
Open-Domain Targeted Sentiment Analysis via Span-Based Extraction and Classification基于Span的开放域情感提取与分类
摘要
面向开放域的情感分析旨在从句子中检测意见目标及其情感极性。之前的工作通常将此任务描述为序列标记问题。然而,该公式存在搜索空间大、情感不一致等问题。为了解决这些问题,我们提出了一个基于广度的抽取-再分类框架,在目标span边界的监督下,直接从句子中抽取多个观点目标,然后使用它们span表示对相应的极性进行分类。在此框架下,我们进一步研究了三种方法,即pipeline,joint, and collapsed models。在三个基准数据集上的实验表明,我们的方法始终优于序列标记基线。此外,我们发现,与其他两种模型相比,pipeline模型的性能最好。
1介绍
面向开放领域的情感分析是意见挖掘和情感分析的一项基本任务,与传统的句子级情感分析任务相比,这项任务需要检测句子中提到的目标实体及其情感极性,因此更具挑战性。以图1为例,目标是首先将“Windows 7”和“Vista”确定为意见目标,然后预测其相应的情绪等级。

通常,整个任务可以解耦为两个子任务。由于没有给出意见目标,我们需要首先从输入文本中检测目标。此子任务通常表示为目标提取,可通过序列标记方法解决,接下来,极性分类旨在预测提取的目标实体上的情感极性。虽然已经做出了很多努力来为这个子任务设计复杂的分类器,但它们都假设目标已经给出。
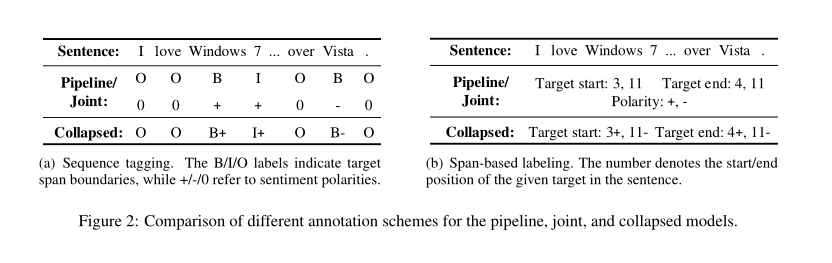
有些作品没有为每个子任务使用单独的模型,而是试图通过联合提取目标并预测他们的情绪,以更综合的方式解决任务,关键是用一组目标标记(例如,B,I,O)和一组极性标记(例如,+,-,0)标记每个单词,或者使用一组更折叠的标记(例如,B+,I-)直接指示目标情绪的边界,如图2(a)所示。因此,整个任务被描述为序列标记问题,并在相同的网络架构下使用pipeline,joint, and collapsed模型来解决。
序列标注方式存在的问题:
序列标注的组合是所有单词的幂集,搜索空间大,效率低。(在序列标注的时候是取每个token对应目标标签的取值中最大的一个,对于一个序列,序列标注的组合虽然是所有单词的幂集,但是并不是搜索所有的组合,而是取每个token对应标签最大的,将他们进行组合)
如果是多个单词组成的实体,每个单词判断极性时候忽略了整个实体的语义,无法保证多个单词组成的实体的情感一致。
然而,上述注释方案在目标提取和极性分类方面存在一些缺点。Lee等人(2016)表明,当使用BIO标签进行抽取式问答任务时,由于标签的组合性(所有句子单词的幂集),模型必须考虑巨大的搜索空间,因此效率较低。至于极性分类,序列标记方案由于两个原因而存在问题。首先,每个单词的目标极性忽略整个意见目标的语义。其次,正如Li et al.(2019)所述,由于目标词的预测极性可能不同,因此无法保证多词实体的情感一致性。例如,图2(a)中的单词“Windows”和“7”有可能由于单词级标记决策而具有不同的极性。
为了解决这些问题,我们提出了一种基于span的标签方案,用于开放域的情感分析,如图2(b)所示。关键的见解是用其广度边界和情感极性来注释每个意见目标。在这种注释下,我们引入了一种先提取后分类的框架,该框架首先使用启发式多跨度解码算法提取多个意见目标,然后使用相应的摘要跨度表示对其极性进行分类。这种方法的优点是提取的搜索空间可以随着句子长度线性减少,这远远小于标记方法。此外,由于极性是使用目标跨度表示确定的,因此该模型能够在进行预测之前考虑所有目标词,从而自然避免了情感不一致。
我们将BERT(Devlin et al.,2018)作为默认骨干网络,并探讨了两个研究问题。首先,我们对基于标记的模型和基于跨度的模型进行了详细的比较。其次,继之前的工作(Mitchell et al.,2013;Zhang et al.,2015)之后,我们比较了基于跨度的标记方案下的pipeline,joint, and collapsed模型。在三个基准数据集上的大量实验表明,我们的模型始终优于序列标记基线。此外,pipeline模型比joint模型和collapsed模型都有明显的改进。
2相关工作
除了句子级情感分析,要求检测开放领域中的句子涉及的实体的情感的目标级情感分析,也是一个重要的研究主题。
如§1所述,此任务通常分为两个子任务。第一种是目标提取,用于从输入句子中识别实体。传统上,条件随机场(CRF)(Lafferty et al.,2001)已被广泛探索。最近,许多工作集中于利用深度神经网络来解决这一任务,例如,使用CNN(Poria et al.,2016;Xu et al.,2018)、RNN(Liu et al.,2015;He et al.,2017)等。第二种是极性分类,假设给定了目标实体。最近的工作主要集中在利用各种神经结构(如LSTM,注意力机制,CNN,记忆网络)捕捉目标和句子之间的相互作用。
与其用单独的模型解决这两个子任务,更实用的方法是直接预测对实体的情绪,同时发现实体本身。具体而言,Mitchell等人(2013年)将整个任务描述为序列标记问题,并提议使用CRF和手工制作的语言特征。Zhang等人(2015年)进一步利用这些语言特征来增强神经CRF模型。最近,Li等人(2019)提出了一个统一模型,该模型包含两个堆叠的LSTM以及精心设计的组件(A unified model for opinion target extraction and target sentiment prediction. In Proceedings of AAAI.),用于保持情绪一致性和提高目标单词的检测。我们的工作与这些方法的不同之处在于,我们将此任务表述为跨度(SPAN)的提取,然后再进行分类。
拟议的基于广度的标签方案受到了机器理解和问答方面最新进展的启发(Seo等人,2017;Hu等人,2018),其中的任务是从文档中提取连续的文本跨度作为问题的答案。为了解决这一问题,Lee等人(2016)研究了几种预测策略,如BIO预测、边界预测,结果表明,预测答案的两个端点比标记方法更有益。Wang和Jiang(2017)探索了两种答案预测方法,即序列法和边界法,发现后者表现更好。我们的方法与这项工作相关。然而,与这些提取一个跨度作为最终答案的工作不同,我们的方法旨在动态输出一个或多个意见目标。
3提取然后分类的框架
我们建议使用基于跨度的标记方案,而不是将开放域目标情感分析任务表述为序列标记问题:给定一个长度为n的输入句子x=(x1,…,xn),目标列表T={t1,…,tm},其中目标数为m,每个目标ti用其开始位置、结束位置和情感极性进行注释。目标是从句子中找到所有目标,并预测它们的极性。
拟议框架的总体说明如图3所示。我们模型的基础是Bert模型,我们使用预先训练好的Transformer将单词嵌入到上下文化的标记表示中,首先使用多目标提取器从句子中提出多个候选目标(§3.2)。然后,设计了一个极性分类器,使用其摘要范围表示(§3.3)预测对每个提取的候选对象的情绪。我们在此框架下进一步研究了三种不同的方法,即pipeline,joint, and collapsed models
3.1Bert作为骨干网络
我们使用Transformers(BERT)的双向编码器表示(Devlin et al.,2018),这是一种经过预培训的双向变压器编码器,可在各种NLP任务中实现最先进的性能,作为我们的骨干网络。
我们首先使用30522词条词汇表对句子x进行标记,然后通过连接CLS标记,标记过的句子和SEP标记,然后对于输入句子中的每个token,通过对标记,segment和位置编码的求和把它转换到向量空间,然后得到了输入的编码 h表示隐藏单元的大小,就是字向量编码的维度。
h表示隐藏单元的大小,就是字向量编码的维度。
接下来,我们使用L层的Transformer变换器将输入嵌入转换成句子的上下文表示向量中 ,
,

3.2多目标提取器
多目标提取器旨在提出多个候选意见目标(图3(a))。
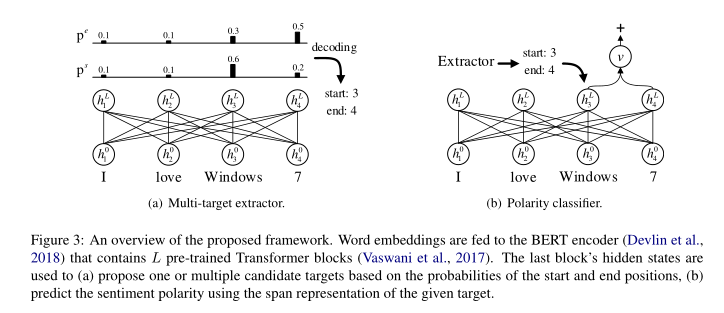
最后一个块的隐藏状态用于(a)基于开始和结束位置的概率提出一个或多个候选目标,(b)使用给定目标的跨度表示预测情感极性。
我们不是通过序列标记方法寻找目标,而是通过预测句子中目标的开始和结束位置来检测候选目标,如抽取式问答(Wang and Jiang,2017;Seo et al.,2017;Hu et al.,2018)所示。我们获得的非标准化得分以及起始位置的概率分布如下:
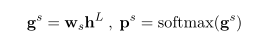
其中ws∈ Rh是一个可训练的权重向量。类似地,我们可以通过以下方式获得终点位置的概率及其置信度得分:
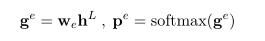
在训练期间,由于每个句子可能包含多个目标,我们为列表T中的所有目标实体标记范围边界。因此,我们可以获得一个向量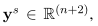 其中,每个元素ysi指示第i个标记是否开始一个目标,并获得另一个向量ye 是标签的终止位置。然后,我们将训练目标定义为两个预测概率上真实起始位置和结束位置的负对数概率之和,如下所示:
其中,每个元素ysi指示第i个标记是否开始一个目标,并获得另一个向量ye 是标签的终止位置。然后,我们将训练目标定义为两个预测概率上真实起始位置和结束位置的负对数概率之和,如下所示:
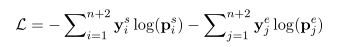
在推理时,先前的工作选择了跨度(k,l)(k≤ l) 以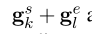 (g也就是上面的两个公式,起始位置和终止位置的置信度)的最大值作为最终预测。然而,这种解码方法不适用于多目标提取任务。此外,简单地根据两个分数相加来计算top-K跨度也不是最优的,因为多个候选人可能引用同一文本。图4给出了一个定性示例来说明这种现象。示例表明top-K中存在很多冗余跨距。
(g也就是上面的两个公式,起始位置和终止位置的置信度)的最大值作为最终预测。然而,这种解码方法不适用于多目标提取任务。此外,简单地根据两个分数相加来计算top-K跨度也不是最优的,因为多个候选人可能引用同一文本。图4给出了一个定性示例来说明这种现象。示例表明top-K中存在很多冗余跨距。

为了适应多目标场景,我们提出了一种启发式多跨度解码算法,如算法1所示。对于每个示例,首先从两个预测分数gs和ge(第2行)中选择topM指数,然后在结束位置不小于开始位置以及两个分数相加超过阈值γ(第3-8行)的约束条件下,将候选跨度(si,ej)(表示为rl)及其启发式正则化分数ul分别添加到列表R和U中。对于每个示例,首先从两个预测分数gs和ge(第2行)中选择topM指数,然后在结束位置不小于开始位置以及两个分数相加超过阈值γ(第3-8行)的约束条件下,将候选跨度(si,ej)(表示为rl)及其启发式正则化分数ul分别添加到列表R和U中。请注意,我们启发式地将ul计算为两个分数之和减去跨度长度(第6行),这对性能至关重要,因为目标通常是短实体。接下来,我们使用非最大值抑制算法修剪R中的冗余跨距,具体而言,我们从集合R中移除拥有最大分数ul的跨度rl,并将其添加到集合O(第10-11行)。我们还删除了与rl重叠的任何跨度rk,这是通过单词级别F1函数测量的(第12-14行)。对R中的其余跨度重复此过程,直到R为空或已提出top-K目标跨度(第9行)。

3.3极性分类
通常,极性分类是使用序列标记方法或复杂的神经网络来解决的,这些神经网络分别对目标和句子进行编码。相反,我们建议根据其广度边界总结上下文句子向量的目标表示,并使用前馈神经网络预测情感极性,如图3(b)所示。具体而言,给定目标跨度r,我们使用注意机制(Bahdanau et al.,2014)计算对应边界(si,ej)内标记的汇总向量v,类似于Lee et al.(2017)和He et al.(2018):
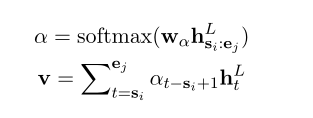
极性得分是通过应用两个线性变换获得的,中间有一个Tanh激活,并使用softmax函数进行归一化,以输出极性概率,如下所示:
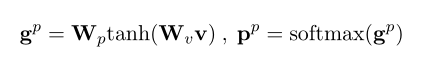
我们将预测概率上真实极性的负对数概率最小化为:
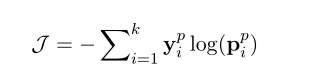
yp代表真实极性的独热标签,k代表了情感极性的个数。
在推理过程中,计算集合O中每个候选目标跨度的极性概率,选择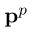 中的最大值。
中的最大值。
3.4模型变体
继Mitchell等人(2013年)之后;Zhang et al.(2015),我们研究了三种模型:
Pipeline model我们首先构建一个多目标提取器,其中专门使用BERT编码器。然后,使用第二骨干网络为极性分类器提供上下文句子向量。在推理过程中,将两个模型分别训练。
Joint model在该模型中,每个句子都被输入到一个共享的BERT骨干网络中,该骨干网络最终分支为两个兄弟输出层:一个用于提出多个候选目标,另一个用于预测每个提取目标上的情感极性。采用联合训练损失L+J对整个模型进行优化。推理过程与pipeline模型相同。
Collapsed model我们将目标跨度边界和情感极性结合到一个标签空间中。例如,图2(b)中的句子有一个正跨度(3+,4+)和一个负跨度(11-, 11-)然后,我们通过生成三组开始和结束位置的概率来修改多目标提取器,其中每一组对应于一个情绪类别(例如,对于积极目标,ps+和pe+)。然后,我们定义了三个目标,以针对每个极性进行优化。在推理过程中,对每组分数执行启发式多跨度解码算法,输出的三个集合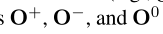 聚合为最终的预测。
聚合为最终的预测。
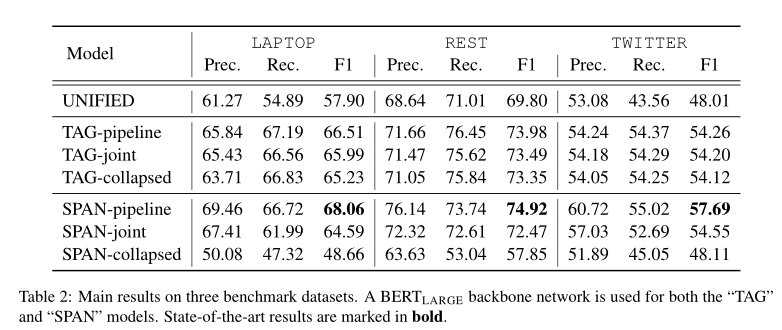
从表中可以获得两个主要观察结果。首先,尽管“TAG”基线已经优于以前的最佳方法(“统一”),但它们都被“SPAN”方法击败。与最佳标记方法相比,基于广度的最佳方法在三个数据集上的绝对增益分别为1.55%、0.94%和3.43%,表明了我们的提取-然后分类框架的有效性。其次,在基于跨度的方法中,跨度pipeline的性能最好,这与Mitchell等人(2013)的结果相似;Zhang等人(2015)。这表明目标提取和极性分类之间只有微弱的联系。SPAN collapsed方法的结果也支持这一结论,该方法在所有数据集中都会严重下降,这意味着将极性标签合并到目标跨度中并不能有效地解决这一任务。
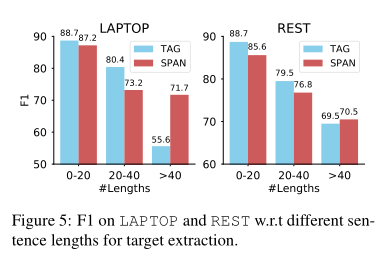
4.4目标提取的分析
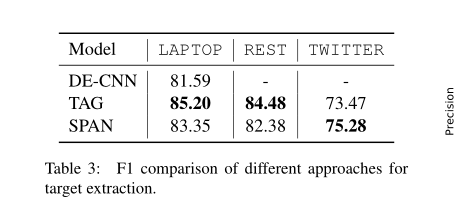
为了分析目标提取的性能,我们在三个数据集上运行了标记基线和多目标提取器,如表3所示。我们发现,BIO-tagger在笔记本电脑和REST上的性能优于我们的提取器。这一观察结果的一个可能原因是,这些数据集上输入句子的长度通常很小(例如,98%的句子剩余部分少于40个单词),这限制了标记者的搜索空间(所有句子单词的幂集)。因此,计算复杂度大大降低,这有利于标记方法。
为了证实上述假设,我们在图5中绘制了不同句子长度的F1分数。我们观察到,随着句子长度的增加,BIO-tagger的性能急剧下降,而我们的提取器对于长句更为健壮。在笔记本电脑和REST上,当长度超过40时,我们的提取器成功地将tagger分别超过16.1 F1和1.0 F1。上述结果表明,我们的抽取器更适合长句,因为它的搜索空间只随句子长度线性增加。
由于可以根据我们的提取器中的阈值γ来调整精度和查全率之间的权衡,因此我们进一步绘制了不同消融下的精度查全率曲线,以显示启发式多跨度解码算法的效果。如图6所示,NMS代表没有最大抑制,heuristics代表没有启发式搜索。
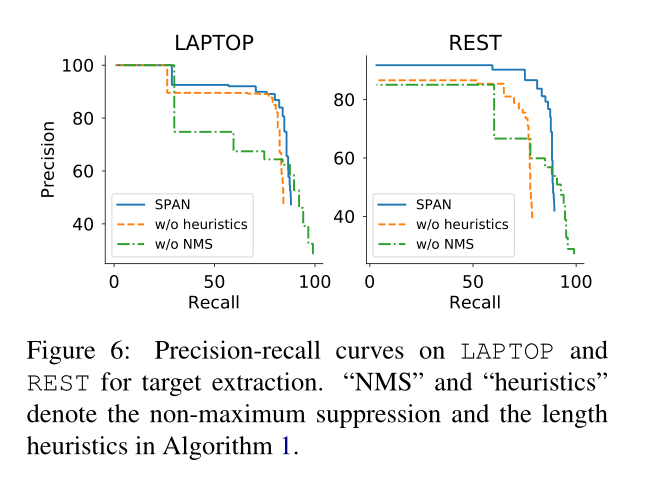
没有长度启发式会导致两个数据集的一致性能下降。通过抽样错误的预测,我们发现有许多目标彼此密切相关,如size,speed,portions,price等没有长度启发式的模型很可能将整个短语作为单个目标输出,因此是完全错误的。此外,删除非最大抑制(NMS)会导致性能显著下降,这表明删减引用相同文本的冗余跨度至关重要。
4.5情感极性分类分析
为了评估极性分类子任务,我们比较了跨级极性分类器与表5中基于CRF的标记器的性能。结果表明,我们的方法在三个数据集上实现了9.97%、8.15%和15.4%的绝对增益,显著优于标记基线,并大大超过了笔记本电脑上以前最先进的模型。相对于标记基线的巨大改进表明,使用整个跨度表示法检测情感比预测每个单词的极性更为有利,因为给定目标的语义已得到充分考虑。
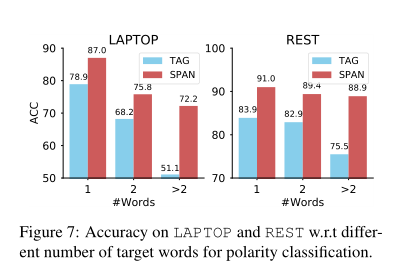
为了更深入地了解性能改进,我们在图7中绘制了两种方法相对于不同目标长度的精度。我们发现,在笔记本电脑和REST数据集上,随着字数的增加,跨级分类器的精度只会略有下降。然而,标记基线的性能随着目标的变长而显著降低。研究表明,对于多词目标实体,标记方法确实存在情感不一致问题。相反,基于跨度的方法可以自然地缓解这一问题,因为极性是通过考虑所有目标词来分类的。
4.6消融实验
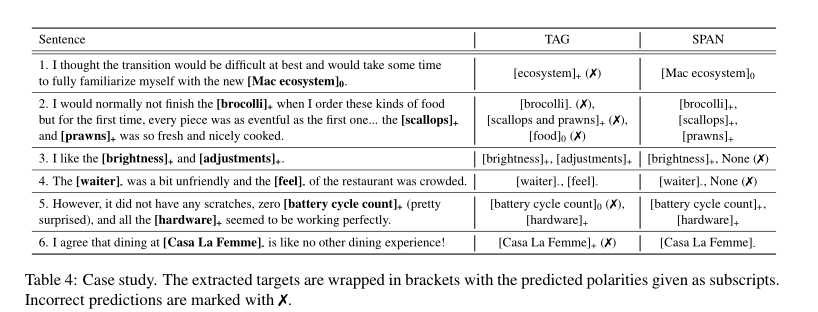
表4显示了从管道方法中抽取的一些定性案例。正如前两个例子中所观察到的,“标记”模型错误地预测了目标范围,要么遗漏了“Mac”一词,要么提出了跨两个目标的短语(“鳞片和对虾”)。其失败的一个可能原因是输入的句子相对较长,而标记方法在处理这些句子时效率较低。但是,对于较短的输入(例如,第三个和第四个示例),标记基线通常比我们的方法表现更好。我们发现,我们的方法有时可能无法提出目标实体(例如,(3)中的“调整”和(4)中的“感觉”),这是因为设置了相对较大的γ。因此,该模型只能做出谨慎而自信的预测。相比之下,标记方法不依赖于阈值,并且具有更高的召回率。例如,在第二个示例中,它还预测实体“食物”作为目标。此外,我们发现标记方法有时无法预测正确的情感类别,尤其是当目标由多个单词组成时(例如,(5)中的“电池循环计数”和(6)中的“Casa La Femme”),表明标记者无法有效地保持单词之间的情感一致性。然而,我们的极性分类器可以通过使用目标广度表示来预测情绪来避免此类问题。
5结论
我们重新研究了序列标记方法在开放域有针对性情感分析中的缺陷,并提出了一种提取然后分类的框架,该框架使用了基于广度的标记方案。该框架包含一个预先训练的变压器编码器作为骨干网络。在此基础上,我们设计了一个多目标提取器,使用启发式多跨度解码算法提出多个候选目标,并引入了一个极性分类器,该分类器使用每个候选目标的摘要跨度表示来预测对每个候选目标的情感。在三个基准数据集上,我们的方法明显优于序列标记基线以及以前最先进的方法。模型分析表明,主要性能改进来自于跨级极性分类器,而多目标分类器更适合长句。此外,我们发现pipeline model始终优于joint model和 collapsed model
模型采用了基于跨度的提取方式提取目标实体,发现这种方法对于长句子十分有效。对于从候选实体中选出目标实体采用了启发式多跨度解码算法,这种方法删除了相同文本的冗余跨度。预测目标实体的情感时将跨度内的单词进行汇聚,形成一个变量,然后预测目标实体的情感。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号