chatPDF学习 embedding
一.
近期很火的chatPDF. 分析原因, 想一下能和一本书沟通, 这本身就是一件神奇的事情, 再者, 它能帮助你通过聊天的方式学习到其中的内容, 调动了学习的乐趣. 除了装X外, 乐趣也是很大的驱动力啊.
其它人的理解:
1)chatpdf并不能增强chatgpt阅读长文的能力,其能力依然锁定在4096个token内
2)pdf的所谓阅读的做法是把文章分成无数个上述长度内的片段然后生成embedding。你提问,依赖embedding召回,最后再去问一次chatgpt
3)字体变小会让成本加倍增长
相关的原理介绍
搭建基于知识库内容的机器人
其实我这个需求,在传统的机器人领域已经有现成方法,比如你应该看到不少电商客服产品,就有类似的功能,你说一句话,机器人就会回复你。
这种传统的机器人,通常是基于意图去回答人的问题。举个例子,我们构建了一个客服机器人,它的工作原理简单说来是这样的:
当用户问「忘记密码怎么办?」时,它会去找最接近这个意图「密码」,每个意图里会有很多个样本问题,比如「忘记密码如何找回」「忘记密码怎么办」,然后这些样本问题都会有个答案「点击 A 按钮找回密码」,机器人会匹配最接近样本问题的意图,然后返回答案。
但这样有个问题,我们需要设置特别多的意图,比如「无法登录」、「忘记密码」、「登录错误」,虽然有可能都在描述一个事情,但我们需要设置三个意图、三组问题和答案。
虽然传统的机器人有不少限制,但这种传统方式,给了我们一些灵感。
我们好像可以用这个方法来解决限制 token 的问题,我们仅需要传符合某个意图的文档给 AI,然后 AI 仅用该文档来生成答案:
比如还是上面的那个客服机器人的例子,当用户提问「忘记密码怎么办?」时,匹配到了「登录」相关的意图,接着匹配知识库中相同或相近意图的文档,比如「登录异常处理解决方案文档」,最后我们将这份文档传给 GPT-3,它再拿这个文档内容生成答案。
GPTIndex 这个库简单理解就是做上图左边的那个部分,它的工作原理是这这样的:
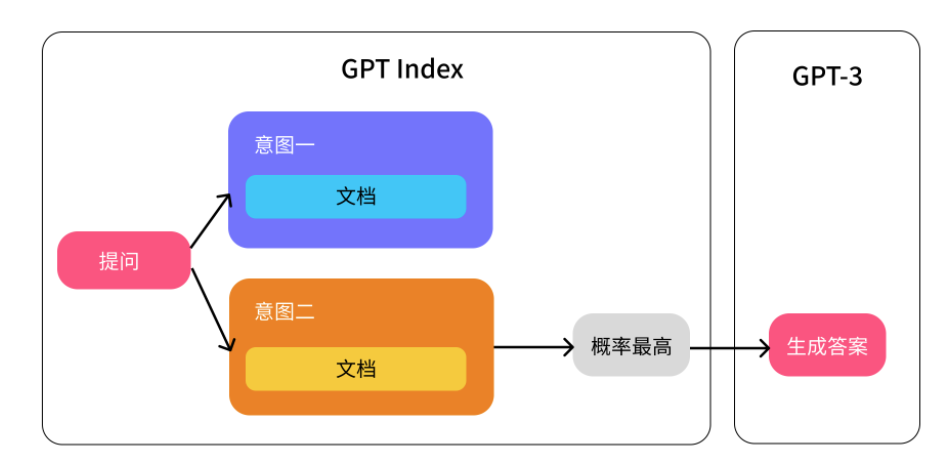
创建知识库或文档索引
找到最相关的索引
最后将对应索引的内容给 GPT-3
限制与注意的地方
虽然这个方法解决了 token 限制的问题,但也有不少限制:
当用户提一些比较模糊的问题时,匹配有可能错误,导致 GPT-3 拿到了错误的内容,最终生成了非常离谱的答案。
当用户提问一些没有多少上下文的信息时,机器人有时会生成虚假信息。
所以如果你想用这个技术做客服机器人,建议你:
通过一些引导问题来先明确用户的意图,就是类似传统客服机器人那样,搞几个按钮,先让用户点击(比如无法登录)。
如果相似度太低,建议增加兜底的回答「很抱歉,我无法回答你的问题,你需要转为人工客服吗?」"
GPT进行工作原理总结:
GPT Index库的工作原理可以简单概括为:
创建知识库或文档索引:将一组文本内容(如newsletter)转换成向量形式,并将这些向量放入索引中。
找到最相关的索引:当需要使用文本内容时,将该文本内容转换成向量,然后在索引中寻找与该向量最相似的向量,从而找到与该文本内容最相关的文本。
最后将对应索引的内容给GPT-3:将找到的相关文本传递给GPT-3模型,让其根据文本内容生成答案或建议。
这种方法的好处在于,它可以解决限制token数的问题,因为我们可以将一个非常长的文本内容(如newsletter)分成多个小的、符合某个意图的文本,然后分别将它们放入索引中。当我们需要使用这些文本内容时,我们只需要将与需要回答的问题最相关的文本传递给GPT-3,这样就可以大大减少token数,同时还可以提高模型的回答准确度。
不过,这种方法也存在一些限制和注意事项,如匹配错误、生成虚假信息等问题。因此,建议在使用这种方法时,需要进行一些引导问题,以明确用户意图,并增加兜底的回答来处理匹配错误的情况。
我的理解为:
举例: 所有的文本转换成数字向量存储, 而索引则是一张纸, 当有问题进入时转换成向量. 然后在纸上寻找相同的或者最贴近的向量. 之后返回, 如果没有匹配到就可能返回假的答案.
举例: 假设一个纸上有五个1: 11111, 而你输入的prompt 是: 11100, 那么他们有 60% 的相似度. 我可以这样设定, 当相似度低于 60% 时, 返回兜底内容「很抱歉,我无法回答你的问题,你需要转为人工客服吗?」, 当相似度低于 80% 时, 返回兜底内容「你是要找这个内容吗: 11111」,当相似度在 90% 左右时, 返回内容「11111」. 这种方式是相似度阈值 + 混合模型策略.
0327 add:
向量的转换原理大致为
将近似的词汇存储在相近的地方.
例子: apple -> [1, 0] orange -> [0.9, 0.1] car -> [0, 1] bus -> [0.1, 0.9]
可以观察到,水果(苹果和橙子)的向量在第一个维度上具有较高的值,而交通工具(汽车和公共汽车)在第二个维度上具有较高的值。这种表示方法捕捉了单词之间的关系:相似的单词在向量空间中靠得更近。
--这只是一个简化的例子,实际的单词嵌入算法(如 Word2Vec、GloVe 和 FastText)使用更复杂的技术来学习单词之间的关系。这些算法使用大量的文本数据作为输入,分析单词之间的共现信息(即单词在文本中一起出现的频率),并学习将单词映射到高维空间中的向量,以便捕捉单词之间的语义关系。这些高维向量可以捕捉诸如相似性、类比和关联性等复杂关系,从而帮助改进各种自然语言处理任务的性能。
交互过程
1.当我输入查询 "如何在AI时代寻找商业机会"。
2.根据输入的查询在嵌入库中搜索最相关的文档内容。这个过程涉及将查询与库中的文档进行比较,并找到与查询最匹配的文档。
3.找到最相关的文档内容后,将其与用户的查询一起生成一个新的 prompt。这个新的 prompt 可能类似于 "根据这篇关于 AI 领域的文章,如何在 AI 时代寻找商业机会?",其中包含了搜索到的文档内容。
4.将新的 prompt 传递给 GPT 模型。GPT 模型会根据新的 prompt、搜索到的文档内容以及其内置的知识库生成回应。这个回应可能包含关于在 AI 时代寻找商业机会的策略和建议。
5.之后就是 GPT 返回最终内容
问题: 当向量中匹配了超过输入限制的内容时如何处理
1.对文档进行排序和筛选:利用相关性或其他评分机制进行优先级排列, 找出最相关的内容.
2.分批查询:现在市面上的视频总结插件使用的就是这个原理, 分批发送, 接收响应, 重复执行, 最后可以根据已有数据再进行全文总结.
3.对文档进行摘要:在生成新的 prompt 时,您可以尝试对找到的文档内容进行摘要,提取每篇文档中的关键信息。可以使用自动摘要技术(如 extractive 或 abstractive summarization)来实现这个功能。
(注意: 通过举例的方式学习, 信息的传递是有损的, 参考这里)
二.
另外还有一款平替的软件: https://mapdeduce.com/ . 还有看其它人说可以使用 DEV 版的 edge 浏览器, 效果也极佳.
最后, 对于类似的应用有一个疑问. 对于一本没有读过的 PDF 且不知道其中的内容概要, 应该如何提问呢.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号