数据挖掘课程学习——序列模式发现相关内容调研
数据挖掘课程学习——序列模式发现相关内容调研
本次实验完成"序列模式发现"的相关内容调研,主要内容包括:什么是序列模式发现;应用在哪些领域;经典的算法有哪些;应用在怎样的数据上;得到怎样的结果。其他内容自由发挥。提交实验报告的word文件。
概念
序列模式挖掘 (sequence pattern mining )是指挖掘相对时间或其他模式出现频率高的模式,典型的应用还是限于离散型的序列。
数据序列是指与单个对象相关联的时间的有序列表。设D为包含一个或多个序列的数据集。
序列s的支持度是包含s的所有数据序列所占的比例。如果序列s的支持度大于或等于用户指定的阈值minsup,则称s是一个序列模式(或频繁序列)
序列模式发现, 给定数据集D和用户指定的最小支持度阈值minsup,序列模式发现的任务是找出支持度大于或等于minsup的所有序列。
产生序列模式的一种蛮力方法是枚举所有可能的序列,并统计他们各自的支持度。
候选序列的个数比候选项集的个数大的多,这就需要采用更好的算法来减小复杂度。
应用领域
序列模式发现涉及多学科技术的集成,被信息产业界认为是人工智能与数据库系统最重要的前沿之一,是当前的热点研究领域。
序列模式发现是最重要的数据挖掘任务之一并有着广阔的应用前景,比如交易数据库中的客户行为分析,Web访问日志分析,科学实验过程的分析,文本分析,DNA分析和自然灾害预测等等。
经典算法
Apriori算法
Apriori算法是第一个关联规则挖掘算法,它开创性地使用基于支持度的剪枝技术,系统地控制候选项集指数增长。
对于文章开头表 6-1 中所示的事务,下图 6-5 给出Apriori算法频繁项集产生部分的一个示例。
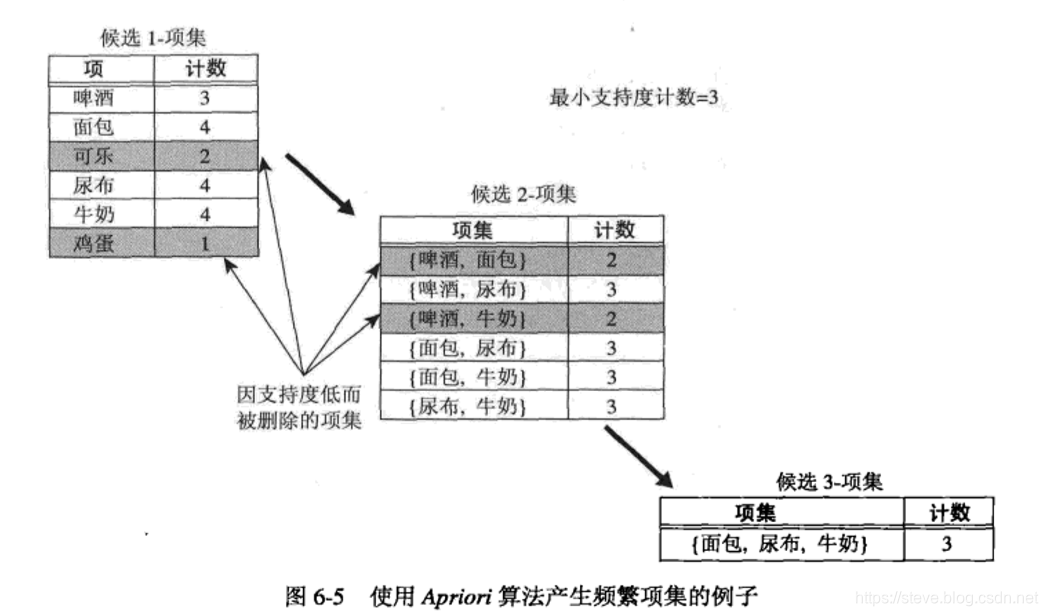
初始时每个项都被看作 候选1-项集。对它们的支持度计数之后,候选项集 {可乐} 和 {鸡蛋} 被丢弃。
在下一次迭代中,就只需使用 频繁1-项集 来产生 候选2-项集 ,由于只有4个 频繁1-项集,因此算法产生的 候选2-项集 的数目为 \(C(4, 2) = 6\)个。计算它们的支持度之后,发现4个候选项集是频繁的,因此用此4个来产生候选3-项集。
通过此例子可以看出先验剪枝策略的有效性。
枚举所有项集到3-项集的暴力策略过程将产生\(C(6, 1) + C(6, 2) + C(6, 3)=6+15+20=41\)个候选项;
而使用Apriori算法,只产生\(C(6, 1) + C(6, 2) + 1 = 13\)个候选。候选项集的数目降低了68%。
Apriori算法伪代码:![在这里插入图片描述]()

其中,\(C_k\) 为 候选k-项集,\(F_k\)为 频繁k-项集。
- 该算法初始通过单遍扫描数据集,确定每个项的支持度。产生 频繁1-项集 的集合\(F_1\)。(步骤1,2)
- 然后,该算法将使用上一次产生的 频繁(k-1)-项集,产生新的 候选k-项集(步骤5)。
- 为了计算新候选项集的支持度,算法需要再次扫描一遍数据集(步骤6-10)。使用子集函数发现事务t包含了哪些候选项集。
- 完成支持度计算后,算法将删去支持度小于支持度阈值minsup的所有候选项集,生成频繁k-项集。
当没有新的频繁项集或候选项集产生时,算法结束。
Apriori算法的重要特点:
- 它是一个逐层 ( level-wise ) 算法,即从频繁1-项集到最长的频繁项集,它每次遍历项集格中的一层;
- 它使用产生-测试 ( generate-and-test ) 策略来发现频繁项集。在每次迭代之后,新的候选项集都由前一次迭代发现的频繁项集产生,然后对每个候选的支持度进行计数,并与最小支持度阈值进行比较。该算法的总迭代次数是\(k_{max} + 1\),其中\(k_{max}\)是频繁项集的最大长度。
Java代码示例(摘自)
package cluster;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
/**
* Apriori算法实现 最大模式挖掘,涉及到支持度,但没有置信度计算
* @author push_pop
*
*/
public class AprioriMyself {
private static final double MIN_SUPPROT = 0.2;//最小支持度
private static boolean endTag = false;//循环状态
static List<List<String>> record = new ArrayList<List<String>>();//数据集
public static void main(String args[]){
//*************读取数据集**************
record = getRecord();
//控制台输出记录
System.out.println("以矩阵形式读取数据集record");
for(int i=0;i<record.size();i++){
List<String> list= new ArrayList<String>(record.get(i));
for(int j=0;j<list.size();j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
//************获取候选1项集**************
List<List<String>> CandidateItemset = findFirstCandidate();
//控制台输出1项候选集
System.out.println("第一次扫描后的1级 备选集CandidateItemset");
for(int i=0;i<CandidateItemset.size();i++){
List<String> list = new ArrayList<String>(CandidateItemset.get(i));
for(int j=0;j<list.size();j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
//************获取频繁1项集***************
List<List<String>> FrequentItemset = getSupprotedItemset(CandidateItemset);
//控制台输出1项频繁集
System.out.println("第一次扫描后的1级 频繁集FrequentItemset");
for(int i=0;i<FrequentItemset.size();i++){
List<String> list = new ArrayList<String>(FrequentItemset.get(i));
for(int j=0;j<list.size();j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
//***************迭代过程**************
while(endTag!=true){
//**********连接操作****由k-1项频繁集 获取 候选k项集**************
List<List<String>> nextCandidateItemset = getNextCandidate(FrequentItemset);
System.out.println("扫描后备选集");
for(int i=0;i<nextCandidateItemset.size();i++){
List<String> list = new ArrayList<String>(nextCandidateItemset.get(i));
for(int j=0;j<list.size();j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
//**************减枝操作***由候选k项集 获取 频繁k项集****************
List<List<String>> nextFrequentItemset = getSupprotedItemset(nextCandidateItemset);
System.out.println("扫描后频繁集");
for(int i=0;i<nextFrequentItemset.size();i++){
List<String> list = new ArrayList<String>(nextFrequentItemset.get(i));
for(int j=0;j<list.size();j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
//*********如果循环结束,输出最大模式**************
if(endTag == true){
System.out.println("Apriori算法--->频繁集");
for(int i=0;i<FrequentItemset.size();i++){
List<String> list = new ArrayList<String>(FrequentItemset.get(i));
for(int j=0;j<list.size();j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
}
//****************下一次循环初值********************
CandidateItemset = nextCandidateItemset;
FrequentItemset = nextFrequentItemset;
}
}
/**
* 读取txt数据
* @return
*/
public static List<List<String>> getRecord() {
List<List<String>> record = new ArrayList<List<String>>();
try {
String encoding = "GBK"; // 字符编码(可解决中文乱码问题 )
File file = new File("simple.txt");
if (file.isFile() && file.exists()) {
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTXT = null;
while ((lineTXT = bufferedReader.readLine()) != null) {//读一行文件
String[] lineString = lineTXT.split(" ");
List<String> lineList = new ArrayList<String>();
for (int i = 0; i < lineString.length; i++) {//处理矩阵中的T、F、YES、NO
if (lineString[i].endsWith("T")|| lineString[i].endsWith("YES"))
lineList.add(record.get(0).get(i));
else if (lineString[i].endsWith("F")|| lineString[i].endsWith("NO"))
;// F,NO记录不保存
else
lineList.add(lineString[i]);
}
record.add(lineList);
}
read.close();
} else {
System.out.println("找不到指定的文件!");
}
} catch (Exception e) {
System.out.println("读取文件内容操作出错");
e.printStackTrace();
}
return record;
}
/**
* 有当前频繁项集自连接求下一次候选集
* @param FrequentItemset
* @return
*/
private static List<List<String>> getNextCandidate(List<List<String>> FrequentItemset) {
List<List<String>> nextCandidateItemset = new ArrayList<List<String>>();
for (int i=0; i<FrequentItemset.size(); i++){
HashSet<String> hsSet = new HashSet<String>();
HashSet<String> hsSettemp = new HashSet<String>();
for (int k=0; k< FrequentItemset.get(i).size(); k++)//获得频繁集第i行
hsSet.add(FrequentItemset.get(i).get(k));
int hsLength_before = hsSet.size();//添加前长度
hsSettemp=(HashSet<String>) hsSet.clone();
for(int h=i+1; h<FrequentItemset.size(); h++){//频繁集第i行与第j行(j>i)连接 每次添加且添加一个元素组成 新的频繁项集的某一行,
hsSet=(HashSet<String>) hsSettemp.clone();//!!!做连接的hasSet保持不变
for(int j=0; j< FrequentItemset.get(h).size();j++)
hsSet.add(FrequentItemset.get(h).get(j));
int hsLength_after = hsSet.size();
if(hsLength_before+1 == hsLength_after && isSubsetOf(hsSet,record)==1 && isnotHave(hsSet,nextCandidateItemset)){
//如果不相等,表示添加了1个新的元素,再判断其是否为record某一行的子集 若是则其为 候选集中的一项
Iterator<String> itr = hsSet.iterator();
List<String> tempList = new ArrayList<String>();
while(itr.hasNext()){
String Item = (String) itr.next();
tempList.add(Item);
}
nextCandidateItemset.add(tempList);
}
}
}
return nextCandidateItemset;
}
/**
* 判断新添加元素形成的候选集是否在 新的候选集中
* @param hsSet
* @param nextCandidateItemset
* @return
*/
private static boolean isnotHave(HashSet<String> hsSet,
List<List<String>> nextCandidateItemset) {
// TODO Auto-generated method stub
List<String> tempList = new ArrayList<String>();
Iterator<String> itr = hsSet.iterator();
while(itr.hasNext()){
String Item = (String) itr.next();
tempList.add(Item);
}
for(int i=0; i<nextCandidateItemset.size();i++)
if(tempList.equals(nextCandidateItemset.get(i)))
return false;
return true;
}
/**
* 判断hsSet是不是record2中的某一记录子集
* @param hsSet
* @param record2
* @return
*/
private static int isSubsetOf(HashSet<String> hsSet,
List<List<String>> record2) {
//hsSet转换成List
List<String> tempList = new ArrayList<String>();
Iterator<String> itr = hsSet.iterator();
while(itr.hasNext()){
String Item = (String) itr.next();
tempList.add(Item);
}
for(int i=1;i<record.size();i++){
List<String> tempListRecord = new ArrayList<String>();
for(int j=1;j<record.get(i).size();j++)
tempListRecord.add(record.get(i).get(j));
if(tempListRecord.containsAll(tempList))
return 1;
}
return 0;
}
/**
* 由k项候选集剪枝得到k项频繁集
* @param CandidateItemset
* @return
*/
private static List<List<String>> getSupprotedItemset(List<List<String>> CandidateItemset) {
// TODO Auto-generated method stub
boolean end = true;
List<List<String>> supportedItemset = new ArrayList<List<String>>();
int k = 0;
for (int i = 0; i < CandidateItemset.size(); i++){
int count = countFrequent(CandidateItemset.get(i));//统计记录数
if (count >= MIN_SUPPROT * (record.size()-1)){
supportedItemset.add(CandidateItemset.get(i));
end = false;
}
}
endTag = end;//存在频繁项集则不会结束
if(endTag==true)
System.out.println("无满足支持度项集,结束连接");
return supportedItemset;
}
/**
* 统计record中出现list集合的个数
* @param list
* @return
*/
private static int countFrequent(List<String> list) {
// TODO Auto-generated method stub
int count = 0;
for(int i = 1; i<record.size(); i++) {
boolean notHaveThisList = false;
for (int k=0; k < list.size(); k++){//判断record.get(i)是否包含list
boolean thisRecordHave = false;
for(int j=1; j<record.get(i).size(); j++){
if(list.get(k).equals(record.get(i).get(j)))//list。get(k)在record。get(i)中能找到
thisRecordHave = true;
}
if(!thisRecordHave){//只要有一个list元素找不到,则退出其余元素比较,进行下一个record。get(i)比较
notHaveThisList = true;
break;
}
}
if(notHaveThisList == false)
count++;
}
return count;
}
/**
* 获得一项候选集
* @return
*/
private static List<List<String>> findFirstCandidate() {
// TODO Auto-generated method stub
List<List<String>> tableList = new ArrayList<List<String>>();
HashSet<String> hs = new HashSet<String>();
for (int i = 1; i<record.size(); i++){ //第一行为商品信息
for(int j=1;j<record.get(i).size();j++){
hs.add(record.get(i).get(j));
}
}
Iterator<String> itr = hs.iterator();
while(itr.hasNext()){
List<String> tempList = new ArrayList<String>();
String Item = (String) itr.next();
tempList.add(Item);
tableList.add(tempList);
}
return tableList;
}
}
AprioriAll算法
AprioriAll算法与Apriori算法的执行过程是一样的,不同点在于候选集的产生,具体候选者的产生如下:
候选集生成的时候需要区分最后两个元素的前后,因此就有<p.item1,p.item2,…,p.,q.>和<p.item1,p.item2,…, q.,p.>两个元素。
AprioriSome算法
AprioriSome算法可以看做是AprioriAll算法的改进,具体可以分为两个阶段:
(1)Forward阶段:找出置顶长度的所有大序列,在产生Li后,根据判断函数j=next(last),此时last=i,j>i,下个阶段不产生i+1的候选项,而是产生j的候选项,如果j=i+1,那么就根据Li生成Cj,如果j>i+1,那么Cj就有Cj-1产生。然后扫描数据库计算Cj的支持度。
(2)Backward阶段:根据Lj中的大项集,去掉Ci(i<j)中出现的Lj项,然后计算Ci中的支持度,判断那些在Forward阶段被漏判的项集。
AprioriAll算法和AprioriSome算法的比较:
(1)AprioriAll用去计算出所有的候选Ck,而AprioriSome会直接用去计算所有的候选,因为包含,所以AprioriSome会产生比较多的候选。
(2)虽然AprioriSome跳跃式计算候选,但因为它所产生的候选比较多,可能在回溯阶段前就占满内存。
(3)如果内存占满了,AprioriSome就会被迫去计算最后一组的候选。
(4)对于较低的支持度,有较长的大序列,AprioriSome算法要好些。
GSP算法
GSP(Generalized Sequential Patterns)算法,类似于Apriori算法大体分为候选集产生、候选集计数以及扩展分类三个阶段。与AprioriAll算法相比,GSP算法统计较少的候选集,并且在数据转换过程中不需要事先计算频繁集。
GSP的计算步骤与Apriori类似,但是主要不同在于产生候选序列模式,GSP产生候选序列模式可以分成如下两个步骤:
(1)连接阶段:如果去掉序列模式S1的第一个项目与去掉序列模式S2的最后一个项目所得到的序列相同,则可以将S1和S2进行连接,即将S2的最后一个项目添加到S1中去。
(2)剪枝阶段:若某候选序列模式的某个子集不是序列模式,则此候选序列模式不可能是序列模式,将它从候选序列模式中删除。
应用过程
典型的应用还是限于离散型的序列。
参考来源:
[1]: https://blog.csdn.net/yohjob/article/details/92198700
[2]: https://baike.baidu.com/item/序列模式/6009963?fr=aladdin
[3]: https://blog.csdn.net/u010498696/article/details/45641719/)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号