初始Hadoop
Hadoop核心组件之分布式文件系统HDFSHadoop核心组件之资源调度系统yarnHadoop核心组件之分布式计算框架MapReduce侠义Hadoop VS 广义HadoopHadoop生态系统Hadoop生态系统Hadoop常用发行版即选型
Hadoop核心组件之分布式文件系统HDFS
-
源自于Google的GFS论文,论文发表于2003年10月
-
HDFS是GFS的克隆版
-
HDFS特点:扩展行&容错性&海量数据存储
-
拓展性:Hadoop集群上存在很多节点,如果以一个集群上100个节点为例,此时存储的文件大于这个节点数,那么最简单的方法就是增加机器(使集群上有100多个节点)
-
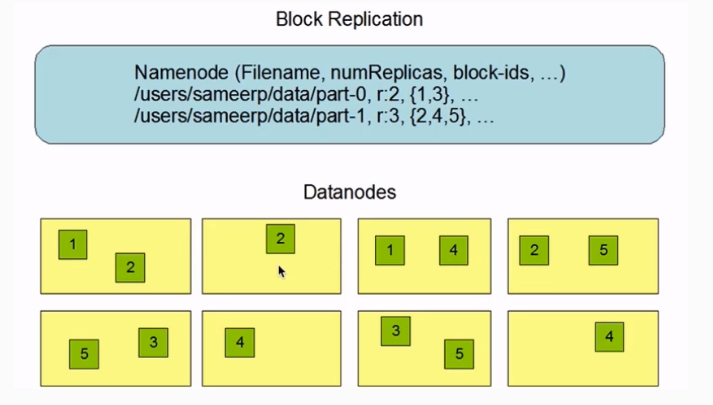
容错性:在hdfs上文件存储的方式是以多副本的方式存储,假设我们的的一个文件是100m的大小,如果你在hdfs设置的一个块的大小是128m,那么这个数据会存在一个块中,由于它支持容错,那么它会将这个块上的数据多存几份,假设默认存储三份,那么就在三台机器上都存储一个这个数据,如果有一天机器挂掉了,此时还有其它机器上副本。
-
海量数据存储
-
-
数据切分、多副本、容错等操作对用户是透明的
-
-
Hadoop核心组件之资源调度系统yarn
-
yarn:Yet Another Resource Negotiator
-
负责整个集群资源的管路和调度
-
yarn特点:扩展性&容错性&多框架资源统一调度
-
扩展性:如果计算能力不够,可以通过添加机器的方式提高计算能力。
-
容错性:作业在执行过程中,tast出现问题有什么异常的话,那么yarn这个资源调度系统就会对你当前这个任务进行一定次数的重试,重试的次数是可以都过我们打的参数控制的。
-
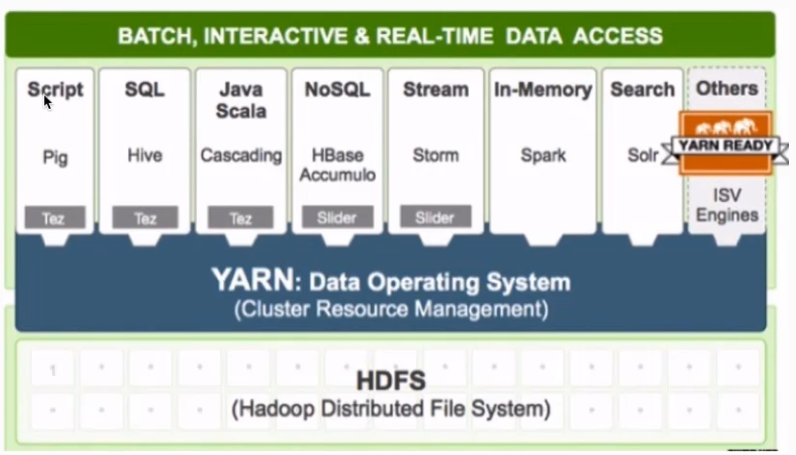
多框架资源统一调度:
Hadoop核心组件之分布式计算框架MapReduce
-
-
源自于Google的MapReduce论文,论文发表于2004年12月
-
MapReduce是Google MapReduce的克隆版
-
MapReduce特点:扩展性&容错性&海量数据离线处理
-
扩展性
-
容错性
-
海量数据离线处理:数据量大,实时处理数据慢,离线处理快
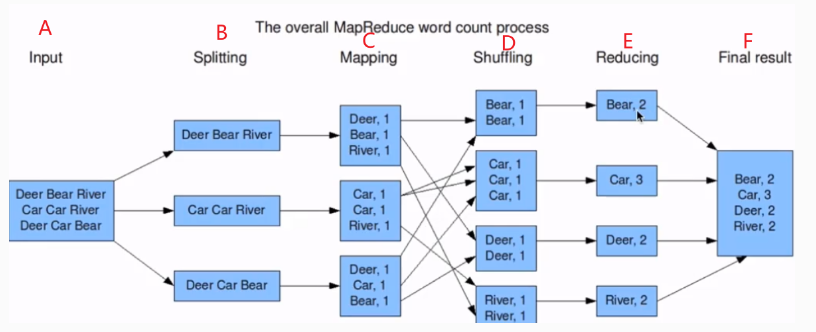
图分析:A里面包含很多数据,B对数据进行读取,按行读取,C(mapping)对所有数据进行统计不对数据进行合并操作,shuffling对数据进行筛选,redcing再多节点上对数据进行合并,最后数据实在一个文件上输出的。以上操作都是多节点操作。
-
-
Hadoop优势之高可靠性
-
数据存储:多数据多副本
-
数据计算:重新调度作业计算
-
-
Hadoop优势之高扩展性
-
存储/计算资源不够时,可以横向的线性扩展机器
-
一个集群可以包含数以千计的节点
-
-
Hadoop优势其它
-
存储在廉价的机器上,降低成本
-
成熟的神态圈
-
侠义Hadoop VS 广义Hadoop
-
侠义Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台;
-
广义Hadoop:指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,Hadoop是其中最重要基础的一个部分;生态系统的每一个子系统只解决某一个特定的问题域(甚至可能很窄),不搞统一性的一个全能系统,而是小而精的多个小系统;
Hadoop生态系统

Hadoop生态系统
-
开源、社区活跃
-
囊括可大数据处理的方方面面
-
成熟生态圈
Hadoop常用发行版即选型
-
apache Hadoop
-
cdh:cloudera distributed Hadoop
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号