建库原理
湿实验好久没做,防止基础知识不牢固,最近看到一篇建库的文章,觉得不错,搜集如下:
转载自知乎 https://zhuanlan.zhihu.com/p/25190448
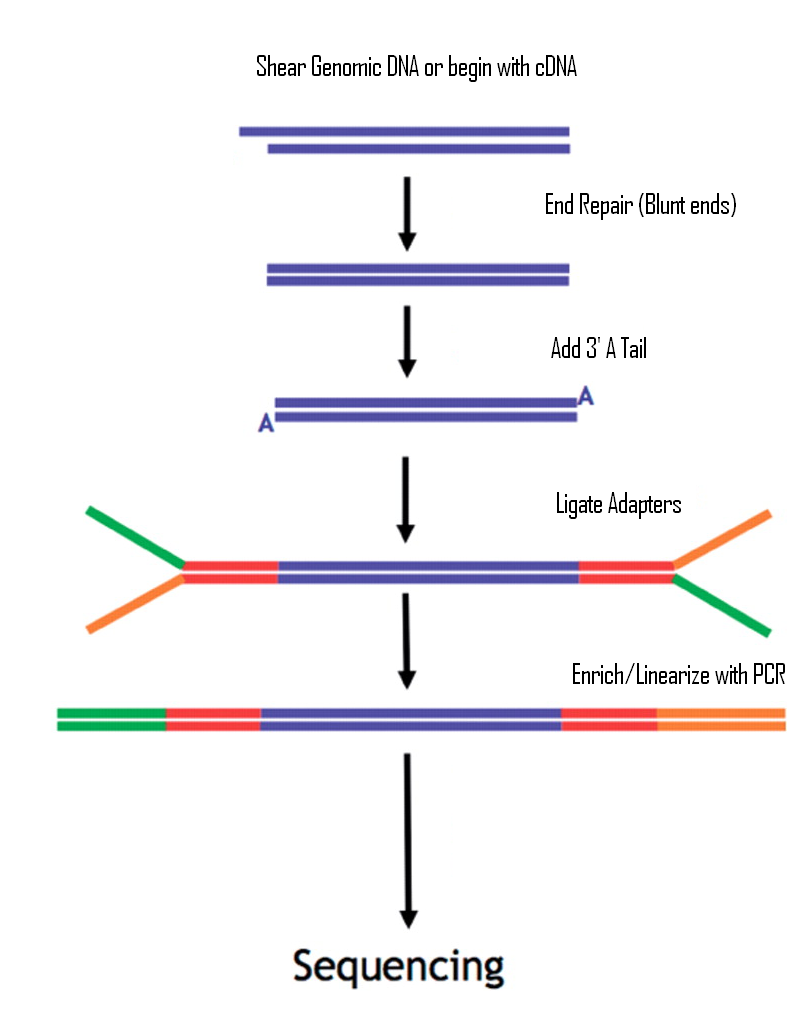
Illumina 平台二代测序文库构建原理简介
来一波Illumina二代测序文库构建原理介绍。一个制备好的Illumina二代测序文库就是含有一堆双链DNA的海洋,其中每一段DNA的5‘和3’部分的序列都是固定的(adapter),而中间的序列是可以随便变化的。所以测序文库的构建就围绕着如何给未知序列的上下游加上特定的adapter而展开的。Illumina 最经典的建库原理如图1所示:首先将DNA整理成双端都是blunt ends的形式,然后再用酶给3'端加上一个A(还记得taq酶的PCR产物可以直接和T载体连接吧,一回事),之后就是用TA连接方法加上Y形adapter,最后用PCR将文库扩增并回收后就可以上机测序了。这个Y形adapter可是很有创意,当时看懂这个的时候感觉五体投地,简直是高。
图1. 图片来源:TUFTS - TUCF Genomics
接下来介绍一种最近兴起的建库方法,基于Tn5转座子的建库方法。具体的不同如图2所示: 首先就是用Tn5酶将adapter连接到DNA双链中,这样两个Tn5插入就可以形成一个完整的文库,之后就用酶将Tn5插入导致的gap修复好,然后经过PCR完成文库扩增。
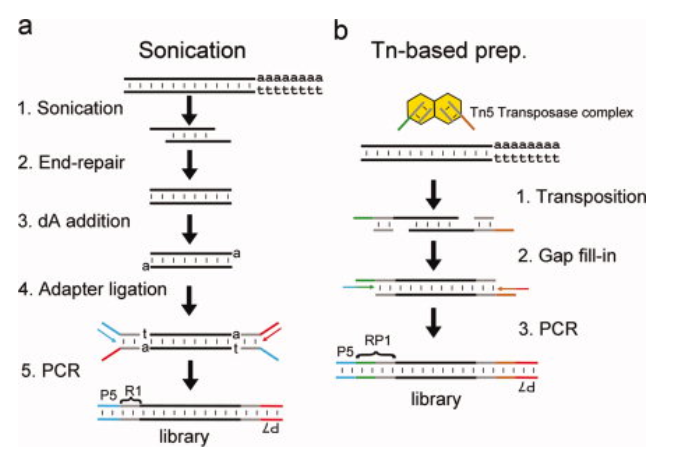
图2. 图片来源:A simple and novel method for RNA‐seq library preparation of single cell cDNA analysis by hyperactive Tn5 transposase
Tn5本身是一个DNA转座子的转座酶,它可以带着自己的DNA在基因组上到处插入,研究人员就借用了Tn5的这个特点将其用于文库构建。
对其中细节感兴趣的读者可以打开图注中的链接仔细研究。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号