
go学习笔记(依赖管理、异常处理、反射、并发控制等)
前言
这个学习笔记是写来做组内分享的,额嗯,其实他们都是大佬。那我就抛砖引玉吧,如果你看到了,也希望能给我提出宝贵指正。
目录
1. 概述
2. 什么是gopath和goroot
3. GOPATH依赖管理
4. vendor
5. GO MODUE
go.mod
go.sum
版本选择
1. error
2. defer
3. panic和recover
1. 协程
2. 调度策略
队列轮转
系统调用
工作窃取
3. 并发控制工具
1. channel
2. context
一.Go的依赖管理
1. 概述
go的依赖管理经过了gopath、vendor、go module三个过程。gopath不方便管理依赖的多个版本,vendor可以把项目依赖的版本库同项目一起管理但增加了项目的大小,go module则是一种更成熟的依赖管理方式,不再需要把指定版本的依赖包放到项目中。
2. 什么是gopath和goroot
goroot就是所谓的go安装目录,里面包含了go的可执行工具、标准库等。


gopath是工作目录,其下需要有bin、pkg、src三个目录,分别存放生成的可执行文件、归档文件(加速编译)、源码文件。gopath指向用户域,使用命令安装go的时候会在当前户目录下创建一个go目录作为gopath,这样就做到了用户工作空间的隔离。
3. GOPATH依赖管理
在这种依赖管理模式下,go项目创建在gopath的src目录下,并且第三方依赖也同样需要放入src目录下。如下图所示:

其中bin是执行go install主程序(编译并移动文件)后生成的可执行文件地址,pkg是go install依赖后生成的归档文件地址,作用是加快后续编译,src则是源码地址,包括了第三方依赖。下图是使用gopath创建的一个项目的IDE截图:
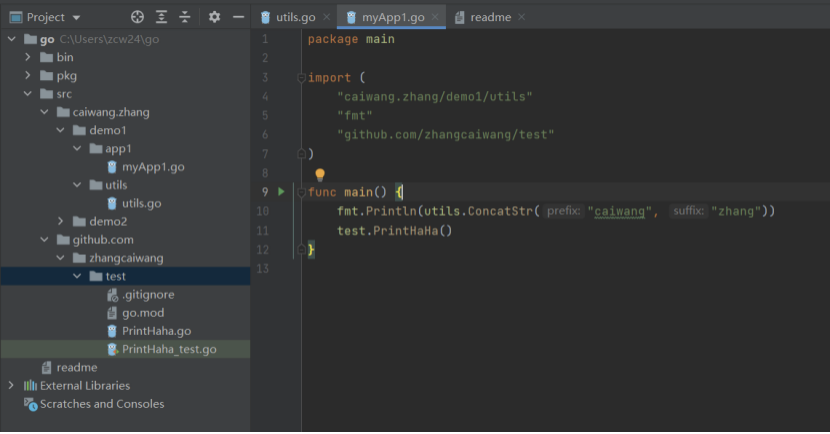
在gopath下,如果想要使用第三方依赖,首先需要使用go get xxx把依赖下载到src目录下,自己的源码则引用src下的依赖。项目查找依赖时的查找顺序是GOROOT/src -> GOPATH/src,从查找顺序可以知道,在一个固定的GOPATH下,不可能同时有一个依赖的两个不同版本,这个时候如果两项目要依赖不同版本的依赖就出问题了。
4. vendor
为了解决 GOPATH 方案下不同项目下无法使用多个版本库的问题,Go v1.5 通过设置变量GO15VENDOREXPERIMENT=1开始支持 vendor,并在v1.7后取消该变量,默认支持vendor。使用vendor的时候,一般是在项目的根目录下添加一个vendor目录,并把第三方依赖放入vendor目录中,如下图所示:
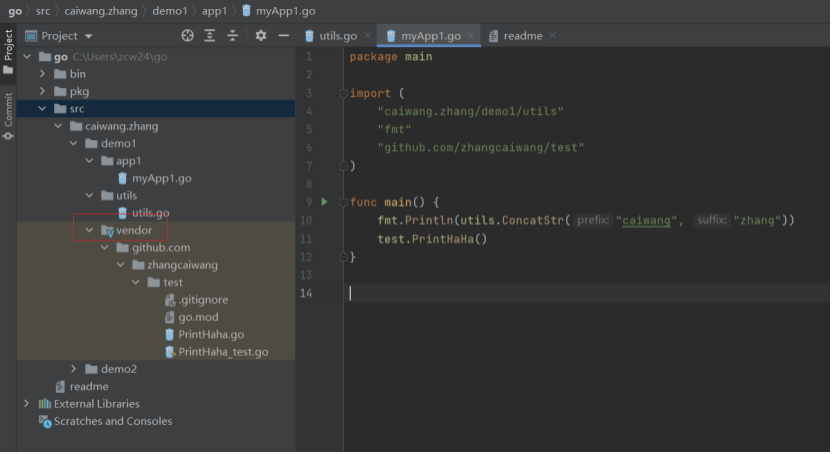
但是vendor目录不止是可以放在根目录下, 上图中vendor移动到app1目录中也是可以的。在vendor模式下查找依赖,先从源码所在目录查找vendor目录,查不到再向上查找,依次查找,直到找到 src 下的 vendor 目录。如果找不到,则按照gopath模式下的查找顺序查找。
vendor目录下,不同的项目可以实现依赖不同版本的依赖,但是增加了项目的体积。并且这个时候,项目依旧是存在于GOPATH/src目录下的。
5. GO MODUE
go module在v1.11版本推出,现在可以通过设置变量GO111MODULE=on开启go module。使用go module的时候,项目可以不必再创建再GOPATH下,也可以不用再使用vendor目录,并且灵活地实现了不同项目同时依赖不同版本的第三方依赖。
使用go module首先需要初始化go.mod文件,在任意一个目录下执行如下指令便成功创建了项目:
go mod init github.com/zhangcaiwang/goModule
使用go mod init [模块名]初始化一个项目,在go.mod中初始会标识了modue名字和开发代码时使用的go版本。
go.mod
下面是一个简单的gomodule项目,其中依赖了第三方的库,但是并没有vendor目录,GOPATH/src下也没有对应的包,且该项目放在了非GOPATH目录下:
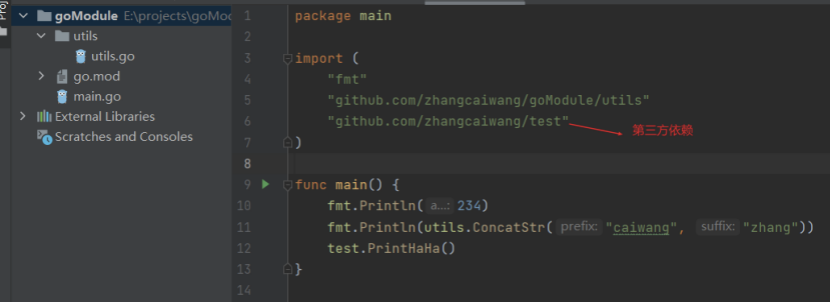
go.mod中会使用到四个指令:module、require、replace、exclude。module标识模块名字,当其他项目依赖该项目的时候,import路径需要以该名字作为前缀。require表示该项目所依赖的第三方依赖及其版本。replace表示当require中的依赖有bug或者因为网络等原因无法下载时,可以使用其他包替换,比如替换版本或者替换为其他镜像。exclude则明确标识不适用某个版本的依赖包。
在go.mod中,有些依赖包后面会有// indirect,出现该指令一般表示使用了过时的依赖。该指令指示了两种情况:
1. 直接依赖未启用go module。
比如项目A依赖于项目B,B项目依赖于项目B1、B2,且项目B未启用go module,那么在项目A的go module中不仅会require B、B1、B2,并且会在B1、B2的版本后面加上//indirect
2. 直接依赖的go.mod中的依赖不全。
同样上面的情况,B的go.mod文件中require了B1,但是没有requireB2,那么在A的go.mod中,不仅会requireB、B2,且B2的版本后面加上//indirect
go.mod文件中的依赖版本除了有v1.0.0这样的语义化版本之外,还有vx.y.z-yyyymmddhhmmss-abcdefghijkl这样的伪版本号。其实无论是语义化版本还是伪版本,其对应的都是commit id,也就是说go的依赖真正的版本是commit id。对于伪版本第一部分是虚拟的语义化版本,第二部分是commit提交时间,第三部分是前12位的commit id。
go.sum
go.sum文件中每一行由<module> <version>[/go.mod] <hash>组成,分别是模块名、依赖的版本、hash值。如下所示:

正常情况下,每个依赖包版本会包含两条记录,一条记录了该依赖包所有文件的hash值,包含/go.mod的另一条则记录了go.mod文件的hash值。如果依赖没有go.mod文件,则只有第一条记录。
版本选择
最小版本选择
假设有一个项目有可能会依赖下面的三个项目,这三个项目都依赖D且D的最高版本是1.4.2:
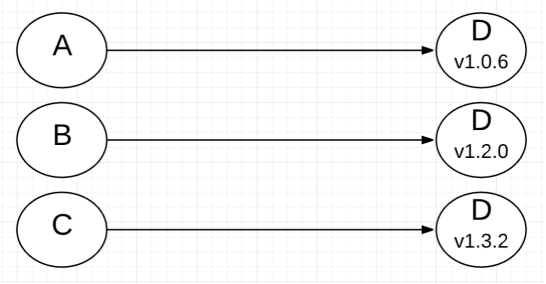
在项目依赖A的时候,Go会尊重module A的要求并选择版本1.0.6。在需要module的项目的所有依赖项的当前所需版本集合中,Go会选择“最小”版本。换句话说,现在只有module A需要module D,而module A已指定它要求的版本为v1.0.6,所需版本集合中只有v1.0.6,因此Go选择的module D的版本即是它。
如果我引入要求项目导入module B的新代码时会怎样?将module B导入项目后,Go会将项目的module D版本从v1.0.6升级到v1.2.0。Go再次在项目依赖项module A和B的当前所需版本集合(v1.0.6和v1.2.0)中选择了module D的“最小”版本。
如果我再次引入需要项目导入module C的新代码时会怎样?Go将从当前所需版本集合(v1.0.6,v1.2.0,v1.3.2)中选择最新版本(v1.3.2)。请注意,版本v1.3.2仍然是module D(v1.4.2)的“最小”版本,而不是“最新最大”版本。
二.Go的异常处理
1. error
error是只有一个Error() string方法的接口,任何实现了该方法的结构体都可以作为error,相对于普通变量和panic,我们可以把error当作普通的变量来看待。
创建error有两种方法:
1. errors.New(“”) // 返回一个errorString结构体的指针,该指针类型实现了Error方法
2. fmt.Errorf(xxx)
链式error
go1.13版本以后增加了链式error,目的是为了保留原始的error,其对应的结构体类型为wrapError。errors.wrapError依然可以认为是普通的error因为它实现了Errors() string方法。

此外,它还实现了Unwrap方法,此方法可以拿到wrapError包裹的上一级error。创建wrapError可以使用fmt.Errorf()通过动词%w创建:fmt.Errorf(“error msg:%w”, err)。error之间将会组成一个链式结构:
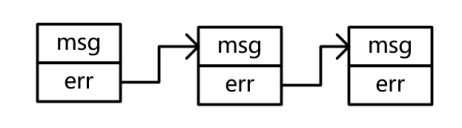
在链式error下,原始的error可能会被包裹比较深,如何知道链中是否包含指定的error就是一件重要的事情。比较笨的方法是可以通过wrapError的Unwrap方法或者errors.Unwrap方法去遍历链,另外一种方法是通过errors.Is(err, target error) bool方法便捷地达到目的。此外,如果想知道链中是否包含某一种类型的error,则可以通过errors.As(err error, target interface{}) bool 做判断,其中的target参数是一个指针,并且必须指向实现error接口的类型或者interface{}类型。
func main() {
err := errors.New("init error")
err2 := fmt.Errorf("err2: %w", err)
fmt.Println(err2)
fmt.Println(errors.Is(err2, err))
var err3 error
fmt.Println(errors.As(err2, &err3))
}
output:
err2: init error
true
true
2. defer
defer用于延迟函数的调用,通常用于关闭文件描述符、释放锁、处理panic等场景。defer语句采用后进先出的设计,函数执行时,每遇到一个defer都会把函数压入栈中,函数返回前再将延迟函数从栈中取出执行,最早遇到的defer函数会被最晚执行。
关于defer,可以先思考一下下面这两个函数的输出和返回是什么:
func test() {
w := 1
defer fmt.Println(w)
w++
}
func test() (num int){
w := 1
defer func() {
num++
}()
return w
}
上面的两个函数对应了defer的两个特性。第一个,defer的延迟函数在defer语句的位置确定(output:1)。第二个(return:2),函数的return并不是原子的,返回过程经过了两个步骤:设置返回值 -> 返回,而defer的延迟函数则是在这两个步骤间执行的。
3. panic和recover
panic是一个内置函数,可以传入任意类型参数,如果panic使用recover函数恢复,那么该参数就是recover函数的返回值。
func panic(v interface{})
panic函数执行后,调用panic的函数的后续代码不会被执行,并会调起栈中的defer函数执行,如果中途没有遇到recover函数,则当defer函数执行完后,程序退出。如果遇到revover,defer函数依旧会执行完,但是程序不会退出。此外,panic函数不会处理其他协程中的defer延迟函数。
recover函数也是一个内置函数,通常配合defer执行,其作用是为了恢复panic,避免程序异常退出。
func recover() interface{}
func test() {
defer fmt.Println("test")
defer func() {
if err := recover(); err != nil {
fmt.Println("recover")
}
fmt.Println("B")
}()
panic("demo")
}
recover函数起作用需要在defer函数中调用,并且在defer的嵌套函数中不会起作用,如下面的例子,虽然defer的嵌套函数中调用了recover函数,却不能恢复panic,程序依旧会异常退出:
func test() {
defer fmt.Println("test")
defer func() {
func() {
if err := recover(); err != nil {
fmt.Println("recover")
}
}()
fmt.Println("B")
}()
panic("demo")
}
三.Go反射
要了解反射首先需要了解interface。interface是一组方法的集合,任何实现了这一组方法的类型都可以称为其实现了这个接口,而这个类型的变量可以存储到这个interface变量中(var v xxxinterface)。
空interface(interface{})没有任何方法,所以任意类型的变量都可以赋值给空指针。
在go中使用runtime.iface结构表示接口,这个结构体保存了接口存储的变量的类型和指向变量值的指针:
type iface struct {
tab *itab // 变量类型
data unsafe.Pointer // 指向变量值的指针
}
而反射的机制就是使用一组方法操作interface结构体中这两个值。
go的反射提供了两种类型:reflect.Type、reflect.Value,这两种类型分别对应了interface结构体的两个变量。使用下面的两个方法可以获取:
func ValueOf(i interface{}) Value
func TypeOf(i interface{}) Type
func test() {
var a = 100
v := reflect.ValueOf(a)
t := reflect.TypeOf(a)
fmt.Printf("val: %v, type: %v", v, t)
}
output:val: 100, type: int
从上面两个函数的定义可以看到,其入参类型是interface{},即变量a先转化成了inteface{}类型的变量,反射操纵这个interface{}变量。
当变量通过反射被转换成了reflect.Value类型后,可以通过Interface()方法转换回来:
func test() {
var a = 100
v := reflect.ValueOf(a)
b := v.Interface()
if a == b {
fmt.Println("equal")
}
fmt.Printf("type: %T, %T", b, a)
}
// output:
equal
type: int, int
此外反射还可以通过Value.Setxxx()来修改变量的值,但是如果直接修改int类型的变量是不被允许的,因为int是不可变量。这个时候可以传入变量的地址来达到修改变量的目的,下面的代码中,v是一个包含了指向初始值的指针的Value,所以可更改原始值:
func test() {
var a = 100
v := reflect.ValueOf(&a)
v.Elem().SetInt(101)
fmt.Println(a)
}
func (v Value) SetInt(x int64) {
v.mustBeAssignable()
switch k := v.kind(); k {
default:
panic(&ValueError{"reflect.Value.SetInt", v.kind()})
case Int:
*(*int)(v.ptr) = int(x)
case Int8:
*(*int8)(v.ptr) = int8(x)
case Int16:
*(*int16)(v.ptr) = int16(x)
case Int32:
*(*int32)(v.ptr) = int32(x)
case Int64:
*(*int64)(v.ptr) = x
}
}
从上面看到,这里使用了Elem()方法,那么这个方法是做什么的呢?下面看一下这个方法的描述:
// Elem returns the value that the interface v contains // or that the pointer v points to. // It panics if v's Kind is not Interface or Ptr. // It returns the zero Value if v is nil. func (v Value) Elem() Value
从上面可以看出,可以调用Elem的元素只可以是Interface和指针,并返回他们包含或者指向的值。同理reflect.Type也有其对应的Elem方法,不同的是这个Elem方法返回的是复合类型所包含的元素的类型:
// Elem returns a type's element type. // It panics if the type's Kind is not Array, Chan, Map, Ptr, or Slice. Elem() Type
那么,kind又是什么呢?reflect.Kind表示reflect.Type表示的特定类型,表示Kind的常量有:
const ( Invalid Kind = iota Bool Int Int8 Int16 Int32 Int64 Uint Uint8 Uint16 Uint32 Uint64 Uintptr Float32 Float64 Complex64 Complex128 Array Chan Func Interface Map Ptr Slice String Struct UnsafePointer )
如果反射处理的对象是结构体,我们还可以获取结构体的方法、反射调用方法、获取结构体的字段、tag、设置字段值:
func test() {
var myStruct MyStruct
myStruct.Name = "wang"
refValue := reflect.ValueOf(myStruct)
// 方法调用
m := refValue.MethodByName("PlusOne")
args := []reflect.Value{reflect.ValueOf(1)}
m.Call(args)
// 获取字段值
field := refValue.Field(0)
fmt.Println(field)
// 获取字段个数
fmt.Println(refValue.NumField())
// 设置字段值
reflect.ValueOf(&myStruct).Elem().FieldByName("Name").SetString("wangwang")
fmt.Println(myStruct)
refType := reflect.TypeOf(myStruct)
// 获取方法
m2, _ := refType.MethodByName("PlusOne")
fmt.Println(m2)
// 获取字段 & tag
field2, ok := refType.FieldByName("Name")
if ok {
fmt.Println(field2.Name)
fmt.Println(field2.Tag)
}
}
type MyStruct struct {
Name string "this is a tag"
}
func (num MyStruct) PlusOne(input int) {
fmt.Println(input + 1)
}
// output:
2
wang
1
{wangwang}
{PlusOne func(main.MyStruct, int) <func(main.MyStruct, int) Value> 0}
Name
this is a tag
四.Go并发控制
1. 协程
我们最常说的一句话是,进程是系统资源分配的基本单位,线程是系统调度的基本单位。那么协程是什么呢?在go里,协程可以理解为一种轻量级的线程,也叫两级线程模型。协程的调度不是由系统而是由用户程序进行调度的,在go中使用runtime包的协程调度器调度,因而协程切换更快,并且内存占用少。
在Java中没有协程的概念,并发执行任务时会创建一个线程池,线程循环从线程池的任务队列中不断拿取任务执行。但是这样有一个弊端,那就是当线程阻塞的时候,处理任务的线程就少了,导致程序处理能力下降,而创建过多的线程会导致上下文切换频繁,不一定能提高效率。
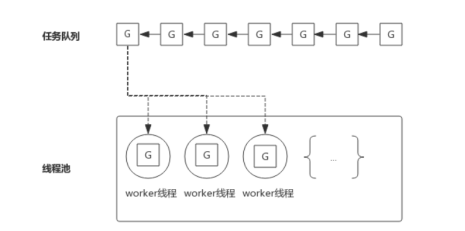
而在go中,协程作为调度的基本单位,多个协程共用一个线程的时间片,由协程调度器决定哪一个协程占用线程执行任务。当协程阻塞的时候,协程调度器则采用各种策略避免cpu时间被阻塞浪费。
go的协程相对于线程有一下优点:
1. go的协程开始分配8kb,并且可以由runtime控制动态增加或者减少,但是一个线程需要1m起步的容量。因此,只能启动几千个线程的机器在使用go时可以启动十万级的协程。
2. go协程的调度由runtime执行的,而线程是由操作系统调度,所以协程的切换速度很快,数千个协程可以复用一两个线程,极大地节省了资源。
3. Goroutines 通过内置的原始通道进行通信,这些通道是为处理竞争条件而构建的。因此,go 例程之间的通信是安全的,并且可以防止显式锁定,goroutines之间共享的数据结构不必被锁定。线程使用锁来访问共享变量,这样会导致难以检测的死锁和竞争条件。相比之下,goroutines 使用通道进行通信,整个同步由 go 运行时管理,这样就避免了死锁和竞争条件。
2. 调度策略
在go的调度中有几个比较重要的概念:
a. M:Machine,工作线程,由系统调度。个数不确定,由runtime创建和维护。
b. P:Processor,协程处理器。个数在程序启动时确定,默认与逻辑cpu个数相等,可 以通过GOMAXPROCS环境变量指定,P的数量最大为256。
c. G:Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、 状态以及任务函数,可重用。使用go关键字可以创建一个协程。
调度模型如下图:
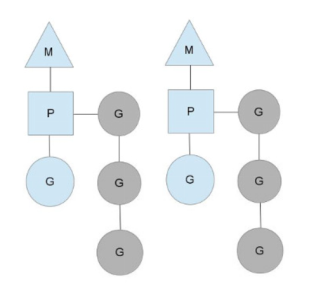
上面的图包含了两个工作线程M,每个M持有一个处理器P,并且每个M中有一个协程在运行。灰色的部分是待运行的协程队列,为P私有,其来源一般是P中的协程创建的协程,此外也有可能是窃取其他P的任务。此外,还有一个全局的协程队列,供多个处理器共享。
[ref]go调度器是一个非抢占式的协作调度器,在协作调度程序中,线程必须明确让出执行。在一些特定的检查点下,goroutine 可以(但不是必定)将其执行交给其他 goroutine:
1. 函数调用
2. 垃圾回收
3. 网络访问
4. 操作channel
5. 使用go 关键字
6. 阻塞原语,如mutex等
队列轮转
这种调度策略是依次把P维护的协程队列中的协程放入M中执行。此外,P会周期性查看全局队列中是否有G待运行,如果有则放入M中执行。因为全队队列没有对应的P,这样做的目的是防止全局队列中的协程饿死,而全局队列中的G的来源有两种,一个是因系统调用阻塞后被唤起的协程,另外是局部协程队列满了之后创建的协程。
系统调用
系统调用的模型如下所示:
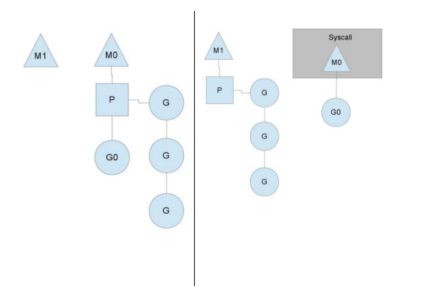
首先要明确的一点是go中也会有线程池(M池)。如上图所示,当前M0正在处G0,当G0进行系统调用的时候,M0发生阻塞,这个时候M0将会放弃P,进而线程池中的或者新建的M1将会持有P,M1会接替M0完成剩下的工作,保证处理器时间不空闲。从这里也看出来,相比较java中的线程池,go的调度策略在遇到系统阻塞时会更高效。
当G0的系统调用完成时,如果有空闲的P则M0会获取一个P继续执行P0,否则会将G0放入全局队列中等待其他P的调度,而M0则会放入线程池。
工作窃取
前面知道,局部协程队列中的协程是由自己的P中的协程创建的,那么有的时候可能会出现这样一种情况,某些协程会创建新的协程等导致P的协程队列边长,但是有的P的协程队列的协程可能比较少。当某个P中的协程消耗完后,为了继续运行 Go 代码,P可以从全局运行队列中取出 goroutine,但如果其中没有 goroutine,则必须从其他地方获取它们。某处是其他P。当P中的协程用完时,它会尝试从P中窃取大约一半的运行队列。这确保在每个上下文上总是有工作要做,从而确保所有线程都以最大容量工作。
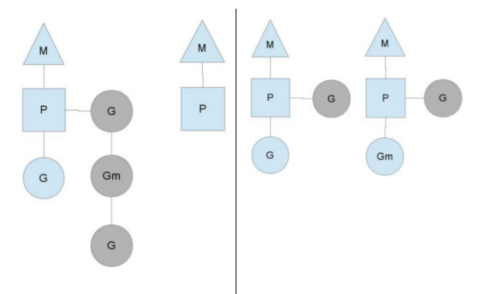
抢占式
在golang中,一个goroutine最多可以运行10ms,避免其他goroutine饿死。
3. 并发控制工具
WaitGroup
这是一种Go应用开发过程中常用的并发控制技术,对外暴漏的只有三个方法:Add,Done,Wait。首先看一下结构体定义:
type WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
上面的定义中,被用于并发控制的是state1字段,它包含了三个部分,counter表示当前还未执行结束的协程计数器,waiter表示等待协程结束的协程计数器,semaphore表示信号量:
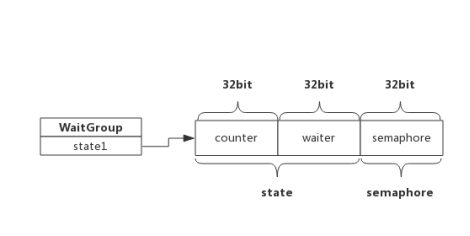
下面直接看源码,了解waitgroup的内部实现[ref]。最简单的就是Done():
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
就是这么神奇~
func (wg *WaitGroup) Add(delta int) {
// 获取状态(Goroutine Counter 和 Waiter Counter)和信号量
statep, semap := wg.state()
// 原子操作,goroutine counter累加delta
state := atomic.AddUint64(statep, uint64(delta)<<32)
// 获取当前goroutine counter的值(高32位)
v := int32(state >> 32)
// 获取当前waiter counter的值(低32位)
w := uint32(state)
// Goroutine counter是不允许为负数的,否则会发生panic
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// 当wait的Goroutine不为0时,累加后的counter值和delta相等,说明Add()和Wait()同时调用了,所以发生panic,因为正确的做法是先Add()后Wait(),也就是已经调用了wait()就不允许再添加任务了
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 正常`Add()`方法后,`goroutine Counter`计数器大于0或者`waiter Counter`计数器等于0时,不需要释放信号量
if v > 0 || w == 0 {
return
}
// 注:v == 0 && w > 0。走到这里说明是在执行Done()方法,并且前面add的所有协程都已经执行完毕。w>0说明已经调用了waiter,这个时候如果statep如果发生变动,不论是v变更了,还是w变更了,都说明了add和wait发生了并发调用。
// 能走到这里说明当前Goroutine Counter计数器为0,Waiter Counter计数器大于0, 到这里数据也就是允许发生变动了,如果发生变动了,则触发panic
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 重置状态,并发出信号量告诉wait所有任务已经完成
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
func (wg *WaitGroup) Wait() {
// 获取状态(Goroutine Counter 和 Waiter Counter)和信号量
statep, semap := wg.state()
for {
// 使用原子操作读取state,是为了保证Add中的写入操作已经完成
state := atomic.LoadUint64(statep)
// 获取当前goroutine counter的值(高32位)
v := int32(state >> 32)
// 获取当前waiter counter的值(低32位)
w := uint32(state)
// 如果没有任务,或者任务已经在调用`wait`方法前已经执行完成了,就不用阻塞了
if v == 0 { // point1
// Counter is 0, no need to wait.
return
}
// 使用CAS操作对`waiter Counter`计数器进行+1操作,外面有for循环保证这里可以进行重试操作
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 在这里获取信号量,使线程进入睡眠状态,与Add方法中最后的增加信号量相对应,也就是当最后一个任务调用Done方法
// 后会调用Add方法对goroutine counter的值减到0,就会走到最后的增加信号量
runtime_Semacquire(semap)
// 在Add方法中增加信号量时已经将statep的值设为0了,如果这里不是0,说明在wait之后又调用了Add方法,使用时机不对,触发panic
// 注:如果进入下面的方法,则说明一定是调用了Add方法。调用Done方法会报异常,调用wait方法并不会增加waiter数,而是在point1处就返回了。
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
return
}
}
}
从上面的解析中可以看出以下几点:
a. Add方法与wait方法不可以并发同时调用,Add方法要在wait方法之前调用.
b. Add()设置的值必须与实际等待的goroutine个数一致,否则会panic(delta小).
c. 调用了wait方法后,必须要在wait方法返回以后才能再次重新使用waitGroup,也就是Wait没有返回之前不要在调用Add方法,否则会发生Panic(Wait中).
五.其他
1. channel
管道是go在语言层面上提供的协程间交流的方式。创建管道可以采用两种方式:
a. var ch chan int // 声明方式
b. make方式
ch := make(chan int) // 无缓冲
ch := make(chan int, 10) // 有缓冲,容量为10
默认的管道可读可写,用<-控制数据的流向。当向管道中写入数据时,如果管道存在空闲缓冲或者有协程在读取管道时,可以写入,否则阻塞。读取管道时,当管道中有缓冲数据或者有协程正在写入时,可以正常读取,否则阻塞。此外,读写nil的管道会阻塞,写入已经关闭的管道会panic,可以读取已经关闭的管道。
管道在函数间传递时,可以限制其读写:
func test1(read <- chan int) { // 只能从管道读数据
}
func test2(writ chan <- int) { // 只能向官渡写数据
}
读取管道可以返回两个值:v, ok := <-ch。当ok==false表示管道已经关闭,v为对应类型的零值。但是当ok==true的时候并不能说明管道没有关闭,因为管道关闭后可能存在缓冲数据。
2. Context
Context是我们在开发中经常需要遇到的。比如在当前开发中,我们使用它来传递参数,打log,协程控制等等。Context本质是一种接口,任何实现下面几个接口的类型都属于Context:
type Context interface {
Deadline() (deadline time.Time, ok bool) // 返回deadline和是否设置deadline,如果没有设置,则返回time.Time的零值
Done() <-chan struct{} // 返回channel,如果非cancel类型的context,返回nil
Err() error // 描述context关闭原因
Value(key interface{}) interface{} // 用于valueCtx,传入key,返回value
}
比如经常会使用到的ctx := context.Background(),这里的ctx类型是“type emptyCtx int”。
通过查看Context的实现可知,在context包中go提供了四种实现:
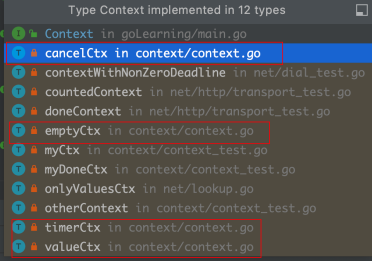
除了其中的emtyCtx,对于另外的三个实现,Context包提供了四个方法创建对应的实现:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)
func WithValue(parent Context, key, val interface{}) Context
其中WithTimeout和WithDeadline本质上是同一种实现,只是表述方式不一致而已。
cancelCtx
这种类型的ctx可以手动取消,而检测其是否取消可以通过Done方法,该方法返回一个通道,如果ctx被取消,则信道关闭,读取关闭的信道不再阻塞而是返回对应类型的零值。我们对于这种类型的ctx,通常会在select中这样使用:
ctx, cancel := context.WithCancel(root)
...
select {
case <- ctx.Done():
fmt.Println("calcel")
default:
fmt.Println("default")
}
其定义为:
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done chan struct{} // created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call,当前ctx cancel的时候会调用children中所有的ctx的cancel
err error // set to non-nil by the first cancel call
}
cancelCtx的核心实现的Done方法和cancel方法。
其中Done方法是Contex接口方法,其返回用于指示ctx是否被取消的信道,如果ctx没有被取消,则信道不关闭,从信道获取值会阻塞,如上例中的select中所示。
而cancel方法则是关闭Done方法锁返回的通道,从而实现指示ctx关闭。此外,cancel还会调用children中元素的cancel方法并把自身从parent中移除,parent是结构体中的Context变量。
当调用cancel方法的时候回传入context定义的error:Canceled,其描述为”context canceled“。也就是说,对于cancelCtx,不需要我们去管理它的error。
timeCtx
timeCtx实现了Context中的Deadline方法,该方法返回deadline和true。
通过名字可以了解到,这种类型的context是跟时间相关的,它可以在某个时间点到达的时候自动关闭,所以它需要有一个定时器。另外,这种类型的context也可以手动关闭,而上面的cancelCtx有这个功能,所以timeCtx的定义如下:
type timerCtx struct {
cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}
而创建timeCtx有两种方式:context.WithDeadline和context.WithTimeout,一个传入时间点,一个传入时间间隔,其中后者的内部实现是调用前者。
从上面的描述可以知道,timeCtx相对于cancelCtx来说只是多了一个定时关闭的功能,而这个功能可以在创建ctx的时候通过字段timer实现:
if c.err == nil {
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded)
})
}
return c, func() { c.cancel(true, Canceled) }
其中DeadlineExceeded是context定义的一个error,其描述为”context deadline exceeded“。观察上面的代码,最后一行返回了一个cancel函数,也就是说,timeCtx除了在timer中加了一个cancel方法,而且创建的时候还返回了一个cancel方法。这两个方法的不同之处仅在于error入参的不同。一个是自动调用,一个是手动调用。
另外,由于增加了定时器,所以在timeCtx的cancel方法中比cancelCtx多了关闭定时器的步骤:
func (c *timerCtx) cancel(removeFromParent bool, err error) {
c.cancelCtx.cancel(false, err)
if removeFromParent {
// Remove this timerCtx from its parent cancelCtx's children.
removeChild(c.cancelCtx.Context, c)
}
c.mu.Lock()
if c.timer != nil {
c.timer.Stop()
c.timer = nil
}
c.mu.Unlock()
}
valueCtx
valueCtx相对于前面的两种就简单多了,它不可以被cancel,并且只实现了Value方法,通过传入key返回value,因此它的结构体定义也比较简单:
type valueCtx struct {
Context
key, val interface{}
}
func (c *valueCtx) Value(key interface{}) interface{} {
if c.key == key {
return c.val
}
return c.Context.Value(key)
}
注意Value方法的最后一行,如果在当前ctx中找不到value,则会向上查找。
这种类型的ctx在我们的系统中用的也是很多的,因为可以通过value传递一些值,比如请求id之类的:
参考:
1. https://tonybai.com/2019/12/21/go-modules-minimal-version-selection/
2. https://golangbyexample.com/goroutines-golang/
3. https://segmentfault.com/a/1190000039192995?utm_source=tag-newest
4. 任洪彩.《GO专家编程》
5. https://www.cnblogs.com/wongbingming/p/12941021.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号