


Spark1.6.0 on Hadoop2.6.0 完全分布式安装
1、SCALA安装
1)下载并解压scala
master@Master:~$ sudo tar -zxvf scala-2.10.4.gz -C /opt

2)配置scala变量
master@Master:~$ sudo gedit /etc/profile
#SCALA
export SCALA_HOME=/opt/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
master@Master:~$ source /etc/profile
3)测试scala运行环境

2、SPARK安装
1)下载并解压spark
master@Master:~$ sudo tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz -C /home/hnu

2) 配置spark环境变量
master@Master:~$ sudo gedit /etc/profile
#SPARK
export SPARK_HOME=/home/hnu/spark-1.6.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
master@Master:~$ source /etc/profile
3)配置spark
master@Master:/home/hnu/spark-1.6.0-bin-hadoop2.6/conf$
master@Master:/home/hnu/spark-1.6.0-bin-hadoop2.6/conf$ sudo cp spark-env.sh.template spark-env.sh
master@Master:/home/hnu/spark-1.6.0-bin-hadoop2.6/conf$ sudo gedit spark-env.sh
#spark
export JAVA_HOME=/opt/jdk1.8.0_91
export SCALA_HOME=/opt/scala-2.10.4
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/hnu/hadoop-2.6.0/etc/hadoop
export SPARK_PID_DIR=/home/hnu/hadoop-2.6.0/pids
export SPARK_DIST_CLASSPATH=$(/home/hnu/hadoop-2.6.0/bin/hadoop classpath)
master@Master:/home/hnu/spark-1.6.0-bin-hadoop2.6/conf$ sudo cp slaves.template slaves
master@Master:/home/hnu/spark-1.6.0-bin-hadoop2.6/conf$ sudo gedit slaves
#slaves
slave1
slave2
4) 向各节点复制spark
hnu@Master:~$ scp -r ./spark-1.6.0-bin-hadoop2.6/ slave1:~
hnu@Master:~$ scp -r ./spark-1.6.0-bin-hadoop2.6/ slave2:~
5)赋予权限
对master/slave1/slave2执行相同操作
将目录spark-1.6.0-bin-hadoop2.6文件夹及子目录的所有者和组更改为用户zgx和组hadoop
root@Master:/home/hnu# chown -R hnu:hadoop spark-1.6.0-bin-hadoop2.6/
6)启动spark
hnu@Master:~/spark-1.6.0-bin-hadoop2.6/sbin$ ./start-all.sh

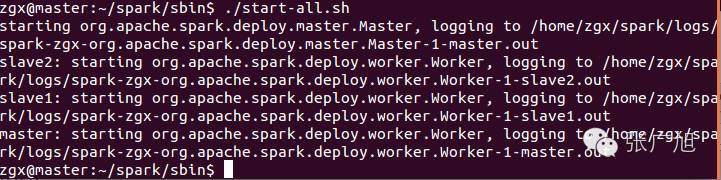
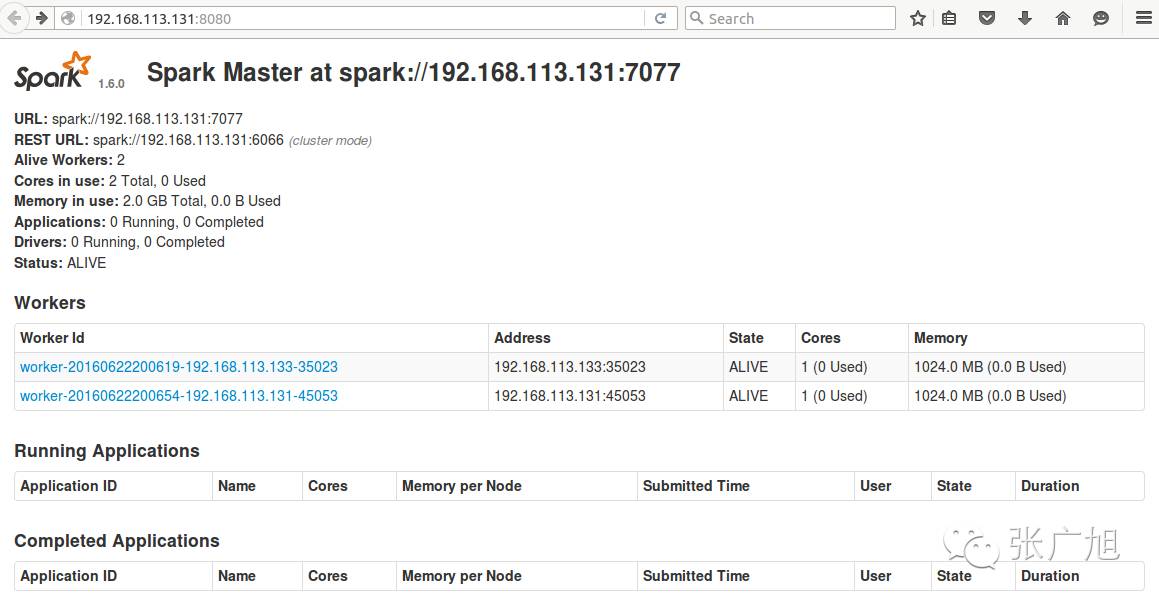
访问master:8080或者192.168.113.131:8080
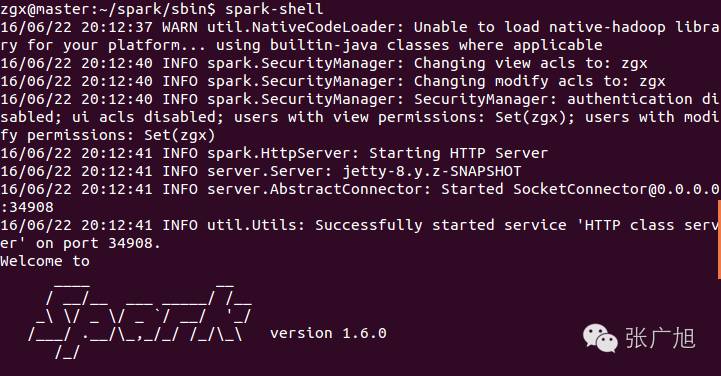
运行./spark-shell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号