
爬虫利器beautifulsoup4
ab官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/


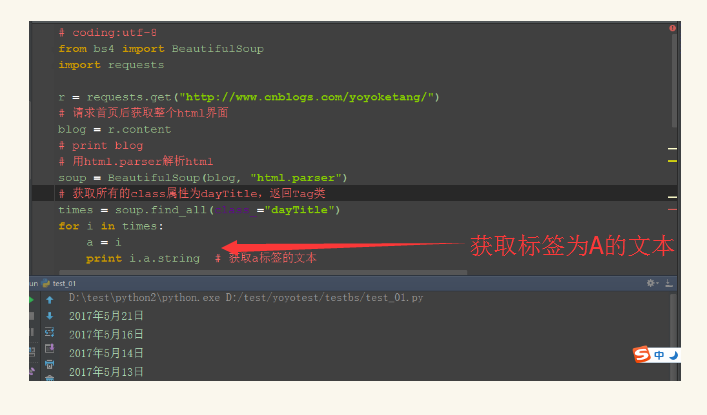
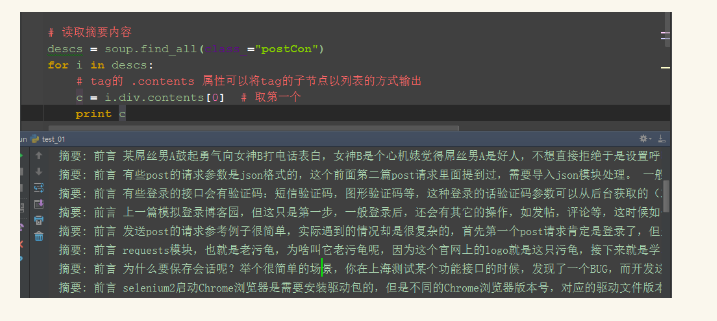
获取标签a的文本

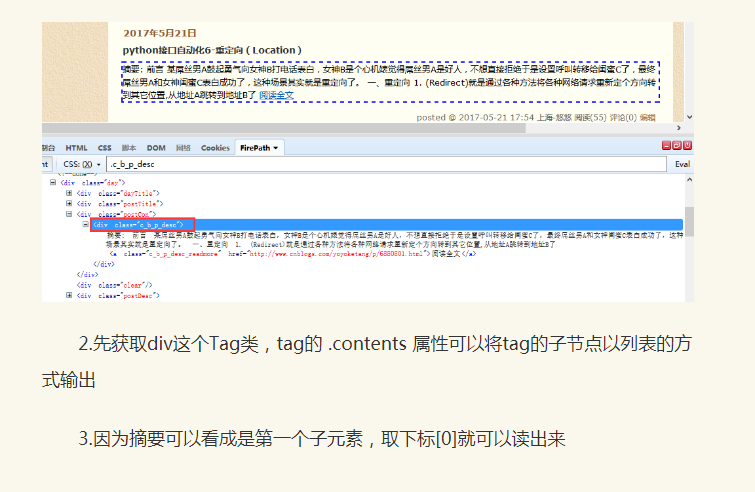
使用contents[0]取第一个元素

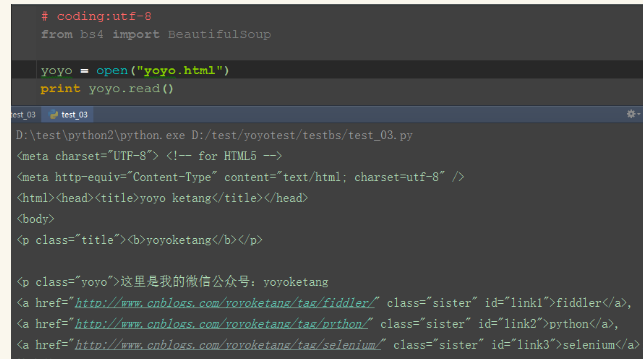
<meta charset="UTF-8"> <!-- for HTML5 --> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <html><head><title>yoyo ketang</title></head> <body> <b><!--Hey, this in comment!--></b> <p class="title"><b>yoyoketang</b></p> <p class="yoyo">这里是我的微信公众号:yoyoketang <a href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" class="sister" id="link1">fiddler</a>, <a href="http://www.cnblogs.com/yoyoketang/tag/python/" class="sister" id="link2">python</a>, <a href="http://www.cnblogs.com/yoyoketang/tag/selenium/" class="sister" id="link3">selenium</a>; 快来关注吧!</p> <p class="story">...</p>
用python的open函数读取这个html,如下图能正确打印出来,说明读取成功了
aa = open("html123.html",encoding='UTF-8') print(aa.read())
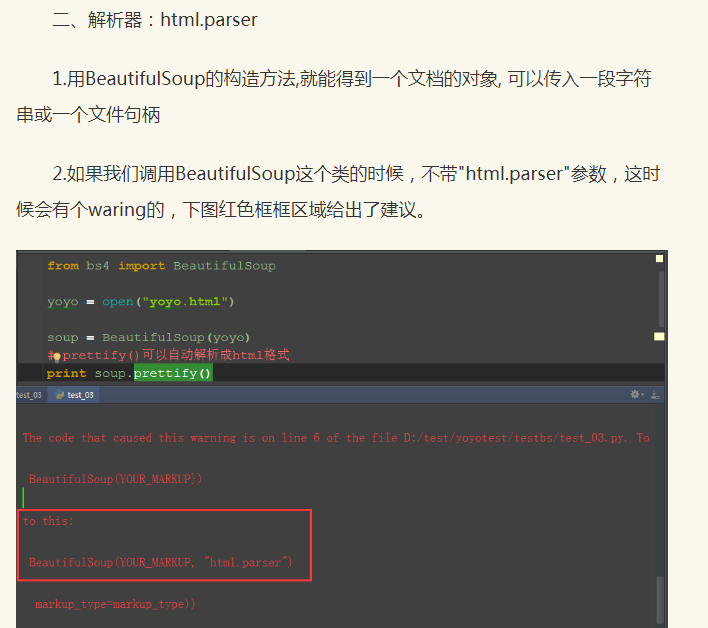
不带"html.parser"参数,这时候会有个waring的
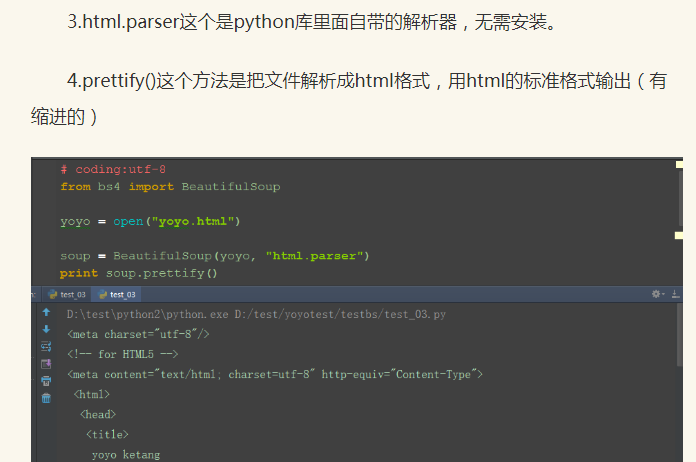


aa = open("html123.html",encoding='UTF-8')
soup = BeautifulSoup(aa,"html.parser")
print(type(soup)) #<class 'bs4.BeautifulSoup'>
tag = soup.title
print(type(tag)) # <class 'bs4.element.Tag'>
print(tag) #<title>yoyo ketang</title>
string = tag.string
print(type(string)) #<class 'bs4.element.NavigableString'>
print(string) #yoyo ketang
comment = soup.b.string
print(type(comment)) #<class 'bs4.element.Comment'>
print(comment) #Hey, this in comment!

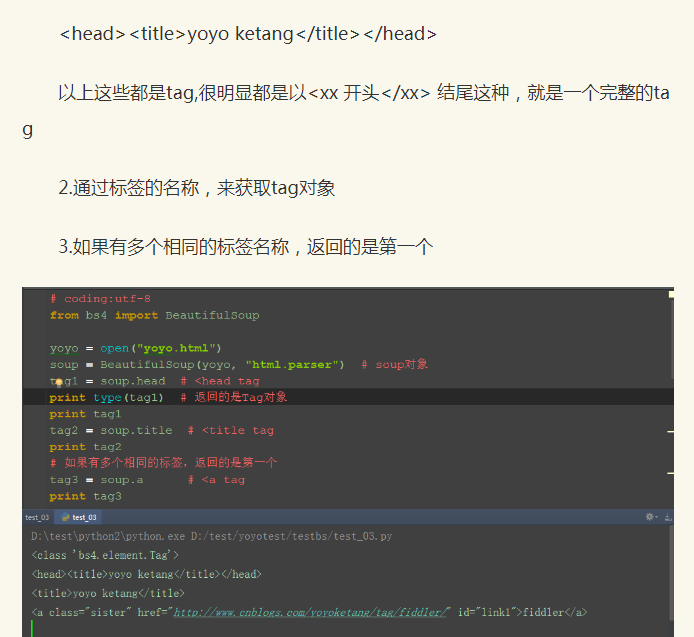
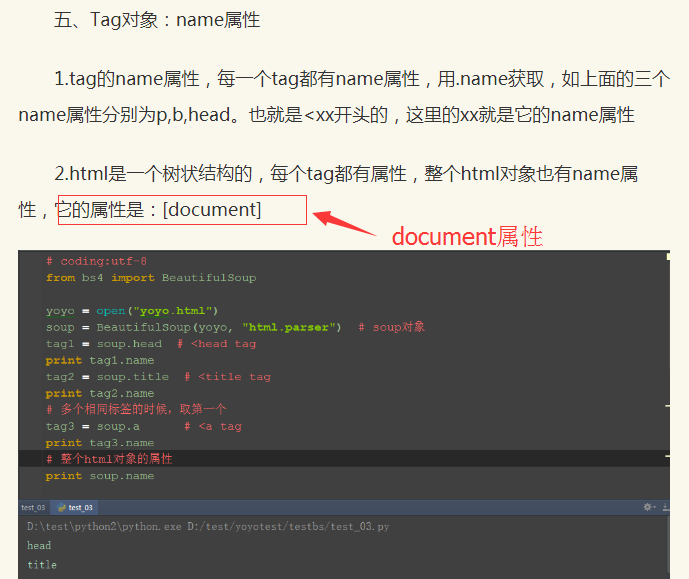
aa = open("html123.html",encoding='UTF-8')
soup = BeautifulSoup(aa,"html.parser")
tag1 = soup.head
print(tag1) #<head><title>yoyo ketang</title></head>
print(tag1.name) #head
tag2 = soup.title
print(tag2) #<title>yoyo ketang</title>
print(tag2.name) #title
tag3 = soup.a
print(tag3) #<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
print(tag3.name) #a
print(soup.name) #[document]


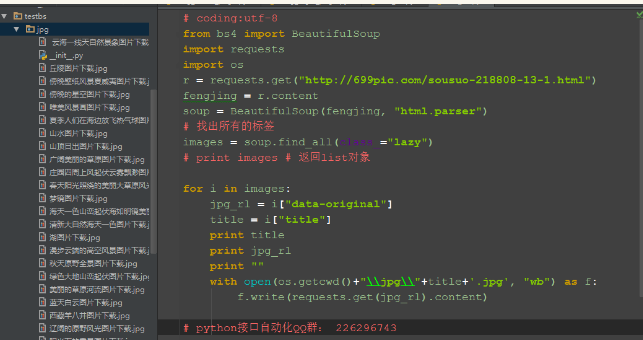
url = "http://699pic.com/sousuo-218808-13-1-0-0-0.html"
r = requests.get(url)
soup = BeautifulSoup(r.content,"html.parser")
# 找出所有的标签
images = soup.find_all(class_="lazy") # print images # 返回list对象
for i in images:
jpg_rl = i["data-original"] #获取url地址
title = i["title"] # 返回title名称
print(jpg_rl)
print(title)
print("")

获取图片内容用.content方法
url = "http://699pic.com/sousuo-218808-13-1-0-0-0.html"
r = requests.get(url)
soup = BeautifulSoup(r.content,"html.parser")
# 找出所有的标签
images = soup.find_all(class_="lazy") # print images # 返回list对象
for i in images:
jpg_rl = i["data-original"] #获取url地址
title = i["title"] # 返回title名称
print(jpg_rl)
print(title)
print("")
with open(os.getcwd()+ "\\jpg\\"+title+".jpg","wb") as f:
f.write(requests.get(jpg_rl).content)
#except:
# pass








 浙公网安备 33010602011771号
浙公网安备 33010602011771号