
python自动化测试课程总结之第三周学习总结
课程从第三周才赶上直播课程,第一二周做一次总结,不在此次博文中.
第三次课程主要内容是第二周课后作业讲解,函数以及参数和返回值,匿名函数以及3个常见高阶函数和sorted函数,文件操作,异常处理,最后是面向对象的基础.
整体来说,我将其分成这几个部分.
第一部分就是作业讲解,也就是回顾之前的内容:常见的几种数据类型(简单类型,即字符,数值,布尔量;复合类型,元祖,列表,字典,集合),就使用经验来看,复合数据类型,列表和字典或者二者相互嵌套使用最多,简单类型一般嵌套在前二者中,其他类型数据也需要掌握,因为这是python语法基础.也有很大频率使用到.例如布尔量或者表达式用于if判断或者列表生成式中,filter函数中,也是布尔量的体现.
例如,在下面的res变量中,存放的就是1-20中能被3整除的整数,列表的形式存放,这里就是布尔量的应用
res=list(filter(lambda x: x % 3 == 0, range(1, 21)))
第二部分是函数,在python脚本开发以及其它应用,很少按照一行一行的方式将代码从文件第一行到最后一行堆叠,既不利于复用,结构也不清晰,也不能利于多人共同开发需要,所以一般都是模块化,函数就是解决这一问题的一种方式.将相同功能的代码块写在一起,将一些变量抽象提取出来,使得函数在其他地方需要多次使用时,只需传入参数,书写少量代码即可使用函数完成相功能.
def add(a,b):
pass
上面一个最简单的函数定义,def是固定的关键字,不必深究,add是函数名称,代表这个函数,括号里面的a,b均为参数,当然参数个数和类型由实际情况决定,也可以没有参数,一个参数或者多个参数,python语言的灵活性,参数类型虽然可以申明,但是不会影响后续传值的类型,增强代码可读性.
先说函数参数,参数分为4类,
'''
1.位置参数,也就是最常见的
def add(a,b):
return a+b
这里的a,b就是位置参数,传的参数按照调用时先后顺序一一对应
c=add(20,30) a=20 c=30
2.默认参数,给某些函数一个初始默认值,
当调用时这个参数没传参时使用该默认值,否则使用传入的值
def add(a,b=20):
return a+b
此处b就是默认值,调用可以不给传入值
c=add(20,30)
c=add(20)
以上调用都是正确的
另外,默认参数是要放在位置参数之后,否则会在运行时报错
3.关键字参数
体现在调用的时候,每个参数值用键值对的形式传入,例如a=20
这样传参时每个参数传入顺序就可以随意,而不需要记住每个参数先后顺序
def add(a,b=20):
return a+b
c=add(a=20,b=30)
d=add(b=15,a=15)
4.不定长参数
有时候参数长度或者类型都不确定的时候,可以使用不定长参数
def add(*arg):
return sum(arg)
这个函数可以计算并返回传入的几个参数的值
c=add(1,2,3,4)
c的值为10
关键字位置参数
def add(**kwargs):
print(kwargs)
此时传入的键值对(a=1,c=2,...)形成字典
add(a=2,c=5,t=7)
打印
{'a': 2, 'c': 5, 't': 7}
不定长参数需要放在其他几种参数之后
**kwargs 需要放在*args之后
kwargs 和args名字随意,可以按照需求自己设定
'''
其次是函数的返回值,严格的来说函数都是有返回值的,没有写return语句的函数可以认为也返回了None,当然这个不重要.有些函数只是完成一件事情,并不需要给调用的代码块一个明确结果,例如把数据写入文件,是否写入成功以其他方式检验.根据需求,一部分函数需要有返回值,例如根据顾客的VIP等级给予不同程度的打折,而基于商品价格和折扣程度,需要返回一个打折后的价格,此时需要返回值,在调用时可拿到返回值.
函数的返回值可以为空(解释器自行返回None),可以为一个对象,但是不能是1个以上.如果遇到多个数据或者其他负责类型数据需要返回,可以使用元祖,列表,字典或者自定义其他类型,总之,返回最多一个对象.
在函数的使用中,有几个高阶函数和匿名函数经常搭配使用(只是习惯性搭配使用,并非不可以单独使用)
匿名函数,即用关键字lambda:+表达式组成的函数,常用于定义一些简单逻辑,好处是不需要def语句,随写随用.甚至可以直接在定义时调用,例如:
![]()

尽管语法上没有错误,但是一般都不会这样调用.用于map,filter,reduce,sorted等函数中.
map函数,可以将一个可迭代对象中的元素逐一取出来,参与到其中func函数中运算得到的值依次存入一个新的可迭代对象中,map函数返回这个可迭代对象, 可以转化成列表或者直接遍历操作;
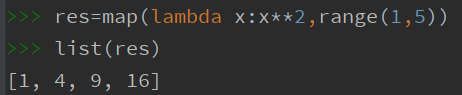
值得注意的是,map函数的对象在转化成列表后,对象已经被清空,转化成的列表也为空列表
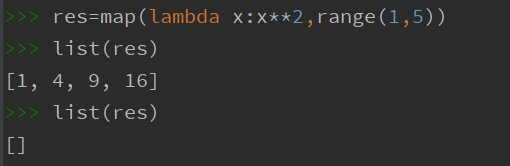
filter函数是用于筛选数据,从传入的可迭代对象中依次取值参与func函数运算,让每次运算结果为True的元素留下来,其余被筛选掉.

容易看出,能被3整除的数字留下来,其余的被筛选掉,同样值得注意的是,filter函数的对象在转化成列表后,对象也被清空,转化成的列表也为空列表
reduce函数不能直接使用,在使用前需要import语句引入

这是python自带库,不需要下载即可使用
reduce这个单词有减少,简约,简化的作用.
在python的作用将传入的可迭代对象,按照func函数参数个数依次取值,参与运算,得到的结果继续与未取到的值参与同样的运算,直到遍历完成.下面一个实例说明
![]()

这里就是将列表中的元素依次取出,参与运算,得到最终结果15.
将1和2取出,分别作为x,y传入参数,计算得到结果3
将上一步计算结果3和列表中的3相加,计算得到结果6
将上一步计算结果6和列表中的4相加,计算得到结果10
将上一步计算结果10和列表中的5相加,计算得到结果15,此时遍历结束,返回最终结果15.
另外,reduece还可以跟第三个参数(原本有一个默认参数,具体值我也还不清楚,前者做加法时应该为0,做乘法时应该为1),
事实上,默认参数先和第一个值参与运算,然后再依次取值运算(也可能是直接和最后一次远算结果一起参与函数运算).
这里给第三个函数传一个值100,
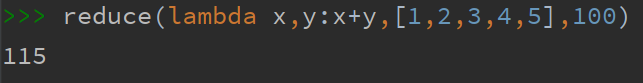
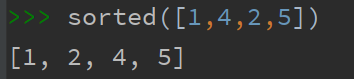
sorted函数可以用于排序,例如:
也可以对指定排序方式,例如:

这里就是运用lambda函数,按照类表中数值的倒数排序
此外,也可以对元素为字典的列表排序

这里就是典型的,按照每个元素(字典)name对应的值排序,遵循ASCII码排序的结果
第三部分是文件的操作,即使用open函数打开磁盘上的文件,用于读或者写
f=open(filename,mode,encoding) 三个参数分别代表文件路径,读取方式(读/写,追加,以及是否为二进制方式),编码方式(指定以什么方式读取文件内容)
文件句柄对象f常用的方法read() ,不传参数时用于读取整个文件为一个字符串,传入整数,即读取指定个数字符.readline()读取一行内容,包括换行符.readlines()读取文件所有内容,并且按照行分割形成一个列表
除了读还有写的方法,write()需要传入一个字符串做为参数,否则会报错.writelines()既可以传入字符串又可以传入一个字符序列,并将该字符序列写入文件
当然文件的读写一定要遵循打开方式,即只读文件不能用于写(否则会报错).而用只写方式打开的文件会被清空,读方法使用没有意义.
第四个部分是python异常处理,Python语句在执行过程中,由于编译人员的失误或者程序运行环境原因(例如网络不通畅,文件不存在等)导致报错,使得程序不能继续执行下去,需要异常处理机制.
使用try...except 语句块可以对出现的异常进行捕获,并作相应的操作(改变执行方式,打印报错信息,记录到日志).这里的异常,一般也叫做错误.
![]()
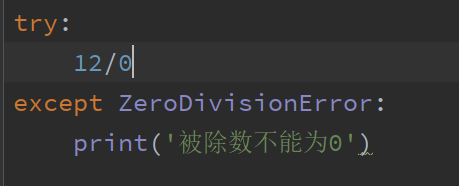
在函数中,12/0会报错,所以放在try...except语句块中,用于捕获这个错误,并且这里指定了具体的错误类型,也就是只捕获它和它的子类的错误,当然也可以不指定,捕获所有错误类型.
另外,还可以在except语句后面跟上else语句块或者finally语句块,组合其它的作用如下图:

except语句后面可以不跟报错类型,也可以跟多个类型(用元组或者列表方式以一个对象呈现)
当然捕获到的异常也可以用一个对象保存下来,便于其他操作,例如:
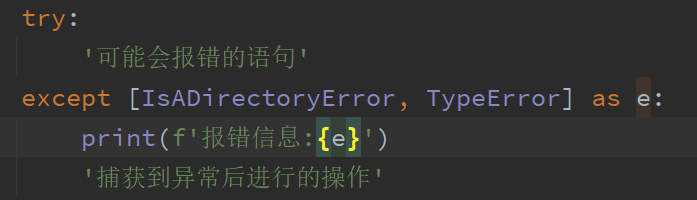
这里的e就是这个报错信息的对象,可以用于打印报错详细信息.
另外,在有的时候,代码本身能够正常执行,但由于业务需求,也会认为抛出一些异常,让程序终止或者让上层调用者处理异常
使用raise 语句,进行指定异常的抛出动作
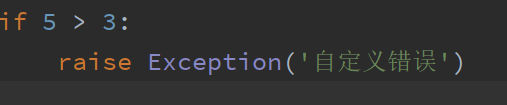
最后一个部分就是类的学习,这也是python语言最重要的思想的体现(个人认为).
和其他面向对象的语言一样,python也是保留用类的方式将实体实物抽象化,形成一个个的类,并作为python语言最终的数据表现形式.
python语言的任何数据形式都是类和类的实例(表述可能有误),同时类具备属性和方法,分别映射到现实事物的特性和事物能够做的事情.
可以把类理解成我们平时复印文件时候用的原件,而实例化的对象就是复印件.所以,按照这种对应关系,实例化对象具备类所拥有的属性和方法.
下面是定义一个学生信息的类:
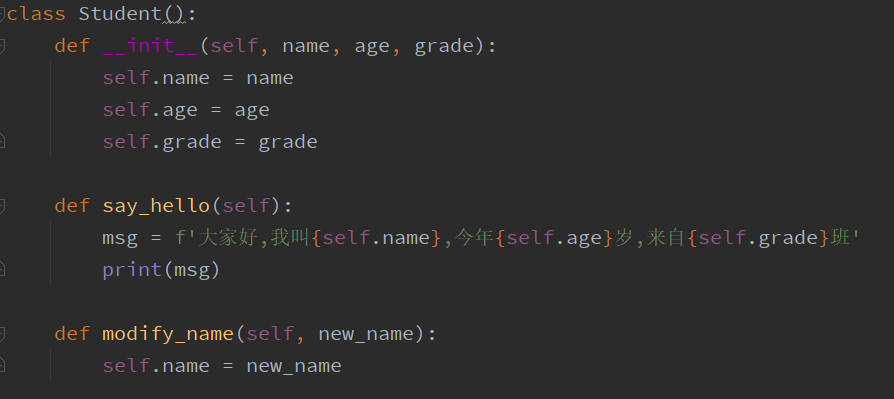
这里class是定义类的关键字,是语法规则,Student是类的名称,当然也对应内存中一个区域,这里的小括号可以省略掉,但是如果需要继承自其他类时,需要将被继承的类名写在括号内.
在类的内部,可以定义方法和属性.上面实例中,定义了三个方法(在类的内部,将函数称作方法),而此处的__init__方法,则是python定义属性的专用方法,当然此__init__方法不是必须的,
因为python解释器对基类(所有的类都继承自基类)已经定义__init__方法,我们只需要根据需求,重新定义它(或者说是改写),为设置属性.此方法会在实例化的时候自动调用.另外两个方法,
名称里面双下划线,是普通方法,类似于前面定义的函数,只不过对象的本身也是其中的一个参数,这里的self都是代表实例化后的对象本身.say_hello,modify都定义了自己的语句块,在调用时
执行相应代码.下面是实例化的过程,代码中实例化出两个对象,并且调用相应的方法:
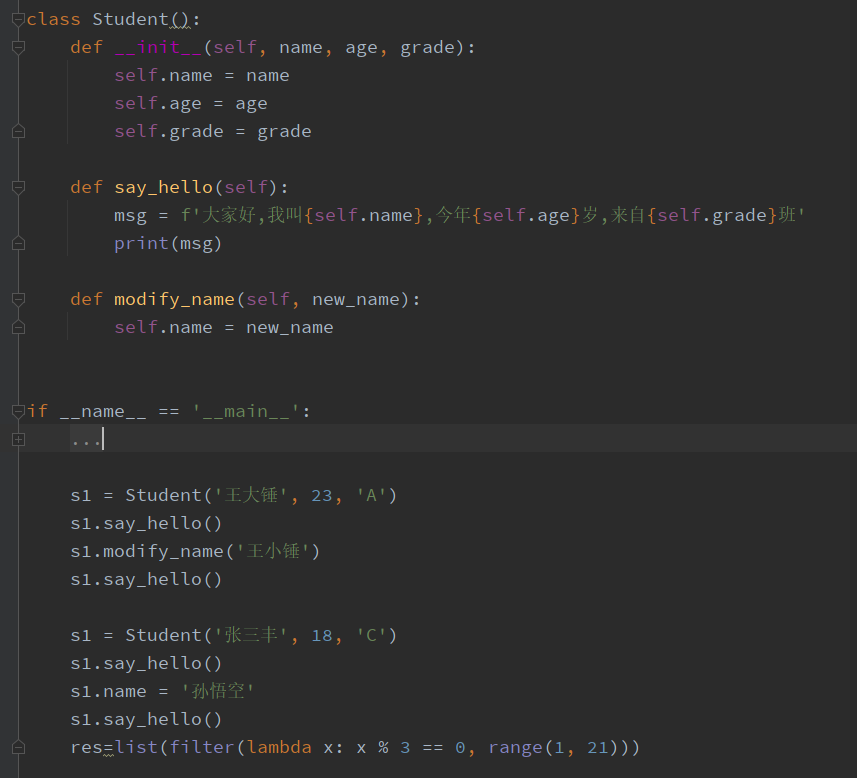
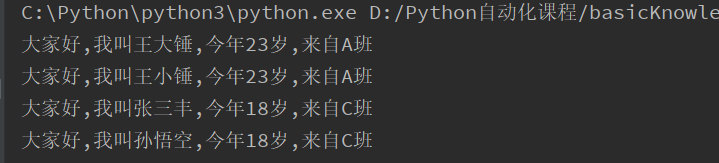
s1先调用say_hello打印个人信息,然后调用modify_name修改自己的姓名(name),再次打印个人信息,可以看到两次的变化,代表姓名修改成功.
在python中,我们可以认为一切皆对象,我们学习最基础的数据类型,例如数值2,字符串"name",列表[1,2,3]都是python中某个类的实例化对象,分别对应了int类,str类,list类.
按照python语法规则,类的名称应该大写,只不过这里是解释器做了特殊设计. 例如 a=list((1,2,3)) 这里也就是list类的实例化过程,将元祖(1,2,3)作为参数传入.
以上便是第三周课程的总结内容.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号