

TCP/IP协议栈在Linux内核中的运行时序分析
TCP/IP协议栈在Linux系统的运行时序分析
姓名:张超衡
学号:SA20225583
1、调研要求
2、Linux操作系统
2.1 Linux操作系统介绍
2.2协议栈简介
2.3Linux内核协议
3、测试与分析
3.1 测试用代码展示
3.2 send和recv过程分析
3.3 send和recv函数介绍
4、网络接口收发数据
4.1 发送网络数据
4.2 接收网络数据
5、数据链路层
5.1 数据帧的接收处理
5.1.1 NAPI的实现
5.1.2 netif_rx的实现
5.2 数据帧的发送处理
6、网络层
6.1 输入数据包在IP层的处理
6.2 发送数据包在IP层的处理
6.2.1 数据包的前送(发送至下一主机)
6.2.2 数据包上传本地主机
7、传输层
7.1 传输层的接收过程的实现
7.2 传输层发送数据流程
8、套接字接口层
8.1 套接字API系统调用的实现
8.1.1 socketcall系统调用
8.1.2 sys_socketcall 套接字分路器
8.1.3 sys_sendto,sys_recvfrom,sys_socket调用流程
9、时序图总结
1、调研要求
1.在深入理解Linux内核任务调度(中断处理、softirg、tasklet、wq、内核线程等)机制的基础上,分析梳理send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析。
2.编译、部署、运行、测评、原理、源代码分析、跟踪调试等。
3.应该包括时序图。
2、Linux操作系统
2.1 Linux操作系统介绍
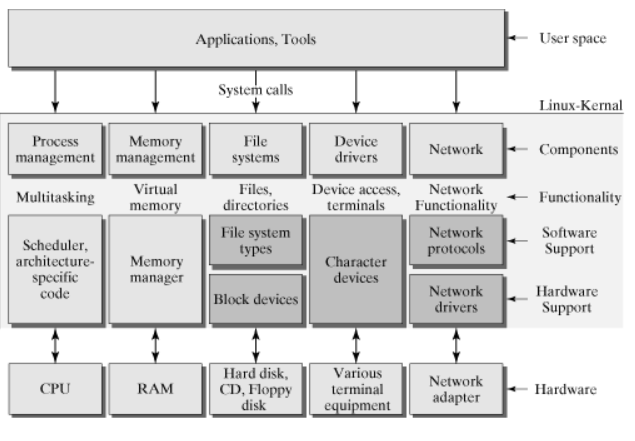
Linux操作系统总体上由Linux内核和GNU系统构成,具体来讲由4个主要部分构成,即Linux内核、Shell、文件系统和应用程序。内核、Shell和文件系统构成了操作系统的基本结构,使得用户可以运行程序、管理文件并使用系统。
内核是操作系统的核心,具有很多最基本功能,如虚拟内存、多任务、共享库、需求加载、可执行程序和TCP/IP网络功能。
2.2协议栈简介
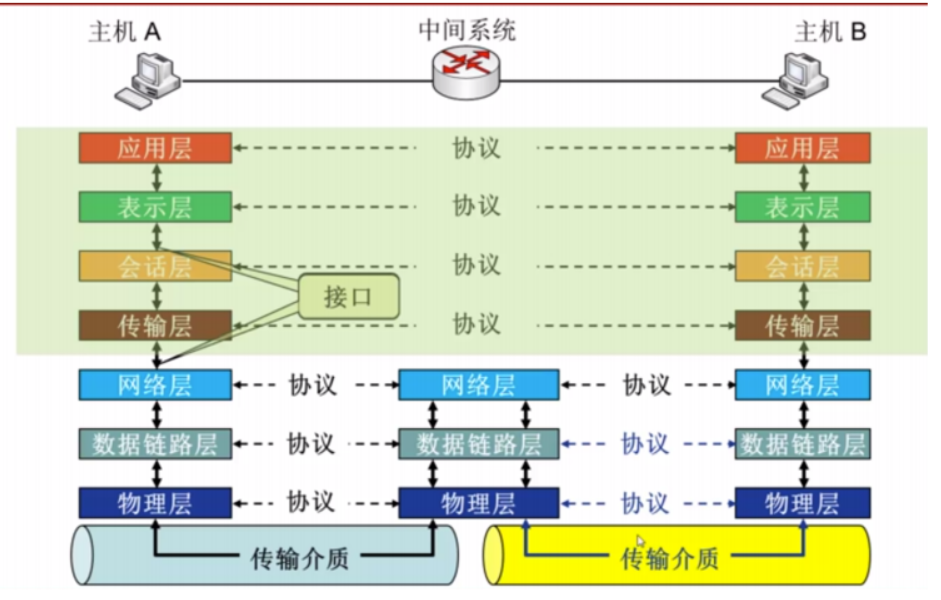
计算机网络分层模型有OSI七层模型和TCP/IP分层模型,
OSI从逻辑上,把一个网络系统分为功能上相对独立的7个有序的子系统,这样OSI体系结构就由功能上相对独立的7个层次组成,如图所示。它们由低到高分别是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。
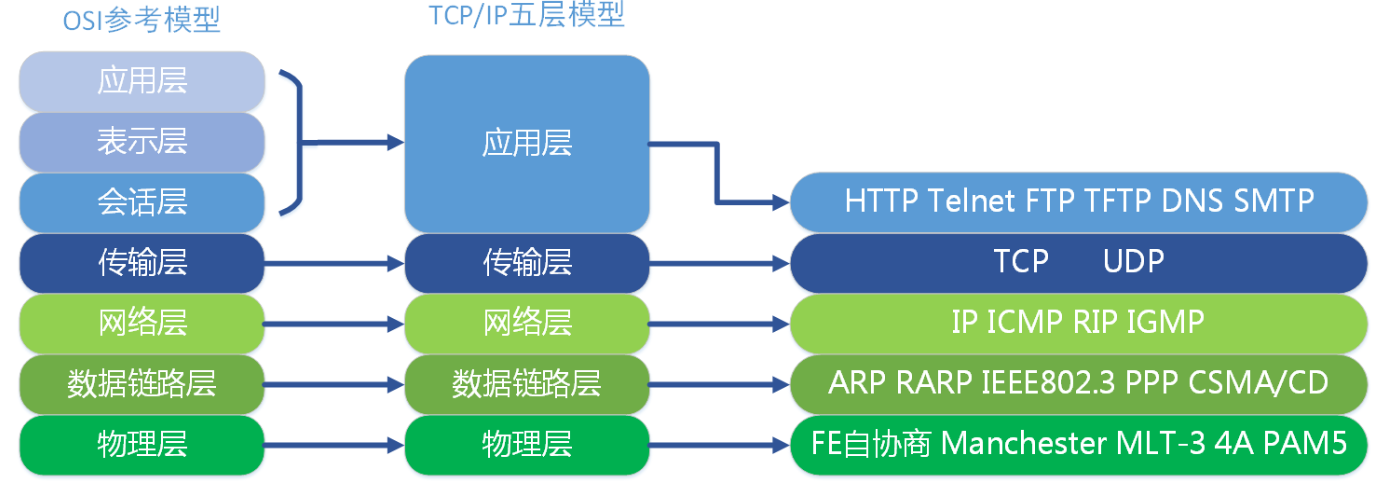
Linux内核采用的TCP/IP分层模型来设计网络结构,其结构如图所示:
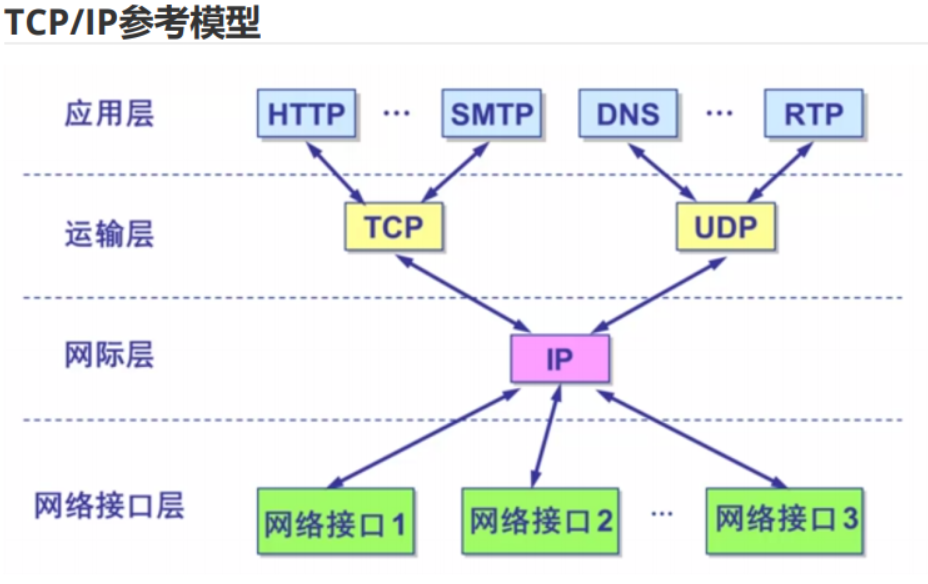
2.3Linux内核协议
Linux的协议栈其实是源于BSD的协议栈,它向上以及向下的接口以及协议栈本身的软件分层组织的非常好。
Linux的协议栈基于分层的设计思想,总共分为四层,从下往上依次是:物理层,链路层,网络层,应用层。
物理层主要提供各种连接的物理设备,如各种网卡,串口卡等;链路层主要指的是提供对物理层进行访问的各种接口卡的驱动程序,如网卡驱动等;网路层的作用是负责将网络数据包传输到正确的位置,最重要的网络层协议当然就是IP协议了,其实网络层还有其他的协议如ICMP,ARP,RARP等,只不过不像IP那样被多数人所熟悉;传输层的作用主要是提供端到端,说白一点就是提供应用程序之间的通信,传输层最著名的协议非TCP与UDP协议末属了;应用层,顾名思义,当然就是由应用程序提供的,用来对传输数据进行语义解释的“人机界面”层了,比如HTTP,SMTP,FTP等等,其实应用层还不是人们最终所看到的那一层,最上面的一层应该是“解释层”,负责将数据以各种不同的表项形式最终呈献到人们眼前。
Linux网络核心架构Linux的网络架构从上往下可以分为三层,分别是:
用户空间的应用层。
内核空间的网络协议栈层。
物理硬件层。
其中最重要最核心的当然是内核空间的协议栈层了。
Linux网络协议栈结构Linux的整个网络协议栈都构建与Linux Kernel中,整个栈也是严格按照分层的思想来设计的,整个栈共分为五层,分别是 :
1,系统调用接口层,实质是一个面向用户空间应用程序的接口调用库,向用户空间应用程序提供使用网络服务的接口。
asmlingkage long sys_getpid(void)
{return current->pid;}
2,协议无关的接口层,就是SOCKET层,这一层的目的是屏蔽底层的不同协议(更准确的来说主要是TCP与UDP,当然还包括RAW IP, SCTP等),以便与系统调用层之间的接口可以简单,统一。简单的说,不管我们应用层使用什么协议,都要通过系统调用接口来建立一个SOCKET,这个SOCKET其实是一个巨大的sock结构,它和下面一层的网络协议层联系起来,屏蔽了不同的网络协议的不同,只吧数据部分呈献给应用层(通过系统调用接口来呈献)。
3,网络协议实现层,毫无疑问,这是整个协议栈的核心。这一层主要实现各种网络协议,最主要的当然是IP,ICMP,ARP,RARP,TCP,UDP等。
在<linux/socket.h>中查到所支持的网络协议:
#define AF_UNIX 1 /* Unix domain sockets */ #define AF_LOCAL 1 /* POSIX name for AF_UNIX */ #define AF_INET 2 /* Internet IP Protocol */ #define AF_AX25 3 /* Amateur Radio AX.25 */ #define AF_IPX 4 /* Novell IPX
其中每一个所支持的协议对应net_family[]数组中的一项,net_family[]是结构体指针数组,其中的每一项都是一个结构体指针,指向一个net_proto_family 结构:
struct net_proto_family {
int family;
int (*create) (struct socket * sock, int protocol);
short authentication;
short encryption;
short encrypt_net;
struct module *owner;
}
4,与具体设备无关的驱动接口层,这一层的目的主要是为了统一不同的接口卡的驱动程序与网络协议层的接口,它将各种不同的驱动程序的功能统一抽象为几个特殊的动作,如open,close,init等,这一层可以屏蔽底层不同的驱动程序。
5,驱动程序层建立与硬件的接口层。
网络栈底部是负责管理物理网络设备的设备驱动程序。例如,包串口使用的 SLIP 驱动程序以及以太网设备使用的以太网驱动程序都是这一层的设备。
在进行初始化时,设备驱动程序会分配一个 net_device 结构,然后使用必须的程序对其进行初始化。这些程序中有一个是 dev->hard_start_xmit ,它定义了上层应该如何对 sk_buff 排队进行传输。这个程序的参数为 sk_buff 。这个函数的操作取决于底层硬件,但是通常 sk_buff 所描述的报文都会被移动到硬件环或队列中。就像是设备无关层中所描述的一样,对于 NAPI 兼容的网络驱动程序来说,帧的接收使用了 netif_rx 和 netif_receive_skb 接口。NAPI 驱动程序会对底层硬件的能力进行一些限制。
可以看到,Linux网络协议栈是一个严格分层的结构,其中的每一层都执行相对独立的功能,结构非常清晰。

3、测试与分析
3.1 测试用代码展示
采用的测试代码是一个简单基于socket的客户端服务器程序,打开服务端并运行,再开一终端运行客户端,两者建立连接并可以发送hello\hi的信息。
client.c代码演示:
#include <stdio.h> /* perror */
#include <stdlib.h> /* exit */
#include <sys/types.h> /* WNOHANG */
#include <sys/wait.h> /* waitpid */
#include <string.h> /* memset */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <netdb.h> /* gethostbyname */
#define true 1
#define false 0
#define PORT 3490 /* Server的端口 */
#define MAXDATASIZE 100 /* 一次可以读的最大字节数 */
int main(int argc, char *argv[])
{
int sockfd, numbytes;
char buf[MAXDATASIZE];
struct hostent *he; /* 主机信息 */
struct sockaddr_in server_addr; /* 对方地址信息 */
if (argc != 2)
{
fprintf(stderr, "usage: client hostname\n");
exit(1);
}
/* get the host info */
if ((he = gethostbyname(argv[1])) == NULL)
{
/* 注意:获取DNS信息时,显示出错需要用herror而不是perror */
/* herror 在新的版本中会出现警告,已经建议不要使用了 */
perror("gethostbyname");
exit(1);
}
if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT); /* short, NBO */
server_addr.sin_addr = *((struct in_addr *)he->h_addr_list[0]);
memset(&(server_addr.sin_zero), 0, 8); /* 其余部分设成0 */
if (connect(sockfd, (struct sockaddr *)&server_addr,
sizeof(struct sockaddr)) == -1)
{
perror("connect");
exit(1);
}
if ((numbytes = recv(sockfd, buf, MAXDATASIZE, 0)) == -1)
{
perror("recv");
exit(1);
}
buf[numbytes] = '\0';
printf("Received: %s", buf);
close(sockfd);
return true;
}
sever.c代码演示:
#include <stdio.h> /* perror */
#include <stdlib.h> /* exit */
#include <sys/types.h> /* WNOHANG */
#include <sys/wait.h> /* waitpid */
#include <string.h> /* memset */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <netdb.h> /* gethostbyname */
#define true 1
#define false 0
#define MYPORT 3490 /* 监听的端口 */
#define BACKLOG 10 /* listen的请求接收队列长度 */
int main()
{
int sockfd, new_fd; /* 监听端口,数据端口 */
struct sockaddr_in sa; /* 自身的地址信息 */
struct sockaddr_in their_addr; /* 连接对方的地址信息 */
unsigned int sin_size;
if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket");
exit(1);
}
sa.sin_family = AF_INET;
sa.sin_port = htons(MYPORT); /* 网络字节顺序 */
sa.sin_addr.s_addr = INADDR_ANY; /* 自动填本机IP */
memset(&(sa.sin_zero), 0, 8); /* 其余部分置0 */
if (bind(sockfd, (struct sockaddr *)&sa, sizeof(sa)) == -1)
{
perror("bind");
exit(1);
}
if (listen(sockfd, BACKLOG) == -1)
{
perror("listen");
exit(1);
}
/* 主循环 */
while (1)
{
sin_size = sizeof(struct sockaddr_in);
new_fd = accept(sockfd,
(struct sockaddr *)&their_addr, &sin_size);
if (new_fd == -1)
{
perror("accept");
continue;
}
printf("Got connection from %s\n",
inet_ntoa(their_addr.sin_addr));
if (fork() == 0)
{
/* 子进程 */
if (send(new_fd, "Hello, world!\n", 14, 0) == -1)
perror("send");
close(new_fd);
exit(0);
}
close(new_fd);
/*清除所有子进程 */
while (waitpid(-1, NULL, WNOHANG) > 0)
;
}
close(sockfd);
return true;
}
两者之间交互过程如下:
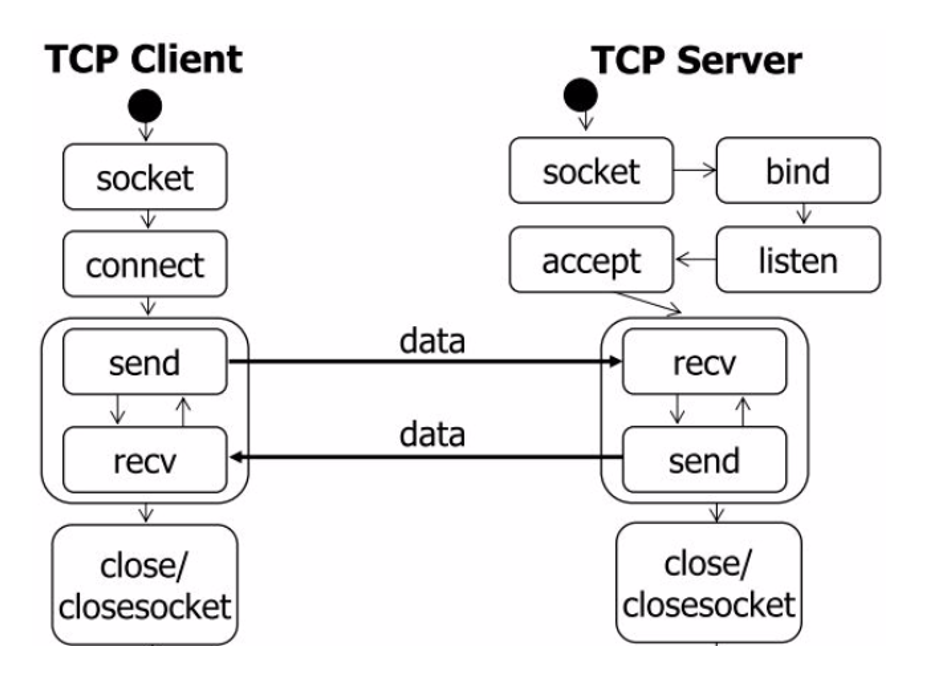
3.2 send和recv过程分析

3.3 send和recv函数介绍
函数原型:
ssize_t send(int sockfd, const void *buff, size_t nbytes, int flags);
ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags);
- send解析
sockfd:指定发送端套接字描述符。
buff: 存放要发送数据的缓冲区
nbytes: 实际要改善的数据的字节数
flags: 一般设置为0
-
send先比较发送数据的长度nbytes和套接字sockfd的发送缓冲区的长度,如果nbytes > 套接字sockfd的发送缓冲区的长度, 该函数返回SOCKET_ERROR;
-
如果nbtyes <= 套接字sockfd的发送缓冲区的长度,那么send先检查协议是否正在发送sockfd的发送缓冲区中的数据,如果是就等待协议把数据发送完,如果协议还没有开始发送sockfd的发送缓冲区中的数据或者sockfd的发送缓冲区中没有数据,那么send就比较sockfd的发送缓冲区的剩余空间和nbytes
-
如果 nbytes > 套接字sockfd的发送缓冲区剩余空间的长度,send就一起等待协议把套接字sockfd的发送缓冲区中的数据发送完
-
如果 nbytes < 套接字sockfd的发送缓冲区剩余空间大小,send就仅仅把buf中的数据copy到剩余空间里(注意并不是send把套接字sockfd的发送缓冲区中的数据传到连接的另一端的,而是协议传送的,send仅仅是把buf中的数据copy到套接字sockfd的发送缓冲区的剩余空间里)。
-
如果send函数copy成功,就返回实际copy的字节数,如果send在copy数据时出现错误,那么send就返回SOCKET_ERROR; 如果在等待协议传送数据时网络断开,send函数也返回SOCKET_ERROR。
-
send函数把buff中的数据成功copy到sockfd的改善缓冲区的剩余空间后它就返回了,但是此时这些数据并不一定马上被传到连接的另一端。如果协议在后续的传送过程中出现网络错误的话,那么下一个socket函数就会返回SOCKET_ERROR。(每一个除send的socket函数在执行的最开始总要先等待套接字的发送缓冲区中的数据被协议传递完毕才能继续,如果在等待时出现网络错误那么该socket函数就返回SOCKET_ERROR)
-
在unix系统下,如果send在等待协议传送数据时网络断开,调用send的进程会接收到一个SIGPIPE信号,进程对该信号的处理是进程终止。
- recv函数
sockfd: 接收端套接字描述符
buff: 用来存放recv函数接收到的数据的缓冲区
nbytes: 指明buff的长度
flags: 一般置为0
-
recv先等待s的发送缓冲区的数据被协议传送完毕,如果协议在传送sock的发送缓冲区中的数据时出现网络错误,那么recv函数返回SOCKET_ERROR
-
如果套接字sockfd的发送缓冲区中没有数据或者数据被协议成功发送完毕后,recv先检查套接字sockfd的接收缓冲区,如果sockfd的接收缓冲区中没有数据或者协议正在接收数据,那么recv就一起等待,直到把数据接收完毕。当协议把数据接收完毕,recv函数就把s的接收缓冲区中的数据copy到buff中(注意协议接收到的数据可能大于buff的长度,所以在这种情况下要调用几次recv函数才能把sockfd的接收缓冲区中的数据copy完。recv函数仅仅是copy数据,真正的接收数据是协议来完成的)
-
recv函数返回其实际copy的字节数,如果recv在copy时出错,那么它返回SOCKET_ERROR。如果recv函数在等待协议接收数据时网络中断了,那么它返回0。
-
在unix系统下,如果recv函数在等待协议接收数据时网络断开了,那么调用 recv的进程会接收到一个SIGPIPE信号,进程对该信号的默认处理是进程终止。
![]()

4、网络接口收发数据
网络接口最主要的任务是数据收发,数据发送相对于数据接收要简单一些,我们先介绍数据包是如何由内核向网络发送的。
4.1 发送网络数据
发送数据是将数据包通过网络连接线路送出。无论什么时候,内核准备好要发送的数据包后(数据包存放在Socket Buffer 中),都会调用驱动程序的ndo_start_xmit函数把数据包放到网络设备的硬件数据缓冲区,并启动硬件发送。ndo_start_xmit是一个函数指针,指向驱动程序实现的数据发送函数。传给ndo_start_xmit的 Socket Buffer 包含了实际要传输的物理数据、协议栈的协议头;接口无须关心数据包的具体内容,也无须修改数据包的值。struct sk_buff 中skb->data给出了要发送数据的起始地址。
如果ndo_start_xmit执行成功则返回0,这时负责发送该数据的驱动程序应尽最大努力保证数据包的发送成功,最后释放存放发送完成数据包的Socket Buffer。如果ndo_start_xmit返回值非0,则说明这次发送不成功,内核过一段时间后会重发。这时驱动程序应停止发送队列,直到发送失败错误恢复。
当CPU需要发送数据给网络设备时,CPU将数据写到IO端口,并向网络设备的命令寄存器写发送控制命令;相反,当网络设备需要发送数据给CPU时,它产生一个中断,CPU执行中断处理程序来为网络设备服务。
4.2 接收网络数据
与发送数据包相反,接收数据包是内核事先无法预见的事件。网络设备接收数据包的过程与内核的操作是并行的,网络设备驱动程序把数据包推送给内核,有两种方式通知内核数据到达。
轮询,即内核周期性地查询网络设备。这种方式的问题是内核需要多长时间询问网络设备一次。如果间隔太短,会无谓地浪费CPU时间;如果间隔太长,数据发送的延迟会增加,可能会丢失数据。
中断,即内核执行中断处理程序接收数据包,将其存放在CPU的接收队列中,其后的处理可以等CPU空闲时再完成。net_rx是在接收中断中调用的处理接收数据的函数。
net_rx 的任务是申请一个Socket Buffer,将硬件数据复制到Socket Buffer中,再将接收设备注册到Socket Buffer的dev数据域,识别数据包的协议类型。接着由netif_rx()函数将接收到的数据包放入CPU的接收队列,更新接收统计信息,这时接收处理程序继续接收下一个数据包,或者结束返回。
5、数据链路层
在TCP/IP协议栈中,数据链路层的关键任务是:将由网络设备驱动程序从设备硬件缓冲区复制到内核地址空间的网络数据帧挂到CPU的输入队列,并通知上层协议有网络数据帧到达,随后上层协议就可以从CPU的输入队列中获取网络数据帧并处理。
另外,上层协议实例要向外发送的数据帧会由数据链路层放到设备输出队列,再由设备驱动程序的硬件发送函数 hard_start_xmit将设备输出队列中的数据帧复制到设备硬件缓冲区,实现对外发送。
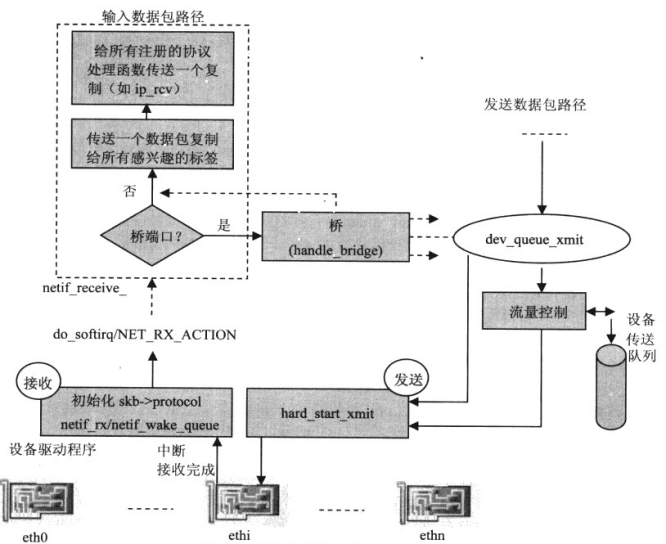
5.1 数据帧的接收处理
网络设备收到的数据帧由网络设备驱动程序推送到内核地址空间后,在数据链路层中,Linux内核网络子系统实现了两种机制,将数据帧放入CPU的输入队列中。
1、netif_rx
这是目前大多数网络设备驱动程序将数据帧复制到Socket Buffer 后,调用的数据链路层方法。它通知内核接收到了网络数据帧;标记网络接收软件中断,执行接收数据帧的后续处理。这种机制每接收一个数据帧会产生一个接收中断。
2、NAPI
这是内核实现的新接口,在一次中断中可以接收多个网络数据帧,减少了CPU响应中断请求进行中断服务程序与现行程序之间切换所花费的时间。
5.1.1 NAPI的实现
NAPI的核心概念是使用中断与轮询相结合的方式来代替纯中断模式:当网络设备从网络上收到数据帧后,向CPU 发出中断请求,内核执行设备驱动程序的中断服务程序接收数据帧;在内核处理完前面收到的数据帧前,如果设备又收到新的数据帧,这时设备不需产生新的中断(设备中断为关闭状态),内核继续读入设备输入缓冲区中的数据帧(通过调用驱动程序的poll函数来完成),直到设备输入缓冲区为空,再重新打开设备中断。这样设备驱动程序同时具有了中断与轮询两种工作模式的优点。
异步事件通知:当有数据帧到达时用中断通知内核,内核无须不断查询设备的状态。
如果设备队列中仍有数据,无须浪费时间处理中断通知、程序切换等。
使用NAPI工作模式需要对网络驱动程序做以下的升级:
(1)新增新的数据结构struct napi_struct;
该实例描述了与NAPI相关的属性与操作。
(2)实现poll 函数;
设备驱动程序要实现自己的poll 函数,来轮询自己的设备,将网络输入数据帧复制到内核地址空间的Socket Buffer,再放入CPU 输入队列。
(3)对接收中断处理程序进行修改;
执行中断处理程序后,不是调用netif_rx函数将Socket Buffer放入CPU 输入队列,而是调用netif_rx_schedule函数。
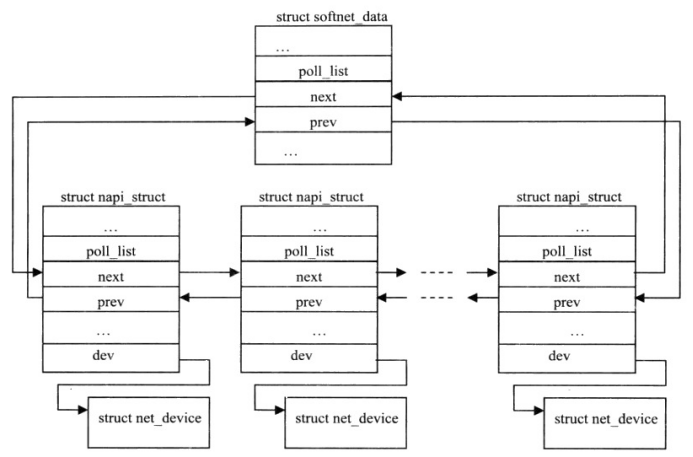
其中struct softnet_data是管理CPU队列的数据结构。
NAPI接收机制的工作流程如下:

5.1.2 netif_rx的实现
netif_rx函数由常规网络设备驱动程序在接收中断中调用,它的任务就是把输入数据帧放入CPU的输入队列中,随后标记软件中断来处理后续上传数据帧给TCP/IP协议栈功能。
netif_rx的函数调用流程如下:
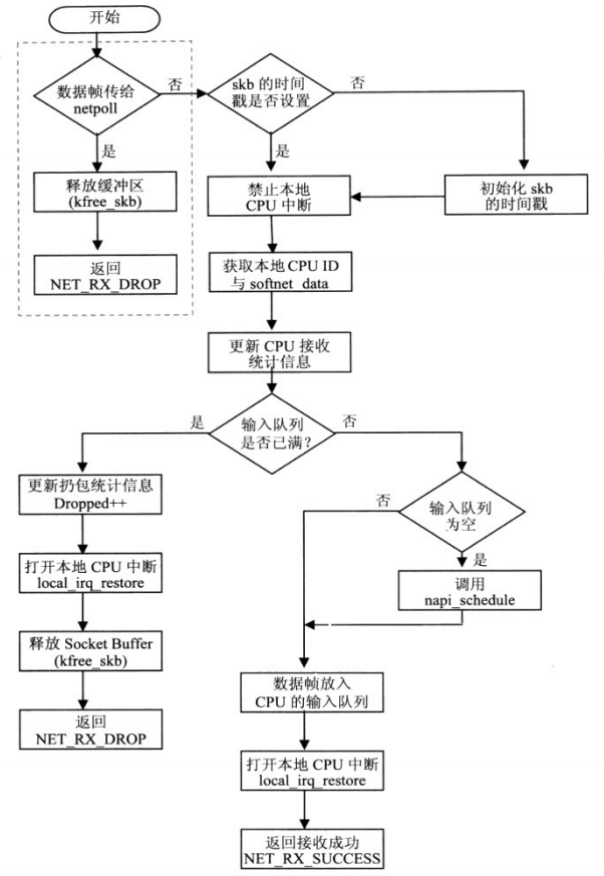
netif_rx调用函数栈
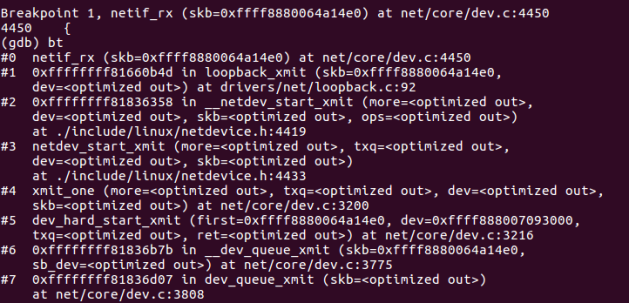
napi_schedule函数是_napi_schedule函数的包装函数,_napi_schedule完成的功能就是将struct napi_struct 数据结构实例放入CPU的poll_list队列,挂起网络接收软件中断NET_RX_SOFTIRQ。这样推送数据帧给上层协议实例的处理函数,就会在内核调度的网络接收软件中断处理程序的net_rx _action函数中被执行。
网络接收软件中断(NET_RX_SOFTIRQ)的处理程序net_rx_action是接收网络数据中断的后半段。引起net_rx _action函数执行的是网络设备产生的接收数据硬件中断,它通知内核收到了网络数据帧,触发内核调度接收中断的后半段。net_rx_action函数的任务就是将设备收到的数据帧上传给TCP/IP 协议栈的上层协议处理。
5.2 数据帧的发送处理
在数据帧的处理过程中,发送和接收的许多步骤都有对称性。大部分数据结构、处理函数与前面讨论的接收过程的数据结构和处理函数都是成对出现,只是其处理过程相反。例如接收软件中断是 NET_RX_SOFTIRQ,相对应的发送数据有软件中断NET_TX_SOFTIRQ;它们的软件中断处理程序分别是net_rx_action和 net_tx_action。
相较于接收过程,可预期的发送过程更为简单,主要流程如下:
(1)启动设备发送数据
Linux设置了一系列的API来操纵检查网络发送队列的状态,常用如下:netif_start_queue/netif_stop_queue(启动/禁止网络发送队列),netif_queue_stopped(返回网络队列当前发送状态),netif_wake_queue(唤醒网络发送队列,重启网络发送过程)。
(2)调度设备发送数据帧
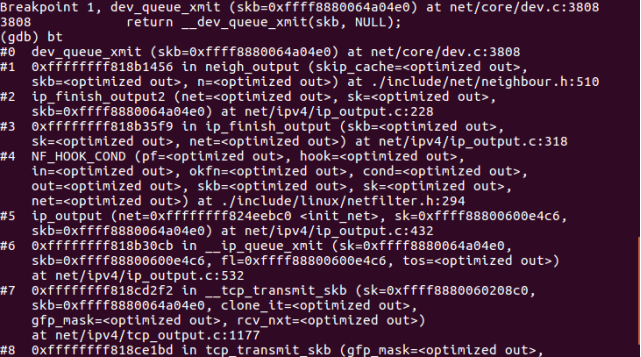
内核实现了dev_queue_xmit函数,该函数将上层协议发送来的数据帧放到网络设备的发送队列(针对有发送队列的网络设备),随后流量控制系统按照内核配置的队列管理策略,将网络设备发送队列中的数据帧依次发送出去。发送时,从网络设备的输出队列上获取一个数据帧,将数据帧发送给设备驱动程序的dev->netdev_ops->ndo_start_xmit方法。
如果获取保护输出队列并发访问的锁失败,内核实现了函数_netif_schedule来重新调度网络设备发送数据帧,它将网络设备放到CPU的发送队列softnet_data->output_queue 上,随后标识网络发送软件中断NET_TX_SOFTIRQ,当发送软件中断被内核调度执行时,CPU输出队列output queue 中的设备会重新被调度来发送数据帧。(其作用就类似netif_rx_schedule函数处理输入路径的功能)。
dev_queue_xmit函数调用栈
6、网络层
网络层协议是TCP/IP协议栈与网络设备驱动程序所管理的硬件发送的连接处,网络数据包经过网络层的处理后,已包含了所有向外发送需要的信息,如源地址、目标地址、协议头等,可交由网络设备发送。另一方面,接收到的网络数据包在网络层确定其进一步发送的路径,是在本机向上传递,还是继续向前发送。数据链路层的驱动程序只关心将上层交给的数据包向外发送,将接到的数据包向上投递,而网络层协议的关键任务就是决定数据包的去向。
在linux中相应的协议处理函数都会分两个阶段实现。
第一阶段函数名通常为do_something (如 ip_rcv),do_something 函数只对数据包做必要的合法性检查,或为数据包预留需要的内存空间。
第二阶段函数名通常为do_something_finish(如 ip_rcv_finish),是实际完成接收/发这操作的函数。
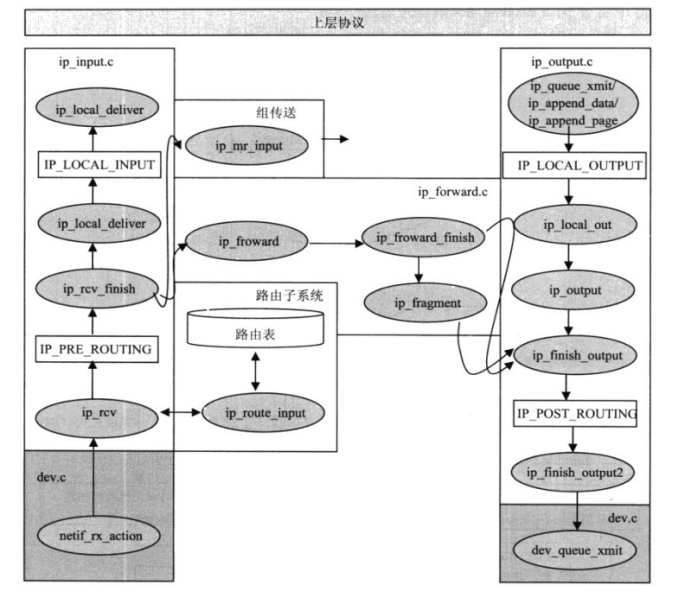
6.1 输入数据包在IP层的处理
Linux内核定义了ptype_base链表来实现数据链路层与网络层之间接收数据包的接口,网络层各协议将自己的接收数据包处理函数注册到ptype_base链表中,数据链路层按接收数据包的skb->protocol值在ptype_base链表中找到匹配的协议实例,将数据包传给注册的处理函数。IP协议在PF_INET协议族初始化函数inet_init中调用dev_add _pack注册的处理函数是ip_rcv。 ip_rcv函数是网络层IP协议处理输入数据包的入口函数,IP协议通过ip_rcv、ip_rcv_finish等函数,完成IP层对输入数据包的处理。
1、ip_rcv函数
Ip_rcv函数主要都是在对skb 中的数据包做各种合法性检查:协议头长度、协议版本、数据包长度、校验和等。传给ip_rcv函数处理的数据包存放在skb中,ip_rcv函数需要从 skb管理结构中获取各种信息,作为处理的依据,并将数据链路层与网络层的处理关联在一起。
主要步骤如下:
(1)检查当前skb各数据域的状态
(2)skb->pkt_type数据域的值,确定上交还是丢弃
(3)数据包共享的处理
(4)IP协议头信息的正确性检查
(5)数据包的正确性检查
(6)清理工作,获得一个干净的数据包
(7)函数结束,回调ip_rcv_finish完成对数据包的处理
2、ip_rcv_finish函数
Ip_rcv_finish函数主要功能如下:
确定数据包是前送还是在本机协议栈中上传,如果是前送,需要确定输出网络设备和下一个接收站点的地址。
解析和处理部分IP选项。
处理流程如下:
(1)获取路由信息
(2)更新流量控制系统使用的统计信息
(3)处理路由选项
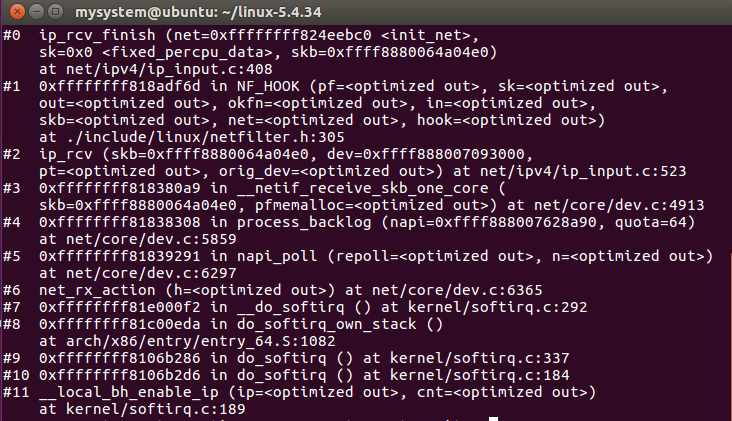
函数结束处理,调用dst_input确定对数据包的处理函数是哪一个,实际的调用存放在 skb->dst->input数据域,根据数据包的目标地址,skb->dst->input设置成ip_local_deliver或ip_forward。
ip_rcv_finish函数调用栈
6.2 发送数据包在IP层的处理
在 ip_rcv_finish 函数结束处,如果数据包的目标地址不是本机,内核需要将数据包前送给适当的主机;反之,如果数据包的目标地址是本地主机,内核需要将数据包上传给TCP/IP 协议栈网络层以上的协议实例。处理函数的选择由dst_input完成,它根据路由将处理函数设置为 ip_forward或ip_local_deliver。
6.2.1 数据包的前送(发送至下一主机)
与数据包接收处理过程类似,数据包前送也分为两个阶段完成:ip_forward和 ip_forward_finish。第二个函数在第一个函数执行结束时调用。
函数处理流程如下:
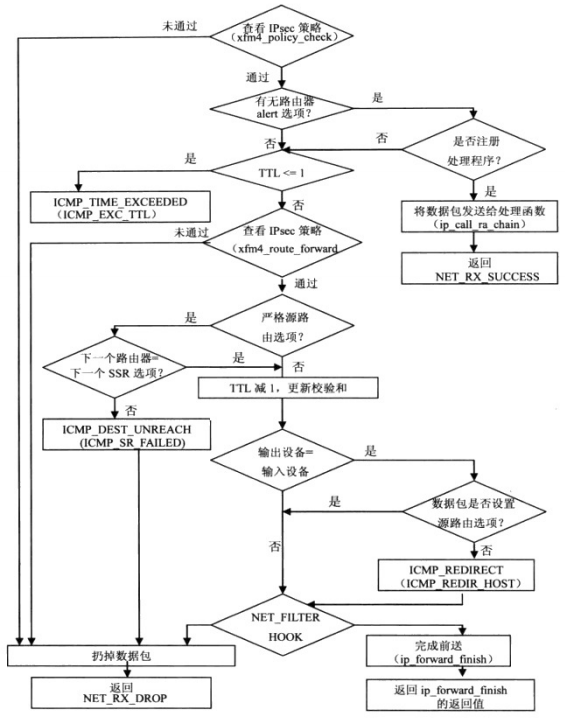
当ip_forward_finish处理完前送数据包的所有IP选项后,交由dst_output函数送达目的主机。
dst_output 调用虚函数output,虚函数output根据数据包的目标地址类型来初始化。目标地址为某一主机地址时,output初始化成ip_output,如果目标地址是组发送地址,则它初始化成ip_mc_output,数据包的发送分3个阶段处理,分别由ip_output,ip_finish_output,ip_finish_output2三个函数完成,对应如下:
ip_output函数初始化数据包的输出网络设备和传输协议,最后由网络过滤子系统对数据包进行过滤,并调用ip_finish_output函数完成实际的发送操作。
ip_finish_output 的主要任务是根据网络配置确定是否需要对数据包进行重路由,是否需要对数据包进行分割,最后调用ip_finish_output2与相邻子系统接口,将数据包目标地址中的IP地址转换成目标主机的MAC地址。
ip_finish_output2函数是与相邻子系统接口的函数,该函数的主要任务是,在数据包中为数据链路层协议插入其协议头,或为数据链路层协议头预留分配空间,然后将数据包交给相邻子系统发送函数dst->neighbour->output处理。
ip层发送过程函数调用栈

6.2.2 数据包上传本地主机
当数据包的目标地址为地本机时,在 ip_rcv_finish 函数中会将skb->dst->input初始化为ip_local_deliver。本地发送功能也分两个阶段完成: ip_local_deliver和 ip_local_deliver_finish。
ip_local_deliver函数的主要任务就是重组数据包,重组数据包的功能通过调用ip_defrag函数完成。ip_defrag完成数据包重组后返回指向完整数据包的指针,如果这时还没有收到数据包的所有分片,数据包还不完整,则它返回NULL。
数据包重组成功,调用网络过滤子系统的回调函数来查看数据包的配置,并执行ip_local_deliver_finish完成数据包上传功能。
ip_local_ deliver_finish函数完成后,数据包就离开网络层上传至TCP/IP协议栈的传输层。
ip层本地接收函数调用栈
ip层时序图具体如下:
网络层实现数据包接收/发送的API调用关系总图
7、传输层
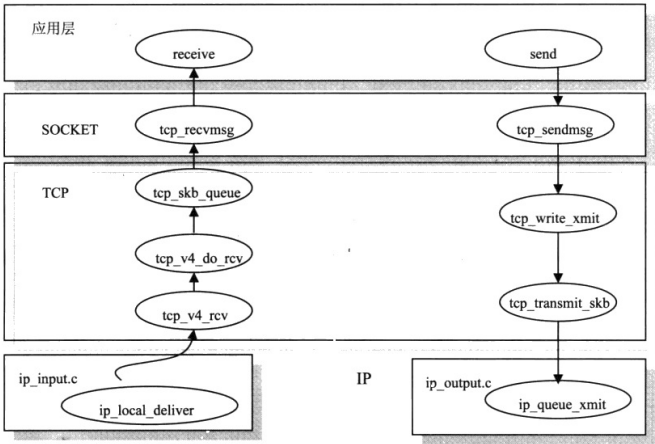
传输层的主要任务是保证数据能准确传送到目的地。在TCP/IP 协议栈中这个功能由传输控制协议(TCP,Transmission Control Protocol)完成。同时传输层紧接在应用层下,它也是用户地址空间的数据进入内核地址空间的接口。TCP/IP 协议栈在传输层提供两个最常用的协议:TCP和UDP,这里我们研究TCP协议的实现。
套接字,TCP,IP层之间的接口函数关系
7.1 传输层的接收过程的实现
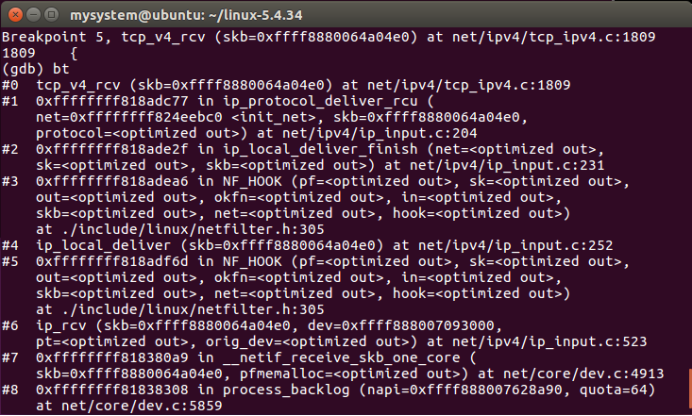
为了将输入数据包传送给传输层正确的协议处理函数,输入数据包使用的传输层协议在IP层处理时已设定。在传输层,各协议输入处理函数在协议初始化时注册到内核TCP/IP协议栈接口,IP层通过调用ip_local_deliver函数在IP数据包协议头 iphdr->protocol数据域中设定的值,在传输层与IP层之间管理协议处理接口的哈希链表inet_protocol中查询,找到正确的传输层协议处理函数块,并上传数据包。对于TCP协议,它在inet _protocol结构中初始化的输入数据包处理函数是tcp_v4_rcv。
1、tcp_v4_rcv函数
在 tcp_v4_rcv函数的起始部分同样也需要对接收到的skb数据包做一系列的正确性检查。tcp_v4_rcv函数主要功能包括以下两个方面:
(1)数据包合法性检查。
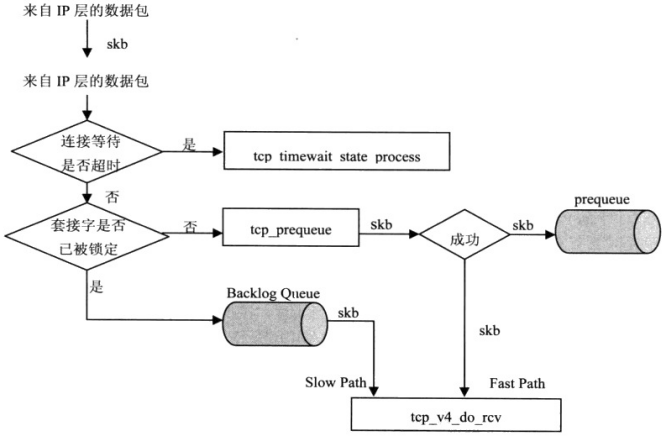
(2)确定数据包是“快速路径”处理,还是“慢速路径”处理。
Linux TCP/IP协议栈中,在TCP层有两条路径处理输入数据包:“Fast Path”和“SlowPath”。“Fast Path”是内核优化TCP处理输入数据包的方式。当TCP协议实例收到一个数据包后,它首先通过协议头来预定向数据包的去处:“Fast Path”或“Slow Path”。
进入快速路径的数据段会放入prequeue队列中,这时用户进程被唤醒,在 prequeue队列中的数据段就由用户层的进程来处理,这个过程省略很多“Slow Path”处理中的步骤,从而加大了数据吞吐量。而慢路径放入backlog queue,需要调用tcp_v4_do_rcv进行处理。
tvp_v4_rcv函数处理流程
tcp_v4_rcv函数调用栈
7.2 传输层发送数据流程
TCP协议实现的传送功能是指将从应用层通过打开的套接字写入的数据移入内核,通过TCP/IP协议栈,最终通过网络设备发送到远端接收主机。一旦应用层打开一个SOCK_STREAM类型的套接字,并发出写数据请求,就会调用TCP协议实现的传送例程tcp_sendmsg来处理所有从打开的套接字上传来的写数据请求。
tcp_sendmsg 函数是TCP协议初始化时在协议函数块中注册发送函数。完成的功能为:
(1)将数据复制到Socket Buffer 中。
(2)把Socket Buffer放入发送队列。
(3)设置TCP控制块结构,用于构造TCP协议发送方的头信息。
tcp_sendmsg将数据从用户地址空间复制到内核空间,最终所有这些从用户地址空传来的数据包,都是通过tcp_write_xmit函数调用 tcp_transmit_skb函数向IP层传送的。
tcp_transmit_skb函数发送过程主要如下:
(1)tcp_transmit_skb函数初始化
(2)确定TCP数据段协议头包含的内容
(3)发送数据,调用实际传送函数将该数据段传送给IP层。
tcp_sendmsg函数调用栈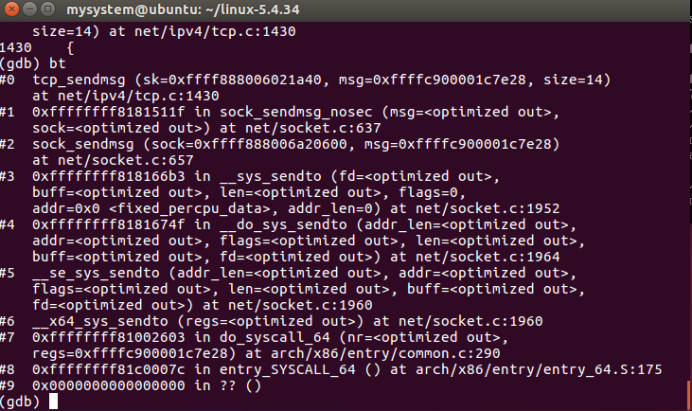
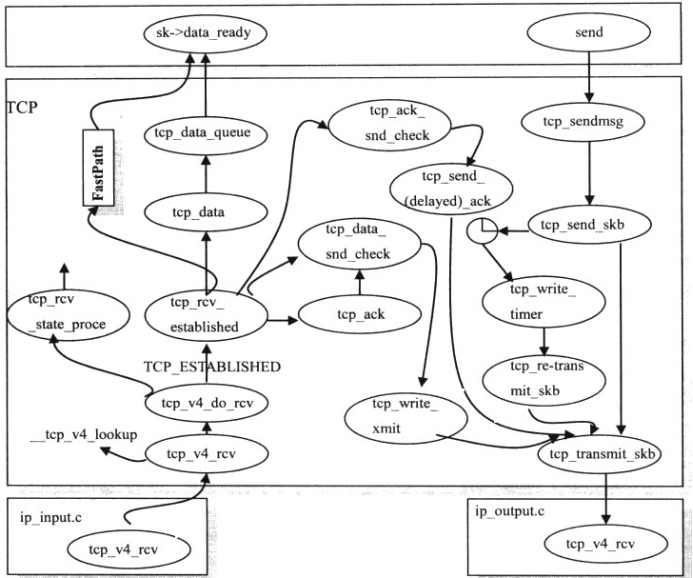
传输层TCP发送接收时序图:
8、套接字接口层
套接字接口最初是BSD操作系统的一部分,在应用层与TCP/IP协议栈之间接供了一套标准的独立于协议的接口。从TCP/IP 协议栈的角度来看,传输层以上的都是应用程序的一部分。Linux与传统的UNIX类似,TCP/IP协议栈驻留在内核中,与内核的其他组件共享内存。传输层以上执行的网络功能都是在用户地址空间完成的。Linux使用内核套接字概念与用户空间套接字通信,这样使实现和操作更简单。Linux 提供了一套API和套接字数据结构,这些服务向下与内核接口,向上与用户空间接口,应用程序使用这一套API访问内核中的网络功能。
8.1 套接字API系统调用的实现
系统调用完成将用户程序的函数调用转换成对内核功能服务调用,并获取内核功能服务的返回值,然后传递给用户程序。
Linux中实现系统调用主要分为下列三步:
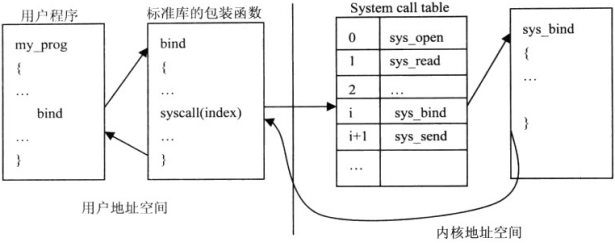
(1)内核实现了一系列的系统调用.所有系统调用函数以sys_为前缀名(如sys_bind),对应用户程序的函数调用。内核为每个系统调用分配一个索引号,索引号与系统调用函数的对应关系保存在系统调用表中。
(2)用户程序调用参数在用户地址空间,内核功能函数要访问这些参数,需将其从用户地址空间映射到内核地址空间。
(3)返回系统调用结果,成功返回0,失败返回错误代码。
8.1.1 socketcall系统调用
在Linux内核中只有一个系统调用sys_socketcall 完成用户程序对所有套接字操作的调用,这需要以不同的参数来决定如何处理用户程序的调用。传给sys_socketcall函数的第-一个参数是一个数字常数,sys_socketcall 以该常数为索引选择需要调用的实际函数。
8.1.2 sys_socketcall 套接字分路器
sys_socketcall函数接收所有来自应用程序对套接字的20种操作的系统调用,sys_socketcall函数的功能并不复杂,它犹如一个分路器,将来自应用程序的系统调用分支到其他函数上,每个函数实现个小的系统调用功能。
应用程序调用应用层套接字的API函数时,会产生一个内核系统调用中断,该中断转而调用sys_socketcall 函数。
sys_socketcall 函数主要完成两个功能:
(1)将从用户地址空间传来的每一个地址映射到内核地址空间。该功能通过调用copy_from_user函数完成。
(2)将应用层套接字的API函数映射到内核实现函数上。
sys_socketcall函数首先检查函数调用索引号是否正确,其后调用copy_from_user函数将用户地址空间参数复制到内核地址空间。最后switch词句根据系统调用函数索引号,实现套接字分路器的功能,将来自应用程序的系统调用转到内核实现函数sys_xxx 上。
sys_socketcall函数分路逻辑 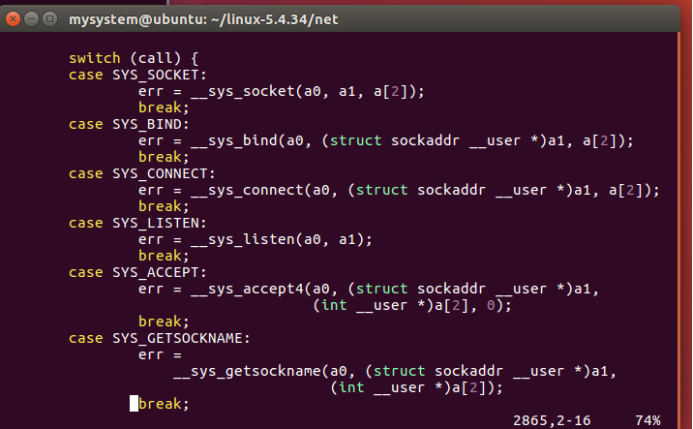
8.1.3 sys_sendto,sys_recvfrom,sys_socket调用流程
1、创建套接字sys_socket:
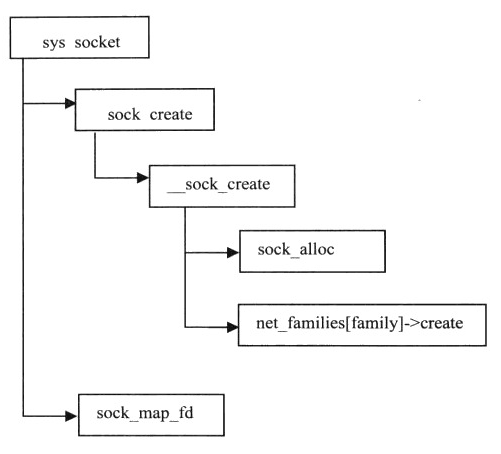
2、发送sys_sendto:
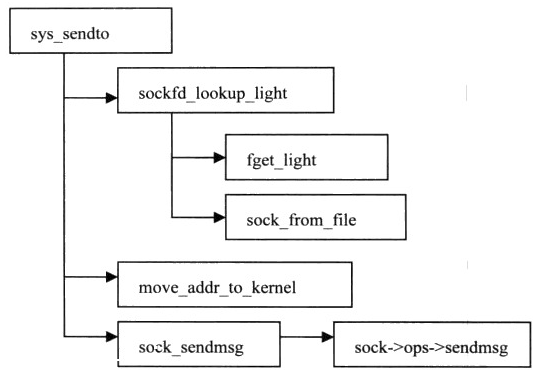
3、接收sys_recvfrom:
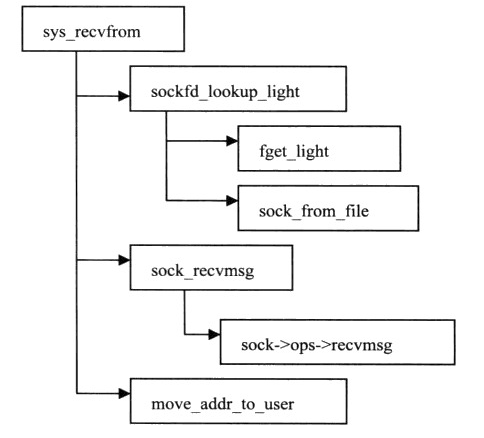
9、时序图总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号