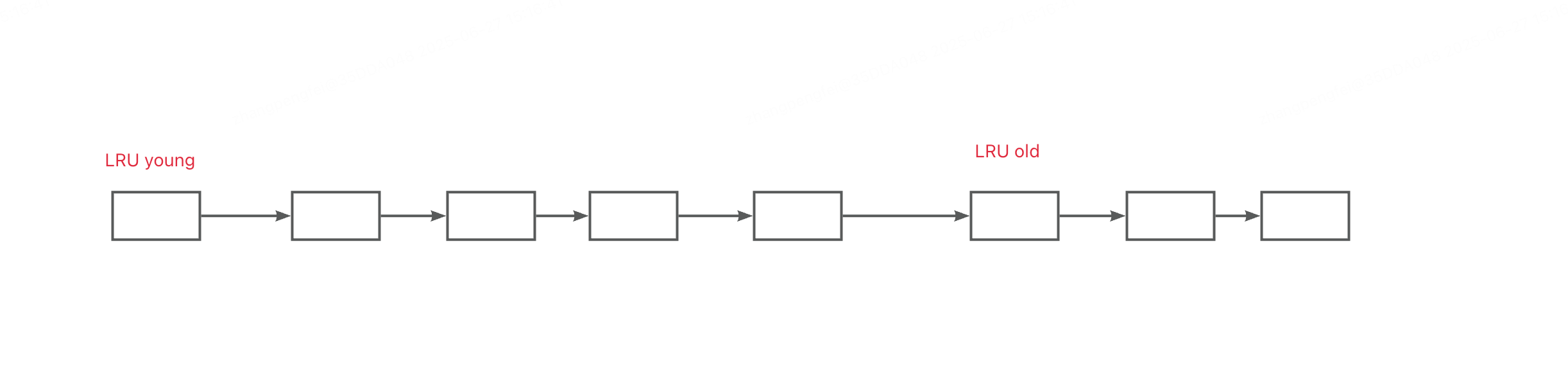
大量的扫表查询对MySQL 的 buffer pool 也会有影响,虽然 MySQL 对 LRU 进行了改进,新扫表写入的数据放到 old 区域,如果在LRU 链表中存在的时间超过1s中才会移动到链表的头部,也就是young 区域,这样保证了 buffer pool 的缓存命中率,不会导致热的数据页也淘汰掉。
![]()
-
离线HIVE表大批量的数据写入也会影响MySQL的性能,然后影响到C端查询的性能
任务依赖设计:
type,cdate,status 存储每个任务当天是否计算完成,如果依赖那个任务完成,需要检验它的状态是否完成
隔离稳定和变化多的模块:
稳定的模块如怎么加钱,减钱,怎么计算,计算流程是改动比较少的
但是对于运营来说,打折、扣减 这些是变化比较多的,隔离开经常变化和不经常变化的模块,让系统迭代更加稳定
类比到广告系统中:检索广告逻辑是比较通用的,但是客户端的样式是各种各样的,所以将检索模块和样式迭代隔离开,检索逻辑只返回 广告单元,然后再根据广告单元召回对应的样式进行返回。同时后续迭代样式,只改动样式服务就行,核心的检索逻辑不会进行变动。
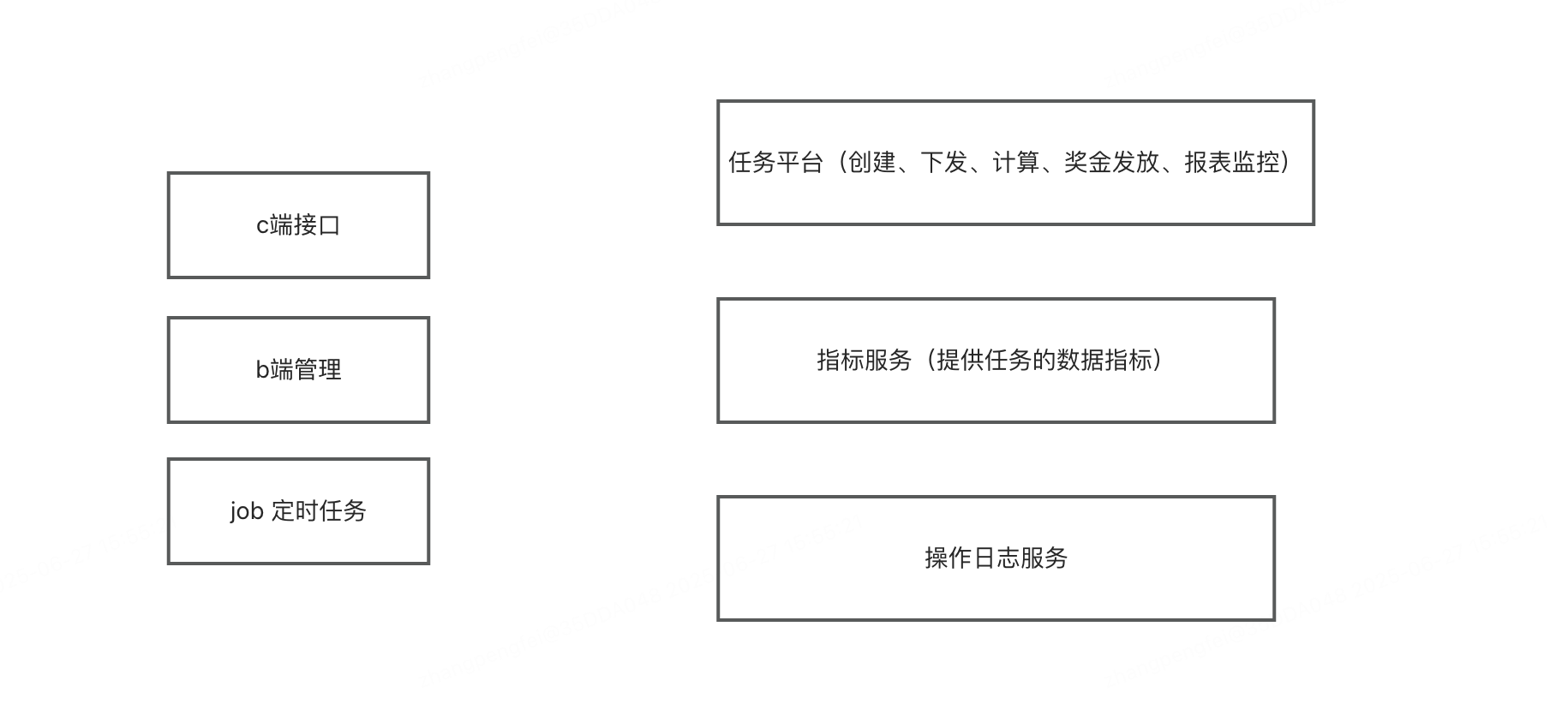
模块化服务:一个服务干一件事情
参考文章:MySQL 实战 45 讲(我查这么多数据,会不会把数据库内存打爆?)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号