
机器学习第四章复习
线性判定与回归
生成模型
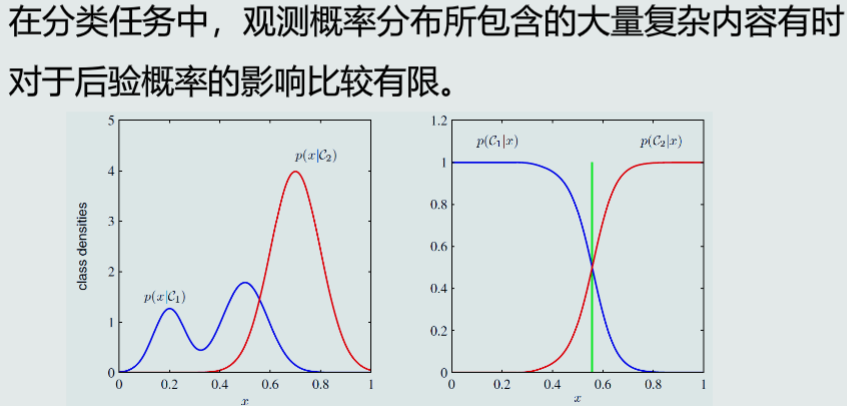
给定训练样本{Xn},直接在输入空间内学习其概率密度,P(x)
在贝叶斯决策分类中,生成模型通常用于估计每个类别的观测似然概率P(x|Ci),再结合先验概率,形成联合概率P(x,Ci)=P(x,Ci)P(Ci),然后,对所有类进行积分,得到边缘概率密度函数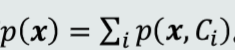 ,
,
最后得到后验概率
优势
可以根据p(x)采样新的样本数据
可以测验出较低概率的数据,实现离群点检测。
劣势
如果高维的x,需要大量训练样本才能准确的估计p(x),否则会出现维度灾难问题。

判别模型
给定训练样本{Xn},直接在输入空间内估计其后验概率P(Ci|x)
优势
快速直接省去了耗时的高维观测似然概率估计
线性判据
定义
如果判别模型f(x)是线性函数,则f(x)是线性判据
也可用于两类分类问题,决策边界是线性的
也可以用于多类,相邻两类之间的决策边界也是线性的
优势
计算量少:在学习和分类问题中,线性判据方法都比基于学习概率方法计算量少
适用于实验样本较少的情况
数学表达

决策边界
决策边界方程如下:

d维空间上的超平面记为H
任意样本到决策边界的距离为:

W0决定边界相对于目标原点的位置
目标函数
设计目标函数:目标函数反映了如何实现有效决策的核心思想
常见的目标函数如
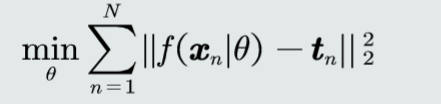
加入约束条件后使得解域范围收缩。
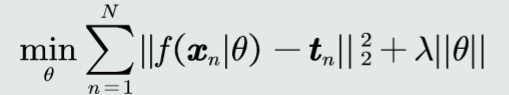

感知机算法
感知机算法目的:根据标记过的训练样本{(xn,tn)}学习模型参数:w,w0
预处理:
1、将两个参数合成一个参数a,线性判据改写为
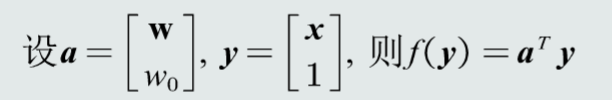
2、将C2类的样本全部取反,从而得到

几何上,通过在特征空间上增加一个维度,使得决策边界可以通过原点
翻转C2类样本,得到一个平面,使得所有样本位于该平面的同一侧

并行感知机
目标函数
针对所有被错误分类的训练样本,其输出值取反求和

该目标函数是a的一次线性函数
最小化其目标函数:去目标函数关于a的偏导
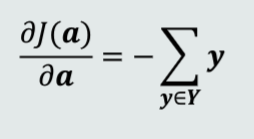
偏导不含有a,所以不能通过偏导为0 来求a
梯度下降算法
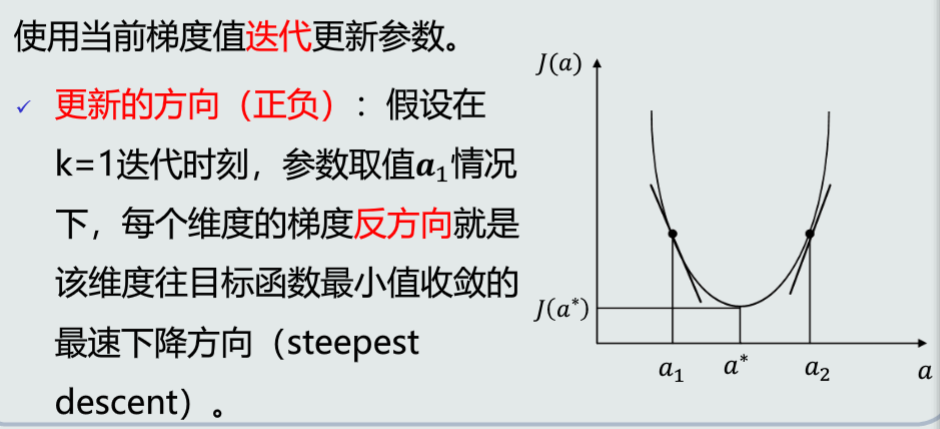
更新的大小:每个维度的梯度幅值代表参数在该维度上的更新程度
通常加入步长来调整更新的幅度。每次迭代可以用不同的步长
参数更新
根据梯度下降算法,参数a的更新公式为

将并行感知机的梯度公式带入:
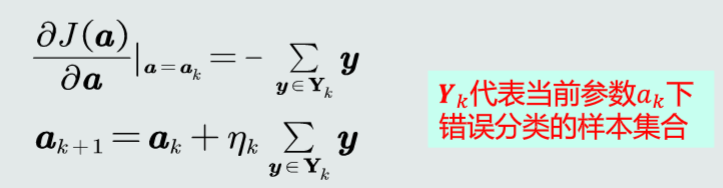
串行感知机算法
训练样本是串行给出的
目标函数
如果当前样本被错误分类,最小化其输出结果取反
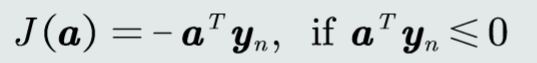
最小化目标函数:取关于参数向量a的偏导
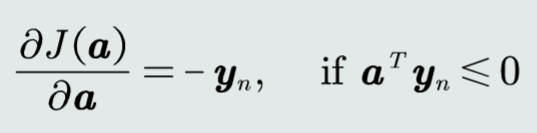

算法流程

收敛性
如果训练样本是线性可分的,感知机算法理论上收敛于一个解
Fisher线性判据
基本原理
找到一个最合适的投影轴,使两类样本在该轴上投影的重叠部分最少,从而使分来效果达到最佳
最佳标准之一:投影后,使得不同类别的样本分布的类间差异尽可能大,同时使得各自类内样本分布的离散程度尽可能小
类间样本的差异程度:用两类样本分布的均值之差度量
类内样本的离散程度:用每类样本分布的协方差矩阵表征
目标函数
在投影轴W上,最大化如下目标函数

优化后目标函数新表达
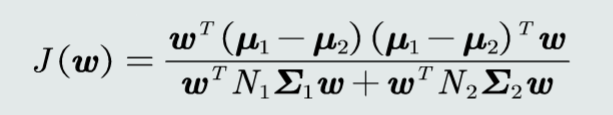
类间离散程度

目标函数求解

最优的W,无需求解最特征值
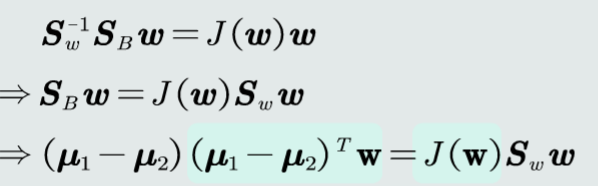
忽略标量项
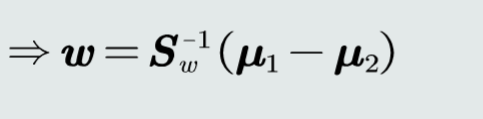
决策边界
决策边界方程如下:

该决策边界过u,斜率为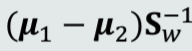 的超平面
的超平面
支持向量机基本概念
设计思想
给定一组训练样本,使得两个类中与决策边界最近的训练样本到决策边界之间的距离最大
目标函数
支持向量机的总目标:最大化总间隔
最大化间隔,等于最小化||W||所以目标函数设计为
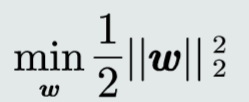
还要满足以下条件
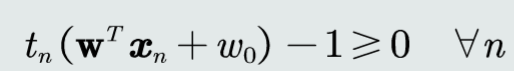
拉格朗日乘数法
拉格朗日乘数法(Lagrange Multiplier Method)在数学最优问题中,是一种寻找变量受一个或多个条件所限制的多元函数的极值的方法。
基本思想
作为一种优化算法,拉格朗日乘子法主要用于解决约束优化问题,它的基本思想就是通过引入拉格朗日乘子来将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题。拉格朗日乘子背后的数学意义是其为约束方程梯度线性组合中每个向量的系数。
比如两个变量求最优时,求 f(x, y) 在条件 g(x,y)=c 时的最大值,我们可以引入新变量拉格朗日乘数 \lambda,这时我们只需要下列拉格朗日函数的极值,此时就回归到了无约束时的最值问题:

KKT条件K
KKT条件是解决最优化问题的时用到的一种方法。这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值。
无约束时函数最优问题
这种问题,通常的解决办法是,对各变量求偏导,使得各偏导同时为零得到驻点。再判断驻点是否为极值点,最后代入原函数验证最优。
等式约束时的最优问题
设目标函数为 f(x,y), 约束条件为 g(x,y)=c。问题是如何在满足约束条件的情况下,使得目标函数最大(最小)。
发现原最优问题可以被替换成求
的最优问题。且这个问题不受g(x,y)所约束。
不等式约束条件
设目标函数f(x),不等式约束为g(x),此时的约束优化问题描述如下:
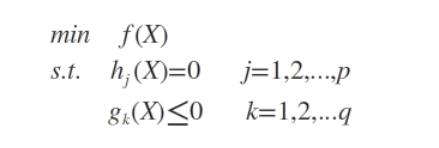
则我们定义不等式约束下的拉格朗日函数L,则L表达式为:
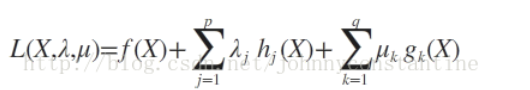
其中f(x)是原目标函数,hj(x)是第j个等式约束条件,λj是对应的约束系数,gk是不等式约束,uk是对应的约束系数。0
此时若要求解上述优化问题,必须满足下述条件(也是求解条件):

这些求解条件就是KKT条件。(1)是对拉格朗日函数取极值时候带来的一个必要条件,(2)是拉格朗日系数约束(同等式情况),(3)是不等式约束情况,(4)是互补松弛条件,(5)、(6)是原约束条件。
对于一般的任意问题而言,KKT条件是使一组解成为最优解的必要条件,当原问题是凸问题的时候,KKT条件也是充分条件。
拉格朗日对偶问题
(1)通过下面两步,构造拉格朗日函数为:
1、引入 松弛变量 / KKT乘子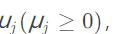 把不等式约束条件转化为等式约束条件。
把不等式约束条件转化为等式约束条件。
2、引入拉格朗日乘子λk把等式约束转化为无约束优化问题。

(2)定义拉格朗日对偶函数为拉格朗日函数把λ,μ当作常数,关于x取最小值得到的函数:

inf 表示下确界,infimum(sup,上确界,supremum)
它只是λ,μ的函数,与x无关。
(3)拉格朗日对偶问题
原问题是最小化f(x),显然,
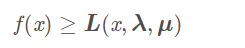
假设f∗是满足原问题约束下的最优解,则

所以g(λ,μ)是原问题最优解的下界。
找下界当然是要找最大的下界,所以导出拉格朗日对偶问题
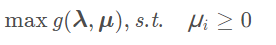
由于g(λ,μ)一定是凹函数,所以拉格朗日对偶问题一定是凸优化问题。
原问题的关于x的最小化转化为了对偶问题关于λ,μ的最大化。
(4)strong duality & weak duality
设d∗
是拉格朗日对偶问题的最优解,则不管原问题是不是凸优化问题,都一定有d∗=f∗
则强对偶成立。这时对偶函数是原问题的紧致下界。
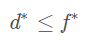
则弱对偶成立。
能不能取到强对偶条件取决于目标函数和约束条件的性质。如果满足原问题是凸优化问题,并且至少存在一个绝对可行点,那么就具有强对偶性。
支持向量机学习算法
用二次规划求解得到最优的 包含N个最优的拉格朗日乘数
包含N个最优的拉格朗日乘数
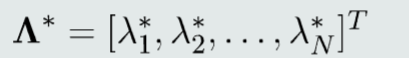
由KKT条件可得
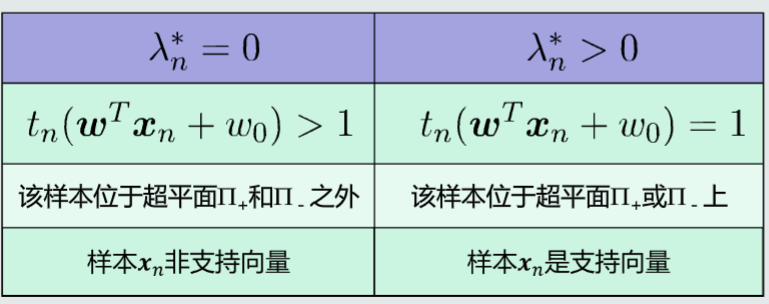
参数最优解


决策过程
给定一个测试模式x,支持向量机分类器可表达为
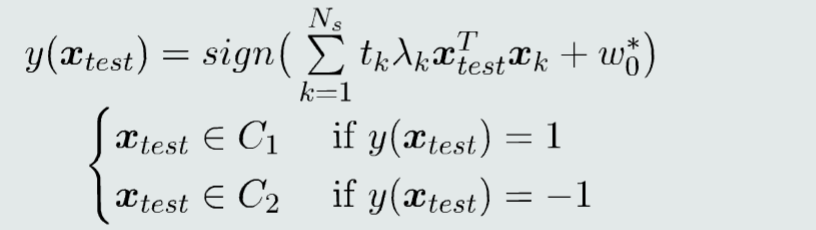
W和w0的学习过程实际上是从训练样本中选择一个支持向量,并将这些支持向量存储下来,用作线性分类器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号