
Python celery 简记
Celery 简介
Celery是一个异步任务的调度工具。
Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农。
在 Python 中定义 Celery 的时候,我们要引入 Broker,中文翻译过来就是“中间人”的意思,在这里 Broker 起到一个中间人的角色。在工头提出任务的时候,把所有的任务放到 Broker 里面,在 Broker 的另外一头,一群码农等着取出一个个任务准备着手做。
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的。所以我们要引入 Backend 来保存每次任务的结果。这个 Backend 有点像我们的 Broker,也是存储任务的信息用的,只不过这里存的是那些任务的返回结果。我们可以选择只让错误执行的任务返回结果到 Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery(芹菜)是一个异步任务队列/基于分布式消息传递的作业队列。它侧重于实时操作,但对调度支持也很好。Celery用于生产系统每天处理数以百万计的任务。Celery是用Python编写的,但该协议可以在任何语言实现。它也可以与其他语言通过webhooks实现。Celery建议的消息队列是RabbitMQ,但提供有限支持Redis, Beanstalk, MongoDB, CouchDB, 和数据库(使用SQLAlchemy的或Django的 ORM) 。Celery是易于集成Django, Pylons and Flask,使用 django-celery, celery-pylons and Flask-Celery 附加包即可。
Celery 介绍
在Celery中几个基本的概念,需要先了解下,不然不知道为什么要安装下面的东西。概念:Broker、Backend。
什么是broker?
broker是一个消息传输的中间件,可以理解为一个邮箱。每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息,进行对于的程序执行。好吧,这个邮箱可以看成是一个消息队列。其中Broker的中文意思是 经纪人 ,其实就是一开始说的 消息队列 ,用来发送和接受消息。这个Broker有几个方案可供选择:RabbitMQ (消息队列),Redis(缓存数据库),数据库(不推荐),等等
什么是backend?
通常程序发送的消息,发完就完了,可能都不知道对方时候接受了。为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果。Backend是在Celery的配置中的一个配置项 CELERY_RESULT_BACKEND ,作用是保存结果和状态,如果你需要跟踪任务的状态,那么需要设置这一项,可以是Database backend,也可以是Cache backend,具体可以参考这里: CELERY_RESULT_BACKEND 。
对于 brokers,官方推荐是 rabbitmq 和 redis,至于 backend,就是数据库。为了简单可以都使用 redis。
我们演示使用RabbitMQ作为Broker,用MySQL作为backend。
来一张图,这是在网上最多的一张Celery的图了,确实描述的非常好

Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis, MongoDB (experimental), Amazon SQS (experimental),CouchDB (experimental), SQLAlchemy (experimental),Django ORM (experimental), IronMQ
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis,memcached, mongodb,SQLAlchemy, Django ORM,Apache Cassandra, IronCache 等。
这里我先不去看它是如何存储的,就先选用redis来存储任务执行结果。
因为涉及到消息中间件(在Celery帮助文档中称呼为中间人<broker>),为了更好的去理解文档中的例子,可以安装两个中间件,一个是RabbitMQ,一个redis。
Celery 是一个强大的 分布式任务队列 的 异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。我们通常使用它来实现异步任务(async task)和定时任务(crontab)。我们需要一个消息队列来下发我们的任务。首先要有一个消息中间件,此处选择rabbitmq (也可选择 redis 或 Amazon Simple Queue Service(SQS)消息队列服务)。推荐 选择 rabbitmq 。使用RabbitMQ是官方特别推荐的方式,因此我也使用它作为我们的broker。它的架构组成如下图:
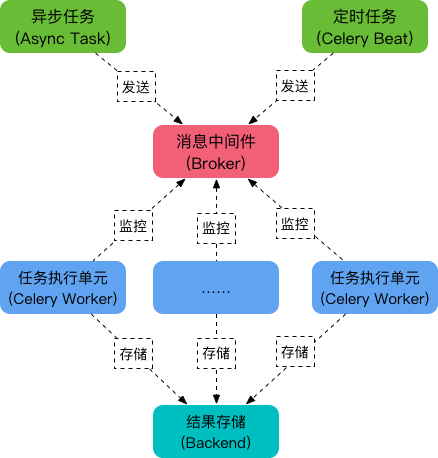
可以看到,Celery 主要包含以下几个模块:
-
任务模块 Task
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
-
消息中间件 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
-
任务执行单元 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
-
任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, redis 和 MongoDB 等。
根据 Celery的帮助文档 安装和设置RabbitMQ, 要使用 Celery,需要创建一个 RabbitMQ 用户、一个虚拟主机,并且允许这个用户访问这个虚拟主机。
$ sudo rabbitmqctl add_user forward password #创建了一个RabbitMQ用户,用户名为forward,密码是password
$ sudo rabbitmqctl add_vhost ubuntu #创建了一个虚拟主机,主机名为ubuntu
# 设置权限。允许用户forward访问虚拟主机ubuntu,因为RabbitMQ通过主机名来与节点通信
$ sudo rabbitmqctl set_permissions -p ubuntu forward ".*" ".*" ".*"
$ sudo rabbitmq-server # 启用RabbitMQ服务器
结果如下,成功运行:
安装Redis,它的安装比较简单
$ sudo pip install redis
然后进行简单的配置,只需要设置 Redis 数据库的位置:
BROKER_URL = 'redis://localhost:6379/0'
注意、URL的格式为:redis://:password@hostname:port/db_number
URL Scheme 后的所有字段都是可选的,并且默认为 localhost 的 6479 端口,使用数据库 0。
安装Celery,我是用标准的Python工具pip安装的,如果你喜欢使用虚拟环境安装可以先使用virtualenv创建一个自己的虚拟环境。如下:
$ sudo pip install celery
安装rabbitmq
官网安装方法:http://www.rabbitmq.com/install-windows.html
启动管理插件:sbin/rabbitmq-plugins enable rabbitmq_management
启动rabbitmq:sbin/rabbitmq-server -detached
rabbitmq已经启动,可以打开页面来看看
地址:http://localhost:15672/#/
用户名密码都是guest 。现在可以进来了,可以看到具体页面。 关于rabbitmq的配置,网上很多 自己去搜以下就ok了。
消息中间件有了,现在该来代码了,使用 celeby官网代码。
剩下两个都是Python的东西了,直接pip安装就好了,对于从来没有安装过mysql驱动的同学可能需要安装MySQL-python。安装完成之后,启动服务: $ rabbitmq-server[回车]。启动后不要关闭窗口, 下面操作新建窗口(Tab)。
开始使用 Celery
使用celery包含三个方面:1. 定义任务函数。2. 运行celery服务。3. 客户应用程序的调用。
创建一个文件 tasks.py输入下列代码:
from celery import Celery
broker = 'redis://127.0.0.1:6379/5'
backend = 'redis://127.0.0.1:6379/6'
app = Celery('tasks', broker=broker, backend=backend)
@app.task
def add(x, y):
return x + y
上述代码导入了celery,然后创建了celery 实例 app,实例化的过程中指定了任务名tasks(和文件名一致),传入了broker和backend。然后创建了一个任务函数add。下面启动celery服务。在当前命令行终端运行(分别在 env1 和 env2 下执行):
celery -A tasks worker --loglevel=info
目录结构 (celery -A tasks worker --loglevel=info 这条命令当前工作目录必须和 tasks.py 所在的目录相同。即 进入tasks.py所在目录执行这条命令。)
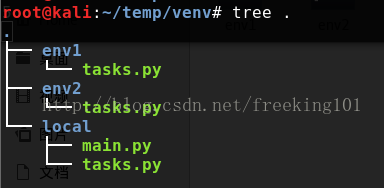
使用 python 虚拟环境 模拟两个不同的 主机。
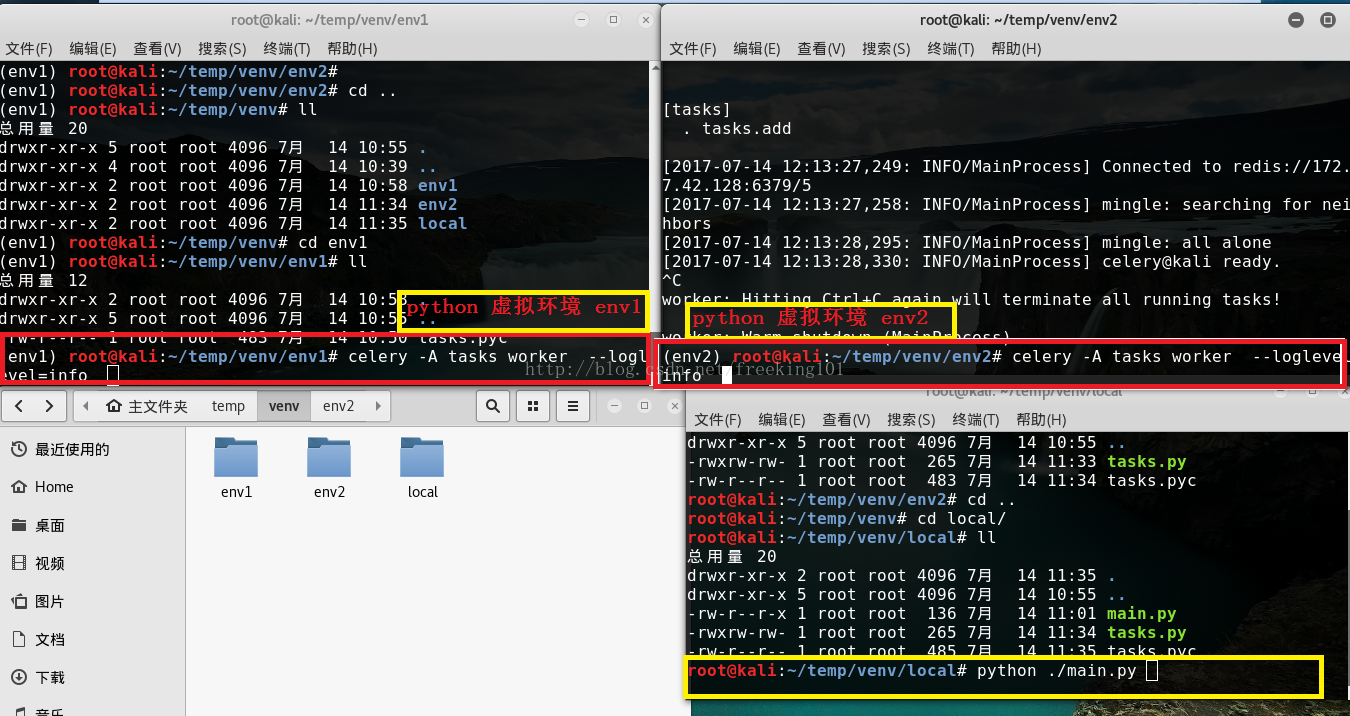
此时会看见一对输出。包括注册的任务啦。
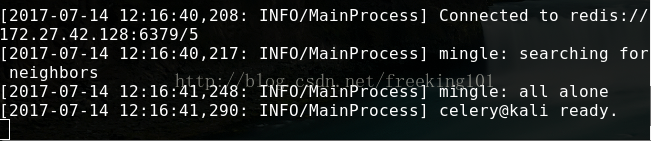
交互式客户端程序调用方法
打开一个命令行,进入Python环境。
In [0]:from tasks import add
In [1]: r = add.delay(2, 2)
In [2]: add.delay(2, 2)
Out[2]: <AsyncResult: 6fdb0629-4beb-4eb7-be47-f22be1395e1d>
In [3]: r = add.delay(3, 3)
In [4]: r.re
r.ready r.result r.revoke
In [4]: r.ready()
Out[4]: True
In [6]: r.result
Out[6]: 6
In [7]: r.get()
Out[7]: 6
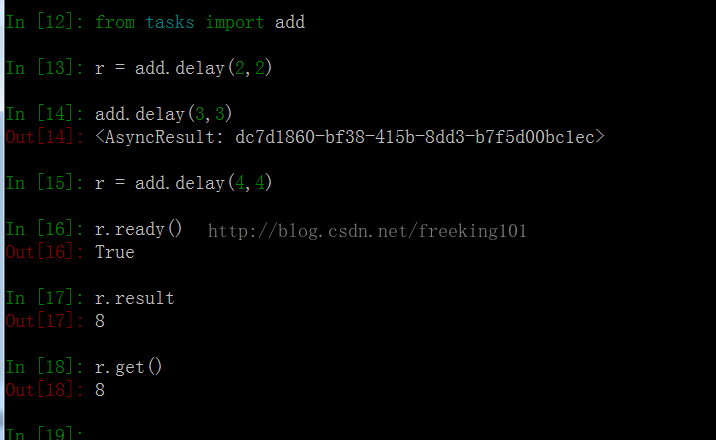
调用 delay 函数即可启动 add 这个任务。这个函数的效果是发送一条消息到broker中去,这个消息包括要执行的函数、函数的参数以及其他信息,具体的可以看 Celery官方文档。这个时候 worker 会等待 broker 中的消息,一旦收到消息就会立刻执行消息。
启动了一个任务之后,可以看到之前启动的worker已经开始执行任务了。

现在是在python环境中调用的add函数,实际上通常在应用程序中调用这个方法。
注意:如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果。因此,实际使用中,不需要把结果赋值。
应用程序中调用方法
新建一个 main.py 文件 代码如下:
from tasks import add
r = add.delay(2, 2)
r = add.delay(3, 3)
print r.ready()
print r.result
print r.get()
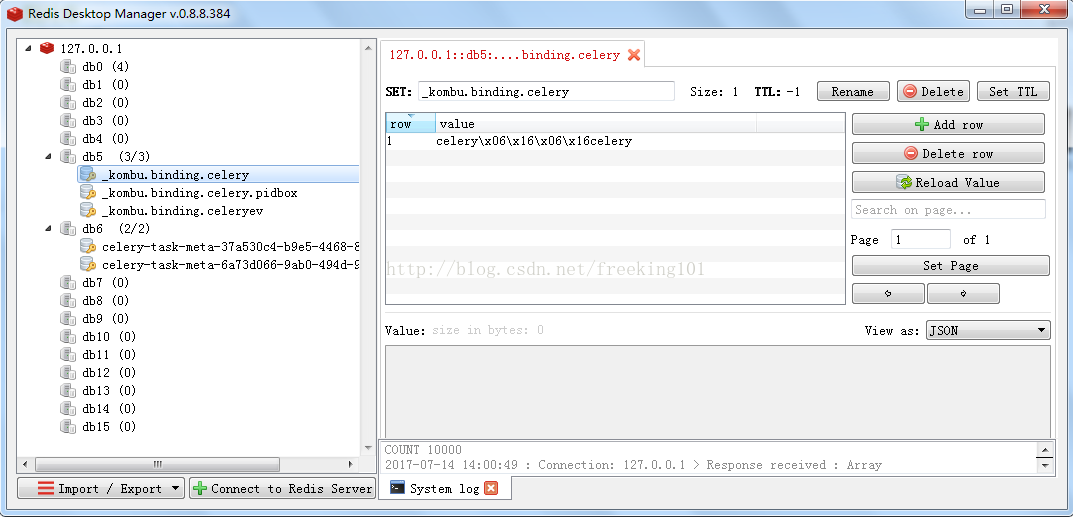
在celery命令行可以看见celery执行的日志。打开 backend的redis,也可以看见celery执行的信息。
使用 Redis Desktop Manager 查看 Redis 数据库内容如图:
使用配置文件
Celery 的配置比较多,可以在 官方配置文档:http://docs.celeryproject.org/en/latest/userguide/configuration.html 查询每个配置项的含义。
上述的使用是简单的配置,下面介绍一个更健壮的方式来使用celery。首先创建一个python包,celery服务,姑且命名为proj。目录文件如下:
☁ proj tree
.
├── __init__.py
├── celery.py # 创建 celery 实例
├── config.py # 配置文件
└── tasks.py # 任务函数
首先是 celery.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from celery import Celery
app = Celery('proj', include=['proj.tasks'])
app.config_from_object('proj.config')
if __name__ == '__main__':
app.start()
这一次创建 app,并没有直接指定 broker 和 backend。而是在配置文件中。
config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
剩下的就是tasks.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from proj.celery import app
@app.task
def add(x, y):
return x + y
使用方法也很简单,在 proj 的同一级目录执行 celery:
celery -A proj worker -l info
现在使用任务也很简单,直接在客户端代码调用 proj.tasks 里的函数即可。
指定 路由 到的 队列
Celery的官方文档 。先看代码(tasks.py):
from celery import Celery
app = Celery()
app.config_from_object("celeryconfig")
@app.task
def taskA(x,y):
return x + y
@app.task
def taskB(x,y,z):
return x + y + z
@app.task
def add(x,y):
return x + y
上面的tasks.py中,首先定义了一个Celery对象,然后用celeryconfig.py对celery对象进行设置,之后再分别定义了三个task,分别是taskA,taskB和add。接下来看一下celeryconfig.py 文件
from kombu import Exchange,Queue
BROKER_URL = "redis://10.32.105.227:6379/0" CELERY_RESULT_BACKEND = "redis://10.32.105.227:6379/0"
CELERY_QUEUES = (
Queue("default",Exchange("default"),routing_key="default"),
Queue("for_task_A",Exchange("for_task_A"),routing_key="task_a"),
Queue("for_task_B",Exchange("for_task_B"),routing_key="task_a")
)
CELERY_ROUTES = {
'tasks.taskA':{"queue":"for_task_A","routing_key":"task_a"},
'tasks.taskB":{"queue":"for_task_B","routing_key:"task_b"}
}
在 celeryconfig.py 文件中,首先设置了brokel以及result_backend,接下来定义了三个Message Queue,并且指明了Queue对应的Exchange(当使用Redis作为broker时,Exchange的名字必须和Queue的名字一样)以及routing_key的值。
现在在一台主机上面启动一个worker,这个worker只执行for_task_A队列中的消息,这是通过在启动worker是使用-Q Queue_Name参数指定的。
celery -A tasks worker -l info -n worker.%h -Q for_task_A
然后到另一台主机上面执行taskA任务。首先 切换当前目录到代码所在的工程下,启动python,执行下面代码启动taskA:
from tasks import *
task_A_re = taskA.delay(100,200)
执行完上面的代码之后,task_A消息会被立即发送到for_task_A队列中去。此时已经启动的worker.atsgxxx 会立即执行taskA任务。
重复上面的过程,在另外一台机器上启动一个worker专门执行for_task_B中的任务。修改上一步骤的代码,把 taskA 改成 taskB 并执行。
from tasks import *
task_B_re = taskB.delay(100,200)
在上面的 tasks.py 文件中还定义了add任务,但是在celeryconfig.py文件中没有指定这个任务route到那个Queue中去执行,此时执行add任务的时候,add会route到Celery默认的名字叫做celery的队列中去。
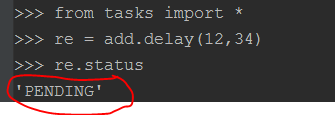
因为这个消息没有在celeryconfig.py文件中指定应该route到哪一个Queue中,所以会被发送到默认的名字为celery的Queue中,但是我们还没有启动worker执行celery中的任务。接下来我们在启动一个worker执行celery队列中的任务。
celery -A tasks worker -l info -n worker.%h -Q celery
然后再查看add的状态,会发现状态由PENDING变成了SUCCESS。
Scheduler ( 定时任务,周期性任务 )
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
一种常见的需求是每隔一段时间执行一个任务。
在celery中执行定时任务非常简单,只需要设置celery对象的CELERYBEAT_SCHEDULE属性即可。
配置如下
config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
CELERY_TIMEZONE = 'Asia/Shanghai'
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add-every-30-seconds': {
'task': 'proj.tasks.add',
'schedule': timedelta(seconds=30),
'args': (16, 16)
},
}
注意配置文件需要指定时区。这段代码表示每隔30秒执行 add 函数。一旦使用了 scheduler, 启动 celery需要加上-B 参数。
celery -A proj worker -B -l info
设置多个定时任务
CELERY_TIMEZONE = 'UTC'
CELERYBEAT_SCHEDULE = {
'taskA_schedule' : {
'task':'tasks.taskA',
'schedule':20,
'args':(5,6)
},
'taskB_scheduler' : {
'task':"tasks.taskB",
"schedule":200,
"args":(10,20,30)
},
'add_schedule': {
"task":"tasks.add",
"schedule":10,
"args":(1,2)
},
}
定义3个定时任务,即每隔20s执行taskA任务,参数为(5,6),每隔200s执行taskB任务,参数为(10,20,30),每隔10s执行add任务,参数为(1,2).通过下列命令启动一个定时任务: celery -A tasks beat。使用 beat 参数即可启动定时任务。
crontab
计划任务当然也可以用crontab实现,celery也有crontab模式。修改 config.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
CELERY_TIMEZONE = 'Asia/Shanghai'
from celery.schedules import crontab
CELERYBEAT_SCHEDULE = {
# Executes every Monday morning at 7:30 A.M
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}
scheduler的切分度很细,可以精确到秒。crontab模式就不用说了。
当然celery还有更高级的用法,比如 多个机器 使用,启用多个 worker并发处理 等。
发送任务到队列中
apply_async(args[, kwargs[, …]])、delay(*args, **kwargs) :http://docs.celeryproject.org/en/master/userguide/calling.html
send_task :http://docs.celeryproject.org/en/master/reference/celery.html#celery.Celery.send_task
from celery import Celery
celery = Celery()
celery.config_from_object('celeryconfig')
send_task('tasks.test1', args=[hotplay_id, start_dt, end_dt], queue='hotplay_jy_queue')
Celery 监控 和 管理 以及 命令帮助
输入 celery -h 可以看到 celery 的命令和帮助
更详细的帮助可以看官方文档:http://docs.celeryproject.org/en/master/userguide/monitoring.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号