线程理论
- 什么是线程
"""
进程:资源单位
线程:执行单位
我们将进程比喻成一个地铁,假如现在有上海和北京两个地方的地铁,地铁里面都有线路,比如说一号线和二号线,这个就是线程
每一个进程肯定自带一个线程
再次总结:
进程:资源单位(起一个进程仅仅只是在内存空间中开辟一块独立的空间)
线程:执行单位(真正被cpu执行的其实是进程里面的线程,线程指的就是代码的执行过程,执行代码中所需要使用到的资源都找所在的进程索要)
进程和线程都是虚拟单位,只是为了我们更加方便的描述问题
"""
-
为何要有线程
""" 开设进程 1.申请内存空间 耗资源 2.“拷贝代码” 耗资源 开线程 一个进程内可以开设多个线程,在用一个进程内开设多个线程无需再次申请内存空间操作 总结: 开设线程的开销要远远的小于进程的开销 同一个进程下的多个线程数据是共享的!!! """ 我们要开发一款文本编辑器 获取用户输入的功能 实时展示到屏幕的功能 自动保存到硬盘的功能 开三个线程处理上面的三个功能更加的合理
创建线程的两种方式
什么是线程呢?在另一个博客中已经介绍了,现在介绍创建线程的两种方式,只要我们会创建进程的两种方式,那么线程的创建也不会太难的,也都是大差不差
from threading import Thread
import time
def task(name):
print(f'{name} 我又回来了')
time.sleep(1)
print(f'{name} 我走了')
if __name__ == '__main__':
t=Thread(target=task,args=('zc',))
t.start()
print('主')
from threading import Thread
import time
class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
print(f'{self.name}1')
time.sleep(1)
print(f'{self.name}2')
if __name__ == '__main__':
t=MyThread('zc')
t.start()
print('主')
tcp并发实现的效果
import socket
from threading import Thread
from multiprocessing import Process
"""
服务端
1.要有固定的IP和PORT
2.24小时不间断提供服务
3.能够支持并发
"""
server =socket.socket() # 括号内不加参数默认就是TCP协议
server.bind(('127.0.0.1',8080))
server.listen(5)
# 将服务的代码单独封装成一个函数
def talk(conn):
# 通信循环
while True:
try:
data = conn.recv(1024)
# 针对mac linux 客户端断开链接后
if len(data) == 0: break
print(data.decode('utf-8'))
conn.send(data.upper())
except ConnectionResetError as e:
print(e)
break
conn.close()
# 链接循环
while True:
conn, addr = server.accept() # 接客
# 叫其他人来服务客户
# t = Thread(target=talk,args=(conn,))
t = Process(target=talk,args=(conn,))
t.start()
"""客户端"""
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data.decode('utf-8'))
线程的join方法
线程对象的join方法,就是让主线程等待子线程,子线程运行结束后再执行主线程。
from threading import Thread
import time
def task(name):
print('%s is running'%name)
time.sleep(3)
print('%s is over'%name)
if __name__ == '__main__':
t = Thread(target=task,args=('egon',))
t.start()
t.join() # 主线程等待子线程运行结束再执行
print('主')
多线程共享数据
多线程和多进程不一样,多进程之间的数据是共享的,不需要借助任何的第三方,因为在同一个进程下的多个线程共享数据。
from threading import Thread
import time
money = 100
def task():
global money
money = 666
print(money)
if __name__ == '__main__':
t = Thread(target=task)
t.start()
t.join()
print(money)
线程对象属性及其他方法
# 线程对象的
# native_id 获取当前对象的线程id
from threading import Thread, active_count, current_thread
# sctive_count() 获取当前存活的线程数
# current_thread() 获取当前线程对象,
# current_thread().name 当前对象的没名字等
# 补充:
active_count 等同于 currentThread,
current_thread 等同于 activeCount
守护线程
无论是线程还是进程,都要遵循xxx会等待主xxx运行完毕之后销毁
强调:运行完毕并非终止运行
-
对于主进程来说,运行完毕是主进程代码运行完毕
-
对于主线程来说,运行完毕指的是主线程所在的进程内的所有非主线程统统运行完毕,主线程才算运行完毕
-
详解:主进程在其代码结束后就已经算运行完毕了(守护进程在此时就会被收回),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则就会产生僵尸进程),才会结束
-
主线程是在其他非守护线程运行完毕后才算完毕(守护线程在此时就会回收)。因为主线程的结束意味着进程的结束,进程的整体资源都将被回收,而进程必须保证非守护线程都运行结束后才能结束。
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.setDaemon(True) #必须在t.start()之前设置 t.start() print('主线程') print(t.is_alive()) ''' 主线程 True ''' from threading import Thread import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print("main-------") ''' 123 456 main------- end123 end456 '''线程互斥锁
from threading import Thread,Lock import time money = 100 mutex = Lock() def task(): global money mutex.acquire() tmp = money time.sleep(0.1) money = tmp - 1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money)GIL全局解释器锁
-
GIL全局锁,本质也是互斥锁,都是将并发变成串行,保证数据的安全。
-
python解释器有很多的版本,有Cpython,Jpython等等,但是只有在Cpython解释器里GIL是一把互斥锁,用来阻止同一个进程下的多个线程的同时执行
重点:
GIL不是python的特点,而是Cpython的特点 GIL是保证解释器级别的数据安全 GIL会导致同一个进程下的多个线程无法同时执行 针对不同的数据还是需要加不同所的处理 解释型语言的通病:同一个进程下多个线程无法利用多核优势
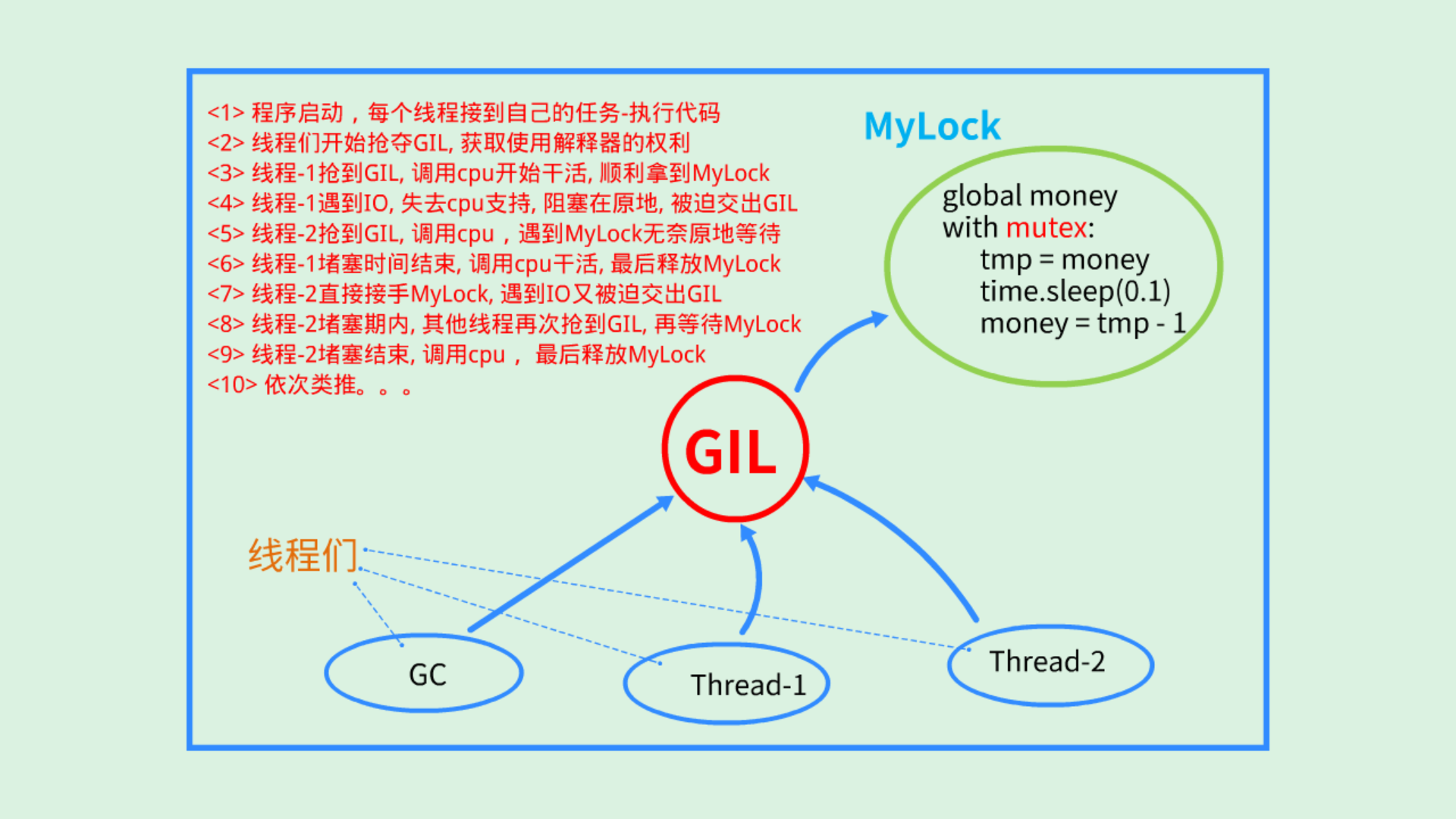
GIL和多线程
计算密集型
多进程:总耗时 10+
多线程:总耗时 40+
IO密集型
多进程:相对浪费资源
多线程:更加节省资源
代码验证:
计算密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res = 0
for i in range(10000000):
res *= i
if __name__ == '__main__':
l = []
for i in range(12):
p = Process(target=work) # 1.4679949283599854
t = Thread(target=work) # 5.698534250259399
t.start()
# p.start()
# l.append(p)
l.append(t)
for p in l:
p.join()
print(time.time()-start_time)
# IO密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work():
time.sleep(2)
if __name__ == '__main__':
l = []
print(os.cpu_count()) # 获取当前计算机CPU个数
start_time = time.time()
for i in range(4000):
# p = Process(target=work) # 21.149890184402466
t = Thread(target=work) # 3.007986068725586
t.start()
# p.start()
# l.append(p)
l.append(t)
for p in l:
p.join()
print(time.time()-start_time)
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号