
[NeurlPS2023]How Re-sampling Helps for Long-Tail Learning
这篇文章作者写得非常详细,读起来非常舒适。
Contribution:
- 在long-tailed data中,re-sampling不一定有效。
- re-sampling的失败可能是对于不相关的context过拟合导致的,作者设计了实验论证了这一假说。
- 在single-stage的框架下,作者提出了上下文转换增强(contextual transformation augmentation)解决不相关上下文。
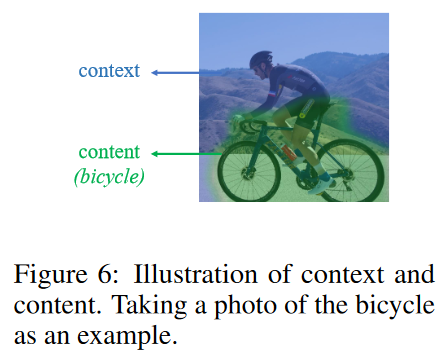
上下文(context)与主体(context)的关系。
从实验引入动机
探索Re-sampling的效果
Re-sampling能学到有区分的表征
在小数据集:MNIST-LT, Fashion-LT;中数据集:CIFAR100-LT;大数据集:ImageNet-LT比较三种方法:
- Cross-Entropy(CE):使用uniform sampling。
- cRT(classifier Re-Training):使用uniform sampling学习表征,再使用class-balanced re-sampling微调分类器。
- Class-Balanced Re-Sampling (CB-RS):整个过程使用class-balanced re-sampling。
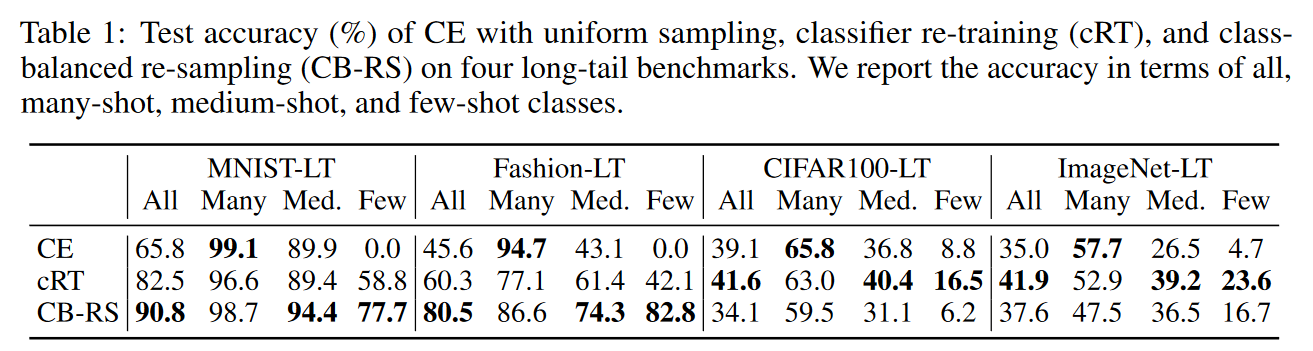
根据实验可观察到:
- CE和cRT使用相同的表征,但cRT精度更高,因此,re-sampling可以帮助分类器学习。
- 在小数据集上,CB-RS远超cRT,且分类器学习阶段两者均使用class-balanced re-sampling,可认为:对比uniform sampling, re-sampling可以帮助(小数据集上的)表征学习。

进一步探索re-sampling的效果:在中等数据集上可视化两种sampling的表征,发现对于uniform sampling,表征空间被head classes占据,而class-balanced re-sampling的表征更有区分性。
这说明:class-balanced re-sampling可以帮助表征学习。
Re-sampling对不相关上下文很敏感
观察Table 1,可以看到在中大数据集上CB-RS的表现不佳。这是因为小数据集上,图片和标签有着更高的语义相关性,而CIFAR和ImageNet包含了更复杂的上下文。作者假设:re-sampling对训练样本的上下文敏感。
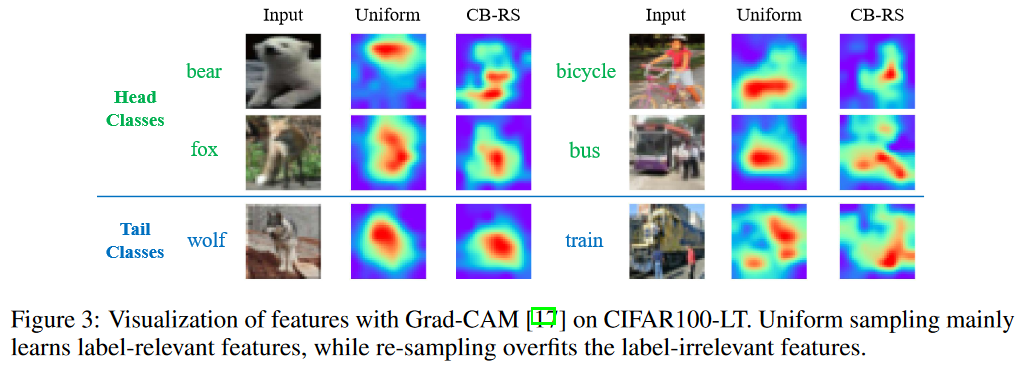
观察上图Grad-CAM可视化:
- 使用uniform sampler,模型能区分head classes样本的context。
- 使用CB-RS,模型往往会过拟合来自过采样tail-classes数据的无关context,这会意外地影响头类的表示。例如,在动物图片中,re-sampling会关注动物的姿势而不是外貌;对于不同的车,re-sampling会被周围的人所影响。
为了进一步验证context对re-sampling的影响,作者对MNIST-LT数据集进行改变:
- head classes 加入了(10种)不同颜色表示丰富的context。
- 相同的(10种内的1种)颜色被加入tail classes样本
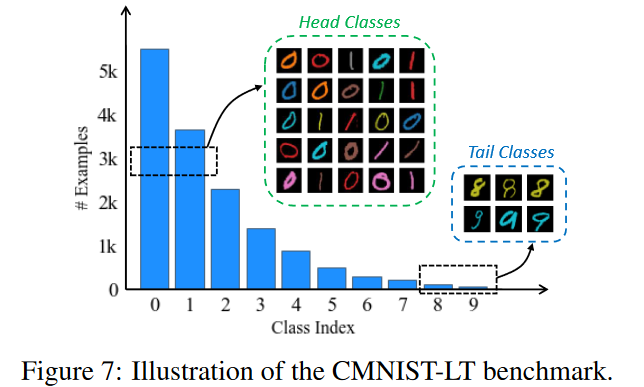
然后还是比较三种训练策略:
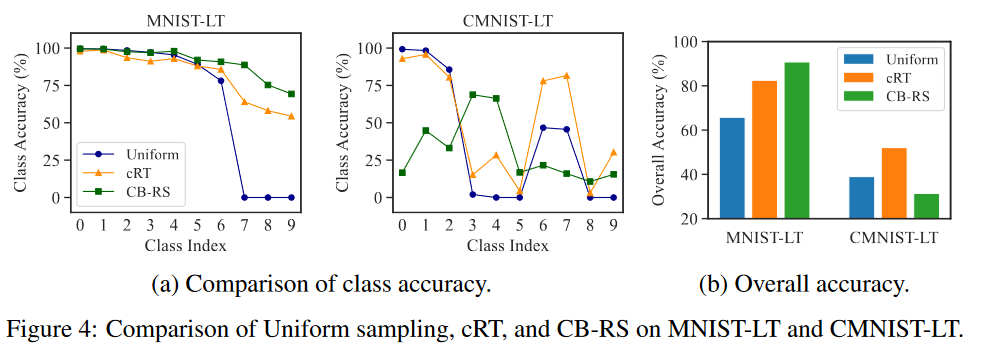
结果表明在MNIST-LT兼顾head classes和tail classes表现得CB-RS,在CMNIST-LB比使用uniform sampling的表征学习的cRT要差,这进一步说明无关context对re-sampling的影响。
但re-sampling的失败并不意味着re-sampling不适用于long-tailed数据,而是需要解决不相关上下文的问题。
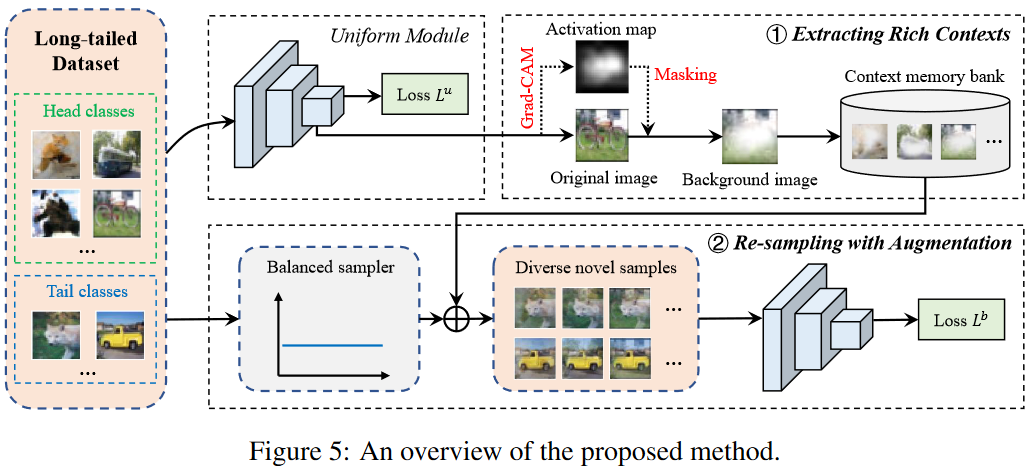
Method
用其他图片的context丰富tail classes图片,避免Re-sampling带来的过拟合。
uniform module
Step 1挑选充分学习的样本,即$p(y=y_{i}\mid x_{i},\phi,f^{u})\geq\delta \(,这里模型\)f^u\(使用uniform sampling训练,\)\delta$表示概率阈值。概率由Softmax计算得到。
\(z_i^u\)表示logits,\(z_i^u=[z_{i,1}^u,\ldots,z_{i,K}^u]=f^u(x_i)\)
Step 2用现有的技术Grad-CAM裁出context:对于图片\({\bm x}_i\)找到它的类激活图\(\mathrm{CAM}({\bm x}_i\mid f^u)\),以及它的背景\(M_i=1-\mathrm{CAM}(\boldsymbol{x}_i\mid f^u)\)。
\(M_i\)的shape与\({\bm x}_i\)相同,取值区间为\([0,1]\),区别于二值掩码,保留float值能留下更多信息。图片\({\bm x}_i\)和得到的背景\(M_i\)将被存入first-in-first-out队列Q(容量V被设置为batch size的大小)。\(M_i\odot {\bm x}_i\)表示该图片的背景。
对于这一模块(称为uniform module)的训练使用交叉熵损失函数:
balanced re-sampling module
伪代码里提到了 a class-balanced dataset \(\tilde{\mathcal{D}}\),其实是使用Class Aware Sampler保证每个类的样本采样数一致,做到类似类平衡的数据集的效果。
用Class Aware Sampler采样\(\tilde{\bm x}\),从队列Q种取出\(\check{\check{\bm x}}_i\)和它的背景\(\check{M}_i\),然后三者融合,得到新的\(\tilde{\bm x}_i\):
区别于mixup,由于这里只是使用了背景,所以不需要改变targets
为了节省计算特征提取部分,使用一个共享的backbone,分类器\(f^u,f^b\)分别使用对应的损失函数\(\ell^u,\ell^b\)进行训练(在代码中,三者均为resnet)。
最后的损失韩函数:

Experiments
对比了Re-sampling, Re-weighting(blue);Head-to-tail 迁移学习方法(green);数据增强方法(red):
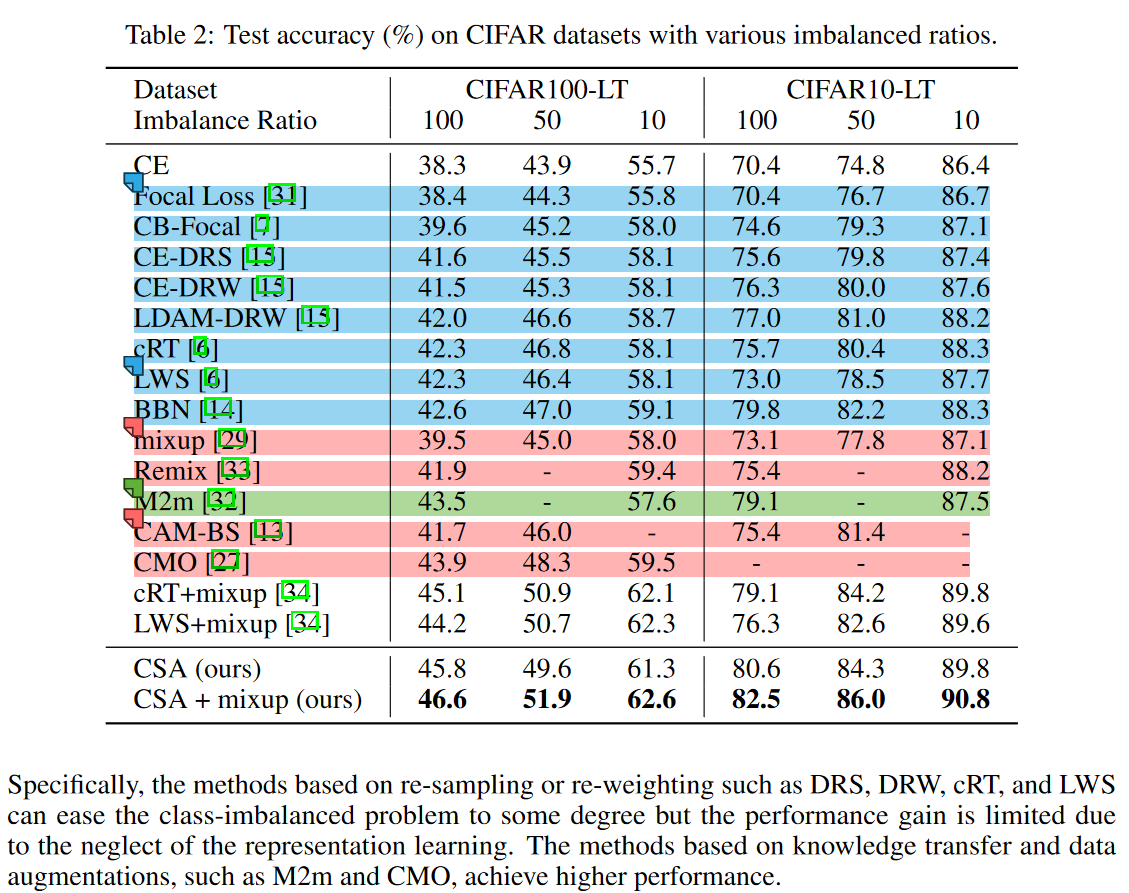
这里作者在文中提到两种迁移学习的方法:OLTR,FSA,但表中并没有它们,而这两篇的论文也没有相同设置下的数据(FSA用的是resnet34)。作者的方法并不SOTA,在大部分设置下都不如MiSLAS。
参考文献
- Shi, Jiang-Xin, et al. "How Re-sampling Helps for Long-Tail Learning?." Advances in Neural Information Processing Systems 36 (2023).
