
When Noisy Labels Meet Long Tail Dilemmas A Representation Calibration Method
用自监督学习MoCO提取表征,然后分布校准(与tailed class 相似的head classes去校准tailed class的分布)。没有开源,没有创新。
Introduction
作者考虑了数据集常见的两个问题:1、部分数据被错误得标注;2、数据呈长尾分布。之前涌现了很多工作分别针对这两个问题,但当两者同时存在,它们不能很好的工作。
专门针对噪声标签的方法,总是依赖于一些假设,但这些假设在long-tailed上不一定成立。例如利用memorization effect也就是通过损失大小判断noisy label,但对于tail classes,noisy label与clean label展示的损失相近。受tail classes的分布影响无法得到准确的噪声转换矩阵。
处理long-tailed数据的方法,对于带噪声标签的学习能力较弱。re-sampling 和 re-weighting受noisy label的影响会导致错误标签的积累。
目前同时考虑noisy label 和 long-tailed 的方法可以分为两类:
- 在tail classes 上区分clean label 和 noisy label,然后进行后续操作。但用于区分的表征来自于深度神经网络,而深度神经网络又是在noisy long-tailed数据上训练的,因此并不容易区分noisy label。
- 用一种统一的框架去处理noisy label 和 long-tailed。这种方式基于强假设,如部分数据具有相同的偶然不确定性,但这在实践中很难检验。
但是作者还是以样本表征服从混合高斯分布为假设。
Method
用对比学习增强表征
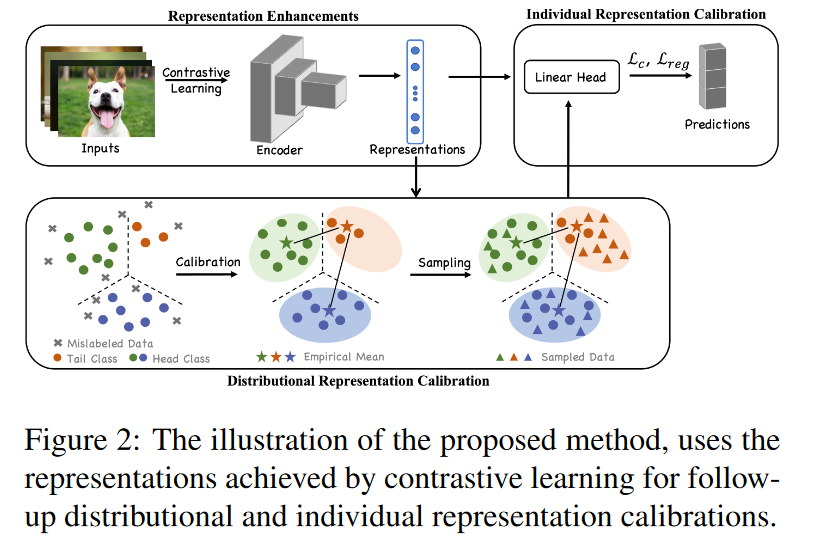
具体实现: 作者照搬了MoCo的Encoder,输入\({\bm x}\)随机进行两次数据增强得到\({\bm x}^q,\ {\bm x}^k\)分别使用query encoder\(f(\cdot)\)和key encoder\(f'(\cdot)\)得到表征\({\bm z}^q=f(\boldsymbol{x}^{q}),\ {\bm z}^k=f^{\prime}({\bm x}^k)\)。然后用投影头(2-layer MLP)得到低维嵌入\(\hat{\bm z}^q,\ \hat{\bm z}^k\)。对于输入\({\bm x}_i\)损失函数如下:
基于获取的表征,执行两种校准策略:分布/个体表征校准。分布表征校准旨在恢复数据损坏前的表征分布。假设每个类的实例服从多元高斯分布,这与之前的假设相比更加合理(这在其他工作中得到证明)。
分布表征校准
获取的表征存在聚类效应,可以在类的层面上进行多元高斯建模。具体来说,根据表征\(z\)使用局部异常值(LOF)算法检测异常值并移除。剩余的第k的类的clean data表示为\(\tilde{\mathcal{S}}_k^{\prime}=\{(z_i,\tilde{y_i})\}_{i=1}^{|\tilde{\mathcal{S}}_k^{\prime}|}\mathrm{~with~}|\tilde{\mathcal{S}_k^{\prime}}|<n_k\),多元高斯分布表示为
由于tail classes数据较少,不足以建立robust的多元高斯分布。受[2]的启发,相似的类具有相似的均值和方差,可以互相借用。而在这里,可以从head classes中借用信息。
- \(\mathcal{B}_{k}\)第k个tail class与head classes(\(\mathcal{G}_h\))均值的L2范数集合。
- \(\mathcal{C}_k^q\),表示\(\mathcal{B}_{k}\)前q个值最小(最接近)head classes的索引集合。
然后校准tail classes的均值和方差:
\(\omega_{c}^{k}\)表示使用head class的c的统计数据对 tail class的 k的校准。与k更相似的头部类将被赋予较小的权重。此外\(\gamma\)为从head classes统计的置信度。\({\bm 1}\in\mathbb{R}^{m\times m}\)为全1矩阵。\(\alpha\in\mathbb{R}^+\)为超参数控制分布程度。
恢复的分布接近干净数据的表示分布,因此使用这些采样数据点进行训练可以使分类器更加可靠。此外通过控制采样的数据点,可以使训练数据更平衡,有助于泛化。
个体表征校准
为了进一步增强robust,首先引入正则化方法,用L2范数限制backbone学到的表征与对比学习学到的表征:
然后引入mixup增强交叉熵损失函数的输入输出\(\mathcal{L}_c(\boldsymbol{x}_{i,j},\tilde{y}_{i,j}).\)最后的损失函数定义为:
\(\beta\)为超参数。整体伪代码如下:

参考文献
- Zhang, Manyi, et al. "When noisy labels meet long tail dilemmas: A representation calibration method." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
- Yang, Shuo, Lu Liu, and Min Xu. "Free Lunch for Few-shot Learning: Distribution Calibration." International Conference on Learning Representations. 2021.
