第一次作业:深度学习基础
【第一部分】视频学习心得及问题总结
1.视频学习心得
孙兴全:
第一个视频主要讲解了人工智能、机器学习和深度学习以及它们的发展史以及目前的发展现状还有三者之间的关系。人工智能是一种人工程序或者是系统,可以让机器像人一样进行感知、认知、决策和执行,如果说人工智能是一个目标的话,那么机器学习是实现这个目标的一种手段,机器学习目前还没有统一的定义,的最常用的定义是“计算机系统能够利用经验提高自身的性能”,但是在可操作、统计学等方面还有其他不同的理解,从而也有不同的定义。就像人工智能和机器学习的关系一样,深度学习也是实现机器学习的一种方式,它源于人工神经网络的研究,比如说含多隐层的多层感知器就是一种深度学习结构。传统的机器学习基于人工设计特征,通过特征处理实现,这种方式需要大量的数据,比如说需要对大量的图片进行标注,从而让机器能够识别并作出处理,而目前的深度学习的目标是给予机器少量的数据,告诉机器这是关于的特征,然后让机器自行处理,它是基于神经网络的发展,它的三大助推剂:大数据、算法、计算力,目前学术上研究的都是算法相关方面,这也告诉我们,深度学习并不是万能的,比如说它基于一定的数据,对数据的依赖性强,不具备的迁移能力,输出不稳定,容易被攻击,专注直观感知类问题,对开放性推理问题无能为力(只能机械地模仿)等。
第二个视频是对深度学习整个的概述,比如说它的三次兴起及其兴起的原因,以及导致它衰落的原因。在深度神经网络之前有浅层神经网络,浅层神经网络的基本单位为生物神经元,而单层感应器为首个可以学习的人工神经网络,但是单层感受器不能解决非线性问题,比如说不能解决异或问题,因此这造成了神经网络的衰落,为解决非线性问题,出现了多层感知器,其原理在我看来是将非线性问题进行线性分类任务组合之后转换为线性可分的问题。在这里还提出了万有逼近定理:如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任何精度逼近任意预定的连续函数。在深层神经网络之中,输入是随着多层的神经网络一步步前向传播的,但在传播过程中会产生损失,传播到神经网络最顶层之后损失会通过梯度反向传播,以求能够对损失进行修正,其中反向传播是根据损失求偏导。但是多层的神经网络可能会导致梯度消失(梯度消失有很多的原因),进而产生不能对机器进行训练的现象。为解决局部最小值和梯度消失,一个很好的方法就是给予一个很好的初始值参数,给予一个权重初始化,也就是通过逐层预训练,每次训练一层的神经网络,然后每层进行叠加。
宋泽涛:
学习完这次的课程,弄清楚了人工智能,机器学习,神经网络,深度神经网络,深度学习等概念的区别和联系,学习了人工智能的发展历史。了解了神经网络类似生物学上的神经,存在激活函数,神经的兴奋和抑制,了解了深度学习开发的框架,如Tensorflow,pytorch等等。同时,我意识到人工智能的基础就是数学,高等数学的梯度,微积分,概率论的条件概率,朴素贝叶斯等等,还需要复习相关的数学知识,为人工智能的学习打基础。
张琪:
这两节视频大致可分为以下几个部分:人工智能在世界以及在中国的发展;机器学习->深度学习;深度学习的劣势:稳定性差、可调式性差、参数半透明、机器偏见、增量性差、推理能力差;神经网络基础等
曾浩洋:
在视频的一开始,老师就介绍了世界主流国家对人工智能行业的重视,并指出人工智能行业存在很大的人才漏洞,吸引大家对这个行业的兴趣。人工智能的概念于1943年由图灵提出,历经六十多年的发展,在二十一世纪进入了高速发展期。人工智能分为三个层面:计算智能,感知智能,认知智能。人工智能囊括了机器学习,而机器学习又包含了当下火热的深度学习。在介绍了机器学习的各种应用场合后,我们可以概括其定义为计算机系统从数据中自动提取知识。机器学习的过程也可以解释为建立模型,制定策略到提出具体算法的过程。我们可以根据数据标记的特点把机器学习分为监督学习,半监督学习,无监督学习和强化学习。接着,通过对机器学习和深度学习的比较,我们又了解到深度学习的大体思路与优点。通过对深度学习的简介,我们认识到了深度学习的发展和应用领域,也认识到了深度学习的不足之处:算法输出不稳定,容易被攻击;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端到端训练方式对数据依赖性强,模型增量差;专注直观感知类问题,对开放性推理问题无能为力;机器偏见难以避免。我们可以用神经元的学习方式来了解机器学习的实现,引出了激活函数,单层感知器,多层感知器。通过对单隐层神经网络可视化的介绍,提出了万有逼近定理: 如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任何精度逼近任意预定的连续函数。输入是随着多层的神经网络每层传播过程中会产生损失。接着就是计算过程,让我回想起高数的恐怖了…
陈瑶明:
第一个视频介绍了人工智能的几个层面,计算层面,感知层面以及认知智能,并且它与各行各业息息相关,从推理期 知识期到学习期的理论技术,从模型,策略,算法角度进行机器学习。深度学习是人工智能的前提,第二个视频内详细介绍了深度学习这一概念的发展历程,包含一些深度学习的几点“不能”,算法输出的不稳定,模型复杂度高,层级复合程度高,对数据依赖性强,对开放性问题无能为力,人类知识无法有效引入监督,并利用大量例子进行例证。对人工智能来说,最重要的是对神经系统的模拟,通过对生物神经元特点的总结,利用大量数学函数,定理和模型,对更宽和更深两种情况下的差错对比从复杂度角度给出了解释。但是,从单层网络到多层网络又出现了新问题:梯度消失,反向传播,因此出现了几种改善梯度消失的方法,训练深度网路,新的激活函数,辅助损失函数,逐渐的尺度归一,选择记忆和遗忘机制。
穆雨含:
机器学习适用于问题复杂度高,规模大,数据足够多的问题。机器学习主要通过建立模型,确定目标函数,以及求解模型参数来完成。 机器学习模型通过数据标记分为监督学习模型和无监督学习模型。数据分布分为参数模型和非参数模型。 建模对象分为生成模型和判别模型。 深度学习是机器学习的一种。大数据,算法,计算力是深度学习的三个助推剂。 深度学习不能: 1.算法输出不稳定,容易被攻击。 2.模型复杂度高,难以纠错和调试。 3.模型层级复合程度高,参数不透明。 4.端到端训练方式对数据依赖性强,模型增量性差。 5.专注直观感知类问题,对开放性推理问题无能为力。 6.人类知识无法有效引入进行监督,机器偏见难以避免。 深度学习准确性很高但是解释性很差。 神经网络 局部极小值和梯度消失问题通过权重初始化 逐层预训练 自编码器,受限玻尔兹曼机:两层神经网络
2.问题总结
问题1:视频中演示的图像识别是不同颜色之间的识别,如果对人脸、汽车等较复杂的物体进行识别的话应该如何进行识别,因为这些物体有多个特征,而且这些特征之间存在着联系,如何在识别中保存这些联系?
问题2:学习人工智能应该着重学习哪一部分?数学公式,模型,还是算法?
问题3:老师能否在课上的时候通过对一个实践的项目进行讲解,因为之前没有关于深度学习的研究,所以仅仅是看视频很多地方还是看不明白,比如第二节后面部分的自编码器,受限玻尔兹曼机等内容。
【第二部分】代码练习
2.1 pytorch基础练习

上面的代码为用torch.Tensor定义数据,其中tensor表示张量,它可以用来表示一个数,一维向量,二维数组以及任意维度的张量。
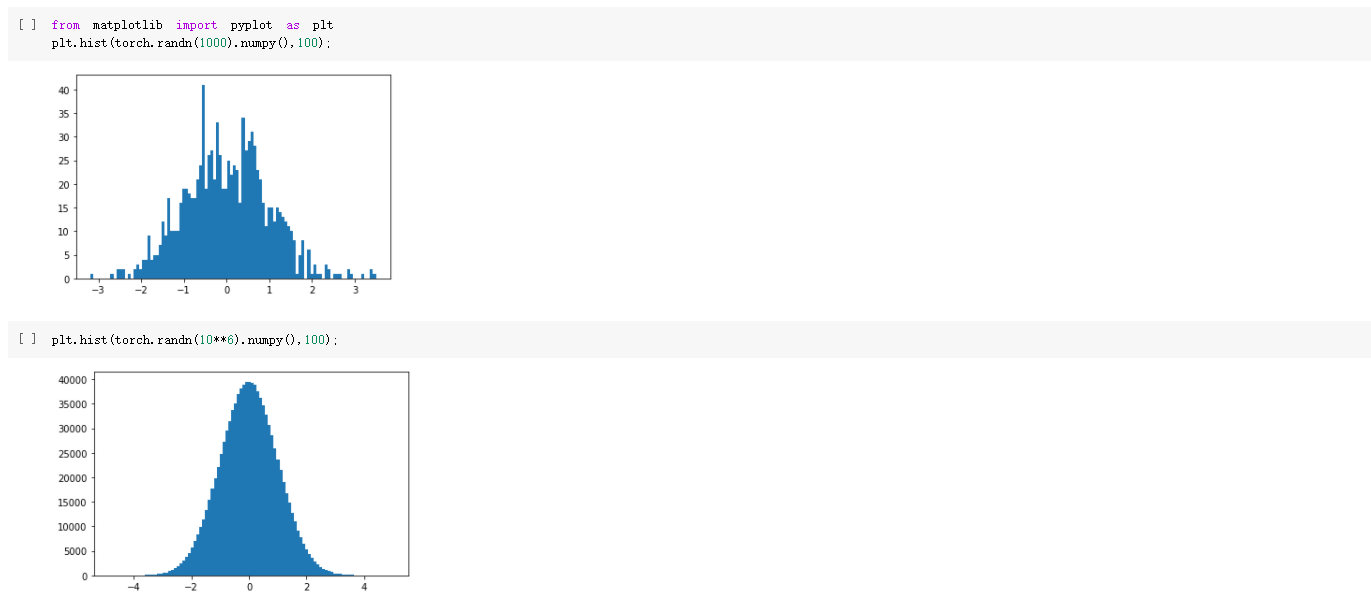
上面的代码表示的是用直方图的形式表示生成的随即图,两张图的区别是第二张图的数据更多一点,经过两张图片对比可以发现,随着数据的增加,随机数正态分布会更加明显。
这是构建线性模型类主要函数代码:

就根据实验指导上面的内容输入就可以得到结果。
其中:使用 print(y_pred.shape) 打印模型的预测结果。为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred的一行里。值最大的一个,即为预测该样本属于的类别
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置保存在 predicted 中。
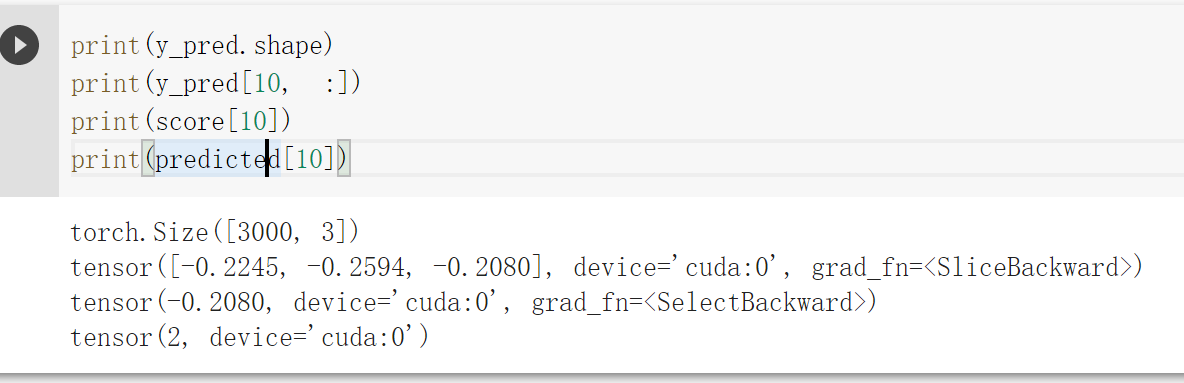
可以看出线性模型的准确性不够高,线性模型难以实现准确分类。
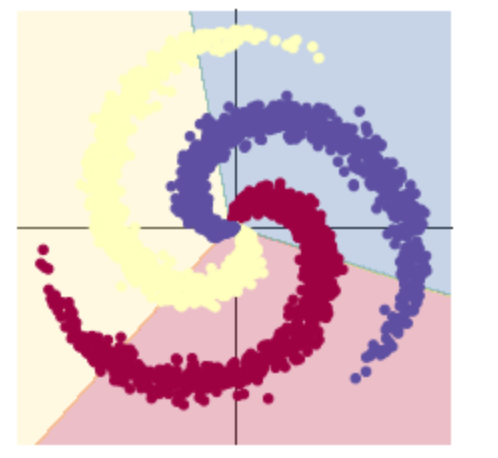
构建两层神经网络分类:
主要函数:

根据显示明显看出加入激活函数后,分类的准确率更高了。
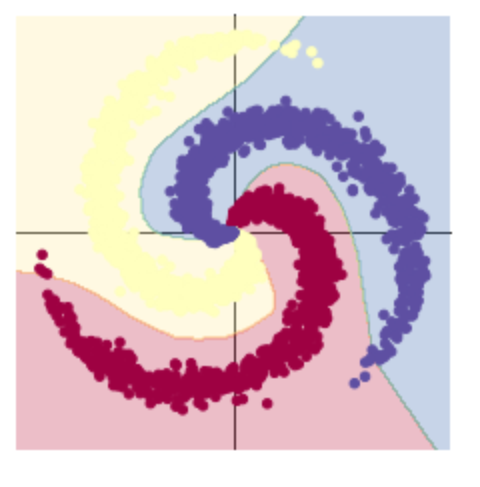
总结:第一个代码练习,主要练习了pytorch的基础语法,一些的基本练习,包括创建数组(向量),张量,生成随机数,画图。
第二个代码练习,主要练习了神经网络的使用,先生成三类数据,然后进行分类。利用sigmoid()函数,发现效果并不是很理想,如课程内容所说,应该是因为误差无法传播,多层网络容易陷入局部极值,难以训练,也正是因为此,神经网络迎来了第二次低估,而后的新激活函数ReLU()使得深度学习成为可能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号