21-4-30_innodb内幕
4.8.2 分区类型
1.Range分区
根据某一列的值的范围进行分区,使用VALUES LESS THAN语句
例如 id < 10 一个分区,
10<= id < 20 一个分区
此时插入 id = 30 的记录会报错,因为不符合分区定义,所以需要加入一个新的MAXVALUE(正无穷)的分区
RANGE主要用于日期列的分区,当搜索条件只在一个分区内时能加快搜索速度
2.LIST分区
和RANGE相似,只是分区列的值是离散的,非连续,使用VALUES IN语句
遇到未定义会抛异常
在insert插入多行数据时遇到一个分区未定义
-
innodb会视为一个事务,全部回滚
-
myisam会把之前的插入,之后的丢弃
3.HASH分区
目的:将数据均匀地分布到预定分区,保证数据量一致
需要制定列值或表达式,和分区数量
PARTITION BY HASH(expr),expr是列名或者表达式
PARTITIONS num,num是分区数量,不指明默认为1
LINEAR HASH:更加复杂算法
4.KEY分区
类似HASH分区,使用的是mysql的函数
innodb使用内部的哈希函数
5.COLUMNS分区
前四种的数据需要是整型,否则通过其他方法将其转化为整型
COLUMNS 可视为第一二种的进化,可以直接使用非整型数据
支持类型
- 所有整型类型:int ,smallint,bigint
- 日期类型:date,datetime
- 字符串:char,varchar,binary,varbinary
4.8.3 子分区
在分区的基础上再分区,复合分区
允许在range和list的分区上进行hash或key的分区
注意:
- 每个子分区数量相同
- 在一个分区表使用
SUBPARTITION定义子分区,就需要定义所有分区,不能跳过其中一个大分区 - 每个
SUBPARTITION子句需要包括子分区的一个名字 - 子分区名字唯一
4.8.4 分区中的NULL值
range类型会将其放于最左边分区,删除左边分区时含NULL记录也会被删除
list类型若允许分区需要在创建时指明哪个分区可以存放NULL值
hash和key类型变长0
4.5.6 在表和分区间交换数据
ALTER TABLE ... EXCHANGE PARTITION来允许分区或子分区的数据和非分区的表中数据进行交换
非分区表为空则是将分区表数据移到非分区表
分区表中数据为空,则是将外部数据导入分区
条件:
- 相同的表结构,被交换表不能有分区
- 非分区表的数据需要在交换的分区定义内
- 被交换的表不能有外键或者其他表有对其外键引用
- 用户需要有alter,insert, create, drop权限
- 不会触发表和被交换表的触发器
- auto_increment重置
第5章 索引和算法
5.1 innodb存储引擎索引概述
支持的索引
- B+树索引(balance)
- 全文索引
- 哈希索引:自适应,不能人为干涉
5.3 B+树的部分操作
5.4 B+树索引


5.4 B+树索引
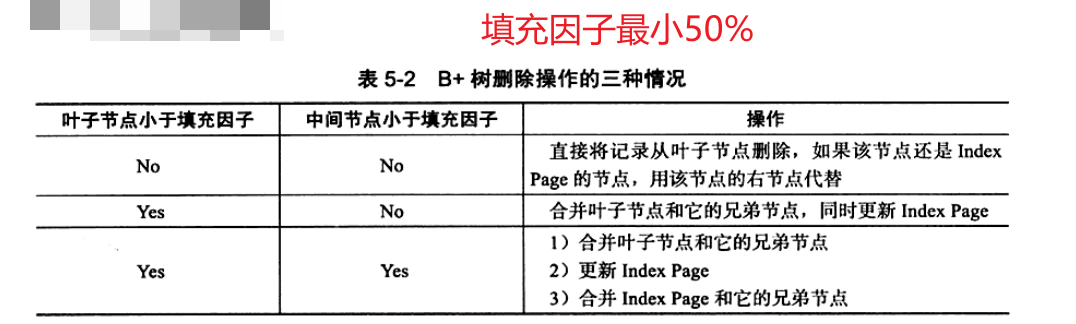
5.4.1 聚集索引
数据按主键顺序存储,聚集索引按主键构造B+树,叶子节点存放整张表的行记录,聚集索引的叶子节点称索引页,数据页都通过双向链表进行连接
一张表一个聚集索引,非数据页的索引页存放的是键值及指向数据页的偏移量,数据页存放的是完整的行记录
聚集索引按照逻辑顺序存储数据,页通过双向链表连接,页按照主键顺序排序,页中记录通过单向链表连接,物理上不按照主键顺序存储
聚集索引对于主键的排序查找和范围查找非常快
5.4.2 辅助索引
叶子节点不包含行记录,只包含键值外还包含了一个书签,叶级别指针获得指向主键索引的主键,再通过主键索引回表找到完整行记录
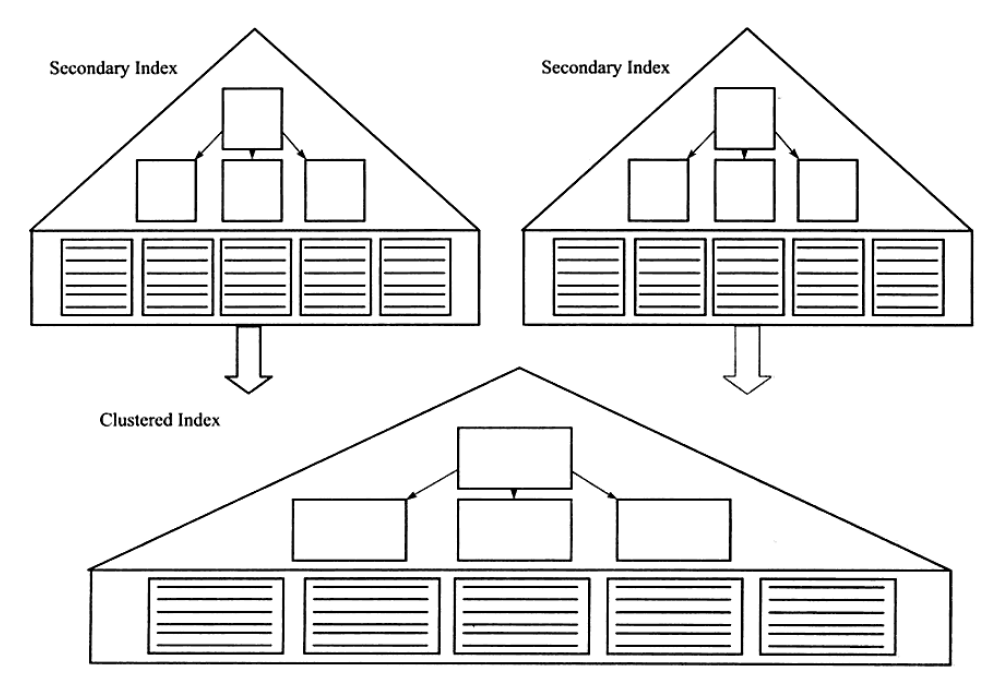
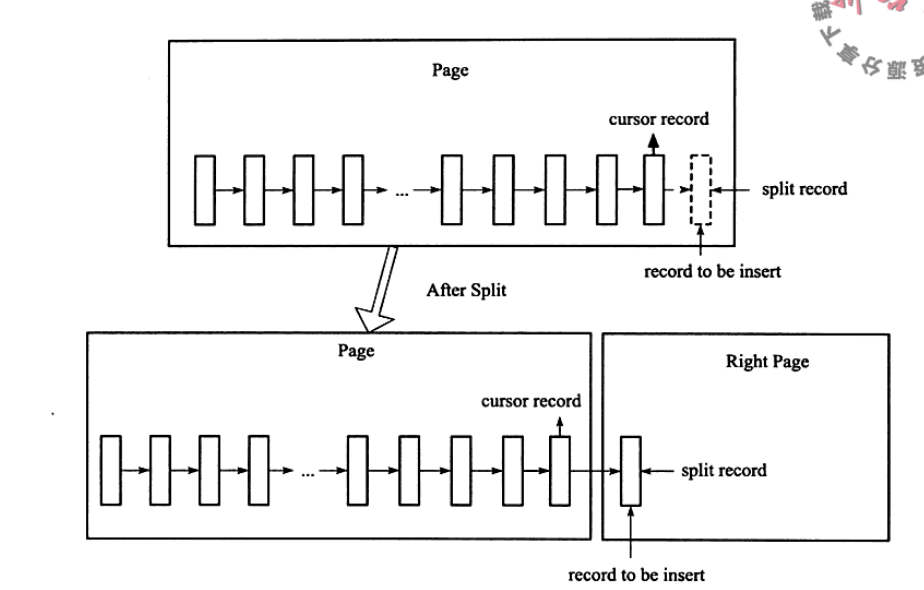
5.4.3 B+树索引的分裂
总是从中间分裂会导致空间的浪费
Page Header中有几个部分来保存插入的顺序信息
- page_last_insert
- page_direction
- page_n_direction
通过这些信息可以决定分裂点记录,是向左还是向右分裂
- 插入随机:页中间作为分裂点
- 若往同一方向进行插入的记录数量为5,则现在已经定位的记录(innodb插入前会进行定位,定位到的记录是待插入位置的前一个记录)后还有 3 条记录,则分裂点为定位到的记录后的第三个记录
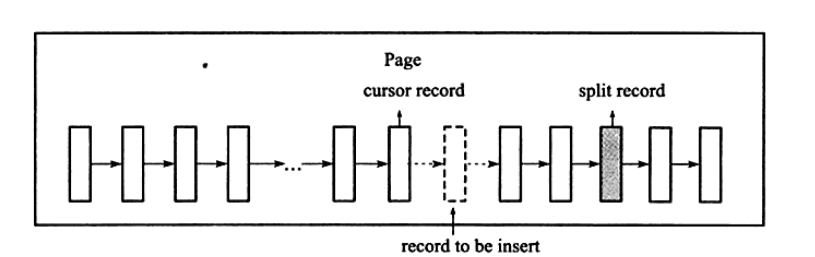
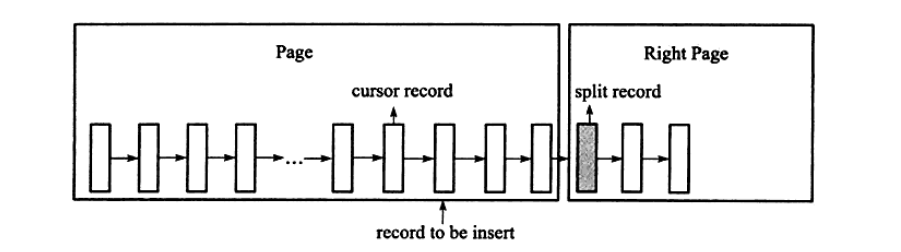
当分裂点为插入记录本身
5.4.4 索引管理
1.索引管理
创建和删除:
alter table
create / drop index

也可以索引前多少字节
alter table t add key idx_b(b(100));
查看索引信息
show index from p\G
*************************** 1. row ***************************
Table: p
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
Seq_in_index: 1
从1开始
Collation: A
B+树索引是A,排序,否则NULL
Cardinality: 0
索引唯一值的估计数,表示不重复记录的数目,如果非常小,可以考虑是否删除索引
Sub_part: NULL
是否列的部分被索引
Packed: NULL
关键字如何被压缩
Null:
是否索引的列含有NULL值
Cardinality:
-
索引唯一值的估计数,表示不重复记录的数目,优化器会根据这个来判断使用这个索引
-
大概的值,实时更新消耗大
-
ANALYZE TABLE来更新
2.Fast Index Creation
创建辅助索引:
对表加上S锁,不需要重建表
删除辅助索引:
更新内部视图,将辅助索引空间标为可用,同时删除内部视图对该表的索引定义
对主键的创建删除需要重建一张表
4.Online DDL
- 创建辅助索引与删除
- 改变自增长值
- 添加或删除外键约束
- 列的重命名
创建方式:

ALGORITHM:创建或删除索引的算法
- copy:创建临时表
- inplace:不需要创建临时表
- default:通过
old_alter_table判断是以上哪种,默认off
LOCK:加锁情况
- NONE:不加任何锁,事务正常进行,不阻塞,最大并发度
- SHARE:S锁
- EXCLUSIVE:X锁
- DEFAULT:从上述三个一个个判断
原理:将inert、update、Delete等操作写入缓存,等索引创建后再重做
innodb_online_alter_log_max_size控制缓存大小,128MB
5.5 Cardinality值
5.5.1 概念
在访问表中很少部分时才使用B+树索引
性别、地区、类型等取值范围小,低选择性
范围广,基本没有重复,高选择性
Cardinality:索引唯一值的估计数,表示不重复记录的数目,预估值
Cardinality / 表中记录数 == 1则很有必要
如果Cardinality太小,则没有必要
5.5.3 Cardinality统计
对Cardinality的统计使用采样
统计策略:
-
1 / 16 的数据发生变化
-
stat_modified_counter > 20 0000 0000,变化发生的次数
(mysql8.0找不到)
采样过程:
- B+树叶子节点数量A
- 随机获得 8 个叶子节点,统计每个页中不同记录的个数 P1 - P8
Cardinality = (p1 + ... + P8) * A / 8
则每次得到的值可能不同
innodb_stats_transient_sample_pages控制采样多少页面
innodb_stats_method判断Null,默认nulls_equal,表示null相等,nulls_unequal不等,nulls_ignored忽略
analyze table、show table status、show index及访问information_schema的tables和statistics会重新计算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号