
jmeter 压测过程
测试策略
1、基准测试,获取无压力情况下,系统的平均响应时间;
2、采用持续并发的策略,获取系统的在不同压力下平均响应时间,TPS ;
3、在现有硬件资源下,获取到最高TPS;
4、在现有硬件资源下,持续较高TPS运行,验证系统的稳定性;
5、资源增加时,最大TPS是否可以线性增加;
6、混合交易,系统最大TPS比例;
7、发生故障时,系统响应处理;
怎么制定指标?
1、业务在19点~20点高峰值最大请求数=90000
2、算最大tps=90000/3600=25,tps每秒25
3、混合业务怎么算比例
A业务19点~20点,请求数90000,19点~20点,请求数90000,B业务19点~20点,请求数60000,C业务19点~20点,请求数10000,
A业务比例=90000/90000+60000+10000
4、最后定一个每个接口不超过1秒
这样指标就出来了
一、基准测试
|
用例编号 |
ZXW_ALI_NATIVE_01 |
名称 |
读接口测试 |
|
测试目的 |
获取无压力下,系统的平均响应时间 |
||
|
预置条件 |
1. 自学网环境就绪,单节点 2. 监控就绪 3. 脚本及测试数据、客户端压测机器就绪 4. 渠道mock挡板响应时间350ms~400 |
||
|
测试步骤 |
1. 设置并发数=1 2. 启动脚本并发,持续10分钟 3. 收集监控数据,获取平均响应时间、TPS等值 |
||
|
预期结果 |
1. 接口正常,各项性能资源消耗低 |
||
|
输出结果 |
1. 平均响应时间 2. 错误率 |
||
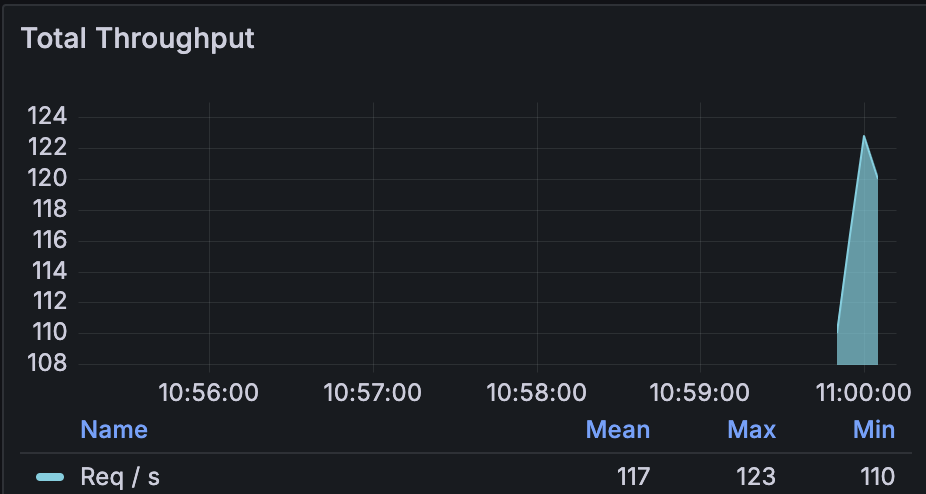
(2). 测试结果:
如图所示:平均响应时间: 9.25ms左右;

如图所示:平均tps吞吐: 117;

二、容量测试
在符合业务指标的同时,探寻承受压力的最大值。
|
用例编号 |
ZXW_ALI_NATIVE_02 |
名称 |
持续性测试 |
|
测试目的 |
采用持续加压并发的策略,获取系统的在不同容量下平均响应时间,TPS以及资源消耗 |
||
|
预置条件 |
1. 环境就绪(应用服务器为1台) 2. 监控就绪 3. 脚本及测试数据、客户端压测机器就绪 |
||
|
测试步骤 |
1. 设置并发 :持续加压,每隔1秒,新增10虚拟用户数; 2. 启动脚本并发,持续39秒 3. 收集监控数据,获取平均响应时间、TPS等值 tps: 测试学习,时间设置太短 |
||
|
预期结果 |
1. 交易正常,平均响应时间不超过1s |
||
|
输出结果 |
1. 每个并发数下的平均响应时间,TPS |
||
(2)测试结果
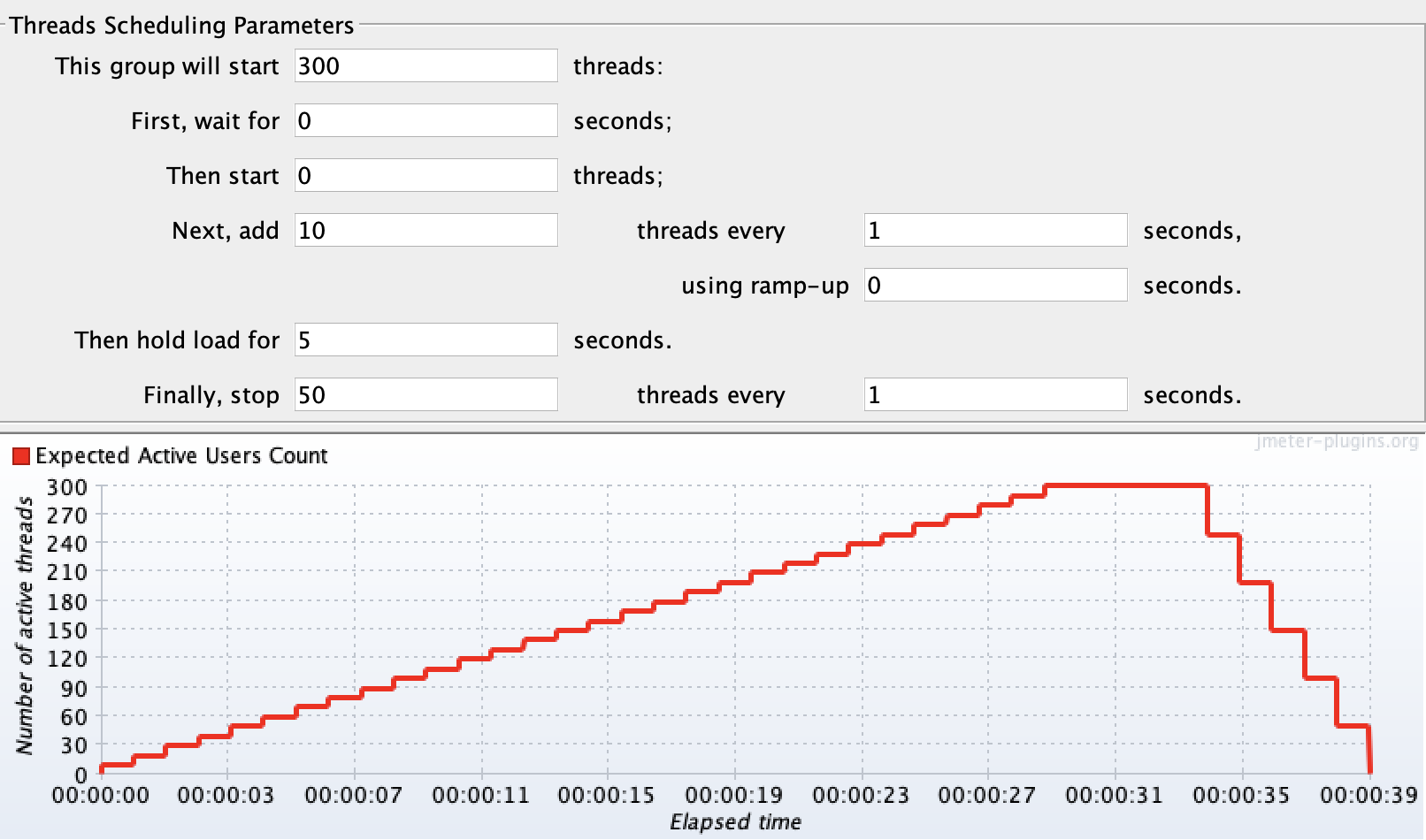
阶梯加压300个线程,每一秒增加10个,立马增加。最后持续5秒,每一秒下降50个线程

13秒的时候,出现错误率,此时tps=130, 人数150人,响应时间900以内。


结论:1台时,13秒出现错误,对应人数是150人左右,tps=130, 响应时间899ms。下图是资源占用情况。

内存到了6%左右,交换内存52%,cpu20%, 磁盘IO 0% 网络IO 1.22 MB/s。交换内存太大,一开始以为数据库连接池小、有慢查询、缓存太小,最后发现这个环境的已经被使用了
494M,一共1024.00M,占48%,52-48=4%, 交换内存只占到4%。合理。
展示最大连接数:SHOW VARIABLES LIKE 'max_connections';
展示使用的最大连接数: SHOW STATUS LIKE 'Max_used_connections';
查询慢查询:SHOW VARIABLES LIKE '%slow_query%';
设置慢查询打开:SET GLOBAL slow_query_log = 'ON';
查询慢查询时间:SHOW VARIABLES LIKE 'long_query_time'; SHOW GLOBAL VARIABLES LIKE 'long_query_time';
设置慢查询时间:SET GLOBAL long_query_time = 2
设置缓存大小:SET GLOBAL innodb_buffer_pool_size = 536870912; 默认134217728
检查缓冲池大小:SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
mac检测内存的:vm_stat 或者 sysctl vm.swapusage
三、稳定性测试
四、异常测试
1、网络断掉
2、数据库宕机
缓存是否生效,状态码返回500,限流降级策略是否生效
3、中间件宕机
从机是否正确运转,消费是否重复、消息是否丢失
五、jmeter 与locust 对比


from locust import HttpUser, TaskSet, task, between from locust import LoadTestShape class User(TaskSet): @task def test_search(self): self.client.get("/getALLMenu") class WebUser(HttpUser): host = "http://127.0.0.1:8000/" tasks = [User] wait_time = between(2, 7) # 用户等待时间 2~7 秒 class StepLoadShape(LoadTestShape): """ 阶梯负载配置: - duration: 从测试开始的总时间(秒) - users: 目标用户数 - spawn_rate: 必须 ≥ users(瞬时生成) """ stages = [ {"duration": 10, "users": 10, "spawn_rate": 10}, # 0-10秒:10用户 {"duration": 20, "users": 30, "spawn_rate": 30}, # 10-20秒:30用户 {"duration": 30, "users": 50, "spawn_rate": 50}, # 200-30秒:50用户 {"duration": 40, "users": 70, "spawn_rate": 70}, {"duration": 50, "users": 90, "spawn_rate": 90}, {"duration": 60, "users": 110, "spawn_rate": 110}, ] def tick(self): run_time = self.get_run_time() for stage in self.stages: if run_time < stage["duration"]: return (stage["users"], stage["spawn_rate"]) return None # 测试结束
启动:locust -f xingNeng2.py


核心差异原因
1. 架构设计
| 特性 | JMeter | Locust |
|---|---|---|
| 协议实现 | 基于Java线程(1线程=1用户) | 基于Python协程(1线程模拟数千用户) |
| 资源消耗 | 高内存(每个线程独立栈空间) | 低内存(协程轻量级切换) |
| 并发模型 | 阻塞式(受限于线程数) | 非阻塞式(异步IO) |
2. 负载生成方式
-
JMeter:
-
严格按线程数生成负载,每个线程模拟一个用户,上下文切换开销大。
-
在100用户时可能已接近机器性能瓶颈(如CPU调度或内存不足),导致响应时间升高。
-
-
Locust:
-
通过协程(gevent)实现高并发,150用户可能仅需少量OS线程。
-
但Python的GIL(全局解释器锁)可能导致CPU密集型任务性能下降。
-
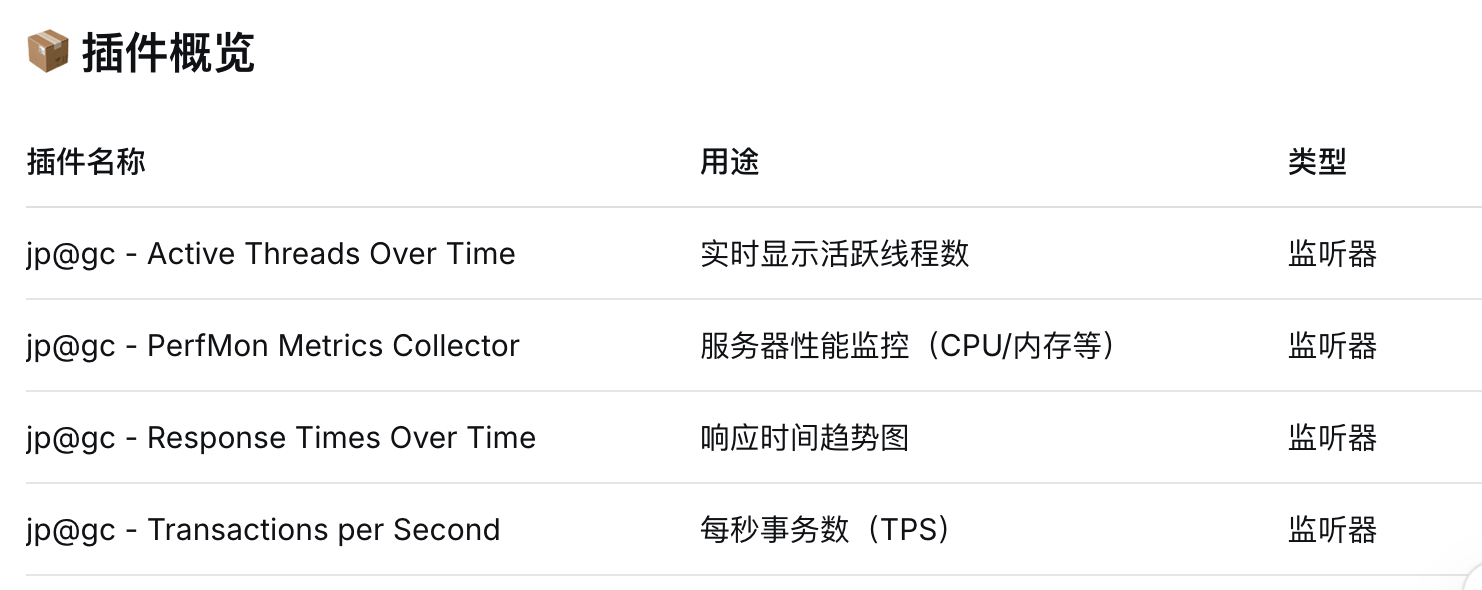
jemeter插件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号