RNN和LSTM
RNN
中文分词、词性标注、命名实体识别、机器翻译、语音识别都属于序列挖掘的范畴。序列挖掘的特点就是某一步的输出不仅依赖于这一步的输入,还依赖于其他步的输入或输出。在序列挖掘领域传统的机器学习方法有HMM(Hidden Markov Model,隐马尔可夫模型)和CRF(Conditional Random Field,条件随机场),近年来又开始流行深度学习算法RNN(Recurrent Neural Networks,循环神经网络)。
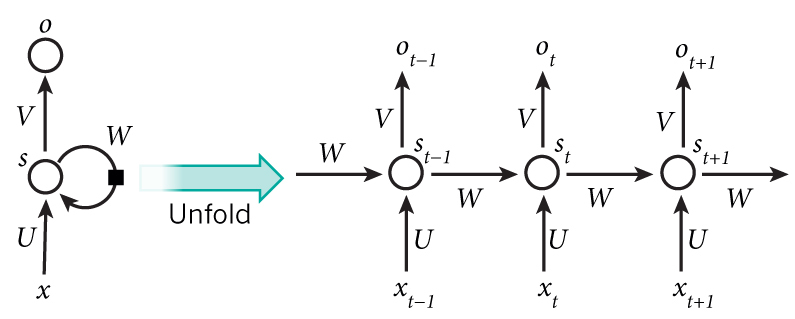
图1 RNN网络结构
比如一个句子中有5个词,要给这5个词标注词性,那相应的RNN就是个5层的神经网络,每一层的输入是一个词,每一层的输出是这个词的词性。
- $x_t$是第t层的输入,它可以是一个词的one-hot向量,也可以是Distributed Representation向量。
- $s_t$是第t层的隐藏状态,它负责整个神经网络的记忆功能。$s_t$由上一层的隐藏状态和本层的输入共同决定,$s_t=f(Ux_t+Ws_{t-1})$,$f$通常是个非线性的激活函数,比如tanh或ReLU。由于每一层的$s_t$都会向后一直传递,所以理论上$s_t$能够捕获到前面每一层发生的事情(但实际中太长的依赖很难训练)。
- $o_t$是第t层的输出,比如我们预测下一个词是什么时,$o_t$就是一个长度为$V$的向量,$V$是所有词的总数,$o_{t}[i]$表示下一个词是$w_i$的概率。我们用softmax函数对这些概率进行归一化。$o_t=softmax(Vs_t)$。
- 值得一提的是,每一层的参数$U, W, V$都是共享的,这样极大地缩小了参数空间。
- 每一层并不一定都得有输入和输出,隐藏单元才是RNN的必备武器。比如对句子进行情感分析时只需要最后一层给一个输出即可。
RNN采用传统的backpropagation+梯度下降法对参数进行学习,第$t$层的误差函数跟第$o_t$直接相关,而$o_t$依赖于前面每一层的$x_i$和$s_i$,$i \le t$,这就是所谓的Backpropagation Through Time (BPTT)。在《神经网络调优》中我已讲到过这种深层神经网络容易出现梯度消失或梯度爆炸的问题,为了避免网络太“深”,有些人对RNN进行改造,避免太长的依赖,即$o_t$只依赖于$\{x_i, s_i\}$,其中$t-n \le i \le t$。LSTM也属于一种改良的RNN,但它不是强行把依赖链截断,而是采用了一种更巧妙的设计来绕开了梯度消失或梯度爆炸的问题,下文会详细讲解LSTM。
RNN的变体
双向RNN
双向RNN认为$o_t$不仅依赖于序列之前的元素,也跟$t$之后的元素有关,这在序列挖掘中也是很常见的事实。

图2 Bidirectional RNNs网络结构
深层双向RNN
在双向RNN的基础上,每一步由原来的一个隐藏层变成了多个隐藏层。
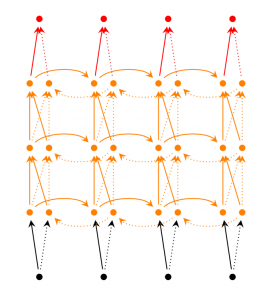
图3 Deep Bidirectional RNNs网络结构
LSTM
前文提到,由于梯度消失/梯度爆炸的问题传统RNN在实际中很难处理长期依赖,而LSTM(Long Short Term Memory)则绕开了这些问题依然可以从语料中学习到长期依赖关系。比如“I grew up in France... I speak fluent (French)”要预测()中应该填哪个词时,跟很久之前的"France"有密切关系。
传统RNN每一步的隐藏单元只是执行一个简单的tanh或ReLU操作。

图4 传统RNN每个模块内只是一个简单的tanh层
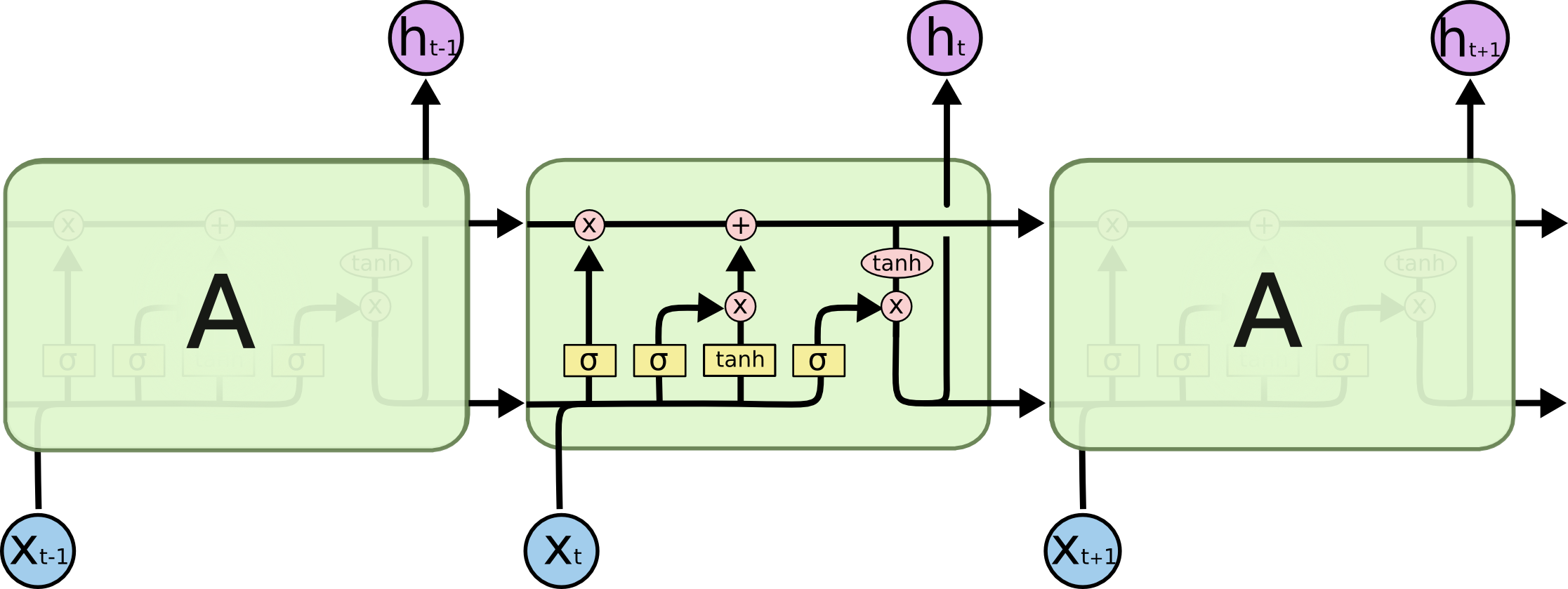
图5 LSTM每个循环的模块内又有4层结构:3个sigmoid层,1个tanh层
LSTM每个模块的4层结构后文会详细说明,先来解释一下基本的图标。

图6 图标说明
粉色的圆圈表示一个二目运算。两个箭头汇合成一个箭头表示2个向量首尾相连拼接在一起。一个箭头分叉成2个箭头表示一个数据被复制成2份,分发到不同的地方去。
LSTM内部结构详解
LSTM的关键是细胞状态$C$,一条水平线贯穿于图形的上方,这条线上只有些少量的线性操作,信息在上面流传很容易保持。
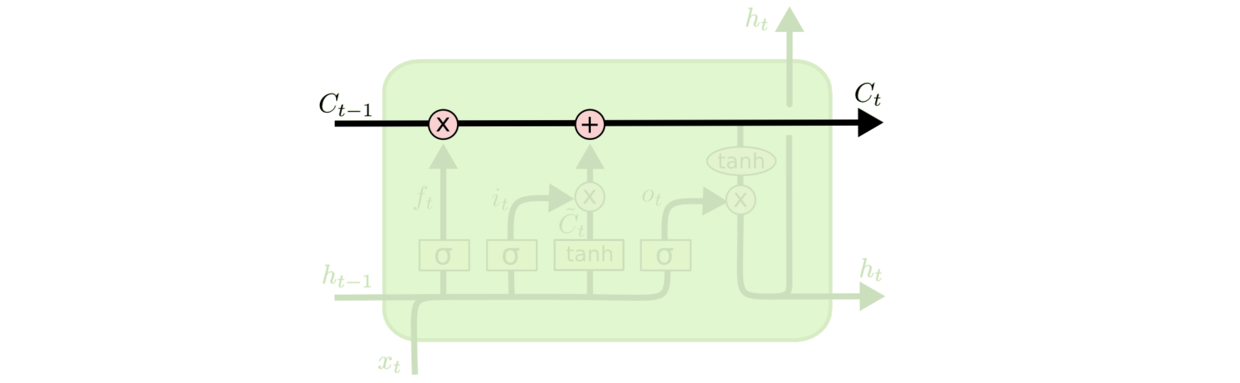
图7 细胞状态的传送带
第一层是个忘记层,决定细胞状态中丢弃什么信息。把$h_{t-1}$和$x_t$拼接起来,传给一个sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态$C_{t-1}$上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
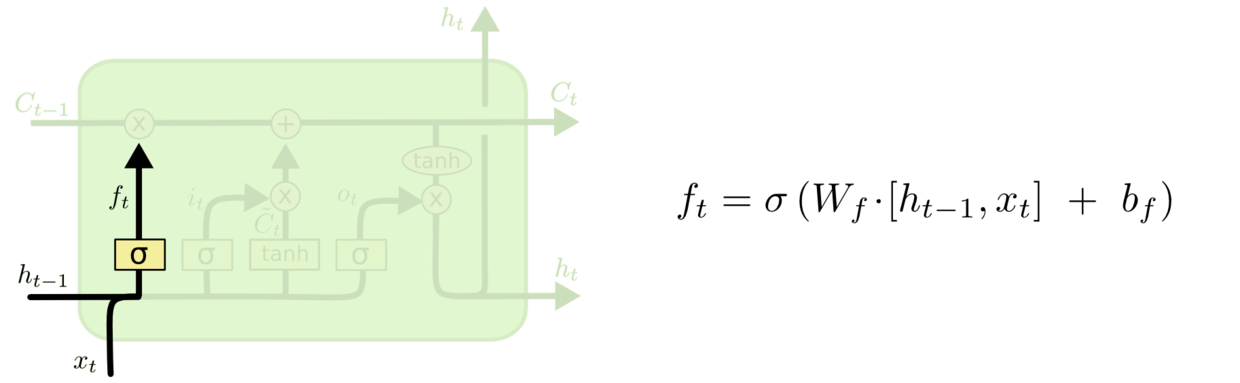
图8 细胞状态忘记一部分,保留一部分
上一步的细胞状态$C_{t-1}$已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?这里又包含2层:一个tanh层用来产生更新值的候选项$\tilde{C}_t$,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
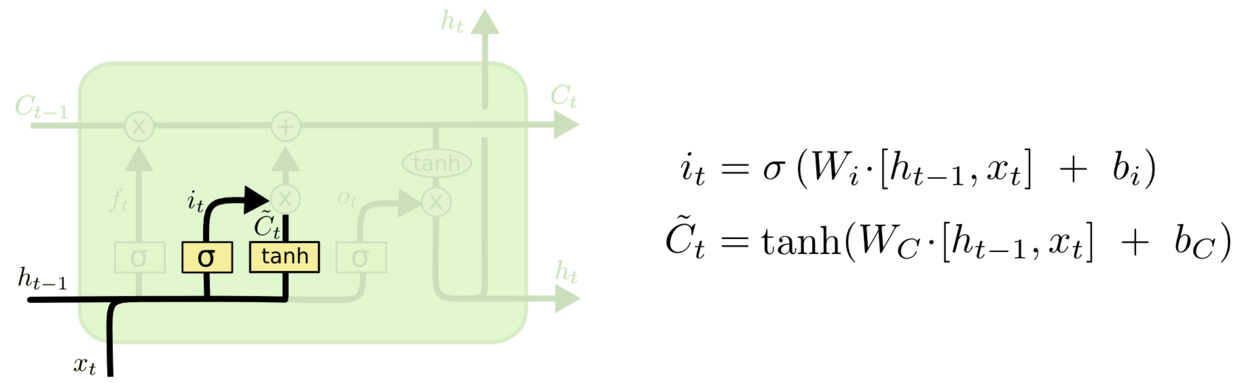
图9 更新细胞状态
现在可以让旧的细胞状态$C_{t-1}$与$f_t$(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分$i_t * \tilde{C}_t$(i是input输入门的意思),这就生成了新的细胞状态$C_t$。

图10 生成新的细胞状态
最后该决定输出什么了。输出值跟细胞状态有关,把$C_t$输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
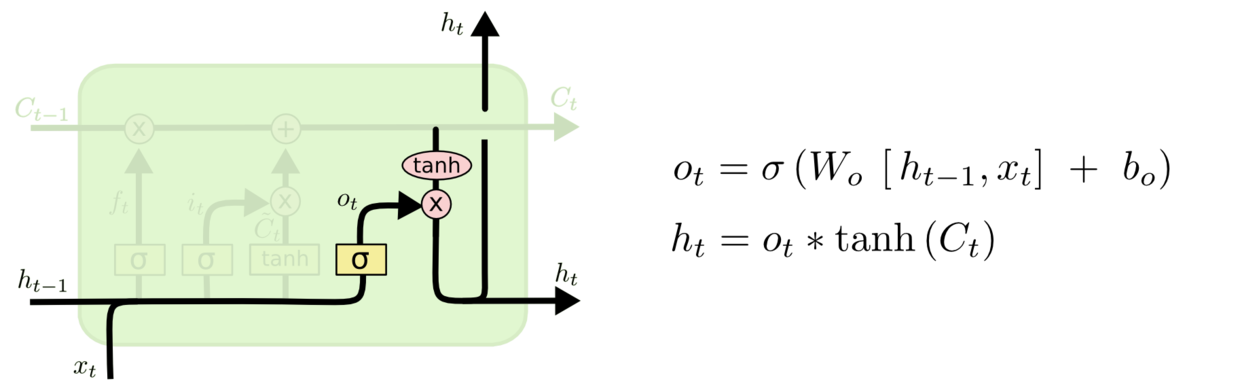
图11 循环模块的输出
LSTM实现
参数更新方法 http://nicodjimenez.github.io/2014/08/08/lstm.html。核心是实现了$\frac{dL(t)}{dh(t)}$和$\frac{dL(t+1)}{ds(t)}$反向递归计算。
对应的代码实现 https://github.com/nicodjimenez/lstm。总共不到200行代码。
GRU
GRU(Gated Recurrent Unit)是LSTM最流行的一个变体,比LSTM模型要简单。

图12 GRU
本文来自博客园,作者:张朝阳讲go语言,转载请注明原文链接:https://www.cnblogs.com/zhangchaoyang/articles/6684906.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号