深度学习系列笔记——贰 (基于Tensorflow2 Keras迁移学习,使用预训练模型解决猫狗大战 四)
深度学习系列笔记——贰 (基于Tensorflow Keras搭建的猫狗大战模型 一)
深度学习系列笔记——贰 (基于Tensorflow Keras搭建的猫狗大战模型 二)
深度学习系列笔记——贰 (基于Tensorflow2 Keras搭建的猫狗大战模型 三)
本篇博客是对于之前猫狗大战的补充,猫狗大战使用的是我们自己的模型,输入的图像尺寸是200x200x3,接下来,在之前的基础上,我们更改一下模型,并且把之前的输入尺寸进行一定的改动,使用经典的VGGNet(包含vgg16和vgg19),提升我们模型训练的准确率和训练速度。
有关keras详细的预训练模型使用,可以参考 官网 的解释。
include_top=False指的是不导入输出层,只选取卷积层的模块作为预训练之用。如果需要的是模型的预训练权重,官网教程也给出了各个模型输入时的默认尺寸,例如下面的MobileNetV2默认输入尺寸为224x224x3,如果不需要预训练权重,只是需要模型的框架,则导入时将weights设置为None即可
from tensorflow.keras.applications import MobileNetV2
model = MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
0、关于预训练权重的下载问题:
在导入预训练模型时,程序会检查本地是否存在预训练模型的权重,若不存在,则需要下载。
1、由于众所周知的原因,国内下载很慢,如果有****工具的同学,可以直接开着,然后把链接复制到浏览器地址栏(就是下图蓝色的地址,全部复制到浏览器地址栏)

2、下载后你会得到一个以.h5结尾的模型文件,然后把下载好的预训练模型直接放到用户路径中的 .keras文件夹中,进入models,这里就是kears存放预训练模型的位置。提醒一下:datasets是用于存放keras常用的数据集,如下所示
我们需要进入的是models,里面存放着权重文件
下图是博主保存的部分权重文件
3、如果没有****工具的同学,可以直接把链接复制到迅雷中,利用迅雷加速下载(有时候迅雷也比较坑,会限速,这个时候就确实没办法了)
放到指定位置后,再重新运行刚刚的程序就可以直接使用本地的权重文件了
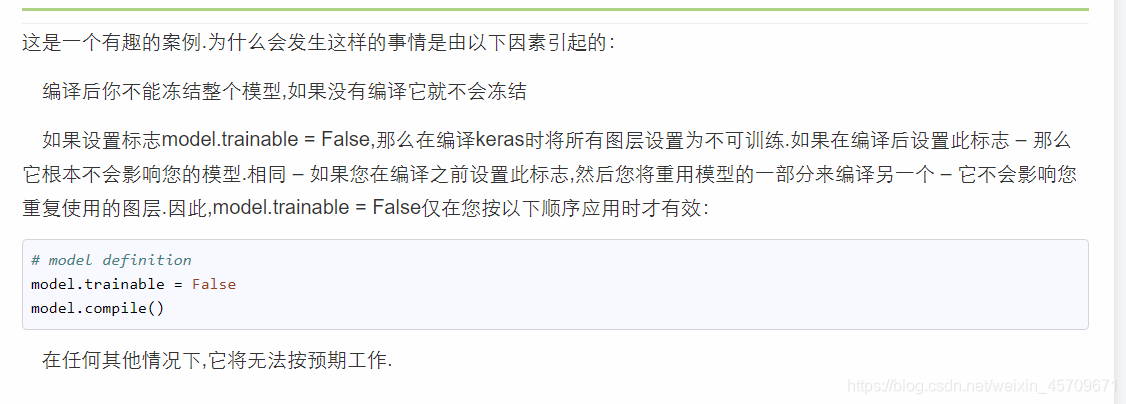
注意:预训练模型如果只需要训练后面的全连接层,不想改变前面的卷积层,则需要将不需要训练的层trainable设置为False,而且需要在模型编译之前,也就是在 model.compile() 之前完成,否则keras将不会冻结卷积层。
可以参考这篇博客:
keras – 不应该是model.trainable =模型下的假冻结权重?
1、VGG模型的使用
模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。
我们使用在ImageNet1000分类上已经预训练过的模型进行再次训练,只改变后面的全连接层的输出,其他的层提取出的特征均不变。
另外,我们对于之前的模型只进行很小比例的改动,将输入的尺寸改为224x224x3。使用预训练模型进行迁移学习,能够很快的达到较高的准确率,经过博主尝试,只需要训练4个epoch,即可在验证集上达到94%的准确率,这个准确率比我们自己之前的要高2.5%。
下面直接给出完整的代码:
# 导入包
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
import os
import time
import matplotlib.pyplot as plt
from tensorflow.keras.applications import VGG16
start = time.time()
# 设置目录路径
PATH = os.path.join('D:/Desktop/catVSdog/data') # 图片数据集的根目录
# 将目录区分位猫狗训练集和验证集
train_dir = os.path.join(PATH, 'train') # train数据集 相对于根目录
validation_dir = os.path.join(PATH, 'validation') # validation数据集 相对于根目录
train_cats_dir = os.path.join(train_dir, 'cats') # train目录下的文件夹 每个会在之后分为一类
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats') # validation目录下的文件夹 每个会在之后分为一类
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
num_cats_tr = len(os.listdir(train_cats_dir))
num_dogs_tr = len(os.listdir(train_dogs_dir))
num_cats_val = len(os.listdir(validation_cats_dir))
num_dogs_val = len(os.listdir(validation_dogs_dir))
total_train = num_cats_tr + num_dogs_tr # 文件数量求和 方便 后续处理和代码复用
total_val = num_cats_val + num_dogs_val
# 为方便起见,设置变量以在预处理数据集和训练网络时使用
# batch_size可以根据自己的电脑配置进行修改
# 另外这个的大小也影响着训练的准确率,较小时可以起到正则化的作用,但是训练速度会受到影响
batch_size = 64
epochs = 4
IMG_HEIGHT = 224
IMG_WIDTH = 224
# 使用实时数据增强生成一批张量图像数据。 通过通道方式获取图片
train_image_generator = ImageDataGenerator(rescale=1. / 255, rotation_range=5,
horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1. / 255)
train_data_gen = train_image_generator.flow_from_directory(
batch_size=batch_size, directory=train_dir, shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(
batch_size=batch_size, directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
# 在windows系统中,打开命令行(键盘 win + r),
# 键入nvidia-smi.exe --loop=4 命令,可以每隔4秒循环查看当前GPU的各项运行状况
# 修改数字4即可改变频率,另外按下 ctrl + c 即可结束循环
def myvgg16():
"""
我们采用函数的方法得到需要的模型
这里我们采用的是在ImageNet上进行预训练过的权重,这个权重经过1000分类,包含了常见的物体识别,因此可以得到比较好的效果,
同时可以大大缩短我们自己训练时的耗时,在短时间内将准确率提升到一个比较高的水平
:return: 返回得到一个利用函数方法构建出来的模型,其中卷积层采用的是vgg自带的权重
"""
# 设置输入层,作为图像数据输入
inputs = tf.keras.layers.Input(shape=(IMG_HEIGHT, IMG_WIDTH, 3))
# 导入预训练模型,include_top=False代表自己重新写输出层
vgg16 = VGG16(input_shape=(IMG_HEIGHT, IMG_WIDTH, 3), include_top=False)
# 将预训练模型的每一层都设置为不可训练,此处我们暂时只训练全连接层,卷积层暂时不管,后期等准确率到达比较高的水平时,再设置为可训练
# 我们可以更改设置,为True
for layer in vgg16.layers:
vgg16.trainable = False
# 连接上我们自己的全连接层,作为模型的训练目标
# 由于全连接层属于参数非常密集的层,因此需要进行一定程度的正则化,对输出每一层的连接进行限制,减缓过拟合现象的发声
x = vgg16(inputs)
x = layers.Flatten()(x) # 拉平层
x = layers.Dense(1024, activation=tf.keras.layers.LeakyReLU(alpha=0.512))(x)
x = layers.Dropout(rate=0.4)(x)
x = layers.Dense(256, activation=tf.keras.layers.LeakyReLU(alpha=0.128))(x)
x = layers.Dropout(rate=0.2)(x)
outputs = layers.Dense(1, activation=tf.keras.layers.LeakyReLU(alpha=0.1))(x)
# 返回一个keras的模型
return tf.keras.Model(inputs=inputs, outputs=outputs)
myvgg16 = myvgg16()
myvgg16.compile(optimizer=tf.keras.optimizers.Adadelta(learning_rate=0.005),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 输出模型信息
myvgg16.summary()
checkpoint_save_path = "./vggCheckpoint/vgg16.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
myvgg16.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = myvgg16.fit(
train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=[cp_callback],
)
end = time.time()
print("This %d epochs cost time: %f s , average %f s per epoch" % (epochs, (end - start), (end - start) / epochs))
# 可视化培训结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(10, 10))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 记录模型优化过程及准确率
logFilePath = './/vggCheckpoint//vgg16_model.txt'
if os.path.isfile(logFilePath):
print("Log file exists.")
logWriter = open(logFilePath, 'a')
else:
print("Log file does not exists. Make it .")
logWriter = open(logFilePath, 'w')
logWriter.write('Training finish at : ' + str(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) + '\n')
logWriter.write('model id : ' + str(myvgg16.name) + '\n')
logWriter.write('Total epoch : ' + str(epochs) + '\n')
logWriter.write('These epochs cost time (second) : ' + str((end - start)) + '\n')
logWriter.write('Training accuracy : ' + '\n ' + str(history.history['accuracy']) + '\n')
logWriter.write('Validation accuracy: ' + '\n ' + str(history.history['val_accuracy']) + '\n')
logWriter.write('---------------------------------------------------------------------------\n')
logWriter.write('\n')
print("Log file has successfully written down.")
logWriter.close()
训练一次即可达到88%的准确率,下图是再次训练4次时的准确率,出现了一些波动,但是我们可以加大训练次数,使之收敛。
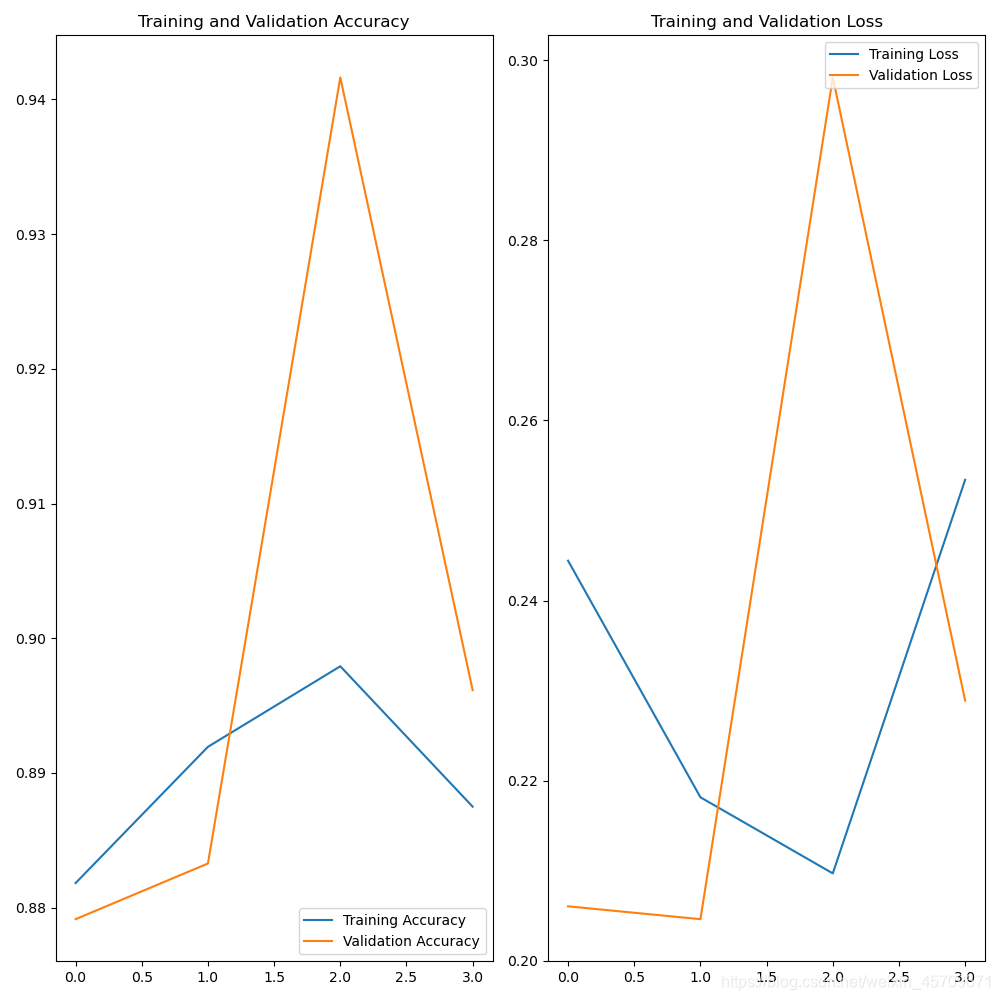
2、InceptionNet的使用
我们利用和上面vgg模型同样的方式,可以搭建Inception的网络,值得注意的是,InceptionV3的默认输入尺寸是 299x299,这里我们按照默认的尺寸导入即可
# 导入包
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
import os
import time
import matplotlib.pyplot as plt
from tensorflow.keras.applications import InceptionV3
from collections import Iterable
start = time.time()
# 设置目录路径
PATH = os.path.join('D:/Desktop/catVSdog/data') # 图片数据集的根目录
# 将目录区分位猫狗训练集和验证集
train_dir = os.path.join(PATH, 'train') # train数据集 相对于根目录
validation_dir = os.path.join(PATH, 'validation') # validation数据集 相对于根目录
train_cats_dir = os.path.join(train_dir, 'cats') # train目录下的文件夹 每个会在之后分为一类
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats') # validation目录下的文件夹 每个会在之后分为一类
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
num_cats_tr = len(os.listdir(train_cats_dir))
num_dogs_tr = len(os.listdir(train_dogs_dir))
num_cats_val = len(os.listdir(validation_cats_dir))
num_dogs_val = len(os.listdir(validation_dogs_dir))
total_train = num_cats_tr + num_dogs_tr # 文件数量求和 方便 后续处理和代码复用
total_val = num_cats_val + num_dogs_val
# 为方便起见,设置变量以在预处理数据集和训练网络时使用
batch_size = 32
epochs = 4
IMG_HEIGHT = 299
IMG_WIDTH = 299
# 使用实时数据增强生成一批张量图像数据。 通过通道方式获取图片
train_image_generator = ImageDataGenerator(rescale=1. / 255, rotation_range=5,
horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1. / 255)
train_data_gen = train_image_generator.flow_from_directory(
batch_size=batch_size, directory=train_dir, shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(
batch_size=batch_size, directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
# 在windows系统中,打开命令行(键盘 win + r),
# 键入nvidia-smi.exe --loop=4 命令,可以每隔4秒循环查看当前GPU的各项运行状况
# 修改数字4即可改变频率,另外按下 ctrl + c 即可结束循环
def myInceptionv3():
"""
我们采用函数的方法得到需要的模型
这里我们采用的是在ImageNet上进行预训练过的权重,这个权重经过1000分类,包含了常见的物体识别,因此可以得到比较好的效果,
同时可以大大缩短我们自己训练时的耗时,在短时间内将准确率提升到一个比较高的水平
:return: 返回得到一个利用函数方法构建出来的模型,其中卷积层采用的是vgg自带的权重
"""
# 设置输入层,作为图像数据输入
inputs = tf.keras.layers.Input(shape=(IMG_HEIGHT, IMG_WIDTH, 3))
# 导入预训练模型,include_top=False代表自己重新写输出层
Inception = InceptionV3(input_shape=(IMG_HEIGHT, IMG_WIDTH, 3), include_top=False)
# 将预训练模型的每一层都设置为不可训练,此处我们暂时只训练全连接层,卷积层暂时不管,后期等准确率到达比较高的水平时,再设置为可训练
# 我们可以更改设置,为True
Inception.trainable = False
# 连接上我们自己的全连接层,作为模型的训练目标
# 由于全连接层属于参数非常密集的层,因此需要进行一定程度的正则化,对输出每一层的连接进行限制,减缓过拟合现象的发声
x = Inception(inputs)
x = layers.Flatten()(x) # 拉平层
x = layers.Dense(512, activation=tf.keras.layers.LeakyReLU(alpha=0.512))(x)
x = layers.Dropout(rate=0.6)(x)
x = layers.Dense(256, activation=tf.keras.layers.LeakyReLU(alpha=0.128))(x)
x = layers.Dropout(rate=0.4)(x)
outputs = layers.Dense(1, activation=tf.keras.layers.LeakyReLU(alpha=0.1))(x)
# 返回一个keras的模型
return tf.keras.Model(inputs=inputs, outputs=outputs)
myInceptionv3 = myInceptionv3()
myInceptionv3.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 输出模型信息
myInceptionv3.summary()
checkpoint_save_path = "./InceptionCheckpoint/Inceptionv3.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
myInceptionv3.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = myInceptionv3.fit(
train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=[cp_callback],
)
end = time.time()
print("This %d epochs cost time: %f s , average %f s per epoch" % (epochs, (end - start), (end - start) / epochs))
# 可视化培训结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(10, 10))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 记录模型优化过程及准确率
logFilePath = './/InceptionCheckpoint//Inceptionv3.txt'
if os.path.isfile(logFilePath):
print("Log file exists.")
logWriter = open(logFilePath, 'a')
else:
print("Log file does not exists. Make it .")
logWriter = open(logFilePath, 'w')
logWriter.write('Training finish at : ' + str(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) + '\n')
logWriter.write('model id : ' + str(myInceptionv3.name) + '\n')
logWriter.write('Total epoch : ' + str(epochs) + '\n')
logWriter.write('These epochs cost time (second) : ' + str((end - start)) + '\n')
logWriter.write('Training accuracy : ' + '\n ' + str(history.history['accuracy']) + '\n')
logWriter.write('Validation accuracy: ' + '\n ' + str(history.history['val_accuracy']) + '\n')
logWriter.write('---------------------------------------------------------------------------\n')
logWriter.write('\n')
print("Log file has successfully written down.")
logWriter.close()
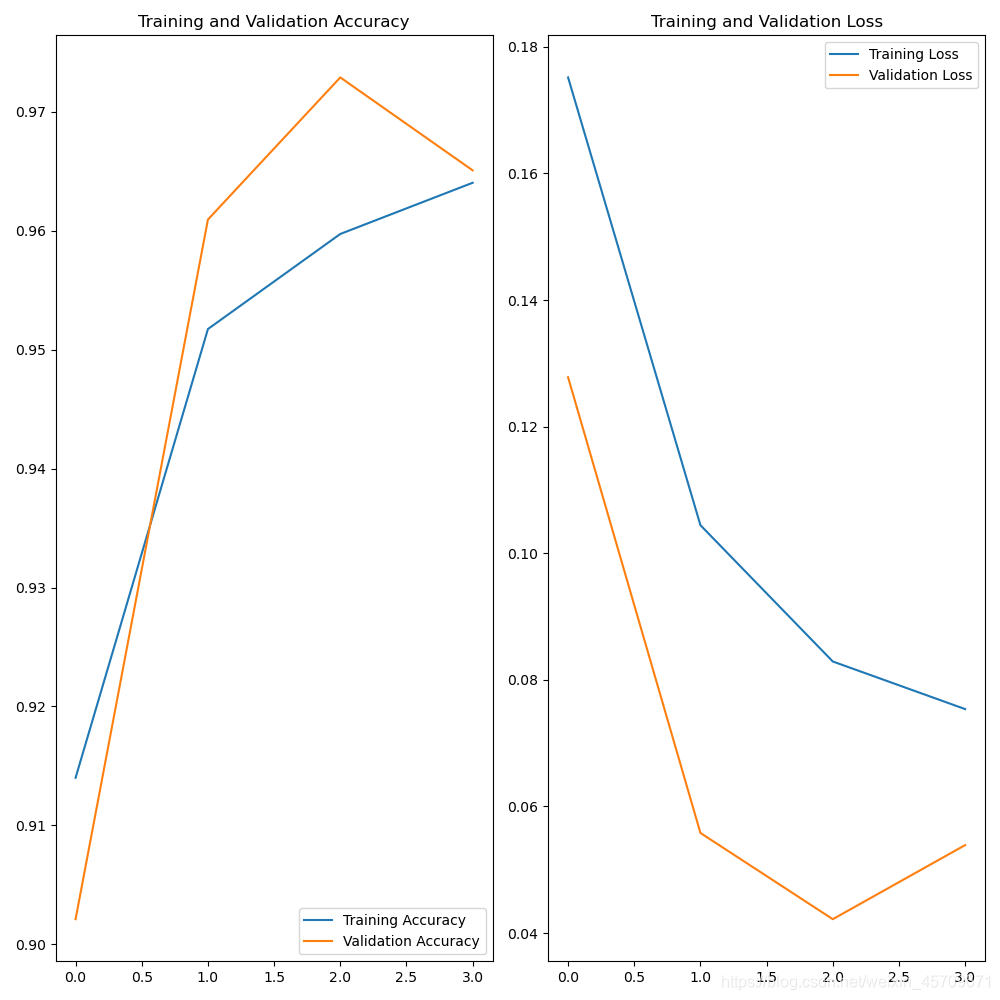
3、InceptionResNetV2的使用
# 导入包
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
import os
import time
import matplotlib.pyplot as plt
from tensorflow.keras.applications import InceptionResNetV2
from collections import Iterable
start = time.time()
# 设置目录路径
PATH = os.path.join('D:/Desktop/catVSdog/data') # 图片数据集的根目录
# 将目录区分位猫狗训练集和验证集
train_dir = os.path.join(PATH, 'train') # train数据集 相对于根目录
validation_dir = os.path.join(PATH, 'validation') # validation数据集 相对于根目录
train_cats_dir = os.path.join(train_dir, 'cats') # train目录下的文件夹 每个会在之后分为一类
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats') # validation目录下的文件夹 每个会在之后分为一类
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
num_cats_tr = len(os.listdir(train_cats_dir))
num_dogs_tr = len(os.listdir(train_dogs_dir))
num_cats_val = len(os.listdir(validation_cats_dir))
num_dogs_val = len(os.listdir(validation_dogs_dir))
total_train = num_cats_tr + num_dogs_tr # 文件数量求和 方便 后续处理和代码复用
total_val = num_cats_val + num_dogs_val
# 为方便起见,设置变量以在预处理数据集和训练网络时使用
batch_size = 32
epochs = 4
IMG_HEIGHT = 331
IMG_WIDTH = 331
# 使用实时数据增强生成一批张量图像数据。 通过通道方式获取图片
train_image_generator = ImageDataGenerator(rescale=1. / 255, rotation_range=5,
horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1. / 255)
train_data_gen = train_image_generator.flow_from_directory(
batch_size=batch_size, directory=train_dir, shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
val_data_gen = validation_image_generator.flow_from_directory(
batch_size=batch_size, directory=validation_dir,
target_size=(IMG_HEIGHT, IMG_WIDTH), class_mode='binary')
# 在windows系统中,打开命令行(键盘 win + r),
# 键入nvidia-smi.exe --loop=4 命令,可以每隔4秒循环查看当前GPU的各项运行状况
# 修改数字4即可改变频率,另外按下 ctrl + c 即可结束循环
def myInceptionResNetV2():
"""
我们采用函数的方法得到需要的模型
这里我们采用的是在ImageNet上进行预训练过的权重,这个权重经过1000分类,包含了常见的物体识别,因此可以得到比较好的效果,
同时可以大大缩短我们自己训练时的耗时,在短时间内将准确率提升到一个比较高的水平
:return: 返回得到一个利用函数方法构建出来的模型,其中卷积层采用的是vgg自带的权重
"""
# 设置输入层,作为图像数据输入
inputs = tf.keras.layers.Input(shape=(IMG_HEIGHT, IMG_WIDTH, 3))
# 导入预训练模型,include_top=False代表自己重新写输出层
inceptionResNetV2 = InceptionResNetV2(input_shape=(IMG_HEIGHT, IMG_WIDTH, 3), include_top=False)
# 将预训练模型的每一层都设置为不可训练,此处我们暂时只训练全连接层,卷积层暂时不管,后期等准确率到达比较高的水平时,再设置为可训练
# 我们可以更改设置,为True
inceptionResNetV2.trainable = False
# 连接上我们自己的全连接层,作为模型的训练目标
# 由于全连接层属于参数非常密集的层,因此需要进行一定程度的正则化,对输出每一层的连接进行限制,减缓过拟合现象的发声
x = inceptionResNetV2(inputs)
x = layers.Flatten()(x) # 拉平层
x = layers.Dense(512, activation=tf.keras.layers.LeakyReLU(alpha=0.512))(x)
x = layers.Dropout(rate=0.6)(x)
x = layers.Dense(256, activation=tf.keras.layers.LeakyReLU(alpha=0.128))(x)
x = layers.Dropout(rate=0.4)(x)
outputs = layers.Dense(1, activation=tf.keras.layers.LeakyReLU(alpha=0.1))(x)
# 返回一个keras的模型
return tf.keras.Model(inputs=inputs, outputs=outputs)
myInceptionv3 = myInceptionResNetV2()
myInceptionv3.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 输出模型信息
myInceptionv3.summary()
checkpoint_save_path = "./ResnetCheckpoint/ResnetCheckpoint_model.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
myInceptionv3.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = myInceptionv3.fit(
train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=[cp_callback],
)
end = time.time()
print("This %d epochs cost time: %f s , average %f s per epoch" % (epochs, (end - start), (end - start) / epochs))
# 保存模型,训练到模型收敛时,打开即可
myInceptionResNetv2.save("myInceptionResNetv2_for_cat_vs_dog.h5")
# 可视化培训结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(10, 10))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 记录模型优化过程及准确率
logFilePath = './/ResnetCheckpoint//myInceptionResNetV2.txt'
if os.path.isfile(logFilePath):
print("Log file exists.")
logWriter = open(logFilePath, 'a')
else:
print("Log file does not exists. Make it .")
logWriter = open(logFilePath, 'w')
logWriter.write('Training finish at : ' + str(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) + '\n')
logWriter.write('model id : ' + str(myInceptionv3.name) + '\n')
logWriter.write('Total epoch : ' + str(epochs) + '\n')
logWriter.write('These epochs cost time (second) : ' + str((end - start)) + '\n')
logWriter.write('Training accuracy : ' + '\n ' + str(history.history['accuracy']) + '\n')
logWriter.write('Validation accuracy: ' + '\n ' + str(history.history['val_accuracy']) + '\n')
logWriter.write('---------------------------------------------------------------------------\n')
logWriter.write('\n')
print("Log file has successfully written down.")
logWriter.close()
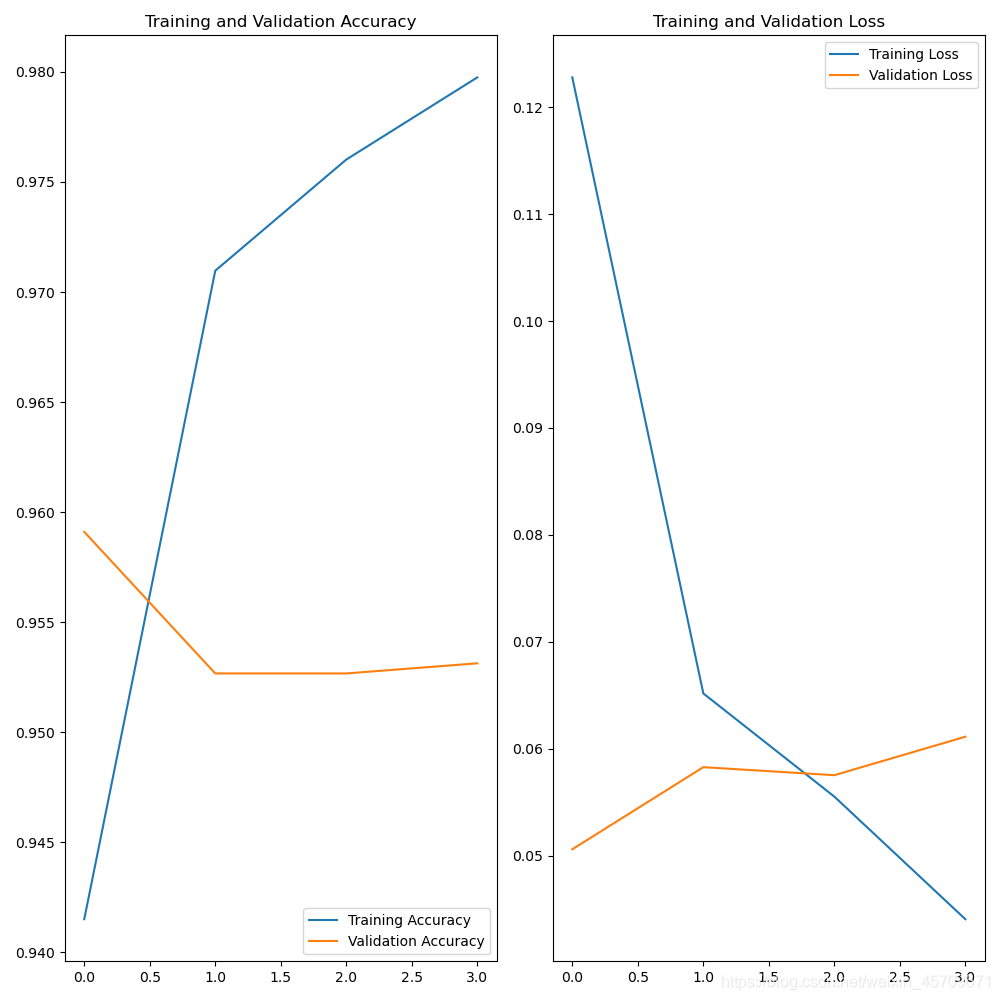
4、模型结构可视化神器
很多时候,复现人家工程的时候,需要了解人家的网络结构。但不同框架之间可视化网络层方法不一样,这样给研究人员造成了很大的困扰。
这里介绍一个可视化模型结构的神器:Netron
目前的Netron支持主流各种框架的模型结构可视化工作,下面直接给出Github链接:
https://github.com/lutzroeder/Netron
支持windows,Linux,mac系统
可以可视化如下所示的框架所对应的模型,非常方便。

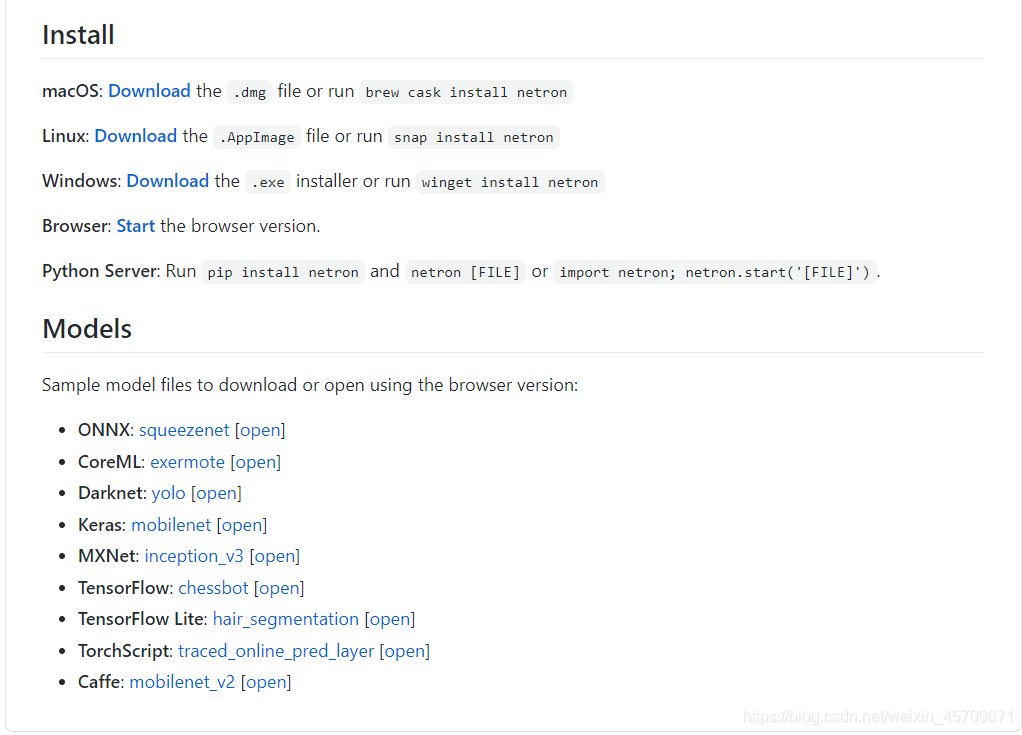
在windows系统,安装exe,如下:
Windows下载链接
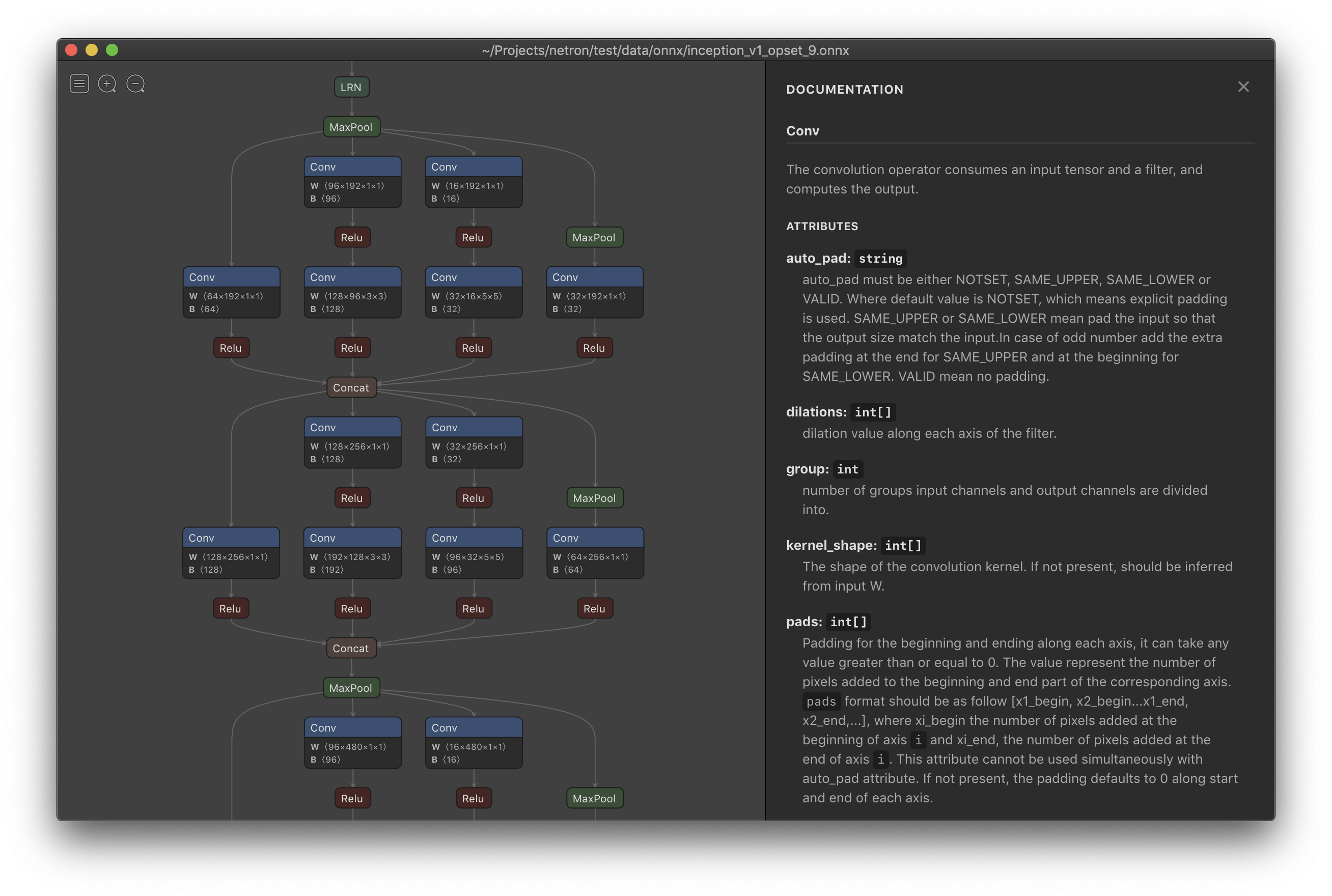
安装好之后,我们将前面3中保存的模型myInceptionResNetv2_for_cat_vs_dog.h5在Netron中打开。

贴出网络部分的结构示意图
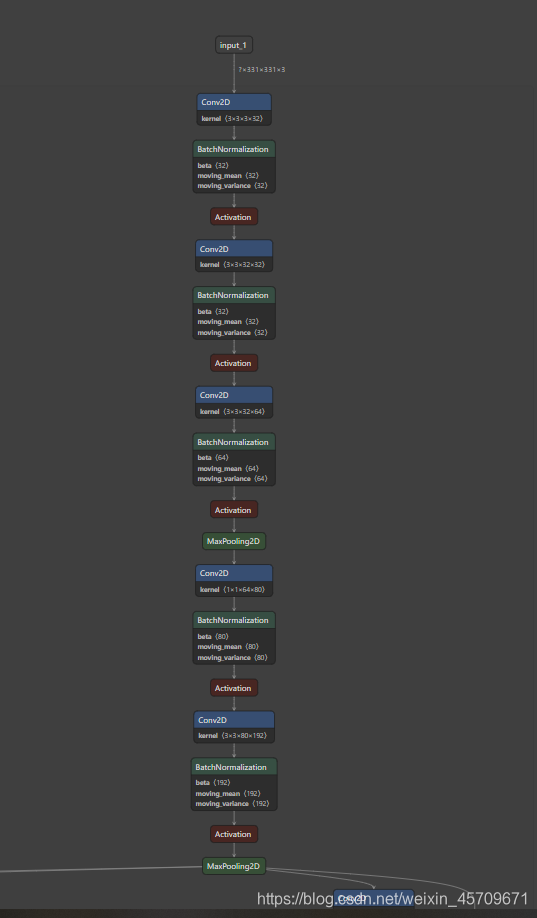
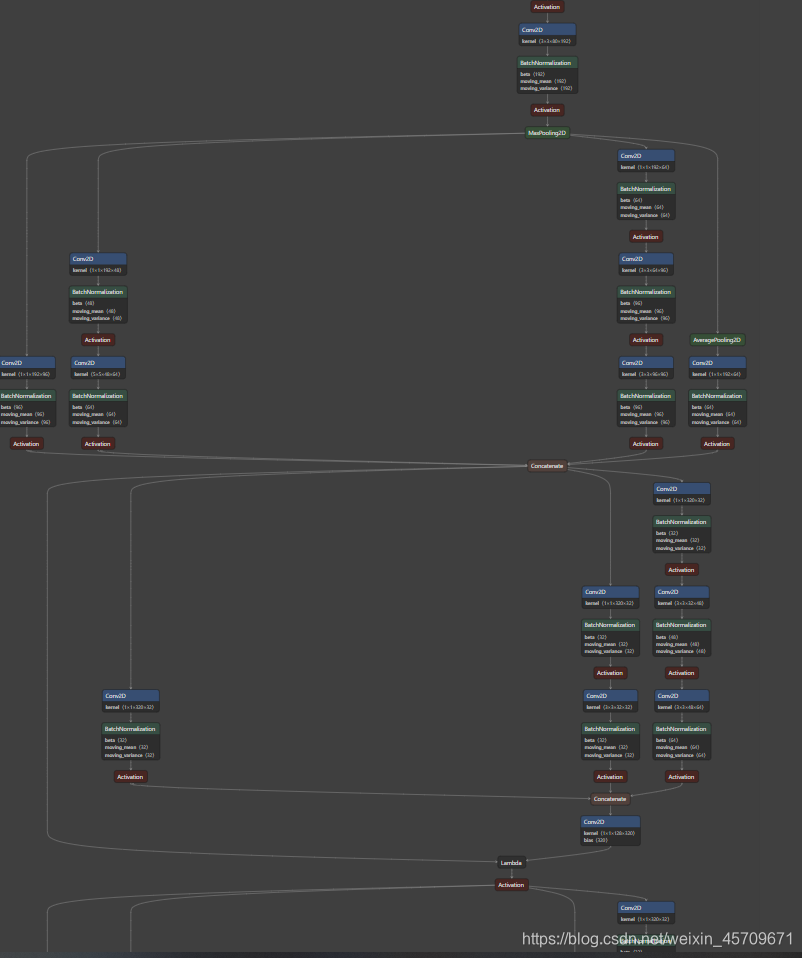
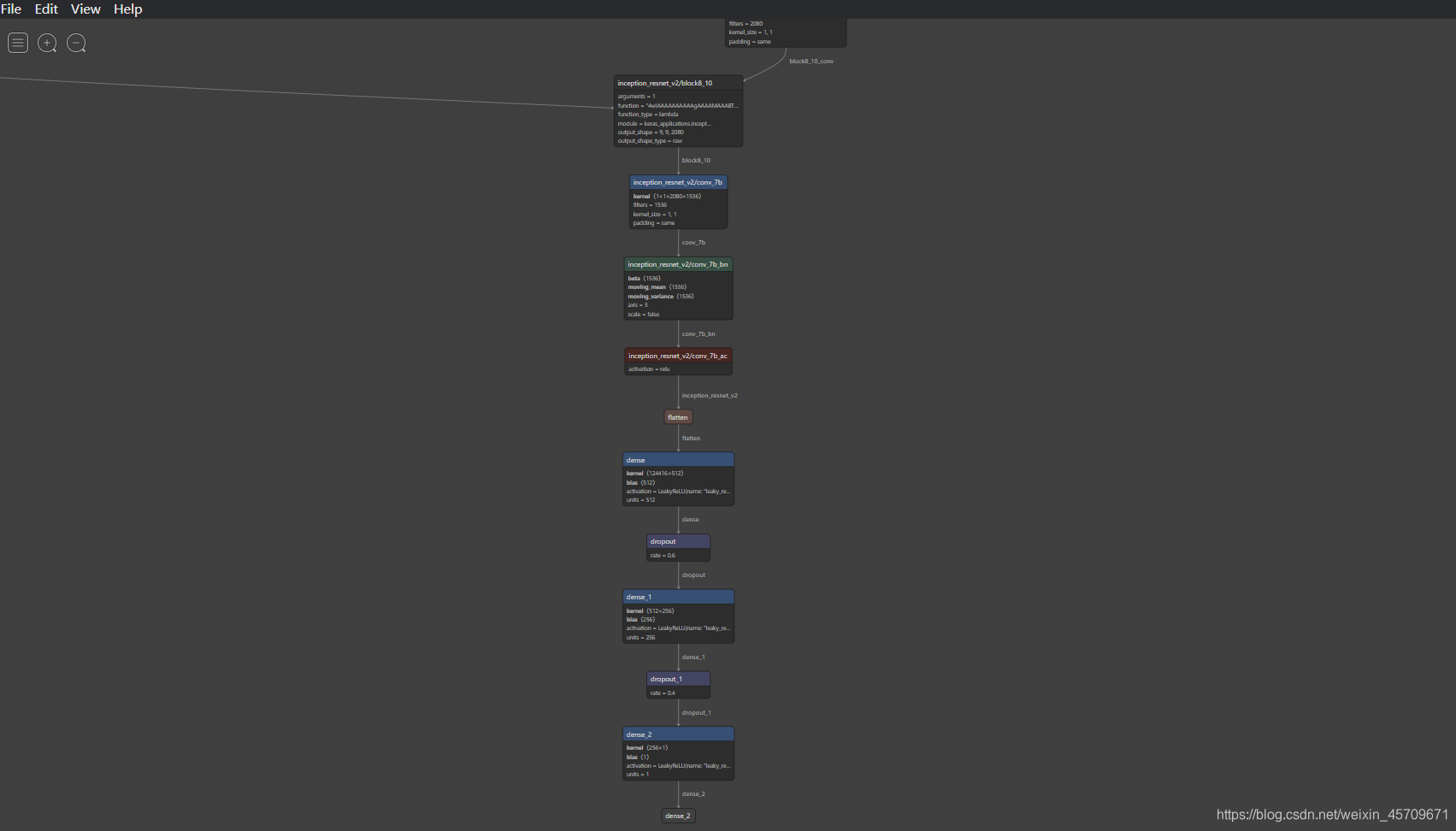
可以看出,InceptionResNetV2非常大,中间还有很多层由于空间不足,没有展示出来,这个工具很方便我们观察网络的结构。
后续还会有其他补充,学无止境。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号