模块
模块
1. 什么是模块?
模块就是一系列功能的集合体, 分为三大类
I:内置的模块
II:第三方的模块
III:自定义的模块
一个python文件本身就一个模块,文件名m.py,模块名叫m
ps:模块有四种形式
*使用python编写的.py文件
*已被编译为共享库或DLL的C或C + +扩展
*把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包)
*使用C编写并链接到python解释器的内置模块
2、为何有用模块
I: 内置与第三的模块拿来就用,无需定义,这种拿来主义,可以极大地提升自己的开发效率
II: 自定义的模块
可以将程序的各部分功能提取出来放到一模块中为大家共享使用
好处是减少了代码冗余,程序组织结构更加清晰
3、如何用模块
y=333
z=444
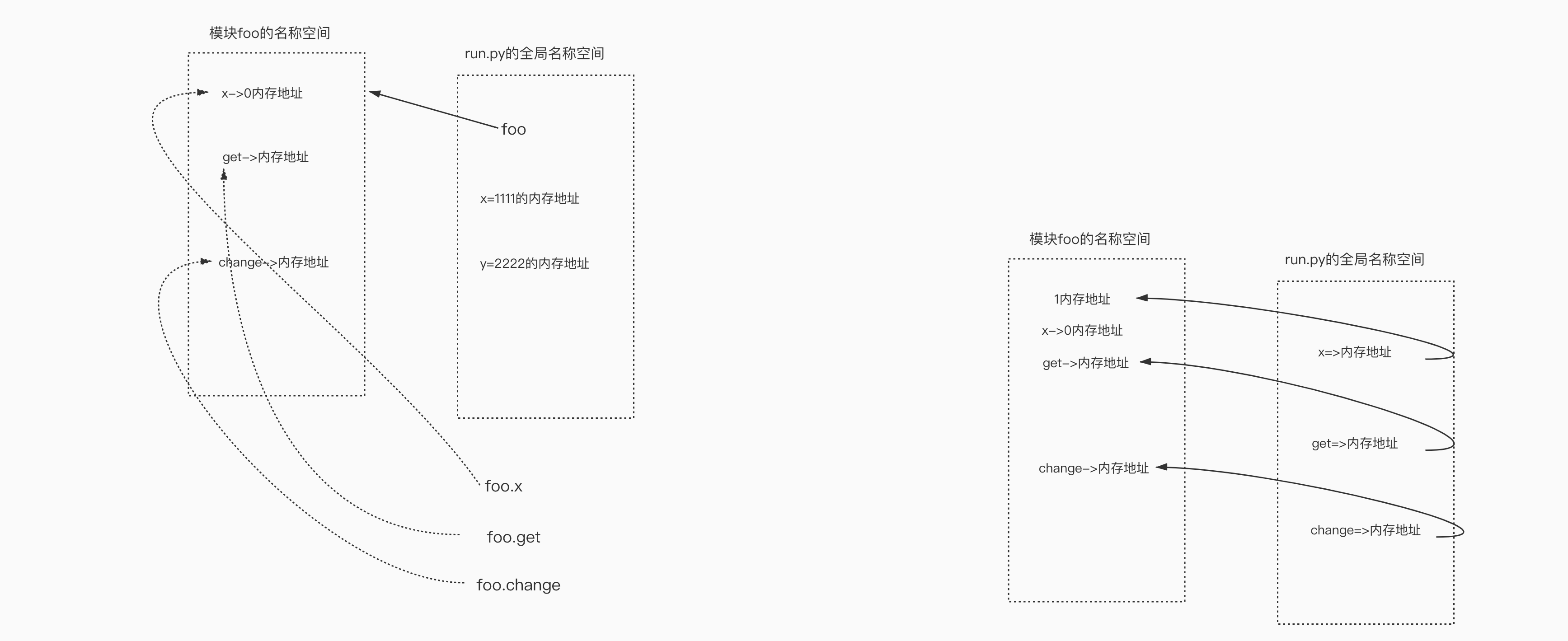
import foo
-
首次导入模块会发生3件事
- 执行foo.py
- 产生foo.py的名称空间,将foo.py运行过程中产生的名字都丢到foo的名称空间中
- 在当前文件中产生的有一个名字foo,该名字指向2中产生的名称空间
之后的导入,都是直接引用首次导入产生的foo.py名称空间,不会重复执行代码
-
引用:
print(foo.change)
强调1:模块名.名字,是指名道姓地问某一个模块要名字对应的值,不会与当前名称空间中的名字发生冲突
x=1111111111111
print(foo.x)
强调2:无论是查看还是修改操作的都是模块本身,与调用位置无关
import foo
x=3333333333
foo.get()
foo.change()
print(x)
print(foo.x)
foo.get()
- 可以以逗号为分隔符在一行导入多个模块
建议如下所示导入多个模块
import time
import foo
import m
不建议在一行同时导入多个模块
import time,foo,m
- 导入模块的规范
I. python内置模块
II. 第三方模块
III. 程序员自定义模块
import time
import 第三方1
import 自定义模块1
- import 。。。 as 。。。
import foo as f # f=foo
f.get()
import a as m
m.f1
-
模块是第一类对象
import foo -
自定义模块的命名应该采用纯小写+下划线的风格
-
可以在函数内导入模块
def func():
import foo
4. 循环导入
循环导入就是模块1加载/导入2模块,2模块加载/导入3模块,3模块加载/导入模块,这就是循环导入的问题,由于第一个模块尚未加载完毕,所以引用失败、抛出异常,究其根源就是在python中,同一个模块只会在第一次导入时执行其内部代码,再次导入该模块时,即便是该模块尚未完全加载完毕也不会去重复执行内部代码
下面例子:
# m1.py
from mmm.m2 import f2
def f1():
print('去你妈的 ')
#m2.py
from mmm.m3 import f3
def f2():
print('去你妈的1')
#m3.py
from mmm.m1 import f1
def f3():
print('去你妈的2')
#run.py
import m1
当我们执行run.py的时候就会报错,
先执行run.py--->执行import m1,开始导入m1并运行其内部代码--->打印内容"去你妈的"
--->执行from m2 import f2 开始导入m2并运行其内部代码--->打印内容“去你妈的1”--->执行from m1 import f1,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿f1,然而x此时并没有存在于m1中,所以报错
这样的问题我们要如何解决呢,我们可以把导入的模块放到函数里面去,这样的话,就只能在家引用或者把变量放在引用模块的开头
5. 搜索模块的路径与优先级
一个python文件有两种用途
- 被当成程序运行
- 被当做模块导入
无论是import还是from...import在导入模块时都涉及到查找问题
优先级:
内存(内置模块)
硬盘:按照sys.path中存放的文件的顺序依次查找要导入的模块
在导入一个模块时,如果该模块已加载到内存中,则直接引用,否则会优先查找内置模块,然后按照从左到右的顺序依次检索sys.path中定义的路径,直到找模块对应的文件为止,否则抛出异常。sys.path也被称为模块的搜索路径,它是一个列表类型
import sys
sys.path()
## sys.path中的第一个路径通常为空,代表执行文件所在的路径,所以在被导入模块与执行文件在同一目录下时肯定是可以正常导入的,而针对被导入的模块与执行文件在不同路径下的情况,为了确保模块对应的源文件仍可以被找到,需要将源文件foo.py所在的路径添加到sys.path中,假设foo.py所在的路径为/pythoner/projects/
import sys
sys.path.append(r'/pythoner/projects/') #也可以使用sys.path.insert(……)
import foo #无论foo.py在何处,我们都可以导入它了
6. 区分py文件的两种用途
一个Python文件有两种用途,一种被当主程序/脚本执行,另一种被当模块导入,为了区别同一个文件的不同用途,每个py文件都内置了__name__变量,该变量在py文件被当做脚本执行时赋值为“main”,在py文件被当做模块导入时赋值为模块名
#foo.py
...
if __name__ == '__main__':
foo.py被当做脚本执行时运行的代码
else:
foo.py被当做模块导入时运行的代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号