关键词提取综述
1 背景
在NLP中,关键词提取能够从海量的文本中把关键的信息提取出来,同时关键词抽取作为nlp的底层基础模块,支持 标签、分类、推荐、搜索等很多上游任务,效果好坏程度直接关系到上层任务的最终效果,因此,关键词提取在文本挖掘领域是非常重要的一部分
2 关键词提取
需要的背景知识:序列标注、词性标注、机器翻译、tf-idf、分词、短语分割、质量短语
关键词抽取分为有监督、无监督、半监督三种方式:
- 有监督:能够利用更多的关键词特征,效果更优,缺点是标注成本高
- 无监督:不需要人工标注,更加快捷,缺点是无法综合利用各种信息对候选关键词排序,效果不如有监督
![]()
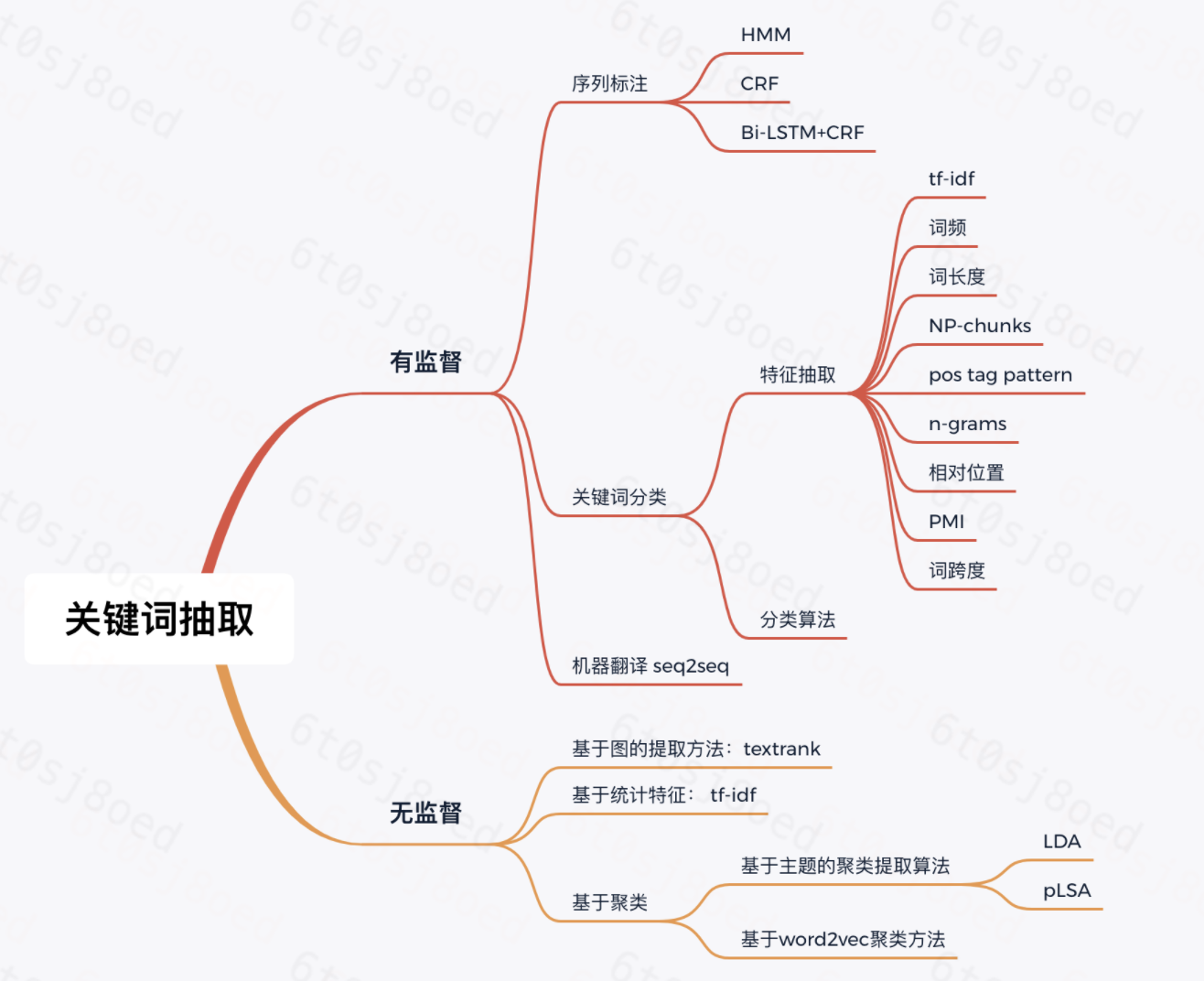
2.1 有监督
2.1.1 序列标注
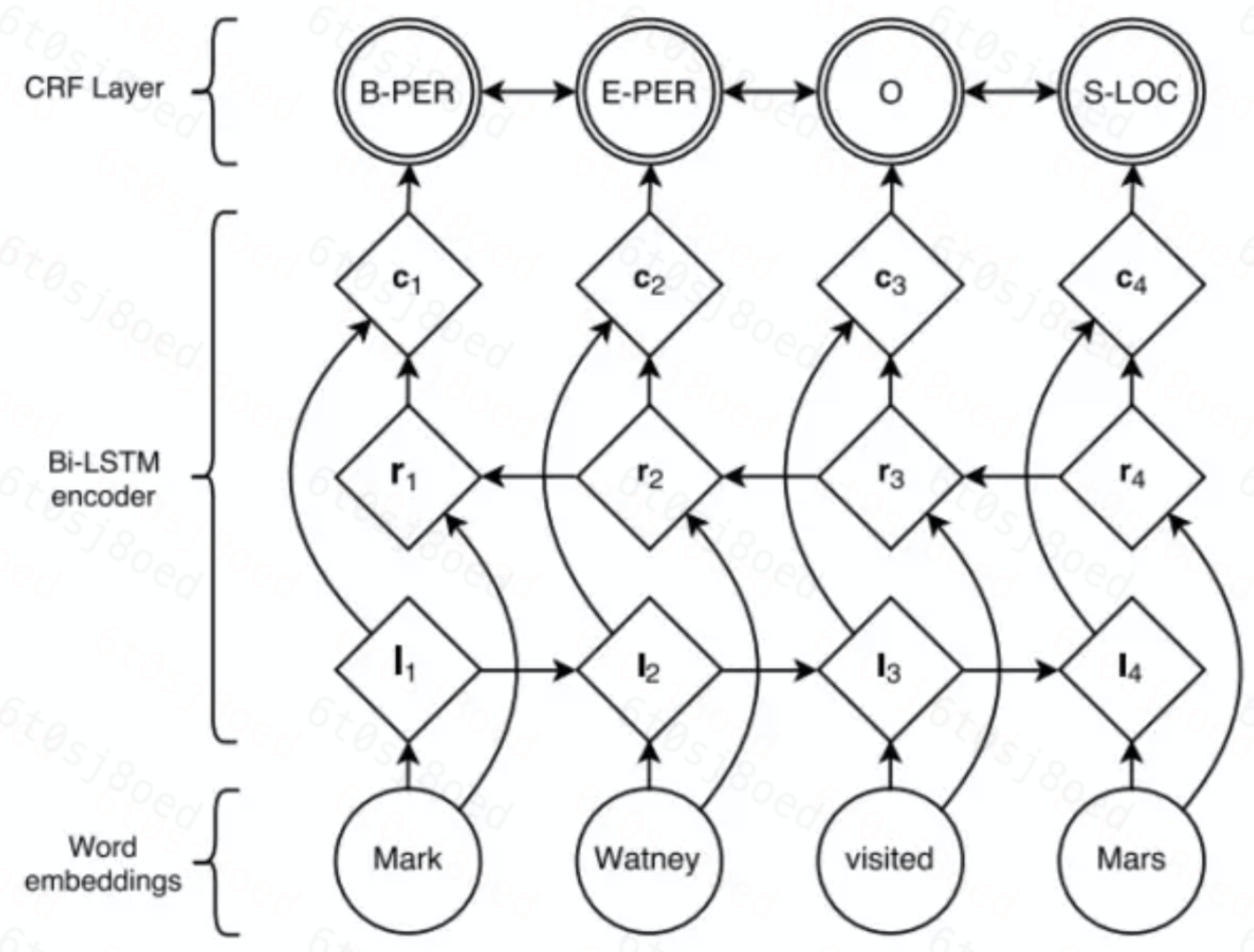
关键词提取转换为序列标注的问题,对文本里的每个字进行BIO标记,其中B表示关键词开始(Beginning),I表示关键词内部,O表示关键词外部,也可以用其他标记方式,根据具体任务决定。常见的标注模型有HMM,CRF,Bi-LSTM+CRF。
Eg:
| 你 | 这 | 是 | 喝 | 醉 | 了 | 么 |
|---|---|---|---|---|---|---|
| O | O | O | B | I | O | O |
| 美 | 女 | 能 | 加 | 个 | 微 | 信 | 么 |
|---|---|---|---|---|---|---|---|
| B | I | O | B | I | I | I | O |
推荐Bi-LSTM+CRF:
- 端到端,不需要手动提取特征
- 不需要分词,没有词截断问题
- 可以一定程度解决新词问题、实体问题
- 能够利用上下文相关性
网络结构(NER的例子):
2.1.2 关键词分类
把是否是关键词看做是一个二分类问题:
1) 数据处理
- 分词、去停用词
- 选出候选词集合
- 对候选词集合进行标注
2) 特征抽取
根据具体任务分析数据,选取关键词的特征,训练是否是关键词的二分类器,特征列表:
- 统计特征:词频TF、逆向文档频率IDF、n-grams、词长度、相对位置、词跨度、互信息PMI 等
- 词性特征:词性、词性组合等
3) 分类算法
分类算法根据特征抽取的结果选择,选择适合的常用分类算法即可。
2.1.3 机器翻译
论文:ACL2017 Deep Keyphrase Generation
该方法将关键词识别定义为一个生成式问题,采用seq2seq 结构,用端到端的方式生成关键词,在该论文中:
- Encoder部分将输入压缩成语义向量C,Decoder部分将语义向量C解码成关键词,Encoder和Decoder部分使用的都是双向的GRU
- 用到了attention机制,得到不同时刻的语义向量
- 提出新概念copy机制,来使模型可以基于位置信息找到重要部分,加入 copy 机制之后,每一个预测词 yt 的概率由两部分来决定,一部分是通过原模型框架 decoder 部分得到的预测词yt的生成概率,另一部分是从源文本中复制这个词的概率,模型更倾向于从原文中生成关键词
copy机制可参考论文: Incorporating Copying Mechanism in Sequence-to-Sequence Learning
需要注意的问题:
1 输入数据处理:
目前seq2seq只适用于单一序列到单一序列的学习,然而一段文本中会有好多个关键短语,因此在预处理过程中需要先将一个一对多的数据转化成多个一对一数据
2 输出部分需要注意的问题:
一篇文章可能有多个关键词,不同于机器翻译,对于生成的序列,机器翻译只需要找出一条最大概率路径即可,生成topn个关键词,选取topn个最大概率路径
2.2 无监督
2.2.1 基于统计特征:TF-IDF
TF-IDF是很强的baseline,具有较强的普适性,该算法基本能应付大部分关键词抽取的场景了。
主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的区分能力和表征能力
TF-IDF计算:
1) 计算词频
2)计算逆文档频率
3)计算TF-IDF

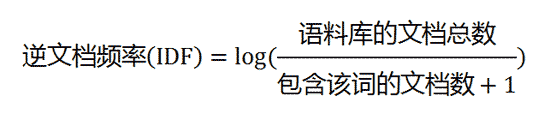
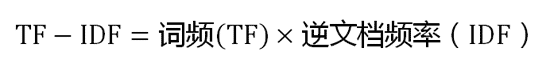
2.2.2 基于图:TextRank
主要思想是根据词和词的共现关系来构建图:词就是Graph中的节点,而词与词之间的边,则利用“共现”关系来确定(所谓“共现”,就是共同出现,即在一个给定大小的滑动窗口内的词,认为是共同出现的,而这些单词间也就存在着边)
TextRank 用于关键词提取的算法如下:
- 文本分句
- 对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词
- 构建候选关键词图 ,由(2)生成的候选关键词组成,然后采用共现关系构造任两点之间的边
- 根据 TextRank 的公式,迭代传播各节点的权重,直至收敛。
S(Vi)表示任意一个节点的权重,d是阻尼系数,一般取0.85,S(Vj)表示与S(Vi)有连接的节点,|Out(Vj)|表示Vj节点连接的节点的个数- 对节点权重进行倒序排序,从而得到最重要的 T 个单词,作为候选关键词。
- 由(5)得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
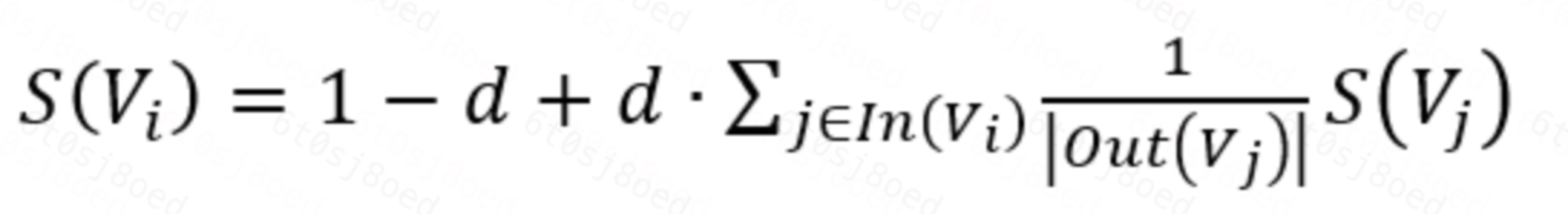
2.2.3 基于主题聚类:LDA
LDA(Latent Dirichlet Allocation)主题模型:
训练LDA模型,得到文章的主题分布,获取主题下的关键词
1)对文本进行分词、词性标注、去停用词等预处理
2)进行LDA模型训练,可用gensim等工具
3)获取主题以及主题词
2.2.4 基于word2vec聚类
算法原理:候选关键词聚类,距离类中心的距离比较近的词进行排序得到关键词
1)对语料进行Word2Vec模型训练,得到词向量文件
2)对文本进行预处理获得N个候选关键词
3)遍历候选关键词,从词向量文件中提取候选关键词的词向量表示
4)对候选关键词进行聚类,得到各个类别的聚类中心
5)计算各类别下,组内词语与聚类中心的距离,按聚类大小进行降序排序
6)对候选关键词计算结果得到排名前TopK个词语作为文本关键词
4 关键词提取工具
目前有很多开源的关键词提取工具,比如以下几种:
- jieba
- 哈工大LTP
- 中科院张华平博士的NLPIR
- Textrank4zh (TextRank算法工具)
- SnowNLP (中文分析)简体中文文本处理
5 结论
1)有监督效果比无监督效果要好
2)无监督也能满足大部分应用场景,推荐TF-IDF 和 聚类的方式,TextRank的实际应用效果并不比TF-IDF要好,并且计算量太大,不是很推荐
3)关键短语提取也很有意义,能够提取短语级别的粒度
4)关键词效果的好坏强依赖分词、词性标注等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号