
Linux内核情景分析之异常访问,用户堆栈的扩展
情景假设:
在堆内存中申请了一块内存,然后释放掉该内存,然后再去访问这块内存。也就是所说的野指针访问。
当cpu产生页面错误时,会把失败的线性地址放在cr2寄存器.线性地址缺页异常的4种情况
1.如果cpu访问的行现地址在内核态,那么很可能访问的是非连续区,需要vmalloc_fault处理.
2.缺页异常发生在中断或者内核线程时,直接失败,因为不可修改页表
3.地址在一个区间内,那就可能是已经物理地址映射了但权限问题(错误处理)或者其物理地址没有分配(分配物理内存)
4.如果找到一个在线性地址其后面的vma(线性地址在空洞).那么可能是空洞上面的区间是
堆栈区,他表示动态分配而没有分配出去的空间,有一种特殊情况,可以缺页异常使得获取物理页框
5.如果找到一个线性地址气候的vma(线性地址在空洞),那么可能是空洞上面的区间不是堆栈区,说明
这个空洞是由于一个映射区被撤销而留下的,那样直接错误处理

==================== arch/i386/mm/fault.c 106 152 ====================106 asmlinkage void do_page_fault(struct pt_regs *regs, unsigned long error_code)107 {108 struct task_struct *tsk;109 struct mm_struct *mm;110 struct vm_area_struct * vma;111 unsigned long address;112 unsigned long page;113 unsigned long fixup;114 int write;115 siginfo_t info;116117 /* get the address */118 __asm__("movl %%cr2,%0":"=r" (address));//得到失败的线性地址119120 tsk = current;//获取当前描述符121122 /*123 * We fault-in kernel-space virtual memory on-demand. The124 * 'reference' page table is init_mm.pgd.125 *126 * NOTE! We MUST NOT take any locks for this case. We may127 * be in an interrupt or a critical region, and should128 * only copy the information from the master page table,129 * nothing more.130 *///如果大于3G,表示缺页异常时,访问的是内核空间,很有可能是访问了非连续的内核空间,转到vmalloc_fault处理131 if (address >= TASK_SIZE)132 goto vmalloc_fault;133134 mm = tsk->mm;135 info.si_code = SEGV_MAPERR;136137 /*138 缺页异常发生在中断时,是错误不可以的,表示是内核线程,不可以对其页表进行修改140 */141 if (in_interrupt() || !mm)142 goto no_context;143144 down(&mm->mmap_sem);145146 vma = find_vma(mm, address);//查到end大于address的地址147 if (!vma)//是否在行现地址内,不在转为错误处理148 goto bad_area;//在线性区内,跳到正常处理部分,可能是由于权限问题,也有可能是对应的物理地址没有分配2种情况149 if (vma->vm_start <= address)150 goto good_area;151 if (!(vma->vm_flags & VM_GROWSDOWN))//如果发生在一空洞上方的区间不是堆栈区,那么此地址是由于撤销映射留下的,进行错误处理152 goto bad_area;
220 /*221 * Something tried to access memory that isn't in our memory map..222 * Fix it, but check if it's kernel or user first..223 */224 bad_area:225 up(&mm->mmap_sem);226 //用户态的错误处理227 bad_area_nosemaphore:228 /* User mode accesses just cause a SIGSEGV */229 if (error_code & 4) {//判断错误发生在用户态230 tsk->thread.cr2 = address;231 tsk->thread.error_code = error_code;232 tsk->thread.trap_no = 14;233 info.si_signo = SIGSEGV;//强制发送SIGEGV信号
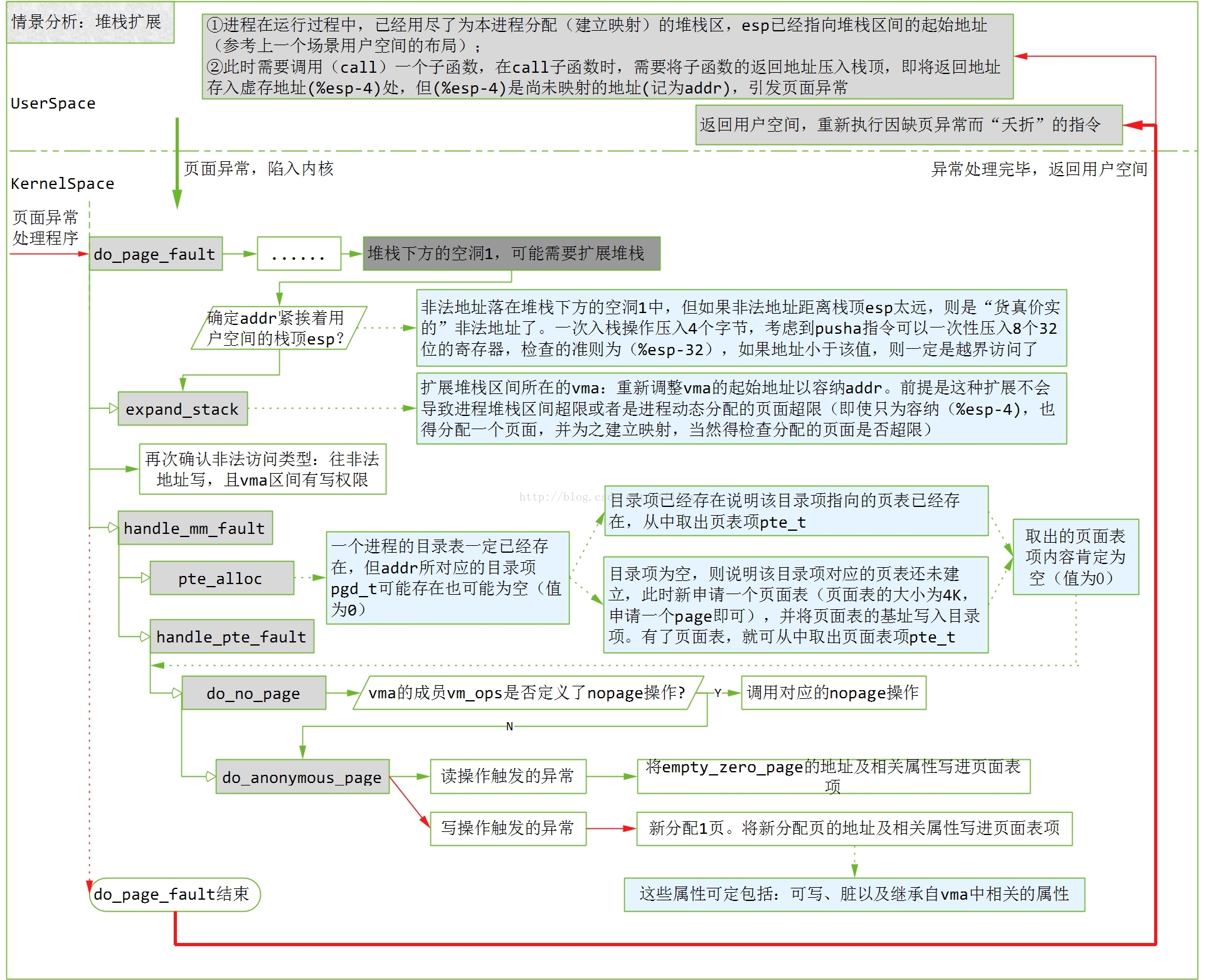
上面提到的第4种情况,因为越界访问而照成堆栈区间扩展的情况
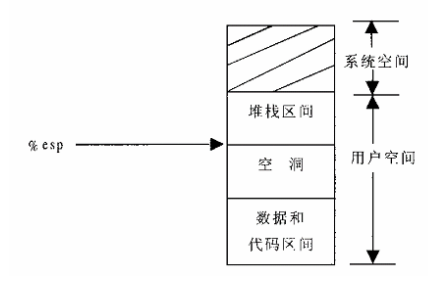
比如一进城要调用某个子程序,cpu需要把返回地址压栈,然而返回地址写入的是空洞地址,会引发一次页面异常错误
VM_GROWDOWN表示为1表示上面是堆栈区
if (!(vma->vm_flags & VM_GROWSDOWN))152 goto bad_area;153 if (error_code & 4) {154 /*155 * 还要检查异常地址是否紧挨着esp指针,如果远超过32,那就是非法越界,错误处理32是因为pusha(一次把32个字节压入栈中)159 */160 if (address + 32 < regs->esp)161 goto bad_area;162 }//扩展堆栈163 if (expand_stack(vma, address))164 goto bad_area;
有下面注释可知,expand_stack只是更改了堆栈区的vm_area_struct结构,没有建立物理内存映射
static inline int expand_stack(struct vm_area_struct * vma, unsigned long address)490 {491 unsigned long grow;492493 address &= PAGE_MASK;//边界对齐494 grow = (vma->vm_start - address) >> PAGE_SHIFT;//增长几个页框//判断是否超过了用户堆栈空间大小限制495 if (vma->vm_end - address > current->rlim[RLIMIT_STACK].rlim_cur ||496 ((vma->vm_mm->total_vm + grow) << PAGE_SHIFT) > current->rlim[RLIMIT_AS].rlim_cur)497 return -ENOMEM;498 vma->vm_start = address;//重新设置虚拟地址499 vma->vm_pgoff -= grow;//偏移减去grow500 vma->vm_mm->total_vm += grow;//地址空间大小501 if (vma->vm_flags & VM_LOCKED)502 vma->vm_mm->locked_vm += grow;503 return 0;504 }
[do_page_fault()]165 /*166 * Ok, we have a good vm_area for this memory access, so167 * we can handle it..168 */169 good_area:170 info.si_code = SEGV_ACCERR;171 write = 0;172 switch (error_code & 3) {173 default: /* 3: write, present */174 #ifdef TEST_VERIFY_AREA175 if (regs->cs == KERNEL_CS)176 printk("WP fault at %08lx\n", regs->eip);177 #endif178 /* fall through */179 case 2: /* write, not present */180 if (!(vma->vm_flags & VM_WRITE))//堆栈段可读可写,调到196行181 goto bad_area;182 write++;183 break;184 case 1: /* read, present */185 goto bad_area;186 case 0: /* read, not present */187 if (!(vma->vm_flags & (VM_READ | VM_EXEC)))188 goto bad_area;189 }190191 /*192 * If for any reason at all we couldn't handle the fault,193 * make sure we exit gracefully rather than endlessly redo194 * the fault.195 */196 switch (handle_mm_fault(mm, vma, address, write)) {197 case 1:198 tsk->min_flt++;199 break;200 case 2:201 tsk->maj_flt++;202 break;203 case 0:204 goto do_sigbus;205 default:206 goto out_of_memory;207 }
[do_page_fault()>handle_mm_fault()]1189 /*1190 * By the time we get here, we already hold the mm semaphore1191 */1192 int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct * vma,1193 unsigned long address, int write_access)1194 {1195 int ret = -1;1196 pgd_t *pgd;1197 pmd_t *pmd;11981199 pgd = pgd_offset(mm, address);//获取该地址所在页面目录项的指针(页表的地址)1200 pmd = pmd_alloc(pgd, address);//分配pmd目录12011202 if (pmd) {1203 pte_t * pte = pte_alloc(pmd, address);//分配pte表现1204 if (pte)//分配物理地址1205 ret = handle_pte_fault(mm, vma, address, write_access, pte);1206 }1207 return ret;1208 }
[do_page_fault()>handle_mm_fault()>pte_alloc()]120 extern inline pte_t * pte_alloc(pmd_t * pmd, unsigned long address)121 {122 address = (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);//给定地址转换为页表的下标,用于定位页表项124 if (pmd_none(*pmd))//如果pmd所指向的页表为空,那就转到getnew分配125 goto getnew;126 if (pmd_bad(*pmd))127 goto fix;128 return (pte_t *)pmd_page(*pmd) + address;129 getnew:130 {131 unsigned long page = (unsigned long) get_pte_fast();//从缓冲池获取(释放页表,并非一定会释放物理地址)132133 if (!page)134 return get_pte_slow(pmd, address);135 set_pmd(pmd, __pmd(_PAGE_TABLE + __pa(page)));//写入中间pmd136 return (pte_t *)page + address;137 }138 fix:139 __handle_bad_pmd(pmd);140 return NULL;141 }
[do_page_fault()>handle_mm_fault()>handle_pte_fault()]1135 /*1136 * These routines also need to handle stuff like marking pages dirty1137 * and/or accessed for architectures that don't do it in hardware (most1138 * RISC architectures). The early dirtying is also good on the i386.1139 *1140 * There is also a hook called "update_mmu_cache()" that architectures1141 * with external mmu caches can use to update those (ie the Sparc or1142 * PowerPC hashed page tables that act as extended TLBs).1143 *1144 * Note the "page_table_lock". It is to protect against kswapd removing1147 * we can drop the lock early.1148 *1149 * The adding of pages is protected by the MM semaphore (which we hold),1150 * so we don't need to worry about a page being suddenly been added into1151 * our VM.1152 */1153 static inline int handle_pte_fault(struct mm_struct *mm,1154 struct vm_area_struct * vma, unsigned long address,1155 int write_access, pte_t * pte)1156 {1157 pte_t entry;11581159 /*1160 * We need the page table lock to synchronize with kswapd1161 * and the SMP-safe atomic PTE updates.1162 */1163 spin_lock(&mm->page_table_lock);1164 entry = *pte;//pte对应的物理地址当然没有,所以为null1165 if (!pte_present(entry)) {//检查其对应的物理地址否为空1166 /*1167 * If it truly wasn't present, we know that kswapd1168 * and the PTE updates will not touch it later. So1169 * drop the lock.1170 */1171 spin_unlock(&mm->page_table_lock);1172 if (pte_none(entry))//页表项内容为0,表明进程未访问过该页1173 return do_no_page(mm, vma, address, write_access, pte);//调用do_no_page分配//否则换出1174 return do_swap_page(mm, vma, address, pte, pte_to_swp_entry(entry), write_access);1175 }11761177 if (write_access) {1178 if (!pte_write(entry))1179 return do_wp_page(mm, vma, address, pte, entry);11801181 entry = pte_mkdirty(entry);1182 }1183 entry = pte_mkyoung(entry);1184 establish_pte(vma, address, pte, entry);1185 spin_unlock(&mm->page_table_lock);1186 return 1;1187 }1145 * pages from under us. Note that kswapd only ever _removes_ pages, never1146 * adds them. As such, once we have noticed that the page is not present
[do_page_fault()>handle_mm_fault()>handle_pte_fault()>do_no_page()]1080 /*1081 * do_no_page() tries to create a new page mapping. It aggressively1082 * tries to share with existing pages, but makes a separate copy if1083 * the "write_access" parameter is true in order to avoid the next1084 * page fault.1085 *1086 * As this is called only for pages that do not currently exist, we1087 * do not need to flush old virtual caches or the TLB.1088 *1089 * This is called with the MM semaphore held.1090 */1091 static int do_no_page(struct mm_struct * mm, struct vm_area_struct * vma,1092 unsigned long address, int write_access, pte_t *page_table)1093 {1094 struct page * new_page;1095 pte_t entry;10961097 if (!vma->vm_ops || !vma->vm_ops->nopage)1098 return do_anonymous_page(mm, vma, page_table, write_access, address);//只是其封装而已......==================== mm/memory.c 1133 1133 ====================1133 }
[do_page_fault()>handle_mm_fault()>handle_pte_fault()>do_no_page()>do_anonymous_page()]1058 /*1059 * This only needs the MM semaphore1060 */1061 static int do_anonymous_page(struct mm_struct * mm, struct vm_area_struct * vma, pte_t *page_table,int write_access, unsigned long addr)1062 {1063 struct page *page = NULL;//如果引起页面异常是一次读操作,那么由mk_pte构建的映射表项要通过pte_wrprotect修正,只读属性//同时对于只读的页面,一律映射ZERO_PAGE同一个物理内存页面,也即是内容全部为0,只有可写才独立分配内存1064 pte_t entry = pte_wrprotect(mk_pte(ZERO_PAGE(addr), vma->vm_page_prot));1065 if (write_access) {1066 page = alloc_page(GFP_HIGHUSER);//分配独立物理页面1067 if (!page)1068 return -1;1069 clear_user_highpage(page, addr);//下面相同.只可写属性1070 entry = pte_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot)));1071 mm->rss++;1072 flush_page_to_ram(page);1073 }//虚拟页面到物理内存页面映射建立1074 set_pte(page_table, entry);1075 /* No need to invalidate - it was non-present before */1076 update_mmu_cache(vma, addr, entry);1077 return 1; /* Minor fault */1078 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号