
20203114 实验四《Python程序设计》实验报告
学号 20203114 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2031
姓名: 张晨曦
学号:20203114
实验教师:王志强
实验日期:2020年5月19日
必修/选修: 公选课
1.实验内容
(1)Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
(2)python包含许多方面的知识,功能强大。关于编程语言的基本知识及逻辑思维,在C语言学习、计算机实习的过程中基本熟练。但对于python特有的其他功能,如爬虫、数据可视化等,都是初步接触,所以我希望通过本次实验,可以对python的独特功能有进一步了解。
本次实验,我运用爬虫爬取当当网好评图书榜的图书信息,并运用python的matplotlib模块对爬取的数据进行可视化分析。
2.实验过程及结果
(1)实验过程
爬虫步骤清晰明确,基本包括三个部分,爬取数据、数据清洗分割及数据保存。数据可视化我在这里也将其分为三部分,导入数据、调用相应方法并将数据填入相应参数部位、按需求对图形其他参数进行设置。
1)对于该实验,爬虫部分整体框架:
baseurl = 'http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-' #网页的baseurl
datalists = getData(baseurl)
saveToexcel('dangdangBOOK.xls', datalists)
①我首先明确要爬取的内容为当当网图书好评榜1-10页的相关图书信息;
②其次,登录相应网站,获取网站url;
③再次,在代码中发送请求,爬取数据;
点击查看代码
url = baseurl + str(pagenum) #每一页的url
html = requests.get(url=url) #请求数据
点击查看代码
bs = BeautifulSoup(html.text, 'html.parser') #解析
bs = bs.find('ul', class_='bang_list clearfix bang_list_mode') #查找
for item in bs('li'):
datalist = []
findlink = re.compile('<div class="name">.*href="(.*?)"')
findname = re.compile('<div class="name">.*title="(.*?)"')
link = re.findall(findlink, str(item))[0]
name = re.findall(findname, str(item))[0]
datalist.append(link)
datalist.append(name)
findstar = re.compile('<div class="biaosheng">.*<span>(.*?)次</span>')
stars = re.findall(findstar, str(item))[0]
datalist.append(stars)
findinfo = re.compile('<div class="publisher_info">.*title="(.*?)">')
findinfo1 = re.compile('<div class="publisher_info"><span>.*_blank">(.*?)</a></div>')
info = re.findall(findinfo, str(item))
if not info:
info = 'none'
datalist.append(info)
else:
datalist.append(info[0])
info1 = re.findall(findinfo1, str(item))[0]
datalist.append(info1)
findtime = re.compile('_info"><span>(.*?)<')
time = re.findall(findtime, str(item))[0]
datalist.append(time)
findpprice = re.compile('<p><span class="price_n">¥(.*?)</')
p_price = re.findall(findpprice, str(item))
datalist.append(p_price[0])
datalists.append(datalist)
点击查看代码
def saveToexcel(savepath, datalists): #数据保存,写入excel表格
workbook = xlwt.Workbook(encoding="utf-8") #创建对象
worksheet = workbook.add_sheet("当当网好评书目", cell_overwrite_ok=True) #对一个sheet表中同一位置多次编辑会覆盖写入不会报错
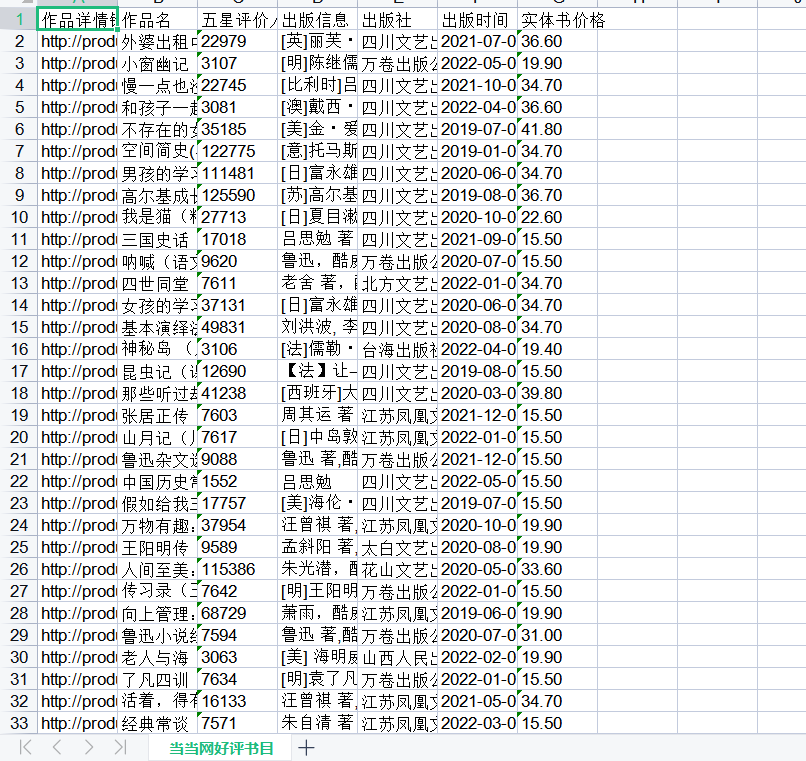
name_sheet = ("作品详情链接", "作品名", "五星评价人数", "出版信息", "出版社", "出版时间", "实体书价格")
for i in range(len(name_sheet)):
worksheet.write(0, i, name_sheet[i]) #向sheet第1行第i列写入数据作为表头
for i in range(len(datalists)):
item = datalists[i] #读取第i本书的信息
print("正在查第%d条内容" % ((i + 1)))
for j in range(len(item)):
worksheet.write(i + 1, j, item[j]) #将第i本书中的信息逐一写入相应位置
workbook.save(savepath) #保存
①首先,将数据从excel表格中导入代码相应列表;
点击查看代码
excel = load_workbook("dangdangBOOK.xlsx")
sheet = excel["当当网好评书目"] #读取sheet信息
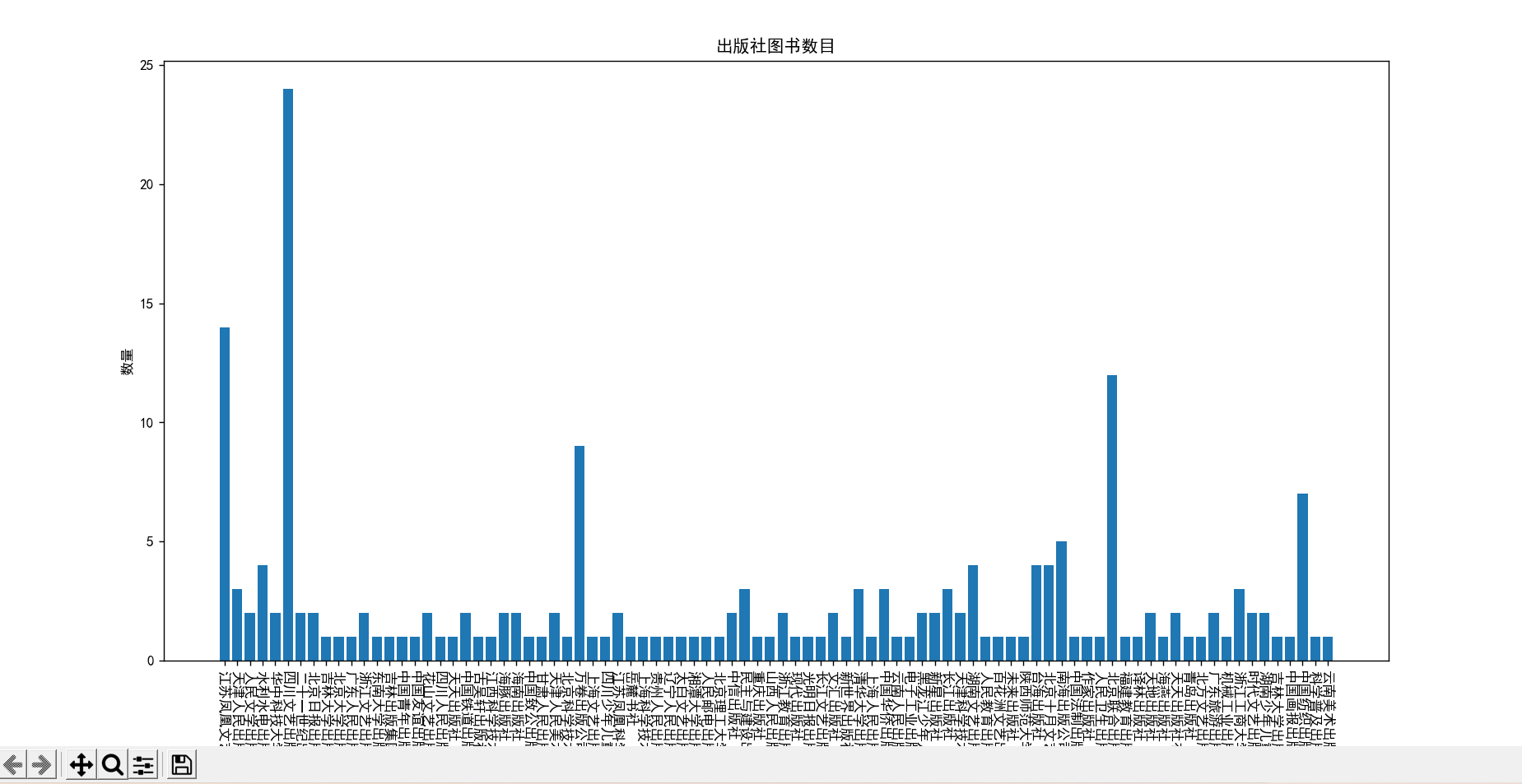
#好评书目中各出版社有多少本-柱状图
chubanshe = [i.value for i in sheet['e'][1:]] #将出版社信息存入该列表
点击查看代码
money = [i.value for i in sheet['g'][1:]]
点击查看代码
chubanshe_xdatas = list(set(chubanshe)) #利用set去除重复出版社,再将其转为列表
for data in chubanshe_xdatas: #去掉none的出版社
if not data:
chubanshe_xdatas.remove(data)
chubanshe_ydatas = []
for chubanshe_xdata in chubanshe_xdatas:
chubanshe_ydatas.append(chubanshe.count(chubanshe_xdata)) #用count统计相同出版社出现次数并存入列表chubanshe_ydatas
f, ax = mp.subplots()
x = range(len(chubanshe_ydatas)) #X轴数据
xx = [i for i in chubanshe_xdatas] #出版社名称
y = [i for i in chubanshe_ydatas] #好评图书中各出版社好评图书数目
mp.bar(x, y) #柱状图,X为横轴数据,Y为纵轴数据
点击查看代码
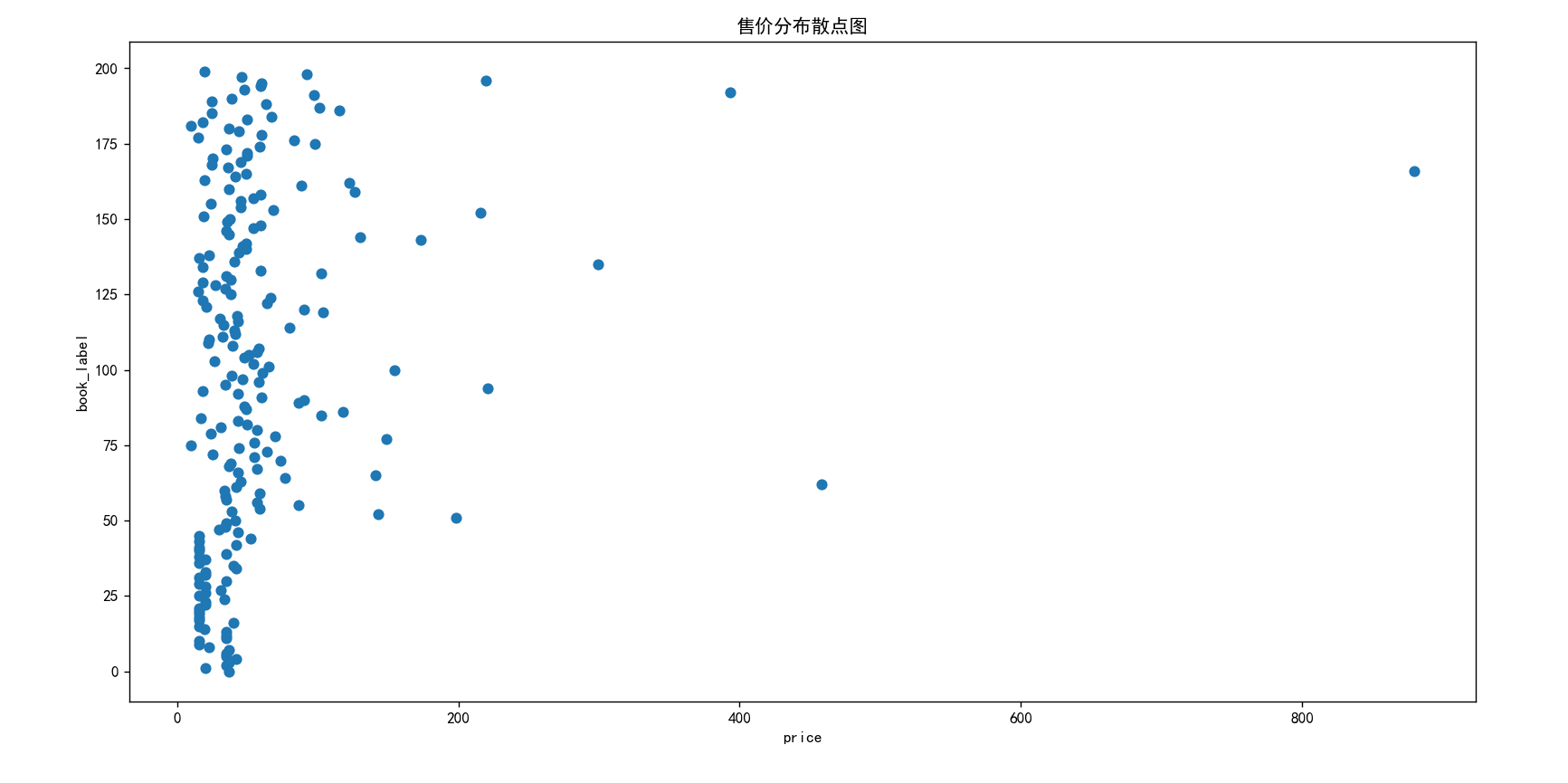
float_money = [float(i) for i in money] #字符串转浮点型
x_money = range(0, 200, 1) #X轴数据
mp.scatter(float_money, x_money) #散点图
点击查看代码
ax.set_xticks(x, xx, rotation=-90) #自定义X轴数据为XX,旋转90度
mp.title("出版社图书数目") #标题
mp.xlabel("出版社") #x标签
mp.ylabel("数量") #y轴标签
mp.show()
点击查看代码
mp.ylabel('book_label') #Y轴标签
mp.xlabel('price') #X轴标签
mp.title("售价分布散点图") #标题
mp.show()
(2)实验结果
1)下载python模块
2)运行

3.实验中遇到的问题及解决过程
·问题1:不知道如何爬取多页数据
·问题1解决方案:通过百度,了解到可利用baseurl,结合循环实现多页数据的爬取。
·问题2:数据可视化时横轴及纵轴标签、标题出现乱码,显示为方框
·问题2解决方案:通过百度,发现可以通过临时重写配置文件和重写配置文件两种方法解决。最终通过临时重写配置文件解决该问题。
·问题3:数据可视化时,不知道如何将X轴上的数据换为自定义的文字
·问题3解决方案:通过查阅资料,发现通过set_xticks方法可以实现坐标轴自定义,包括替换为其他字符,旋转字符角度等。
·问题4:绘制散点图时,发现Y轴数据混乱,未按照大小顺序排列
·问题4解决方案:通过与matplotlib教程中正常显示的散点图程序对比,发现Y轴参数传入的为字符串,不是数值;通过类型转换,将字符串转为整型;后系统仍报错,显示int型数据无效;通过百度,将其设置为浮点型,问题得到解决。
·问题5:在ECS服务器运行时,报错显示:SyntaxError: Non-ASCII character '\xe8'
·问题5解决方案:通过百度,发现问题为无法解析为中文,在代码头加上# -- coding: utf-8 --后问题得到解决
课程总结
(1)心得体会
这学期的python课程告一段落,时间虽短暂,但在老师充满趣味性的讲解中,从课程概述,基础语法,流程控制语句中的while、if、for语句,序列中的列表、字典、元组,字符串、正则表达式、函数、面向对象的类及其相关操作,文件操作异常及处理,数据库,socket,最后到爬虫,老师将知识尽可能涉及到,学到的知识确是许多。
从第一堂课,老师对于课程的概述,使我对于python有了初步了解,但对于爬虫、web等的认识还不明了;同时,老师用简短程序为我们展示的python世界有趣且生动,极大激发了我的学习兴趣,促使着我进一步学习。
在基础语法及流程控制语句学习过程中,我发现python与C语言部分相似、部分区别,这有助于我们快速吸收理解,但也要注意区分。它们整体的框架是相似的,但具体的使用确是区别的。比如python不需要声明变量类型,python的if语句要加冒号,通过缩进辨别是否在if语句内,诸如此类等等。因此这个阶段我每学习一个知识点都要将python与C进行对比,以免将二者记混或是忘记C的使用方法,但其实在后期运用还是会出现问题,最明显的便是在C语言中总是将printf输为print,所以要注意二者区别及练习。
在序列、字符串、函数及文件操作的学习中,结合C语言的知识对其进行理解,可以很快掌握相关知识。在运用中,它们的使用也是及其广泛的。序列可以用来存储数据,字符串及文件的相关操作不可或缺,函数的使用可以使代码更为清晰明了。
在正则表达式的学习中,这可以说是学python以来的第一个较为陌生的知识点,也是一个全新的知识点。它实质上是一种字符串匹配的模式,对字符串进行操作,譬如查找,替换等。在此次实验中,我使用了正则表达式完成所需信息的查找工作。
面向对象的类及其相关操作,是python的一大特点,包括封装、继承、多态三要素。
文件操作异常处理中,了解了如何对程序中的错误进行处理,同时老师还介绍了他的独门绝技,表示很受用。
通过数据库的学习,对相关模块有了一定了解。
通过socket的学习,了解了其工作原理与程序编写基本方法;同时体验到了python的交互性;对于后续计算机网络中相关内容的学习也很有帮助。
学习爬虫,对爬虫这个词汇有了具象化了解,了解了具体操作步骤及相关模块。它的可操作性强,较为容易上手,爬到数据后令我很有成就感(除了总是担心爬了不能爬的网站)对python也更加感兴趣。
截止到现在,我学习了C语言及python两种软件编程语言,初步感觉,编程语言编写需要极强的思维性与创造性。同时,学习编程需要勤加练习,学会和会使用永远不能等同。对于python,我最苦恼的是各种模块及方法的调用,但是对相关模块及方法有了初步了解后,再使用百度基本可以解决该问题。现在各种项目都需要python的支持,其应用十分广泛,由此可见,平时看到的广告也不是空穴来风。未来,我会继续学习python,并深入学习python。
(2)意见建议
建议老师基础语法部分的讲解简略一些,可以分多一点时间给后续数据库、数据可视化等部分。基础语法的部分对于大二大三很好理解,对于大一而言也在C语言课程中同步学习,我个人认为可以简略一些讲,使大家基本了解;从而可以让大家多涉猎一些其他部分的知识。
整体而言,老师的课程质量很高,知识点讲解使用文字展示、课程幽默风趣、知识点结合实例讲解、知识点讲解齐全,同时课后同我们分享各种python知识,为我指明方向。
在此特别感谢一学期以来王老师的指导!
参考资料
[http://c.biancheng.net/matplotlib/9284.html]
[https://blog.csdn.net/Fortware/article/details/51934814?ops_request_misc=&request_id=&biz_id=102&utm_term=python pyplotx轴怎么设置成文字]
[https://www.bilibili.com/video/BV1jT4y1d7kU?spm_id_from=333.337.search-card.all.click]
