数据迁移工具设计
在业务不断发展变化的当下,系统的更新换代、扩展延伸已成常态。当新业务需要依托旧业务的历史数据,且这种情况并非个例,可能在多个场景中反复出现时,一套通用的数据迁移工具就成为了支撑业务顺畅过渡的关键。今天,我们不妨跳出具体的代码实现,从更宏观的角度聊聊数据迁移工具设计的那些事儿。
一、为何需要数据迁移工具
业务的推进往往不会一蹴而就,新业务上线时,常常需要调用旧业务积累的历史数据。就像有的路由业务在运单业务运行一段时间后才启动,运单的历史数据就必须妥善迁移过去。而且,这种情况并非偶然,在不同的业务场景、不同的区域系统中都可能遇到。
随着业务规模的扩大,数据量也会急剧增长。以某个快递系统为例,短短几个月就积累了数千万数据,若按一年的业务量预估,数据总量更是庞大。这就要求数据迁移工具能够应对大规模数据的处理,同时为未来可能的系统扩展做好准备。
二、设计的核心思路
设计数据迁移工具,首先要明确整体的方向。我们可以采用新旧系统并行的方式,让旧系统继续处理业务,同时搭建新的存储架构。通过全量同步与增量同步相结合的方式,先将大部分历史数据迁移过去,然后在业务相对平缓的时段完成切换。最后,再通过数据核对来确保迁移的完整性,对可能遗漏的数据进行补充。
这种思路的核心在于平衡业务连续性和数据迁移的效率与准确性。既不能因为迁移工作影响现有业务的正常运行,又要保证数据能够及时、准确地转移到新的系统中。
三、全量同步的考量
全量同步,顾名思义,就是将指定范围内的历史数据整体迁移。这就像搬家时先把大部分家具一次性搬到新家一样。
- 批次管理:在进行全量同步时,如何合理划分数据批次是个关键问题。批次太小,会增加处理的繁琐程度;批次太大,又可能影响处理效率和稳定性。我们需要找到一个合适的批次大小,让数据处理既能有序进行,又能在出现问题时便于排查和恢复。
- 数据筛选:不是所有的数据都需要迁移,我们可以根据时间等条件,选取业务所需的那部分数据。而且,对于已经存在于新系统中的数据,要判断是否需要更新,确保数据的时效性。
- 流程监控:在整个全量同步过程中,进度的监控也不可或缺。我们需要清楚地知道迁移进行到了哪一步,还有多少数据未迁移,以便及时发现问题并调整策略。
四、增量同步的逻辑
全量同步完成后,旧系统可能还在不断产生新的数据,这就需要增量同步来跟进。增量同步就像是在搬家后,不断把后续添置的小物件及时送到新家。
- 方案考量:为了保证增量数据能够及时、准确地同步,需要一套可靠的机制来捕获和处理这些数据。可以借助消息队列等工具,让数据的传递更加高效、稳定。
- 风险兜底:要处理好数据传递过程中可能出现的异常情况,比如数据丢失、重复等,确保每一条新增或变更的数据都能正确地反映在新系统中。
增量同步的关键在于及时性和准确性,它要紧跟业务的步伐,让新系统中的数据始终与业务实际情况保持一致。
五、应对冲突与保障可靠
在全量同步和增量同步同时进行时,难免会出现数据冲突的情况。比如,同一条数据在全量同步过程中,又在增量同步中被修改。这就需要我们制定合理的规则来判断该保留哪份数据,通常会以时间为依据,保留更新时间更新的数据。
对于删除操作,也需要谨慎处理。要考虑到全量同步和增量同步的先后顺序,避免因为同步的时序问题导致数据不一致。
此外,任何系统都可能出现故障,数据迁移工具也不例外。因此,一套完善的补偿机制必不可少。当某些数据迁移失败时,能够自动进行重试,确保数据最终能够迁移成功。
六、全量同步设计:
流程图:

设计思路:
- 采用迁移任务表记录此次迁移任务,按N条数据一个批次进行滚动查询数据和处理。本批次数据经过一系列过滤和校验后写入新库,每个批次会生成迁移明细记录来记录本批次的处理状态和重试信息,并记录下真实的每个批次执行了多少数据量。
- 把本批次最大的id设置为下一批次的起始id,并把这个id记录在迁移任务表中,记录上一次滚动最后记录的滚动字段值。然后更新本批次迁移明细的状态。如果发生异常会更新本次数据的迁移进度和重试次数。
数据过滤:
- 按时间范围过滤当前阶段的数据,记录创建时间在设定的迁移开始和截止时间之间,否则过滤
- 按主键查询新库,对比要迁移的数据是否已有记录存在新库。
- 如果存在,则判断同步时间是否大于新库记录的创建时间,如果大于需要更新数据,否则不处理。
- 如果不存在,对于修改要转成新增、对于删除进行忽略
写入新库:
写新库的扩展,迁移是针对表去生成迁移任务。所以在这里可以把不同表的数据分组。然后针对每个组的数据,把insert跟delete操作整合一下进行批量,更新操作就是单独执行。
执行异常处理:
一批数据写入过程中,如果正常执行完成就继续执行,更新失败我们会抛出异常,终止全量任务。去排查异常后重启。
极端情况的考量:
- 数据写入新库后,新增明细挂了,未更新迁移表阶段号
- 上一阶段已经更新了迁移表中的上一阶段最后记录值和阶段号,利用阶段号+1查询未产品明细数据,代表下一阶段并未完成,用最后记录值作为起始查询值,填充迁移表最后的记录信息作为新一轮任务。
- 新增明细后,未更新迁移记录和明细状态,挂了
- 未更新迁移明细,重启后查明细会针对未完成的阶段继续进行写入,利用数据过滤机制,保证不重复插入
- 下一阶段查询到数据后挂了
- 上一阶段完成了,直接用上一阶段保存的迁移记录作为新的阶段数据,上一阶段最后写入的记录值作为这一阶段的起始值,查数据处理
迁移进度统计:
统计表架构:表名、业务系统id、数据量、统计时间、查询统计开始截止时间、记录时间
生成逻辑:针对原表的数据,从滚动时间当日开始到截止时间,统计原库中原表数据每日的数据总量。用以与迁移任务表的数据总量进行对比,形成迁移进度。
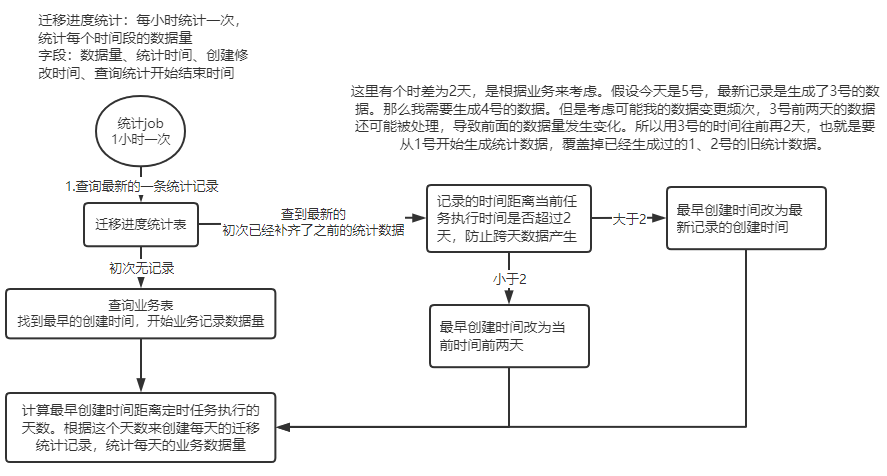
正常情况下全量同步再更新完本轮的明细和迁移任务信息后,去查源表下一批次数据。当查不到说明在设定的时间范围内,已经完成了所有数据的同步。也存在一种情况,最后查到的数据,经过过滤判断已经存在于新库了,那么在每次写入后,需要跟迁移进度表对比一下,看看是否已经同步完成了。
对比逻辑:通过当前批次的滚动时间去查询对应的需要迁移的数据总量,判断迁移记录表中已完成的迁移记录数与需要迁移的数据总数对比,如果大于或等于代表已经同步完成了,结束全量任务。
补偿:定时任务会查询失败的迁移任务数据,进行定时补偿,获取失败前的同步记录进行滚动数据设置,并设置重试次数。最大重试次数为3次。
七、增量同步设计
流程图:
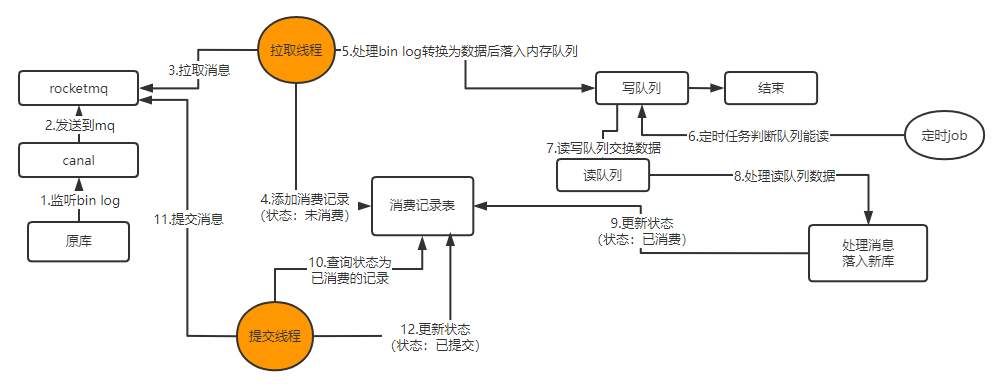
双队列机制:
- 采用内存队列是为了提升下游消费能力,队列实现轻量异步,同时对队列中的数据,进行一批批数据后,根据操作类型入库可以减少磁盘IO频次。
- 采用读写队列,是考虑到数据写入失败。所以设置了只读MQ消息,数据成功后才进提交。如果采用单队列,队列又要被写入,又要读取,无法保证高并发场景下,不上锁怎么去清理掉正确的数据,如果一直不清理,堆积的内存会无限膨胀直到溢出。如果上锁解决,性能反而更加不如双队列。
两个线程:
- 拉取队列负责:新增消费记录,数据进行转换写入内存队列;
- 提交队列负责:查询状态已消费的记录,进行提交;避免binlog消息不丢失,采用手动提交ack。
增量同步的停止:全量当同步不到最新的订单了,任务就会停止。增量同步任务会不断运行,确保两边数据库状态是同步的。会在某一个时刻,两边数据库状态一致。就需要进行数据校验
增量同步故障点和结局:
1、消息刚拉取,还未写入记录表,挂了:未进行任何处理,不影响什么,重启后直接再次拉取
2、消息拉取后,写入了记录表,往队列写数据。数据还没有被拿出来就挂了: 针对已存在记录的数据,会判断记录状态,只要不是已提交数据,都会进行重新入队处理
3、数据被从队列拿出来,处理过程中挂了:数据仍旧是未被消费和提交的,重新拉取处理即可
4、数据拿出来了,写入新库了,但是还未来的及更新消费记录状态为已消费: 重新拉取的数据,会在写入新库前进行数据过滤,通过时间判断会过滤掉已经落库的数据。然后会在这次处理中,完成失败的更新
5、整个流程都成功了,但是offset提交线程还未提交就挂了:下次启动的时候仍旧是会被拉取,然后被数据过滤去重
6、offset提交到mq了,但是本地消费记录状态未修改为已提交:下次启动的时候仍旧是会被拉取,然后被数据过滤去重。这里就涉及到了已有消费记录的数据,哪怕是已消费只要没提交都会进行重新入队
哪怕是记录都修改了后,但是mq本身提交消息时失败了,重试后,对于已提交数据会进行再次提交
本文来自博客园,作者:难得,转载请注明原文链接:https://www.cnblogs.com/zhangbLearn/p/18996688

 浙公网安备 33010602011771号
浙公网安备 33010602011771号