网络IO模型
网络IO交互过程:
一次网络IO的交互涉及到用户态、内核态、网卡之间的处理流程。以输入操作为例:
- 等待网络上的数组分组到达网卡,它会被拷贝到内核中的某个缓存区。该阶段可以定义为:等待数据准备好,然后把数据从网卡拷贝到内核空间
- 数据准备好后,把数据从内核缓存区拷贝到应用进程缓冲区
阻塞/非阻塞:描述的是用户线程调用内核IO操作的方式
- 阻塞是指IO操作需要彻底完成后才返回用户空间。
- 第一阶段数据没有准备好,进入阻塞状态,直到拷贝到用户空间才能返回,否则整个线程一直等待。
- 非阻塞指IO操作被调用后,立即返回给用户一个状态值,无需等待IO操作彻底完成。
- 第一阶段数据没有准备好,也不会进行阻塞状态,直接返回一个状态值表示数据未准备好,需要不断轮询访问。
同步/异步:描述的是用户线程与内核的交互方式
- 同步是指用户线程发起IO请求后需要等待或轮询内核IO操作完后才能继续执行。
- 第二阶段执行完,用户线程才能继续执行其他的
- 异步是指用户线程发起IO请求后,仍可以继续执行其他事情,当内核IO操作完成后会通知用户线程或调用用户线程注册的回调桉树
- 第一第二阶段用户线程无需过问,可以执行其他事情。第二阶段完成后,会通知用户线程或调用用户线程注册的回调函数
BIO:
同步阻塞式IO。服务端创建一个ServerSocket,客户端用一个Socket去连接ServerSocket,然后ServerSocket接收到Socket连接请求就创建一个Scoket和一个线程去跟客户端那个Scoket进行通信

同步体现在客户端socket的一次请求,服务端socket会处理再返回响应,响应必须等待处理完成才会返回,这个过程中客户端不能做其他的事。
该方式弊端在于,每次一个客户端接入都要在服务端创建一个线程来服务这个客户端,这会导致大量客户端接入时,服务端线程数大量增加,导致服务器负载过高甚至崩溃。即使使用线程池,利用固定线程数来处理请求,在高并发场景下,也会导致各种排队和延时,因为没有那么多线程来处理。
AIO:基于Proactor模型,异步非阻塞模型。特点是由OS完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用
NIO:
- 同步非阻塞IO,基于Reactor模型。JDK4后引入,在NIO中有一些概念:
- Buffer:缓冲区,一般是将数据写入Buffer,然后从Buffer中读取数据,有IntBuffer、LongBuffer等很多针对基本数据类型的Buffer。
- Channel:连接到TCP网络套接字的通道,类似于流,NIO中通过Channel来进行数据读写。通道对比流:通道可以同时读写,流只能读或只能写、通道可以实现异步读写数据、通道可以从缓冲区读写数据。
- Selector:多路复用器,selector会不断轮询注册好的channel,如果某个channel上发生了读写事件,selector会通过selectionKey将这些channel获取出来,然后进行IO操作。一个selector通过一个线程去轮询成千上万的channel,意味着服务端可以接入成千上万的客户端。

针对每个客户端的socket都会创建一个channel,客户端发起请求引起channel的改变,selector获取到有改变的channel,并针对每个请求一个线程进行处理。客户端并不是时时刻刻都有请求,所以没必要为每个客户端启动线程,而是针对请求启动线程。只有某个客户端发起一个请求,才会启动一个线程。非阻塞的核心在于无论多少客户端都可以接入服务端,客户端接入不会消耗一个线程只是创建一个channel然后注册到selector,selector线程不停轮询所以的channel,发现有事件就启动一个工作线程处理一个请求。同步体现在工作线程对于请求的处理是同步的,工作线程从buffer读取数据,处理再返回给buffer这个过程是同步的。
同步阻塞、同步非阻塞、异步非阻塞:
- BIO的同步阻塞:不是针对网络编程模型,而是文件IO操作来说。比如用BIO读文件,必须等待这次IO处理完并返回,你才能去做别的事。
- NIO的同步非阻塞:通过NIO的FileChannel发起文件IO操作,发起之后就返回了你可以去处理别的事,这是非阻塞。但是接下来还需要你不断去轮询操作系统看IO有没有处理完成。
- AIO的异步非阻塞:通过AIO发起文件IO操作后,立马可以去处理其他事情,操作系统自己处理完IO后会通过回调函数通知你已经处理完成了。
IO多路复用:
NIO的IO多路复用:
- IO指网络I/O,多路是指多个TCP连接或多个Channel,复用就是用一个或少量线程,来处理这些连接。
- 如nio里的selector:当没有事件时,调用select方法会被阻塞住,一旦有一个活多个事件发生后,就会处理对应的事件,实现多路复用。
- 与阻塞I/O区别:
- 阻塞I/O模式下,若线程因为accept事件发生阻塞,发生read事件后,仍需等待accept事件执行完成后,才能处理read事件
- 多路复用模式下,一个事件发生后,若另一个事件处于阻塞状态,不会影响该事件的执行
实现可以是select、epoll或poll。这三种系统调用上的阻塞,并不是真正阻塞I/O系统调用
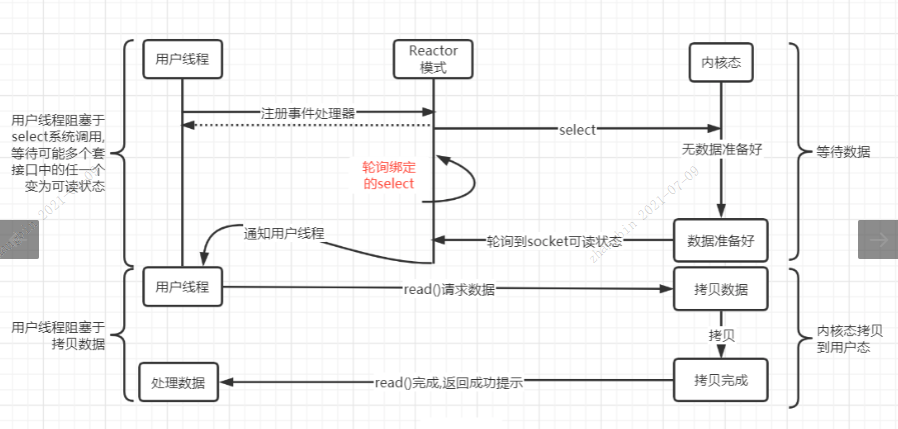
select、poll、epoll原理解析:
- 用户空间 / 内核空间:为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。
- 进程切换:为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行,这种行为被称为进程切换。
- 进程阻塞:正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态,阻塞状态的进程不占用CPU资源。
- 文件描述符(fd):一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
- 缓存IO:在Linux的缓存I/O机制中,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
I/O多路复用:I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select:
维护了一个fd数组,这个FD数组长度在32位系统中最大为1024个,在64位系统中,最大为2048个
select监视数据可读、可写或有异常三类文件描述符,调用select函数会阻塞,直到有描述符就绪,或者超时,函数返回。当select函数返回后,可以通过遍历fd_set来找到就绪的描述符
int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);
- maxfdp1:待测试的文件描述字个数
- fd_set:理解为一个集合,存放文件描述符即文件句柄。中间三个参数指定要让内核测试读、写和异常条件的文件描述符集合
- timeout:告知内核等待指定文件描述符集合中任何一个就绪可以花多少时间
- 返回值:-1表明发生错误,0表明超时,正数表明有n个fd准备就绪
优势:使用select函数进行IO请求的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断调用select读取被激活的socket,可达到在同一个线程内同时处理多个IO请求的目的,而在同步阻塞模型中,必须通过多线程方式才能达到。
弊端:
- 可协调fd数量和数值都不超过1024,无法实现高并发
- 使用O(n)复杂度遍历fd数组查看fd的可读写性,效率低
- 涉及大量kernel和用户态拷贝,消耗大
- 每次完成监控需要再次重新传入并且分事件传入,操作冗余
poll:poll本质上和select没有区别,依然需要进行数据结构的复制,依然是基于轮询来实现,但区别就是,select使用的是fd数组,而poll则是维护了一个链表,所以从理论上,poll方法中,单个进程能监听的fd不再有数量限制。但是轮询,复制等select存在的问题,poll依然存在
epoll:对select和poll的改进,核心思想是基于事件驱动来实现。给每个fd注册一个回调函数,当fd对应设备发生IO事件,就会调用这个回调函数,将该fd放入一个链表中,由客户端从链表中取出一个个fd,以此达到O(1)的时间复杂度
epoll操作实际对应三个函数:
- epoll_create:相当于在内核中创建一个存放fd的数据结构。在select和poll方法中,内核都没有为fd准备存放其的数据结构,只是简单粗暴地把数组或者链表复制进来;而epoll则不一样,epoll_create会在内核建立一颗专门用来存放fd结点的红黑树,后续如果有新增的fd结点,都会注册到这个epoll红黑树上。
- epoll_ctr:select和poll会一次性将监听的所有fd都复制到内核中,而epoll不一样,当需要添加一个新的fd时,会调用epoll_ctr,给这个fd注册一个回调函数,然后将该fd结点注册到内核中的红黑树中。当该fd对应的设备活跃时,会调用该fd上的回调函数,将该结点存放在一个就绪链表中。这也解决了在内核空间和用户空间之间进行来回复制的问题。
- epoll_wait:从就绪链表中取结点,这也解决了轮询的问题,时间复杂度变成O(1)
epoll的优点:
- 没有最大并发连接的限制,远远比1024或者2048要大。(江湖传言1G的内存上能监听10W个端口)
- 效率变高。epoll是基于事件驱动实现的,不会随着fd数量上升而效率下降
- 减少内存拷贝的次数
水平触发和边缘触发:
- 水平:只要条件满足,对应的事件就会一直被触发。未进行处理,那么会一直被通知
- 边缘:条件满足后,对应的事件只会触发一次,无论是否被处理,都只会触发一次。
- select和poll都是水平触发,epoll有两种模式,EPOLLLT和EPOLLET:
- LT(默认模式):水平触发,LT对于read操作比较简单,有read事件就读,读多读少都没有问题,但是write就不那么容易了,一般来说socket在空闲状态时发送缓冲区一定是不满的,假如fd一直在监控中,那么会一直通知写事件,不胜其烦。
- ET(高速模式):边缘触发,fd可读则返回可读事件,若开发者没有把所有数据读取完毕,epoll不会再次通知read事件,也就是说如果没有全部读取所有数据,那么导致epoll不会再通知该socket的read事件,事实上一直读完很容易做到。若发送缓冲区未满,epoll通知write事件,直到开发者填满发送缓冲区,epoll才会在下次发送缓冲区由满变成未满时通知write事件。ET模式下只有socket的状态发生变化时才会通知,也就是读取缓冲区由无数据到有数据时通知read事件,发送缓冲区由满变成未满通知write事件。
本文来自博客园,作者:难得,转载请注明原文链接:https://www.cnblogs.com/zhangbLearn/p/18829301

 浙公网安备 33010602011771号
浙公网安备 33010602011771号