
python生成器学习笔记
python生成器学习笔记
生成器:在程序运行过程中可以挂起和恢复的函数,返回一个可迭代的对象。
不同与列表,生产器是惰性执行的,即你要求一次,它执行一点并返回一个结果,你反复要求,它再依次把结果一个一个返回出来。所以在处理更大的数据集时,生成器有更高的内存效率。
生成器函数
为了创建一个生成器,你像通常一样定义一个函数但是使用yield语句代替return语句,向解释器表明该函数应该被视为一个迭代器
def countdown(num):
print('starting')
while num > 0:
yield
num -= 1
yield语句挂起函数,并保存本地状态以便函数能从它中断的地方被正确的恢复。
当你调用这个函数是,发生了什么?
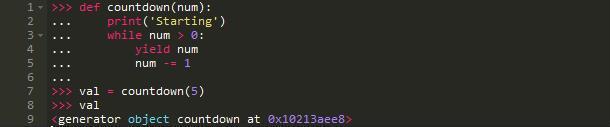
调用这个函数并未真正执行它。我们知道是因为字符串'strings'并未打印。相反,函数返回一个生成器对象用来控制执行。
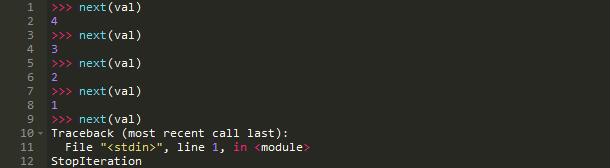
当next()函数被调用时,生成器对象开始执行:

当第一次调用next()函数时,执行从函数的起始处开始直到下面的yield语句并在这里返回这个语句右边的值。
下一次调用next()函数从yield语句处开始执行到函数结尾,然后绕一圈回到函数开始处继续直到遇到下一次yield语句。
如果yield语句没有被调用(在我们的例子中,我们没能通过判断因为num小于等于0)抛出StopIteration异常:
生成器表达式
像列表生解析一样,生成器也可以使用相同的方式编写。不同的是它们返回一个生成器对象而不是一个列表:
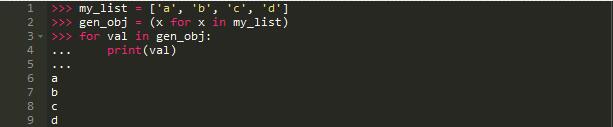
注意第二行代码两边的括号表示一个生成器表达式,在很大程度上,它做的工作和列表推导式相同,但是惰性执行:

小心不要混淆列表推导式和生成器表达式的语法-[]和()-因为(区别)生成器表达式比列表推导式运行得慢(当然,
除非你耗尽内存):
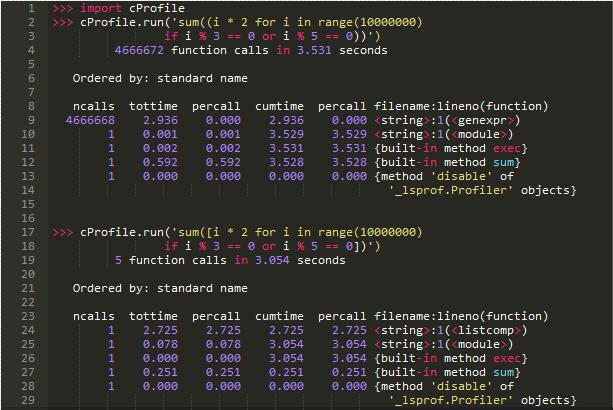
明显例子中上面的(即使是高级开发人员)更容易执行即使两者最终输出相同的东西。
注意:记住当你数据量大于可用内存时生成器表达式更快。
用例
生成器在读取大量大文件时表现优异因为他们一次只产生一个单独的数据块而不论输入流的大小。生成器还可以产生
更简洁的代码通过解耦迭代过程分解成更小的组件。
例子1
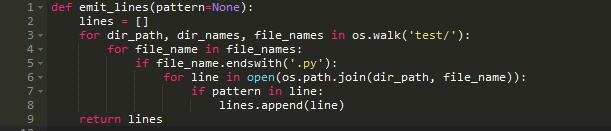
这个函数遍历特定目录下的一系列文件。它打开每一个文件然后遍历每一行来测试是否匹配模式。
处理少量小文件时函数表现正常。但是,如果我们处理极大的文件呢?或者是大量文件?幸运的是,python的open()函数
是高效的而且并不是将文件全部读入内存。但是如果我们要匹配的列表远远超过了我们机器的可用内存呢?
所以,生成器是理想的工具用来处理大量数据,而不是耗尽内存(大列表)和时间(几乎无限数量的数据流),因为他们一次
接一次生成数据(而不是创建中间表)。
让我们看看上术问题的生成器版本,试着理解为什么生成器适合这些使用处理流的用例。
我们把我们的整个处理分成三个不同的模块:
-
生成一系列文件名
-
生成全部文件的所有行
-
在模式匹配的基础上过滤所有行
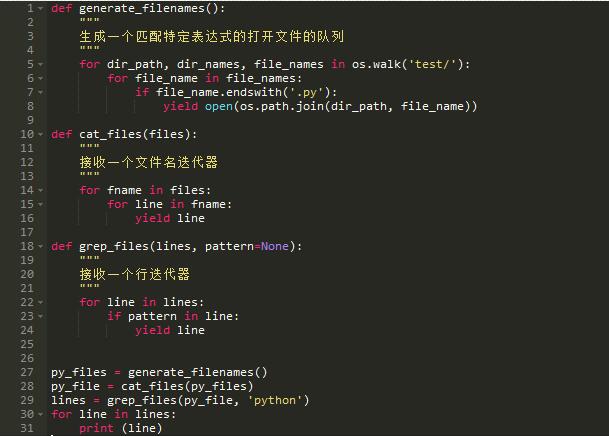
在上面的代码片段,我们不使用任何额外的变量形成行的列表,相反我们创建一个适合构件的流通过迭代一次处理一项。
grep_files接收一个所有以.py为后缀的文件的所有行的迭代对象。同样地,cat_files接受一个目录下所有文件的迭代对象。
这就是如何通过迭代整合整个流程的。
例子2
生成器更好的完成网络抓取和递归爬取:
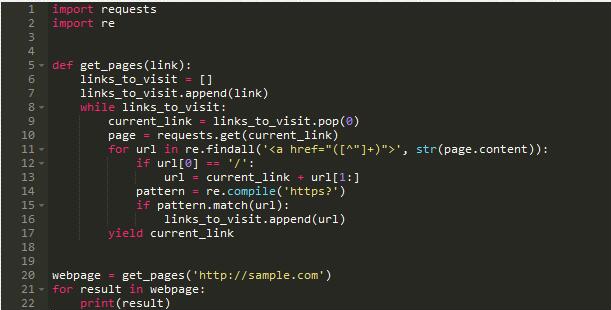
这里,执行时我们一次简单抓取一个单独的页面然后执行某些动作在该页上。要是不用生成器会怎么样?在同一个函数中
抓取和处理(导致难以测试的高耦合代码)或者我们不得不在处理一个单独的页面之前抓取所有链接。
结论
生成器允许我们在需要数据的时候再请求数据,使我们的程序更富内存效率并且在超大量数据流情况下表现优异。生成器
也可以用来重构循环来产生清洁,低耦合的代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号