
数据采集第一次作业_031904129朱贝尔
作业1
-
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
-
输出信息:
2020排名 全部层次 学校类型 总分 1 前2% 中国人民大学 1069.0 2...... -
1) 解题过程
-
1.1 获取HTML函数
def GetHTML(url): try: http = urllib.request.urlopen(url)#完成简单的请求和网页抓取,返回值类型是一个HTTPResponse对象 data = http.read()#得到返回的网页内容 data = data.decode()#解码 #print(type(data)) data = data.replace("\n","")#将换行符去除 return data except Exception as err: print(err) -
1.2 正则匹配
def GetText(text): try: Uni_Rank = re.findall(r'class="ranking" data-v-68e330ae>(.*?)</div>',text) Uni_Name = re.findall(r'class="name-cn" data-v-b80b4d60>(.*?)</a>', text) Uni_Level = re.findall(r'<td data-v-68e330ae>(.*?)</td></tr>', text) Uni_Score = []#利用列表获取学校分值 for j in Uni_Level: Uni_Score.append(re.findall(r"<td data-v-68e330ae> (.*?) ", j)) #print(Uni_Rank[0])测试匹配结果 #$print(Uni_Name[0])测试匹配结果 #print(Uni_Score)测试匹配结果 for i in range(len(Uni_Rank)): Uni_Rank[i] = Uni_Rank[i].replace(" ","") return Uni_Name,Uni_Rank,Uni_Level,Uni_Score except Exception as err: print(err) -
1.3 打印函数
def ShowText(Uni_Name,Uni_Rank,Uni_Level,Uni_Score): try: print('%-14s %-11s %-15s %-10s %-0s' % ("学校排名","学校层次","学校名称","总分",chr(12288))) for i in range(len(Uni_Level)): print('%-13s %-15s %-12s %-12s %-10s' % (Uni_Rank[i],Uni_Score[i][0],Uni_Name[i],Uni_Score[i][1],chr(12288))) except Exception as err: print(err) -
1.4 结果显示
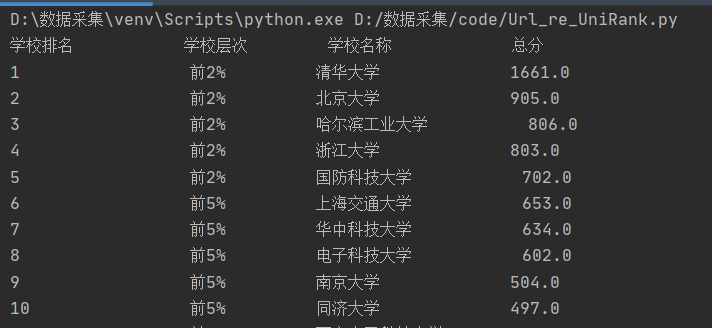
-
-
2)心得体会
- 不使用BeautifulSoup让自己更加的熟悉re正则的运用
- 知悉在处理文本时应处理一些细节问题,如空格,换行符等
-
代码地址: https://gitee.com/zhubeier/zhebeier/blob/master/数据采集第一次作业/第一题
作业二
-
要求 用requests和Beautiful Soup库方法设计爬取(https://datacenter.mee.gov.cn/aqiweb2/ )AQI实时报。
-
输出信息
序号 城市 AQI PM2.5 SO2 No2 Co 首要污染物 1 北京 55 6 5 1.0 225 — 2...... -
1)解题过程
-
1.1 主要函数
def GetHTML(url):#获取HTML内容 try: header = {"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} req = requests.get(url,headers = header) req.raise_for_status() req.encoding = req.apparent_encoding return req.text except Exception as err: print(err) def GetText(text):#获取文本 try: soup = BeautifulSoup(texte,'lxml') new_text = soup.select('td[style="text-align: center; "]') #print(type(new_text)) #print(new_text) return new_text except Exception as err: print(err) def Show(text):#打印结果 try: j = 1 print("{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format('序号','城市','AQI','PM2.5','SO2','NO2','CO','首要污染物')) for i in range(0,len(new_text),9): print("{:^10}\t{:^8}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format(j,new_text[i].text,new_text[i+1].text,new_text[i+2].text,new_text[i+4].text,new_text[i+5].text,new_text[i+6].text,new_text[i+8].text.strip()))#strip:移除空格 j += 1 print(len(new_text)) except Exception as err: print(err) -
1.2 结果显示
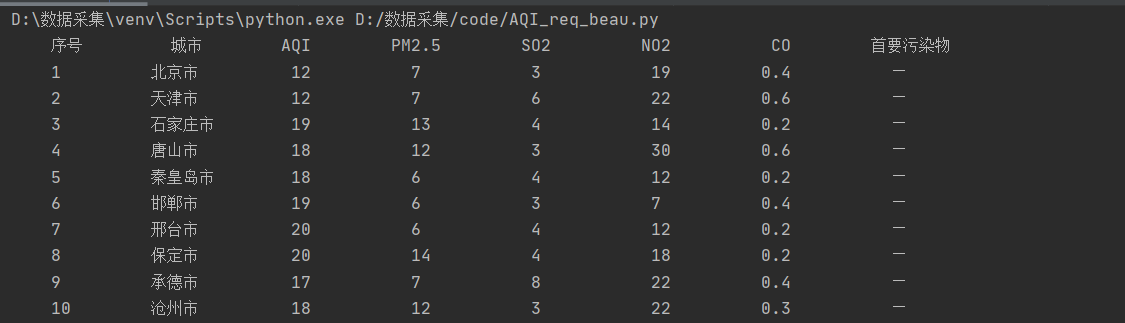
-
-
心得体会
- 熟悉了requests库和urllib.request库的区别。
- 熟悉了利用BeautifulSoup处理HTML文档,并利用find_all方法寻找所需元素。
-
代码地址 https://gitee.com/zhubeier/zhebeier/blob/master/数据采集第一次作业/第二题
作业三
- 要求:使用urllib和requests爬取(http://news.fzu.edu.cn/),并爬取该网站下的所有图片
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
- 1)解题过程
- 1.1 主要函数
def GetHtml(url):#获取url内容 try: header = header = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}#加上头伪装 req = requests.get(url,headers=header) req.raise_for_status() req.encoding = req.apparent_encoding return req.text except Exception as err: print(err) def GetImage(text): try: reg = 'src="(.*?).jpg"'#正则表达式 list_jpg = re.compile(reg).findall(text)#利用正则表达式找到图片的路径 #print(image_list) for i in range(0,len(list_jpg)): image_url = 'http://news.fzu.edu.cn/'+list_jpg[i]#图片保存的路径 file = "D:/FZU_img/" + "第" + str(i) + "张" + ".jpg"#为图片命名(需要先创建相应的文件夹) urllib.request.urlretrieve(image_url,filename=file)#(将图片下载到本地文件夹) reg = 'src="(.*?).png"' # 正则表达式 list_png = re.compile(reg).findall(text) for i in range(0,len(list_png)): image_url = 'http://news.fzu.edu.cn/'+list_png[i]#图片保存的路径 file = "D:/FZU_img/" + "第" + str(i) + "张" + ".png"#为图片命名(需要先创建相应的文件夹) urllib.request.urlretrieve(image_url,filename=file)#(将图片下载到本地文件夹) except Exception as err: print(err) - 1.2 结果显示
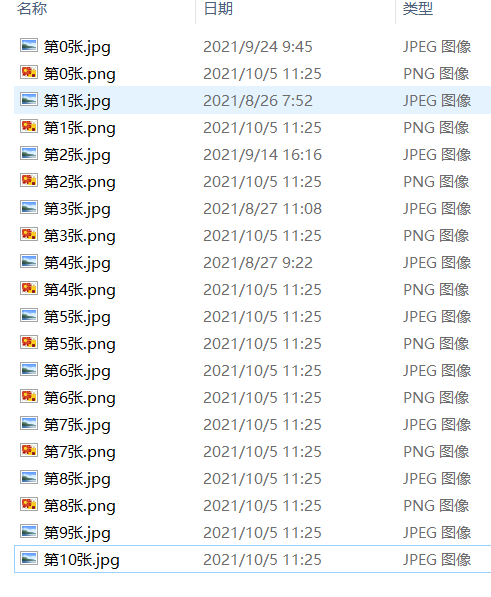
- 1.1 主要函数
- 2)心得体会
- 学会了利用urllib.request.urlretrieve将网页图片保存到本地
- 更加熟悉了findall正则匹配查找所需内容
- 代码地址:https://gitee.com/zhubeier/zhebeier/blob/master/数据采集第一次作业/第三题
