MySQL基础架构
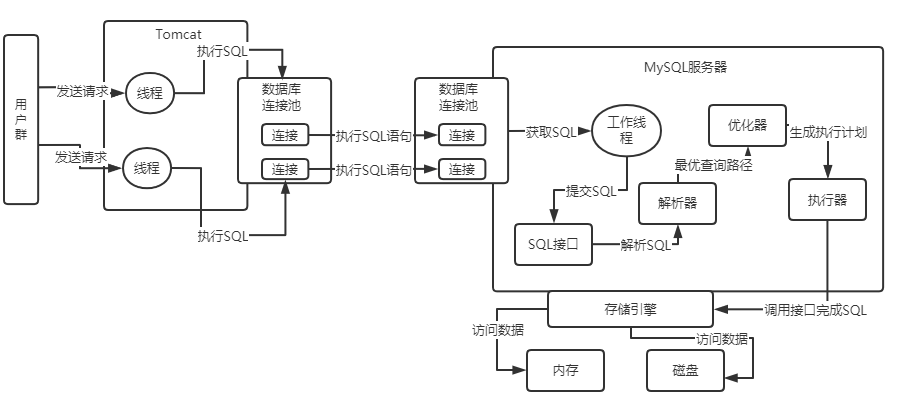
MySQL基础架构示意图:

主体可分为:Server层和存储引擎。Server层包括连接器、查询缓存、分析器、优化器、执行器等。所有跨存储引擎的功能都在这一层实现。存储引擎层负责数据的存储和提取,插件式架构。
应用与MySQL服务器大致交互过程:
- 连接器:
- 负责跟客户端建立连接,获取权限,维持和管理连接。通过TCP握手建立连接后,连接器开始认证用户身份。
- 每个客户端连接都会在服务器进程中拥有一个线程,这个连接的查询只会在这个单独的线程中执行,MySQL5.5之后,支持线程池插件,可以使用池中的少量线程来服务大量连接,不需要为每个新连接创建或销毁线程
- 查询缓存:
- MySQL拿到一个查询请求后,会先查询缓存,之前是否有执行该条语句。有则查询缓存中的结果返回客户端,没有则查询DB并将结果存入查询缓存后返回客户端。
- 大部分情况下不建议使用查询缓存:对表的更新会导致该表上所有查询缓存被清空,对于频繁有更新的库,查询缓存命中率非常低。对于静态表,很长时间更新一次的表,可以适当采用查询缓存
- 分析器:
- 当没有命中查询缓存,就开始真正的执行语句。MySQL首先要知道语句要做什么,因此会对SQL进行解析,先词法分析然后语法分析。在该阶段会判断语句是否正确,表是否存在,列是否存在等等。
- 优化器
- 语句分析完后,会进行优化器。作用是:重写查询、决定表的读取顺序、选择合适的索引。该过程结束后,这个语句的执行方案就确定了。
- 优化器不关心存储引擎,但存储引擎会影响优化器。优化器会请求存储引擎提供容量或某个具体操作的开销信息,以及表数据的统计信息等。
- 执行器:
- MySQL通过分析器知道了语句要做什么,通过优化器知道了怎么做,之后进入执行器开始执行语句。
- 开始执行时会判断用户对该表有没有执行相应操作的权限。如果没有,则返回没有权限,如果有权限,则打开表继续执行。此时执行器会根据表的引擎定义,去使用这个引擎提供的接口
SQL语句成本计算:
- 优化器选择索引会考虑:扫描行数(行数越少代表磁盘访问次数越少,消耗CPU越少)、是否使用临时表、是否排序
- 扫描行数判断:根据索引字段的区分度来进行统计和估算,一个索引上不同值的个数叫基数,基数越大区分度越好
- 索引基数获取:默认选择N个数据页(N可以设置),统计这些页面上的不同值,得到一个平均值,乘以索引页面数,得到该索引基数。数据表会持续更新,当变更数据行数超过1/M(M可以设置)时,自动触发重新做索引统计。
- 得到预估扫描行数后,普通索引会考虑回表代价,排序,临时表等,索引选择出现异常时,可以force index强制指定索引,或通过sql优化、删除误用索引、新建更适合的所以,诱导优化器进行索引选择。
MySQL物理数据存储
一行数据存储结构:变长字段的长度列表,null值列表,数据头(40个bit位),column01的值,column02的值,column0n的值...。除了字段值外,还拥有一些描述信息。
变长字段(VARCHAR)的存储:变长字段在底层磁盘文件是挨着存储的,同时变长字段的实际长度是不固定的,对于每个变长字段,读取的时候不知道实际长度,难以读取。因而将它的实际长度转为十六进制,逆序(建表时字段的上下顺序为正序)存到长度列表。
Null值的存储:直接按照null字符串存储浪费存储空间,null值字段会在NULL指列表中存储,通过二进制bit位来表示。1是NULL,0不是NULL,同样顺序是逆序。NULL列表一般是8个bit位的倍数,不足就高位补0。
读取一行磁盘数据:通过读取变长字段列表和NULL值列表,知道哪些变长字段是NULL,哪几个字段是NULL,不为NULL的变长字段的值长度,再根据这些信息从实际的列值存储区域,找到每个字段的值。
数据头结构:
- 头尾两个bit位是预留位,没有含义
- 1bit-delete_mask:标识数据是否删除,删除数据其实是先修改了这个bit位,而不是立马删除
- 1bit-min_rec_mask:B+树里每一层的非叶子节点里的最小值都有这个标记
- 4bit-n_owner:记录数
- 13bit-heap_no:当前这行数据在记录堆里的位置
- 3bit-record_type:当前数据行类型,0代表的是普通类型,1代表的是B+树非叶子节点,2代表的是最小值数据,3代表的是最大值数据
- 16bit-next_record:指向下一条数据的指针
读取过程:

以 "jack NULL m NULL xx_school"这行数据为例,真实存储大致如下所示:
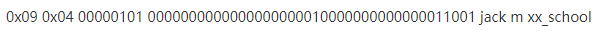
1、读数据时,先读取jack值,长度是4,就读4个长度的数据
2、第二个字段是NULL不用读,第三个定长直接读m
3、第四个字段NULL不用读,第五个变长长度是9,读出xx_school。
实际存储时,字符串会根据数据库指定字符集编码,进行编码后再存储。
隐藏字段:
- 实际存储一行数据时,在真实数据部分还会加入隐藏字段
- DB_ROW_ID:隐含的自增ID,没有指定主键和唯一索引时,内部自动加一个ROW_ID为主键
- DB_TRX_ID:创建这条记录/最后一次更新这条记录的事务ID
- DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本(存储于rollback segment里),用于事务回滚
行溢出:每一行数据都存放在一个数据页,默认大小为16KB,当一行数据的某个字段非常大,大小远超一个数据页大小了,实际存储时会在原来的页存储这行数据,在大字段中仅包含一份数据,同时包含一个20字节的指针,指向其他数据页,这些数据页用链表串联起来,共同存放这个超大大字段的数据。这个过程叫行溢出,这些串联的数据页被称为溢出页,在Buffer Pool中数据就可能存在于多个缓存页。
数据页结构:数据页包含文件头(38字节),数据页头(56字节),最小记录和最大记录(共26字节),多个数据行(不固定),空闲空间(不固定),数据页目录(不固定),文件尾部(8字节)。
插入数据就是在数据页插入一条数据行,同时消耗空闲空间容量,直到空闲空间满了,此时页就满了。
表空间:创建的表都有对应表空间,每个表空间都对应磁盘上的数据文件,表空间中有很多组数据区(extent),一组数据区是256个数据区。每个数据区包含64个数据页,共1MB。
数据页的操作:在CURD时,选择磁盘文件中的数据页,通过表空间定位到对应磁盘文件,找到一个extent组,找到一个extent,然后从里面找出一个数据页。
sql执行顺序:1、最先执行from tab;2、where语句是对条件加以限定;3、分组语句【group by…… having】;4、聚合函数;5、select语句;6、order by排序语句。
磁盘IO为何慢:读写磁头在磁盘扇区上读取或写入数据,一次磁盘IO的时间包含:寻道时间(3~15ms,一般是5ms)+旋转延迟时间(找到正确磁道后,把读写磁头移动到正确的位置上,取磁盘旋转周期的一般作为旋转延迟近似值,如7200转/分->120转/s,取一半1/240s=4.17ms)+数据传输(将数据从磁盘盘片读取或写入的时间,一般是0.几毫米,可以忽略不计),一次磁盘IO时间约在9~10ms。内存读取数据:读取一次数据一般在100ns,1ms=10^6ns
本文来自博客园,作者:难得,转载请注明原文链接:https://www.cnblogs.com/zhangbLearn/p/18829149

 浙公网安备 33010602011771号
浙公网安备 33010602011771号