BUAA-OO-第二单元(多线程电梯调度)总结
一. 架构设计
三次作业的基本架构如下:
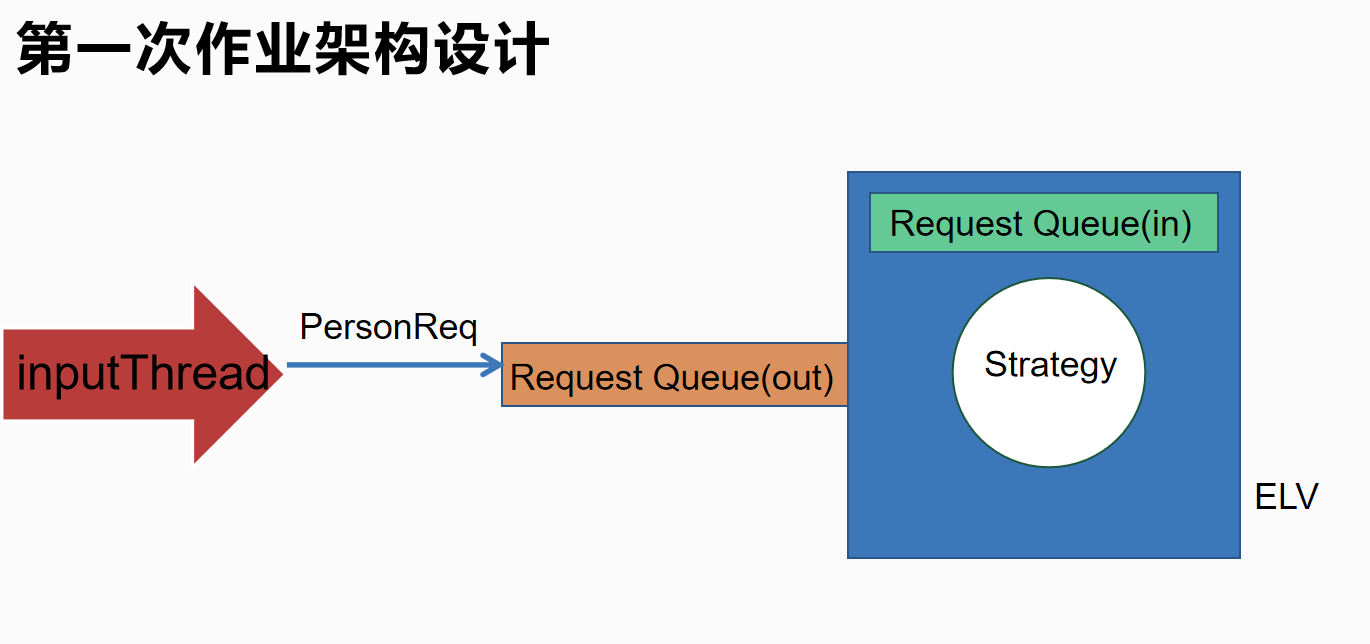
第一次作业设计了两个线程,input线程接受请求,并将请求放入外部请求队列;Elv线程通过内部的Strategy方法,考虑到到达模式的实际情况,根据内外的请求运行。
第二次作业一共设计了两个方案,分布式版和集中式版。
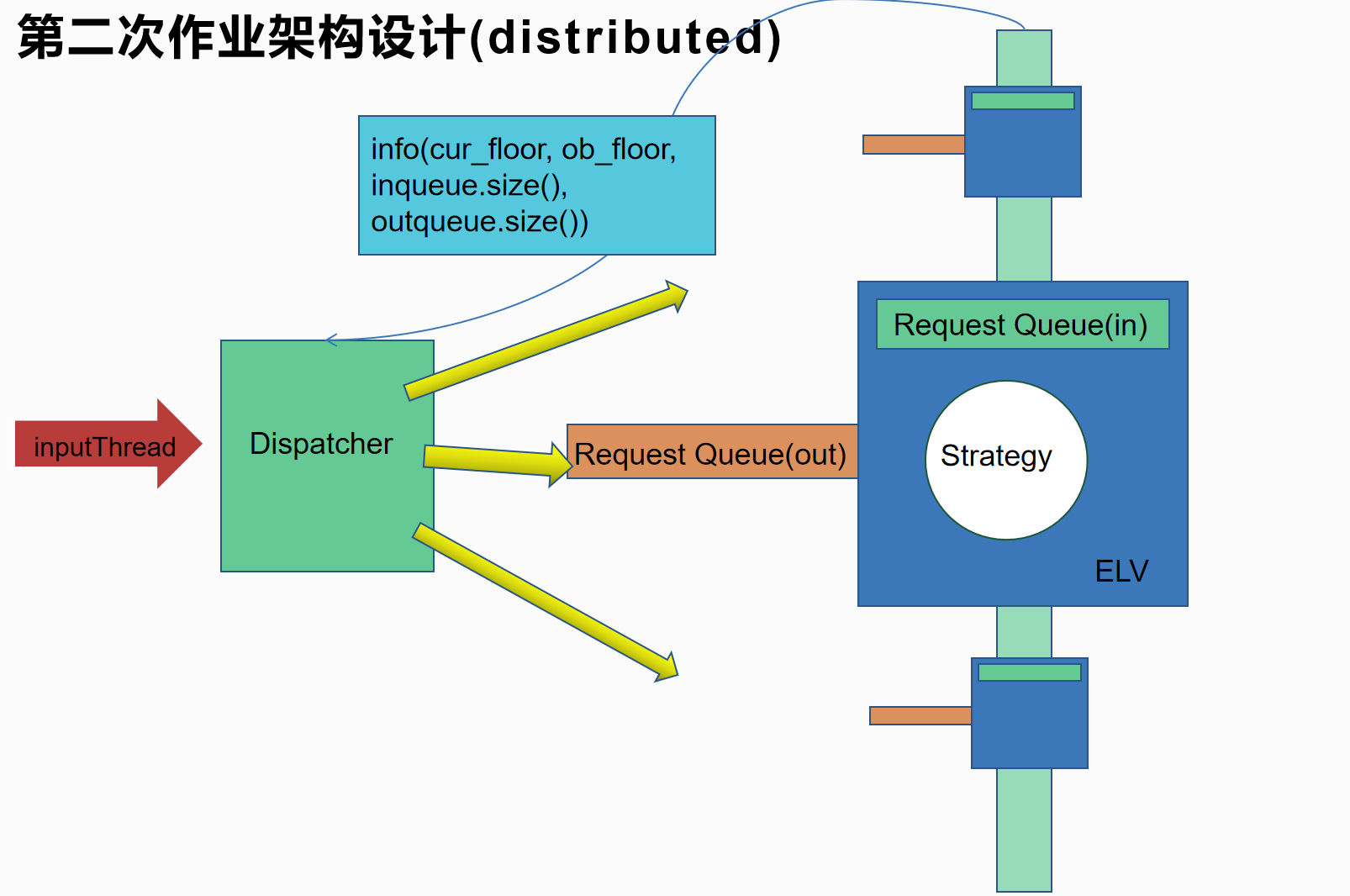
第一种设计相对复杂,就是否共享同一外部请求而言是分布式(distributed)的,即每个电梯的外部请求队列相互独立不共享。在这种情况下,为了使得Dispacher能够更好地分配请求,需要获得各个电梯此时的状态。在add电梯后,需要能够将已经分派给前三个电梯的请求合理地分配给所有的电梯。

第二种设计结构相对简单, 就是否共享同一外部请求而言是集中式(central)的,即所有电梯共享同一外部请求队列,自由竞争所有的请求。另外,在进行第二种方案的设计时,将一个唯一的外部队列改写为楼层类,详见这篇总结的第二部分
两种方案的优劣:分布式方案由于各个电梯的请求队列相互隔离,不会出现因争抢请求而产生的陪跑现象,但对调度器有较高的要求,不仅要尽量公平地将请求放入各个电梯的外部请求,还需要在新增电梯后将已放入的请求取回。集中式方案结构更加简单,减少了调度器这一线程,且公平竞争能够使得各个电梯等待请求的时间相对均衡,但可能出现陪跑现象(对于night这种所有人同时到达的模式尤为明显)。
由于在自己在测评机上测试两种方案时,明显central方案较优,故在最后公测中提交了这一方案。

第三次作业主要基于第二次作业的分布式方案。在其基础上:对每个Elv增加类型,并通过ElvFactory生产不同的电梯;每种类型的电梯共享同一楼层类。对于需要换乘的请求,Dispatch根据起止楼层和电梯的状态更改目标楼层并标记为换乘请求,在换乘请求离开电梯后,又重新当做一个新的请求放回dispatcher中并更换目标楼层,进行重新分派。
二. 作业中线程的同步与互斥
关于线程中需要保证同步的对象,使用较为随机的数据进行测试,并通过Jprofiler展开其相关方法的调用树(颜色越红代表占用CPU时间越长)。
第一次作业方法调用树
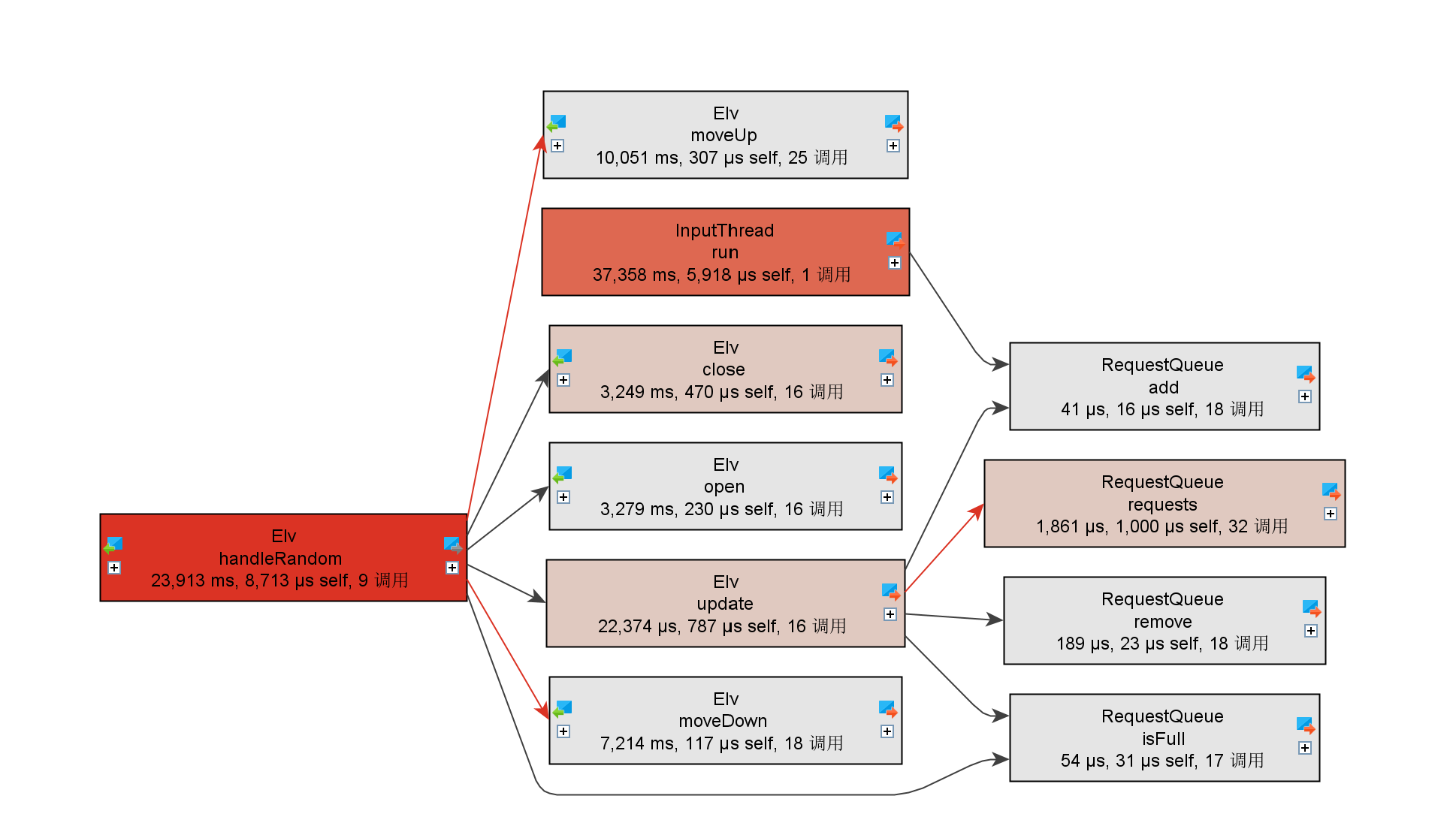
第二次作业方法调用树
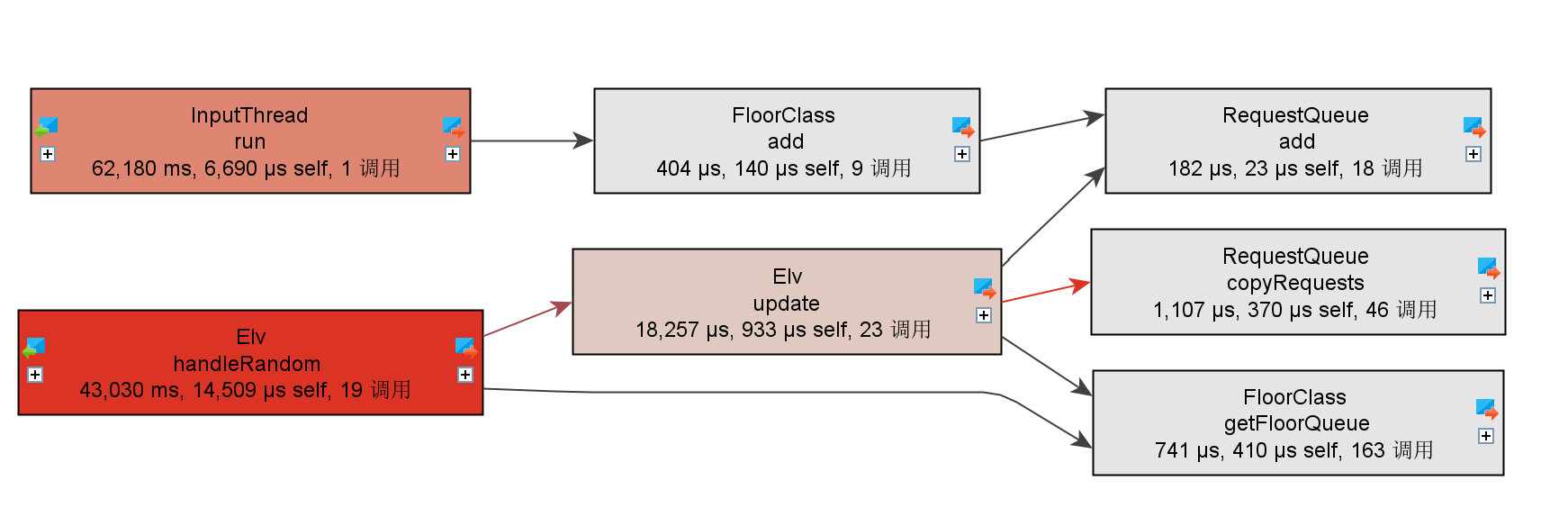
第三次作业方法调用树

这里InputThread由于必须需要轮询,因此在三次作业中都占用了CPU大量的时间。实际上在三次作业中,第一次作业中需要实现互斥的共享对象是RequestQueue;第二次作业和第三次作业中需要实现互斥的共享对象是FloorClass。可以发现,在requestQueue和dispatcher之间加入了一层抽象FloorClass后,围绕着互斥对象的各个方法占用的时间变得更加均衡。当然这里也暴露出来一些不足:在电梯开门后与外部的队列进行交互时,是直接将楼层或者整体的队列做一个拷贝,再遍历其中的请求,符合要求的进入电梯;再锁住实际的外部队列,删除这些请求。对电梯内部的队列也做相同的操作。这样做实际上增加了交互的复杂度,实际使用时应该直接锁住外部队列,通过迭代器遍历其中的请求并直接删除,这样做便可以将此处的操作复杂度由O(mn)转变为O(m)(m是外部队列的请求数,n是需要进入电梯的请求树)。
三个关于锁的优化
细化需要保证互斥的共享对象,从而提高程序的并行程度
在这三次作业中,需要保证互斥的对象仅有电梯外部的队列。第一次作业由于结构较为简单,仅存在一个外部队列。笔者将所有的请求全部装入同一个队列,并对这个队列实现互斥。在第二次作业的一开始,自己沿用了这样的设计,但很快发现这中做法不仅提高了死锁的可能性,还会有严重的效率问题:比如电梯到达某一层开了门,并与外部的请求队列交互,此时电梯将把整个队列锁住,这段时间内input的请求无论在哪一楼层都会被阻塞。这与多线程的提高并行程度的目标是相违背的。于是自己设计了楼层类,为每一个楼层单独设立一个队列,仅装入fromfloor为当前楼层的请求。具体如下:
-
楼层类:维护一个包含20个请求队列(每层一个)的列表,inputThread在调用其方法放入请求时,直接放入其起始楼层的请求队列中,而电梯在开门后关门前,仅与当前楼层对应的外部请求队列交互。
-
楼层类的好处:
-
增加程序的并行度。如当前电梯在11楼与当前楼层的队列交互,同时外部新增一个从12楼起始的请求,这两个楼层有着不同的请求队列,因而不存在互斥的要求。
-
更易实现LRU:在电梯选择外部的请求时,可以以当前所在楼层位基址,上下扫描楼层队列,若发现楼层队列不为空,就以此外部请求当做执行请求。从而实现就近原则,这里给出作业中代码的示例:
-
1 public int findNearestFloor(int floor) { //Random模式下寻找离自己最近的请求 2 int j = 0; 3 while (j < 20) { 4 if (0 < floor + j && floor + j <= 20) { 5 if (!floorQueues.get(floor + j).isEmpty()) { 6 return floor + j; 7 } 8 } 9 if (0 < floor - j && floor - j <= 20) { 10 if (!floorQueues.get(floor - j).isEmpty()) { 11 return floor - j; 12 } 13 } 14 j++; 15 } 16 return 0; //表示当前状态下没有请求 17 }
-
这一拆分或者说是细化的优化,使得不同楼层的外部请求队列可以进行异步的增加和删除操作,从而极大地提高了程序的并行程度。
将synchronized块集中起来管理,从而提高程序的可维护性
在刚开始编写多线程程序时,笔者为了方便,总是一股脑编程,在遇到需要加锁的对象时直接sychronized该对象,再继续编写。在第一次作业中,由于程序较为简单,这样做的问题不大。可到了第二次作业,synchronized块写的到处都是(尤其是在strategy方法中),导致程序变得难以维护,出现死锁也难以发现原因。此时就应该考虑在共享对象的类中实现synchronized加锁。如果共享对象仅有一个:如第一次作业中仅有一个外部队列,就可以直接在方法上加锁。如果共享对象有多个,可以在类的内部,对具体需要加锁的对象加锁,代码展示如下:
1 public void add(PersonRequest req) { 2 synchronized (floorQueues.get(req.getFromFloor())) { 3 floorQueues.get(req.getFromFloor()).add(req); 4 floorQueues.get(req.getFromFloor()).notifyAll(); 5 reqNum += 1; 6 } 7 }
对于需要共享的对象,单独开辟一个类
这句话本来是不言自明的,但笔者想强调的是:如果一个类的对象有些需要互斥,有些不需要时,最好为所有需要互斥的共享对象设计一个新的类。比如在本单元的作业中,电梯内部的请求队列和电梯外部的请求队列是完全相同的。此时,如果用一个相同的类,并在类方申明名或类方法中中加入synchronized上锁就会导致不必要的互斥。因为此时电梯内部的请求队列在变动时也会有Monitor介入的、本可以避免的开销。在此时,就应该为需要共享的对象建立一个新的类,从而减小这部分开销,提高程序运行效率。
总而言之,编写多线程程序的步骤是:
-
搞清楚自己需要几个线程,有哪些共享对象。
-
理清线程开启和结束的条件。
-
为需要实现互斥的有线程安全风险的共享对象开辟单独的类,尽量在其方法的申明或方法中上锁。
-
细化共享对象(基本遵循能不共享就不共享,能在逻辑上划分需要共享的东西的大小就划分它)。
-
进一步优化,避免轮询等。
-
告诉自己谋事在人,成事在天,不可强也!
三. 代码架构分析
第一次作业
UML类图
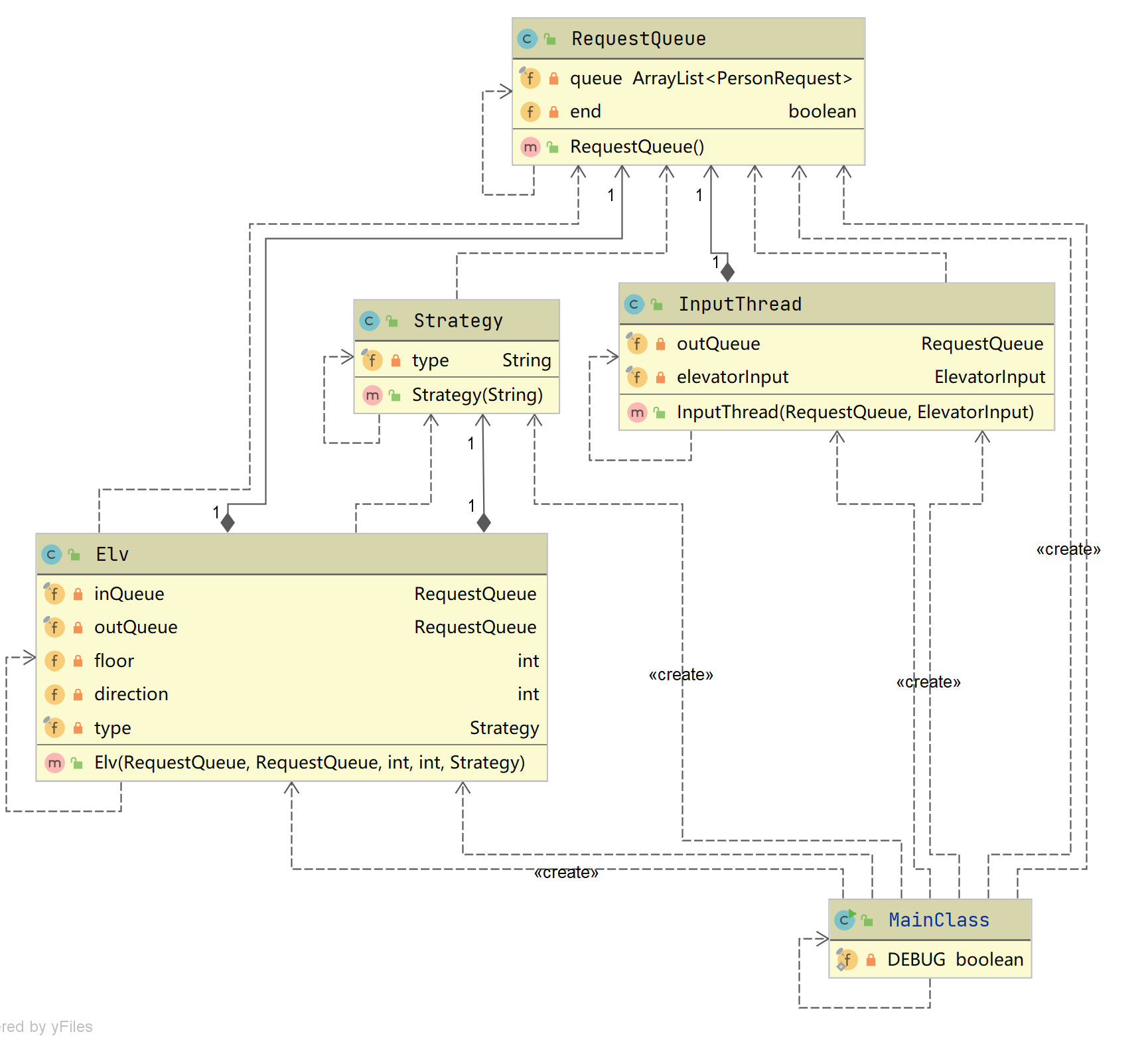
关联矩阵

复杂度统计(按复杂度降序)
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| RequestQueue.containsFloor(int,boolean,int) | 13.0 | 5.0 | 5.0 | 8.0 |
| Elv.handleRandom(PersonRequest,int) | 12.0 | 1.0 | 6.0 | 8.0 |
| Strategy.randomStrategy(RequestQueue,RequestQueue) | 12.0 | 1.0 | 6.0 | 6.0 |
| Elv.run() | 8.0 | 1.0 | 6.0 | 6.0 |
| Elv.update() | 8.0 | 1.0 | 8.0 | 8.0 |
| Elv.handle(PersonRequest,int) | 7.0 | 1.0 | 6.0 | 6.0 |
| Strategy.eveningStrategy(RequestQueue,RequestQueue) | 7.0 | 1.0 | 6.0 | 6.0 |
| DebugInput.run() | 6.0 | 1.0 | 2.0 | 4.0 |
| Total | 100.0 | 42.0 | 88.0 | 100.0 |
| Average | 2.86 | 1.24 | 2.59 | 2.94 |
上述表格是复杂度最高的几个方法,这里RequestQueue类中containsFloor方法中由于遍历所有的表项,还要判断该请求的方向是否与请求的方向是否相同等条件,成为了复杂度最高的方法,当然这里可以使用java8函数式编程的方法简化代码。其余的复杂度较高的方法主要集中在电梯类中。
第二次作业(仅对distributed版进行分析)
UML类图

关联矩阵
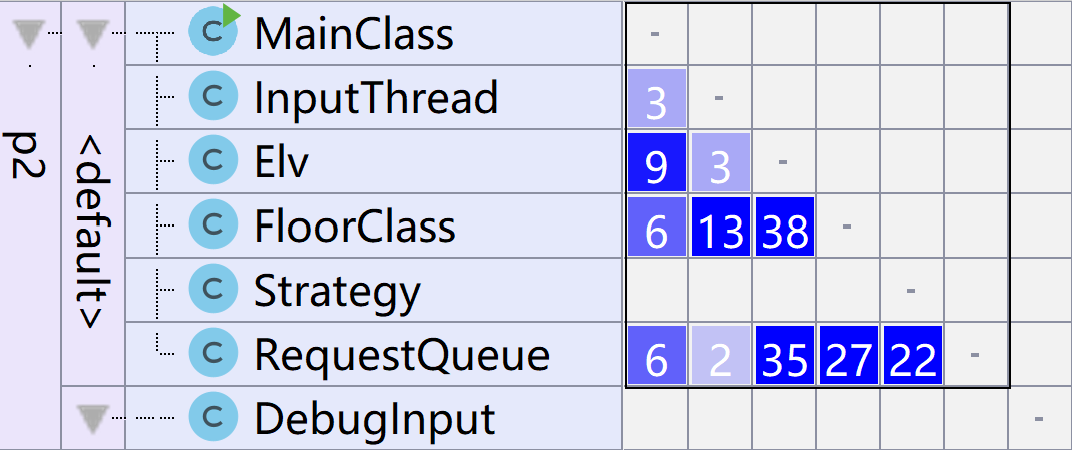
与第一次作业的关联矩阵对比可以发现,内部含有多个RequsetQueue的FloorClass类成功减少了Elv对RequestQueue的依赖关系。这可以理解为在电梯与请求队列直接增加一层抽象。使得Elv不需要关心外部的请求队列具体为何而直接通过FloorClass类及其中的方法获得外部请求队列的信息。并在开门后直接与FloorClass类交互。
复杂度统计(按复杂度降序)
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Elv.run() | 34.0 | 1.0 | 17.0 | 17.0 |
| Elv.handleRandom(int,int) | 15.0 | 4.0 | 6.0 | 10.0 |
| FloorClass.findFarFloor(int) | 13.0 | 6.0 | 4.0 | 8.0 |
| FloorClass.findNearestFloor(int) | 13.0 | 6.0 | 4.0 | 8.0 |
| RequestQueue.containsFloor(int,boolean,int) | 13.0 | 5.0 | 5.0 | 8.0 |
| Elv.update() | 8.0 | 1.0 | 9.0 | 9.0 |
| InputThread.run() | 7.0 | 3.0 | 6.0 | 6.0 |
| debuginput.DebugInput.run() | 6.0 | 1.0 | 2.0 | 4.0 |
| Total | 133.0 | 64.0 | 98.0 | 119.0 |
| Average | 3.325 | 1.64 | 2.51 | 3.05 |
这里Elv的run方法复杂度较高,其主要原因是自己将strategy集成在了run方法内部,这样做是很不对的。
第三次作业
UML类图
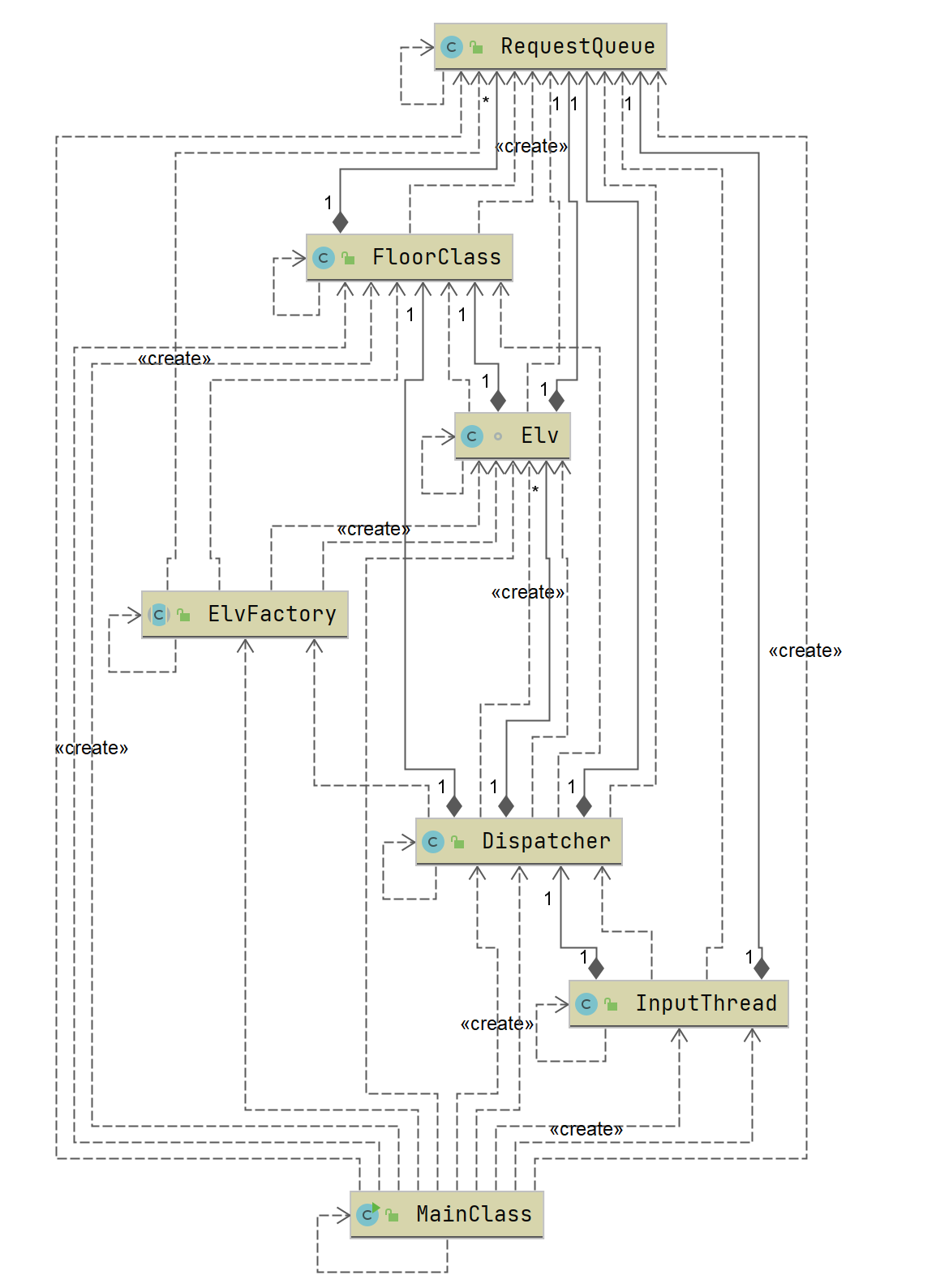
关联矩阵

这里发现一个比较好的现象:ELv对RequestQueue的依赖关系进一步降低了,而转而与更进一步抽象的FloorClass建立更多的联系。
复杂度统计(按复杂度降序)
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Elv.run() | 34.0 | 1.0 | 17.0 | 17.0 |
| Elv.handleRandom(int,int) | 20.0 | 4.0 | 7.0 | 11.0 |
| Dispatcher.run() | 13.0 | 3.0 | 7.0 | 8.0 |
| FloorClass.findFarFloor(int) | 13.0 | 6.0 | 4.0 | 8.0 |
| FloorClass.findNearestFloor(int) | 13.0 | 6.0 | 4.0 | 8.0 |
| RequestQueue.containsFloor(int,boolean,int) | 13.0 | 5.0 | 5.0 | 8.0 |
| Dispatcher.dispatch() | 10.0 | 1.0 | 5.0 | 9.0 |
| Elv.update() | 8.0 | 1.0 | 9.0 | 9.0 |
| InputThread.run() | 7.0 | 3.0 | 6.0 | 6.0 |
| debuginput.DebugInput.run() | 6.0 | 1.0 | 2.0 | 4.0 |
| FloorClass.pickable(int,int) | 4.0 | 4.0 | 2.0 | 4.0 |
| Elv.intArrLookupInt(int[],int) | 3.0 | 3.0 | 2.0 | 3.0 |
| Total | 166.0 | 78.0 | 120.0 | 153.0 |
| Average | 3.32 | 1.59 | 2.44 | 3.12 |
在第三次作业中由于扩展的内容不涉及电梯的run方法,所以其复杂度依旧高居第一(应该之前发现问题早早解耦的),其次由于dispatcher的run方法在有请求进入的时候需要选择合适的对象,对于添加电梯的指令需要开启新的线程,因而也具有较高的复杂度。
横向比较
1. 增加一层抽象,实现解耦

2. 方法的复杂度饼状图

第二次作业中没有对Elv.run方法很好地解耦,第三次作业也延续了这种设计,导致出现了较为不好的现象。可见strategy类的设置还是比较有必要的。
1. 自己的bug
居然在强测和互测中都没有出现bug(但第三次作业由于分派不合理性能巨差)。在本地测试时出现的bugs中值得一提的是在第二次作业中synchrized关键字滥用而出现了一个bug,根据老师反馈的结果是这种bug是很容易犯的,所以详述如下:
由于在写这部分代码时,对synchronized的理解不够到位,写出了如下的程序:
1 //Elv中部分代码 2 synchronized (outQueue) { 3 synchronized (inQueue) { 4 a = this.type.getCurrentReq(outQueue, inQueue); 5 inQueue.notifyAll(); 6 } 7 outQueue.notifyAll(); 8 }
这里getCurrentReq是一个方法,局部的代码展示如下:
1 //strategy中部分代码 2 if (empty) { 3 if (outQueue.isEmpty() && !outQueue.isEnd()) { 4 try { 5 outQueue.wait(); 6 } catch (InterruptedException e) { 7 e.printStackTrace(); 8 } 9 if (!outQueue.isEmpty()) { 10 currentReq = outQueue.getTop(); 11 tag = 2; 12 } 13 } else { 14 currentReq = outQueue.getTop(); 15 tag = 2; 16 } 17 }
既然大家都学完了多线程的部分,bug就显而易见了:Elv拿着inqueue和outqueue两个锁进入了critical区,在critical区中又调用了其他方法,而在该方法中又采用wait-notifyAll方法避免轮询,但是这时wait方法仅能针对inQueue和outQueue中的一个释放锁,最后dispacher由于得不到所有的锁而被阻塞,从而导致死锁。这个bug现在分析是较为简单的(直接犯了连用synchrinzed关键字和critical区中调函数两个禁忌就应警惕很有可能必然有bug),但在当时曾因^^^TOO_NAIVE^^^而找不到死锁的原因一度半宿未睡,心如死灰乃至视死如归。最后还是借助Jprofiler工具分析锁的关系找到了bug的根源,但最令人难过的是在经验分享时被同学和老师告知 为提高性能(对CPU执行而言),策略类完全没必要加锁。它仅需要获得大概的方向,即使读错也不会导致错误,只会导致电梯“白跑“。后来笔者又思考了下"白跑"问题,个人认为:这种情况在事实上由于多线程本身的特性和到达请求本身的随机性会被统计平均到和几乎获得精确信息没有区别,所以这个bug不仅出现的莫名其妙,而且对其复杂的修复也是毫无必要的(直接删除sychronized就好)。
二. 发现bug的测试策略
一共使用两种测试:
-
黑盒测试:首先根据讨论区中分享的方法设置定时输入的管道流。第一次作业
白嫖借用大佬的正确性检查程序,设计了简单的测评机;在第二次作业中将不同的结果分别输出到不同的文件单独检查正确性和电梯空转时间,并输出每个电梯最后的截止时间;在第三次作业中在正确性检查中增加禁止楼层和电梯速度的设置。对程序的正确性进行检查,当然个人感觉效果不佳(没有通过这种方法找到任何bug) -
灰盒测试:借助Jprofiler工具,检查死锁问题和可能的异步执行的风险,并通过调用树的调用数统计检查轮询的存在性。这种测试能够很好地检查多线程中轮询、死锁、风险异步执行的问题,这也弥补了黑盒只针对正确性进行测试的不足。
仅对于自己的程序进行和黑盒和灰盒测试。(由于听说多线程玄学地出错)没有积极地测试别人的程序,也没有积极参与圣杯战争所以没有发现他人的bug。
五. 心得体会
在刚进入第二单元时,笔者感觉自己就像接触了一个全新的庞然大物。曾一度怀疑人生自己的智商,但在经过几次上机实验(观膜助教学长的优秀代码)和单元训练的指导后,逐渐理解了多线程的原理,而在清楚了原理后,会发现JAVA的synchrized关键字为我们很好地屏蔽了同步与互斥的底层实现,最后落实到实际编程时,与单线程编程相比,只需要考虑谁是共享的需要互斥的资源加入critical区即可(甚至在最后感觉难度没有第一单元大(递归下降、表达式树的化简真的好累))。但总的来说,经过这三次作业的训练,自己对多线程编程的相关技巧有了更进一步的理解,经历令人痛苦的debug过程也让我们在摔跤之后留一个心眼下次再来在以后的编程中避免相似的问题,因此,既然OO的目的是整我们提高我们的编程能力,那么它的目标是很好地达到了的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号