
调参工程师的日常
近期调参感受:
- 在实际项目中数据和特征对最终的效果贡献是最大的,所以要花时间打造你的数据流,花时间多想一些特征,特征要算准。
- word2vec、FFM、XgBoost这些算法之所以能得到业界公认,是因为他们在各种数据集上都表现良好,而且对参数不太敏感。
试验总结:
- FFM优于FM,FM优于LR。
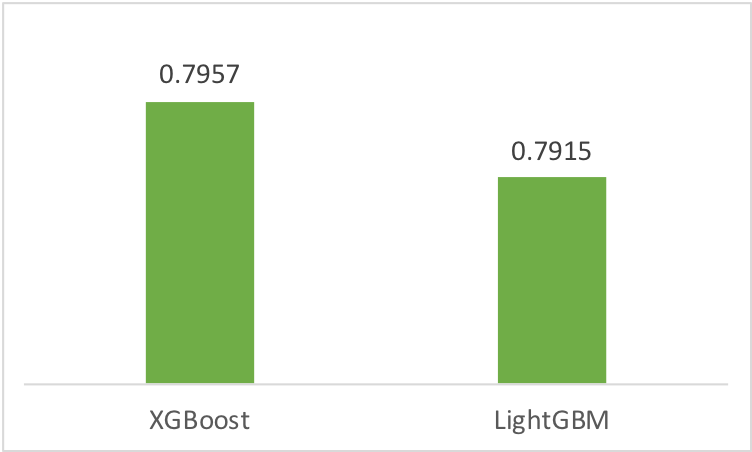
- XGBoost和LightGBM效果几乎接近,比上述线性模型(多项式模型)好很多,LightGBM训练速度比XGBoost快。
- 利用LightGBM产生组合特征,再过一层LR/FM/FFM,效果并没有超越单纯的LightGBM。
word2vec
from gensim.models import Word2Vec model = Word2Vec(sentences, size=100, # 特征向量的维度,比200好 window=5, # 前后各取5个词作为context,增到8效果没有好转 min_count=20, # 出现次数低于该频率的词直接忽略掉 iter=150, # 迭代次数 hs=0, # hs=1表示hierarchical softmax。负采样比hierarchical softmax效果好 negative=10, # 如果要采用负采样,negative表示负采样时背景噪声词的个数。改为20后效果并没有好转 workers=8, # 并行数 sample=1e-4, # 对高频词进行下采样,通常取值在(0,1e-5)。调参结果见下表 )
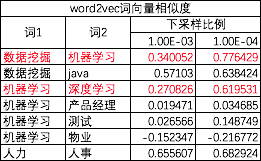
可见下采样参数sample还是很重要的,由1e-3降为1e-4后,<数据挖掘,机器学习>和<机器学习,深度学习>的相似度得到了明显改善。
有2个用户,他们的标签分别是【java|工程师|python|机器学习|模式识别|算法】、【研究生|机器学习|硕士|it研发】,我们有每个词的word2vec向量,现在要计算2个词集的相似度,有3各方法:
- 各词向量取average。考虑了每个词的信息
- 各词向量取max。考虑最显著特征信息(比较注重关键词,忽略平常词)
- average的max拼接起来
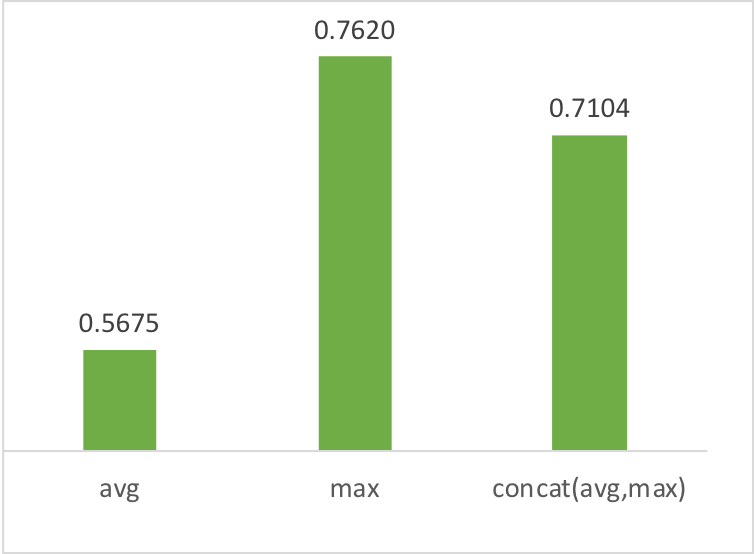
max法重点强调了“机器学习”这个关键词,得到的相似度比较高。方法3是前2种方法的中和。此处参考基线系统需要受到更多关注:基于词向量的简单模型 | ACL 2018论文解读
XGBoost LightGBM
import xgboost params = { 'booster': 'gbtree', #单个booster是采用线性模型还是树模型 'objective': 'binary:logistic', #目标函数 'eta': 0.01, # 每个booster设置相同的学习率 'gamma': 0.1, # 对叶节点个数的惩罚系数 'lambda': 2, # L2正则化项系数,控制叶节点的输出值 'max_depth': 15, 'subsample': 0.7, # 行采样。是否进行行采样对效果没什么影响 'colsample_bytree': 0.7, # 列采样。不进行列采样效果会差一点 'min_child_weight': 10, # 叶节点最少样本数 'silent': 0, # 设置成1则没有运行信息输出,最好是设置为0. 'seed': 0, 'eval_metric': 'logloss', 'nthread': 8, # 并行数 'tree_method': 'exact', # 在所有样本上遍历可能的分割点。计算量太大,默认使用的是approx,即只在分位点上尝试分割。exact比approx效果会好一点点 } # num_boost_round:booster的个数,对于tree boost就是树的个数。每生成一棵树都会去调用一个callback,比如通过callback可以重置学习率[xgb.callback.reset_learning_rate(custom_rates)] model = xgboost.train(params.items(), train_data, num_boost_round=300, callbacks=[])
使用列采样技巧后,AUC提升了1个点,其他参数对AUC影响不大。
import lightgbm params = { 'task': 'train', 'boosting_type': 'dart',# gbdt:0.795695; GOSS:0.7917279; dart:0.7985638; rf:0.714062 'objective': 'binary', 'metric': {'binary_logloss', 'auc'}, 'max_bin': 255, 'num_leaves': 500, 'min_data_in_leaf': 10, 'num_iterations': 300, # 300棵树 'learning_rate': 0.2, # 学习率太大,容易过拟合 'feature_fraction': 0.7, # 列采样比例 # rf时使用,gbdt也可以使用 # 'bagging_fraction': 0.7, # 行采样比例,使用rf时这个比例必须小于1 # 'bagging_freq': 5, # 每隔几轮进行一次行采样 # GOSS时使用 # 'top_rate':0.3, # 'other_rate':0.3, # dart时使用 'drop_rate':0.7, 'skip_drop':0.7, 'max_drop':5, 'uniform_drop':False, 'xgboost_dart_mode':True, 'drop_seed':4, 'verbose': 0, 'num_threads': 8, } gbm = lightgbm.train(params=params, train_set=train_data, valid_sets=test_data)
boosting_type效果对比:rf<gbdt<goss<dart。
学习率太大,容易过拟合。每轮迭代都打印训练集和测试集上的AUC,会发现learning_rate>0.2时,比如0.5、1.0,在训练集上的AUC会比较高,而在测试集上的AUC比较低,learning_rate为0.2时在测试集上的AUC是最高的。
LightGBM在100棵的时候,测试集上的AUC就已经到0.78了,后面的200棵树只是将AUC提升了1个点。
LightGBM由于是采样训练,效果比XGBoost稍差一点,但速度快,能快多少取决采样的比例,试验中LightGBM dart耗时是XGBoost的一半。
LightGBM+LR
用LightGBM根节点到每一个叶节点的路径作为一个组合特征,再输给LR去训练。LR拿到的特征数等于所有叶节点的个数,一棵树有500个叶节点,lightgbm有300棵树,那一共就有150000个叶节点,维度很高,但实际上一个样本在一棵树上只会命中一个叶节点,所以一个样本上非0的维度等于树的个数。试验中我们只取了LightGBM的前100棵树(别忘了LightGBM在100棵树的时候AUC是0.78)。另外这里选用LightGBM而不是XGBoost,是因为LightGBM是leaf-wise生长的,max leaf是可以控制的(实际上每棵树都可以达到max leaf),这样在给所有叶节点编号时简单一些,仅此而已,并不是说XGBoost效果不好。
还可以把LightGBM产生的组合特征与原始特征拼接起来,一同输给LR去训练。
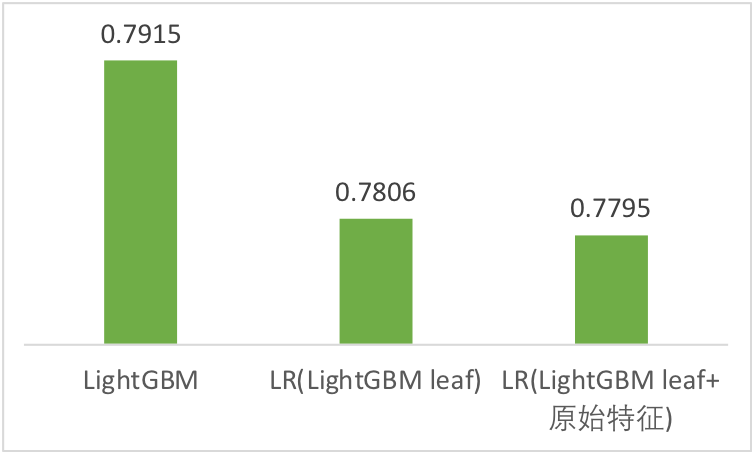
看来LightGBM已把这些特征学习到极致了,即使LR拿到这些组合特征也学不到更好的效果。线性模型还是敌不过非线性模型。决策树得到的是特征组合,但还是在原先的特征空间内,而深度学习是创造了新的特征,超越了原始的特征空间。
LR FM FFM
import xlearn ffm_model = xlearn.create_ffm() ffm_model.setTrain(ffm_train_file) ffm_model.setValidate(ffm_test_file) params = { 'task': 'binary', # 二分类。也可以设为reg 'lr': 0.2, # 学习率。adagrad的学习率是自适应的,这个学习率只是初始的学习率 'lambda': 0, # 正则系数 'metric': 'auc', 'opt': 'adagrad', # sgd,ftlr。如果采用ftlr,则还可以指定其他参数alpha, beta, lambda_1, lambda_2 'k':16, # 隐因子个数。FFM中的k可以比FM中的k小很多 'init': 0.5, # 初始化参数 'epoch': 50, 'stop_window': 5, # 连续5轮指标没有创建新高就停止迭代 } # 不用设置核数,会自动把所有核都利用起来 # ffm_model.disableLockFree() # ffm_model.setQuiet()#迭代时不做evaluation # ffm_model.setOnDisk()#内存容不下所有训练数据时,数据存到磁盘,每次只加载一个block的数据,在params中可以设置block_size ffm_model.setTXTModel(model_explain_file) ffm_model.fit(params, ffm_model_file)
LR、FM、FFM这3个算法对学习率都比较敏感,需要扩大搜索范围多尝试一些学习率。k从4增加到32的过程中AUC是递增的,另外FFM的k值可以比FM小很多。
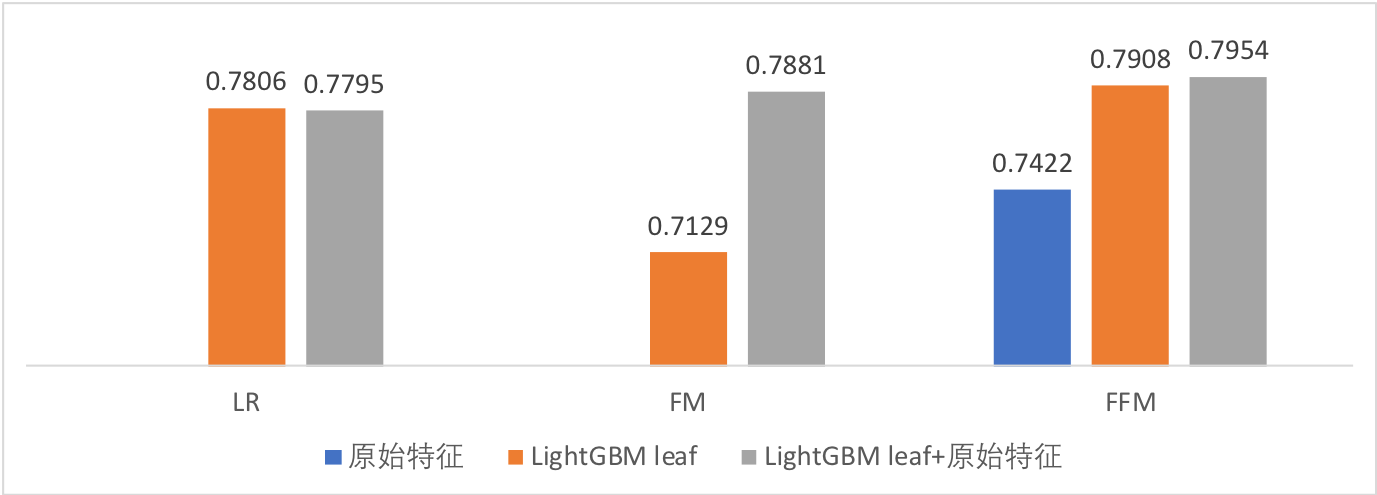
- LightGBM+LR/FM/FFM都没有超越单纯的LightGBM
- 除了LightGBM组合特征外,把原始特征也加进来对FM的提升比较明显,对LR和FFM无提升
- 从FFM可以看到,使用LightGBM组合特征比只使用原始特征有很大的效果提升
本文来自博客园,作者:张朝阳讲go语言,转载请注明原文链接:https://www.cnblogs.com/zhangchaoyang/articles/9239742.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号