第一次作业:深度学习基础
张大滨:
视频学习心得及问题总结:
在之前我曾经较浅的学习了解过深度学习的一些知识,这一次看视频对于深度学习的发展过程一些知识有了较好的了解。深度学习曾经有过两次低谷,现在是第三次浪潮。现在解决了很多之前的问题,我之前写代码添加多个隐层的结果反而没有少的隐层结果好的问题也得到了解决,应该就是梯度消失造成的。但是现在的深度学习精准度高与解释性高有些矛盾。
问题:对于激活函数和前馈公式的导出还是不是很清楚。
代码练习
-
pytorch基础练习



螺旋数据分类
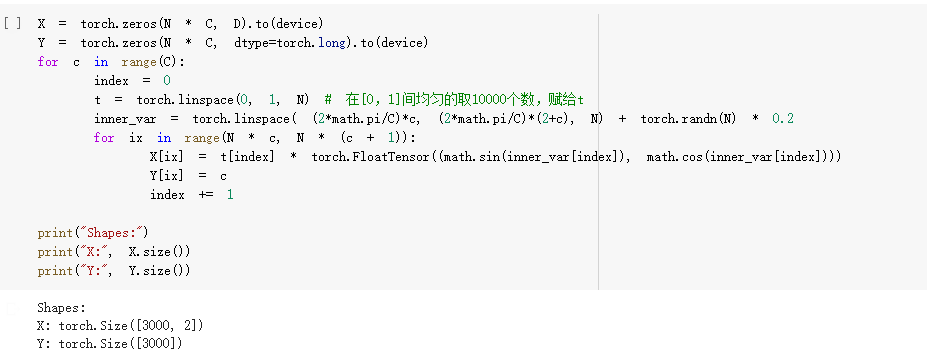
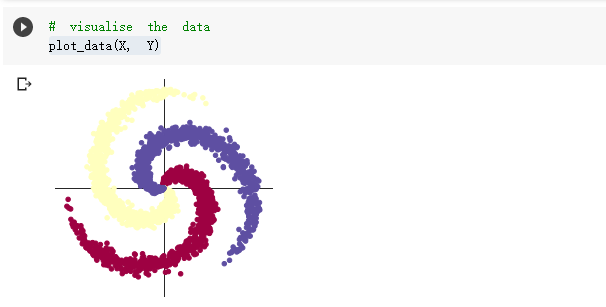

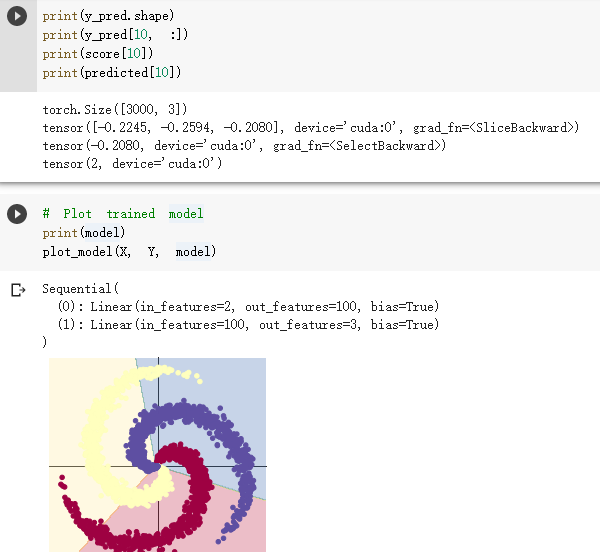

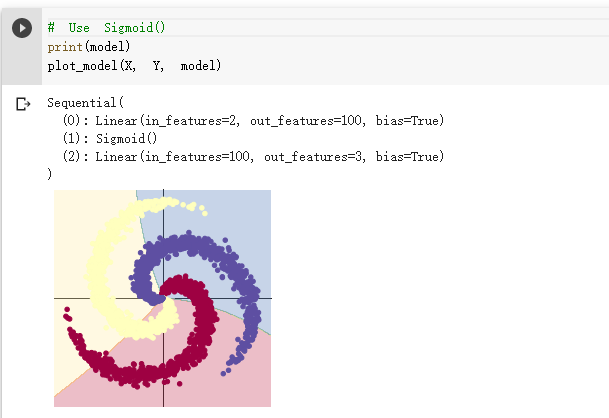
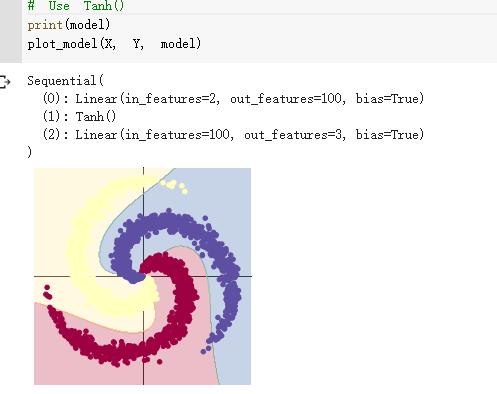
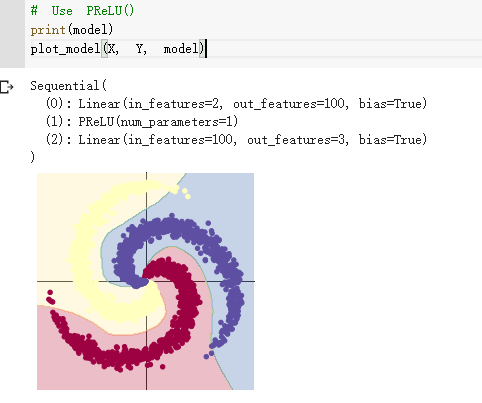
想法和解读:
邓腾跃:
视频学习心得及问题总结:
深度学习是机器学习中的一方面,深度学习能解决很多问题,但是也同样有其局限性,针对神经网络,类似于生物上的神经,在生物上其神经刺激需要一达到一定的阈值才能产生兴奋,同样对于神经网络,激活函数就对应于此,深度学习没有激活函数就相当于矩阵相乘。多层感知器的训练效果要明显好于一层感知器,神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投影到线性可分的区间去投影分类。 问题:梯度下降和反向传播还是不太理解;逐层预训练是怎样训练的;为什么要特征可视化,特征可视化得到的图像代表着什么含义。
代码练习
-
pytorch基础练习
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
螺旋数据分类
.png)
.png)
.png)
.png)
.png)
.png)
.png)
想法和解读:
第一部分是pytorch框架的基础性练习,可能在代码中有一些错误。第二部分是螺旋数据分类,螺旋数据之间的界限是比较复杂的,并不是简单的直线能分割开,根据上面的代码可以看出,神经网络不同,激活函数不同,其分类的效果是不同的,在神经网络中要选择合适的激活函数
李昊阳:
视频学习心得及问题总结:
通过对于视频的学习,了解到了有关深度学习的发展历史以及在发展进程当中几个较为重要的阶段,同时也了解到了深度学习是机器学习领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能。以及深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域的诸多成果。
代码练习
-
pytorch基础练习
螺旋数据分类
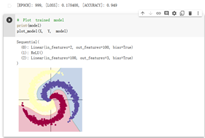

想法和解读:
1.梯度累加就是,每次获取1个batch的数据,计算1次梯度,梯度不清空,不断累加,累加一定次数后,根据累加的梯度更新网络参数,然后清空梯度,进行下一次循环。 2.神经网络中使用激活函数来加入非线性因素,提高模型的表达能力,将权值结果转化成分类结果。
古文祥:
视频学习心得及问题总结:
本周看了有关深度学习的绪论和入门视频。看第一个视频更多的是感受到了人工智能发展的不易,虽然现在阿尔法狗让所有人都见识到了人工智能的强大,但是再听老师讲了深度学习的六个不能,还是深深感受到了深度学习的瓶颈。异或的那个例子让我打开眼界,第一层神经网络看到的同类型的数据不能用线性区分,但是多层次的神经网络却可以改变这样一个非线性的视角,我觉得这个是非常“神奇的”。我有一个疑惑就是,是否有一种方法可以程序化的找到合适的神经网络层数和恰当的系数?如果实现了这样的一个程序化的方法是不是可以很好实现所有的明确目的的深度学习。本周只是大概看了一下老师首讲的几种“已经过时的”深度学习的模型,但是我在听课的时候在数学方面的理解还是感觉半懂不懂,数学倒不是听不明白,激活函数的作用也懂,但是在有关梯度消失的地方还是有点不太明白。总之,这两节课听下来就像打开了一扇新的大门。
代码练习
-
pytorch基础练习


螺旋数据分类
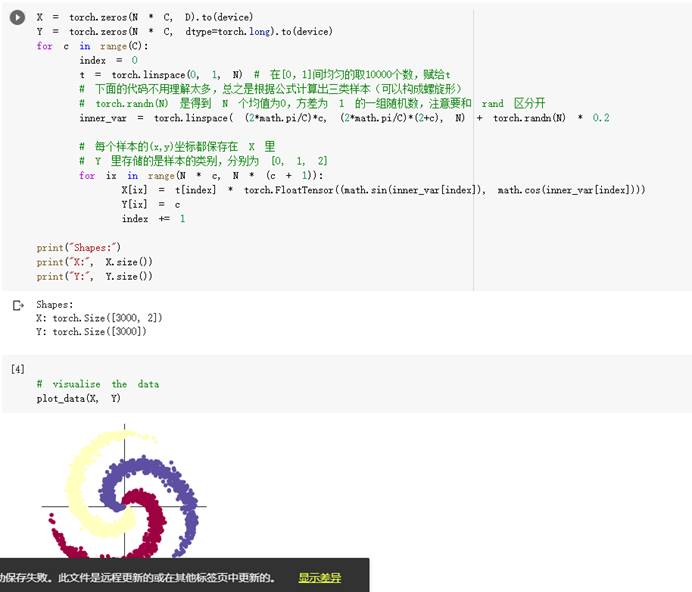
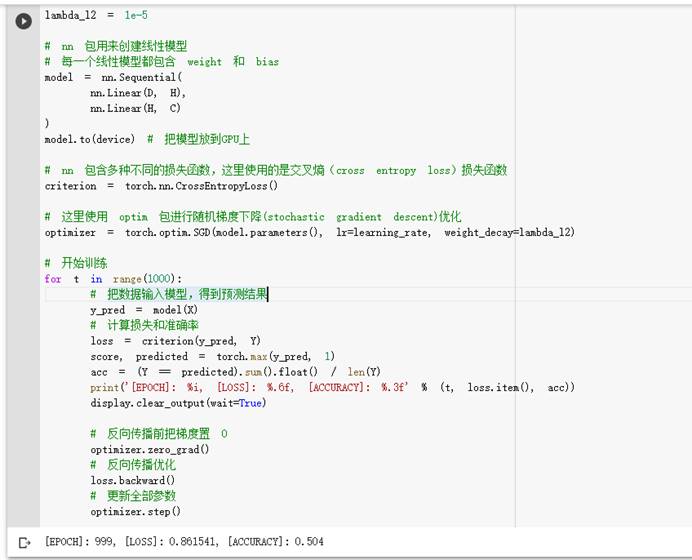

想法和解读:
Sigmoid函数存在梯度消失问题,但是ReLU函数相比Sigmoid函数却能很好的避免这个问题(相对而言)。
一层的神经网络肯定不足以完成一个非线性的划分,所以至少要两层以上,但其实在我的实验中,一层有0.504的概率成功,相比老师的0.500而言是不是我运行的时候生成的随机参数要好一点。(我也不知道是怎么样回事,猜测是找到了更好的最大梯度)
刘路:
视频学习心得及问题总结:
看完视频后我对深度学习有了更深的理解,毕竟发展不到百年,想要完全实现人工智能还有很长的路要走。仅靠算法是无法实现智能的,还需要众多其他领域共同发展,算力的增加,脑科学的发展等等,人工智能的发展之路在曲折中上升。 问题:关于非线性激活函数部分和每一层的数学公式部分不是很明白。
代码练习
-
pytorch基础练习



螺旋数据分类
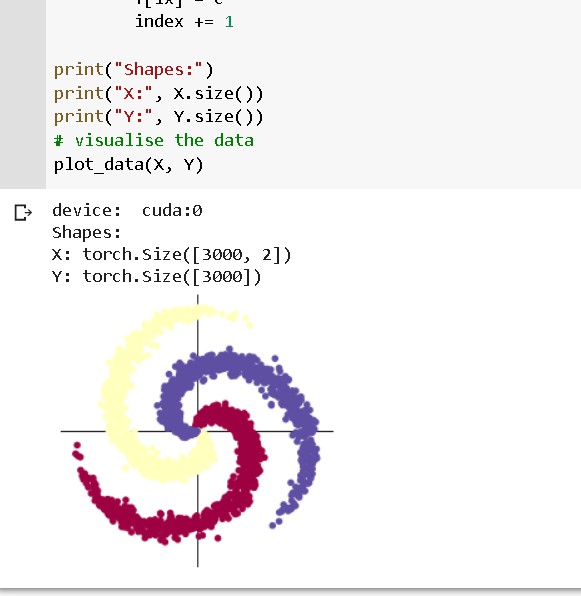

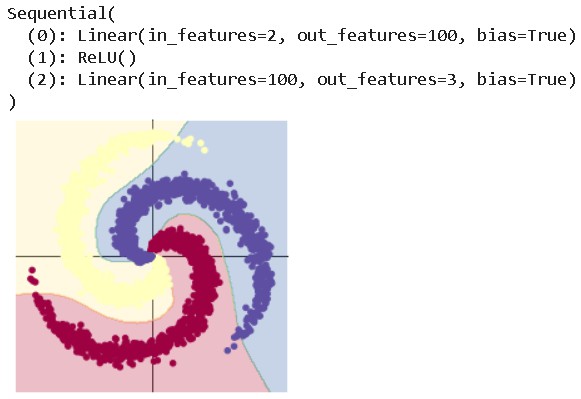
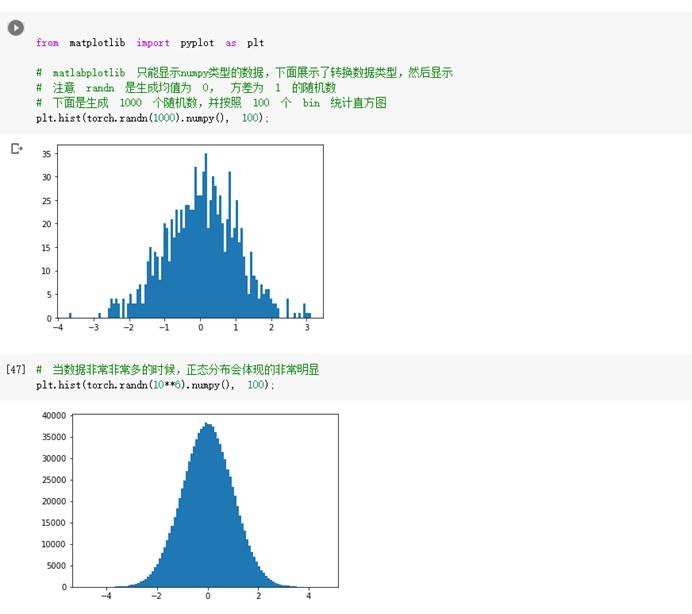
第一个实验是pytorch的基础实验,主要进行的是基础数据类型的操作,其次是生成标准正态分布的随机数据并将其图像化。 实验二则是螺旋数据分类,不同的函数所产生的结果不同,线性分类对于此次的螺旋数据来说,并不能完美实现结果,准确度只有50%,而在两层神经网络里加入ReLU激活函数以后,仅加入一个函数结果就比前者显著提高,因此针对不同情况应选用不同函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号