记录一次 embedding 实践
整个过程: 通过google colab平台以及之前这里提到的脚本, 注入要训练的数据, 开始聊天.(如果不想使用 colab, 这里有一个不错的本地项目here)
过程很简单, 现在按照它文档中的流程开始跑
1.准备要注入的数据, 我准备灌输一些从各种商业分析文章获取的知识, 让 GPT 帮我分析现在与未来的 AI 商业机会, 以及我以一个普通人的身份如何参与到其中.
(共100多K的纯文本)

2.按照指引向下: 下载数据, 安装模块, 设置openai_key
(无法操作记得点右上角的 connect 建立连接)
3.开始跑数据
问题:
1.默认读取的是目录, 解决: 新建一个目录把文件放入
2.文件太大, 无法运行
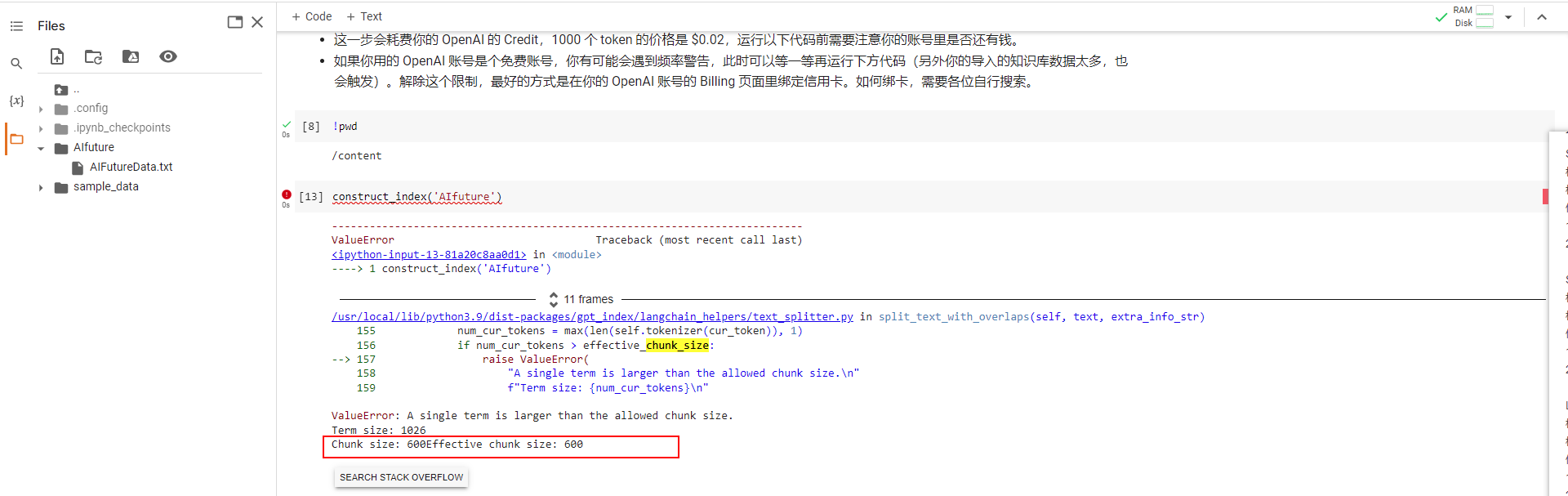
问下 GPT 该怎么办
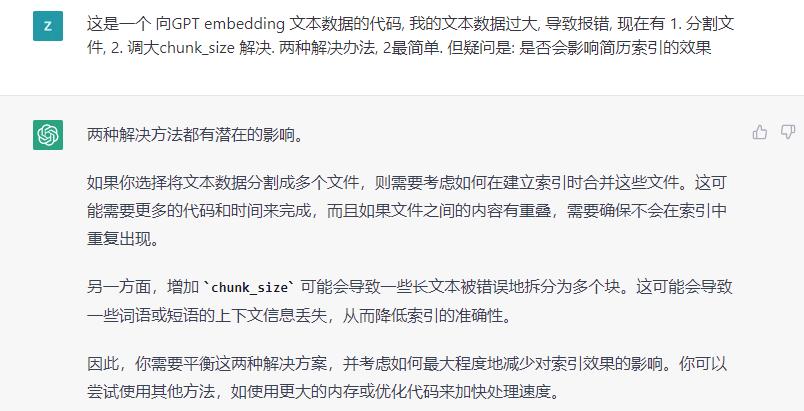

两种都采用: 1.准备分离下数据 2.chunk_size 调到了1024
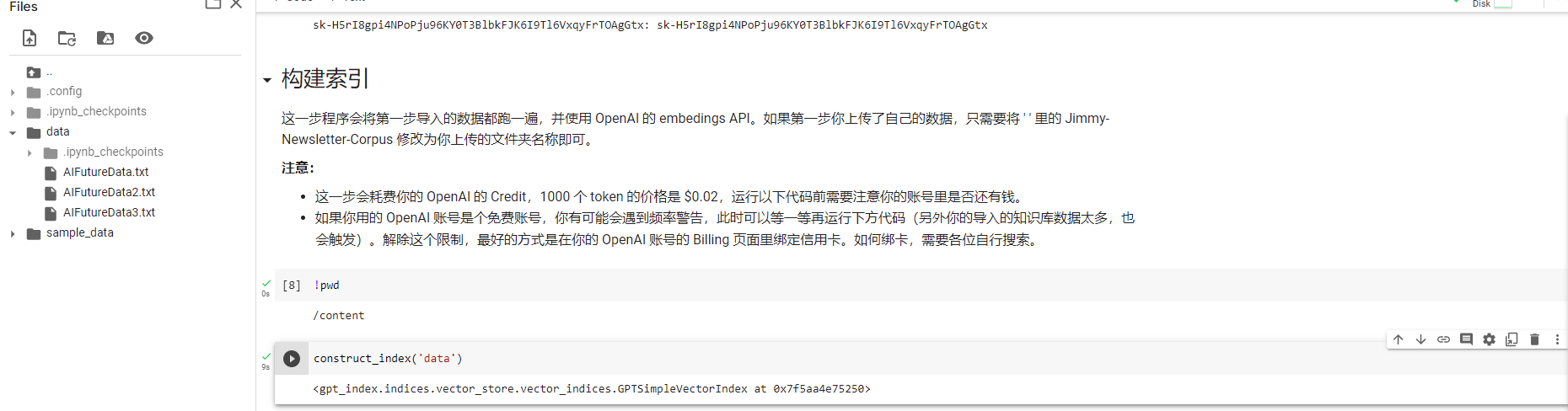
成功, 接下来开始提问了
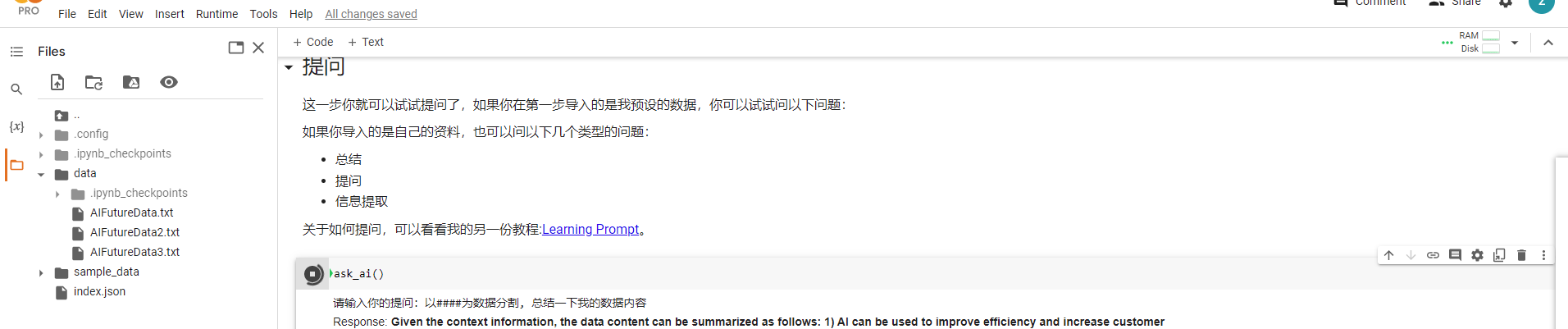
体验结果:
总花费 $0.40, 效果并不理想, 问的问题只从输入的文本总结获取, 没有了自己的独立意识, 只剩下一个总结的躯壳, 总结的很范, 无法达到给出具体的商业建议.
之后会继续体验, 找到最佳的 prompt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号