Python基础篇---日志模块组成部分,配置字典,第三方模块,openpyxl模块
本章内容
• 日志模块组成部分
• 配置字典和使用
• 第三方模块
• openpyxl模块
日志模块的主要组成部分
模块的导入:import logging。
1.logger对象:产生日志(无包装的产品)
logger = logging.getLogger('转账记录')
2.filter对象:过滤日志(剔除不良品)
针对过滤功能完全可以不看 因为handler自带了基本的过滤操作
3.handler对象:控制日志的输出位置(文件、终端...) (产品分类)
hd1 = logging.FileHandler('a1.log',encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log',encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
4.format对象:控制日志的格式(包装)
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
5.给logger对象绑定handler对象
logger.addHandler(hd1) logger.addHandler(hd2) logger.addHandler(hd3)
6.给handler绑定formmate对象
hd1.setFormatter(fm1) hd2.setFormatter(fm2) hd3.setFormatter(fm1)
7.设置日志等级
logger.setLevel(10) # debug
8.记录日志
logger.debug('累死了,想睡觉!!')
配置字典和使用
字典的配置
1.导入模块
import logging import logging.config
2.定义日志输出格式
# 定义日志输出格式 开始 # 标准格式 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 # 简单格式 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束
3.自定义输出文件路径
logfile_path = 'log.log'
4.log配置字典
LOGGING_DIC = {
'version': 1, # 日志的版本
'disable_existing_loggers': False, # 禁用已经存在的logger实例
# 日志文件的格式
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard', # 日志格式
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5, # 最多备份几个
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '注册记录': {
# 'handlers': ['console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
5.使用日志字典配置
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger('日志1') logger2 = logging.getLogger('日志2') logger1.warning('当前为日志1') logger2.debug('当前为日志2')
字典的使用
日志字典数据是日志模块固定的配置,写完一次之后几乎都不需要动,它属于配置文件,应该放在conf文件里。
第一步:配置好字典,写在conf文件夹的settings.py文件里(也可以自己找目录放)。
import logging import logging.config # 定义日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束 # 自定义文件路径(产生的日志文件应该放在log文件夹下) # logfile_path = 'a3.log' import os # BASE_DIR = os.path.dirname(__file__) LOG_DIR = 'log' logfile_name = 'a1.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(LOG_DIR): os.mkdir(LOG_DIR) # log文件的全路径 logfile_path = os.path.join(LOG_DIR, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, # 过滤日志 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置 # '注册记录': { # 'handlers': ['console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 # 'level': 'WARNING', # 'propagate': True, # 向上(更高level的logger)传递 # }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置 }, }
第二步:在common.py公共功能文件里导入settings.py文件,创建一个日志函数。
import logging import logging.config from day23.conf import settings def get_logger(msg): # 记录日志 logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger(msg) # logger1.debug(f'{username}注册成功') # 这里让用户自己写更好 return logger1
第三步:将common.py文件导入到核心业务文件的功能区代码里使用。
from ATM.lib import common def register(): username = input('username>>>:').strip() password = input('password>>>:').strip() logger = common.get_logger('用户注册') logger.debug(f'{username}注册成功') register()
第四步:根据设置的日志导出路径,查看输出的日志。
[2022-04-01 21:25:25,963][MainThread:5096][task_id:用户登录][src.py:18][WARNING][123登录成功]
第三方模块
如何利用工具
需要使用python解释器提供的pip工具,pip的路径在python解释器文件夹内的scripts目录下。
如果下载终端中直接使用pip目录,需要添加环境变量。 python解释器的路径: F:\Python36 pip工具的路径: F:\Python36\Scripts 我们在使用pip工具的时候 为了区分版本会人为的将python3的pip工具写成pip3,python2的pip工具写成pip。
如何查看当前解释器下载的第三方模块
我们一般借助编辑器pycharm查找当前解释器已经下载的第三方模块
查找顺序:file --> settings --> project --> python interpter 纯净的解释器默认只有两个:pip和setuptools
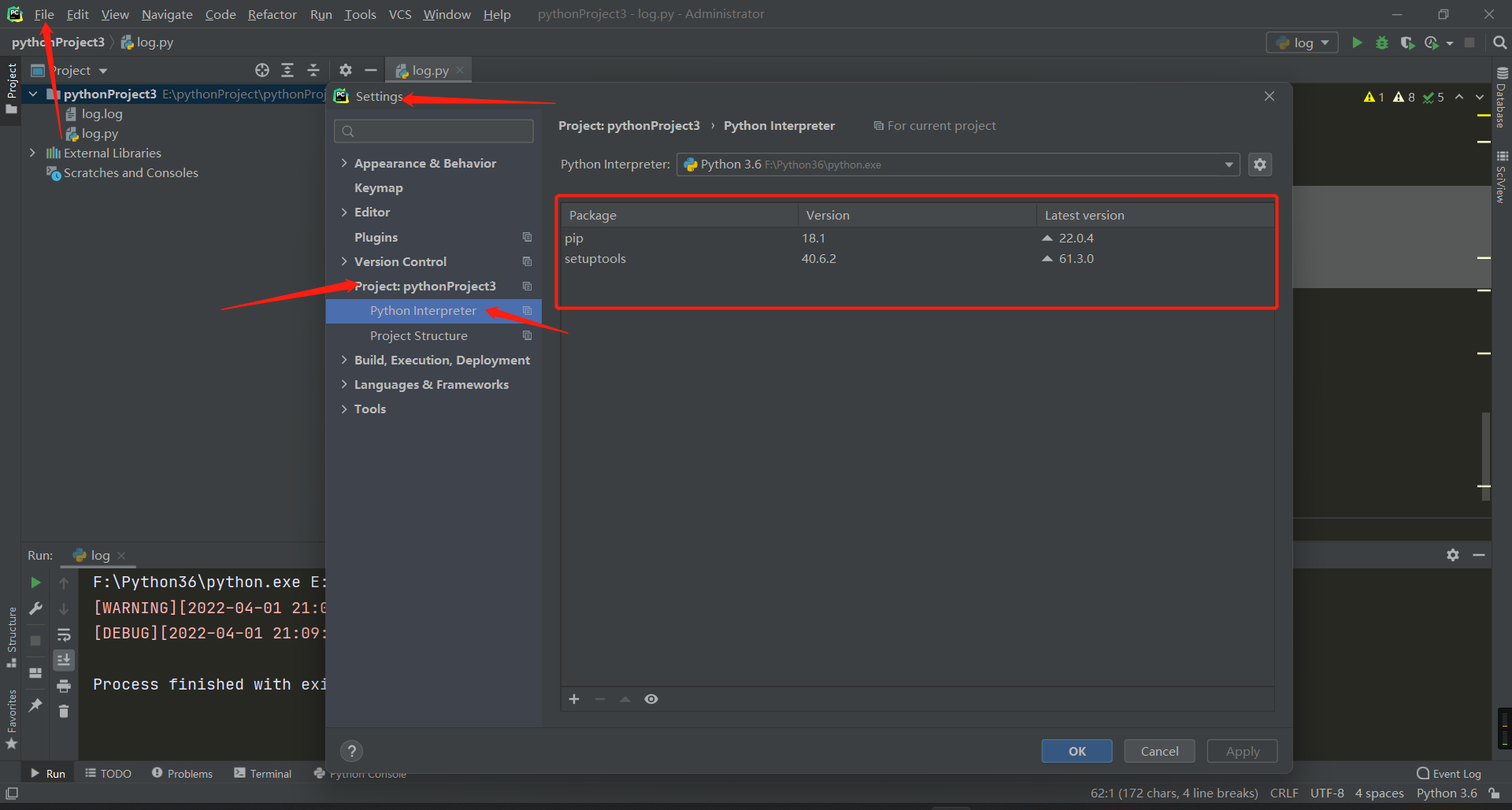
如何下载第三方模块
方式1:
pip3 install 模块名 '''该方式默认下载的是最新版本''' pip3 install 模块名==版本号 '''自定义下载版本号'' pip3 install 模块名 -i 仓库地址 # 命令行临时修改地址 ps:pip工具默认是从国外的仓库下载模块 速度会比较慢 可以修改
仓库地址:
阿里云http://mirrors.aliyun.com/pypi/simple/ 豆瓣http://pypi.douban.com/simple/ 清华大学https://pypi.tuna.tsinghua.edu.cn/simple/ 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/ 华中科技大学http://pypi.hustunique.com/
方法2:
第一步:file --> settings --> project --> python interpter 第二步:双击任意一个模块名称或者左下角加号按钮, 第三步:在搜索框中输入你想要下载的模块即可,并且可以在左侧勾选specify version选择版本。 ps:pycharm可以换源,左下方点击manage repositoires管理地址即可
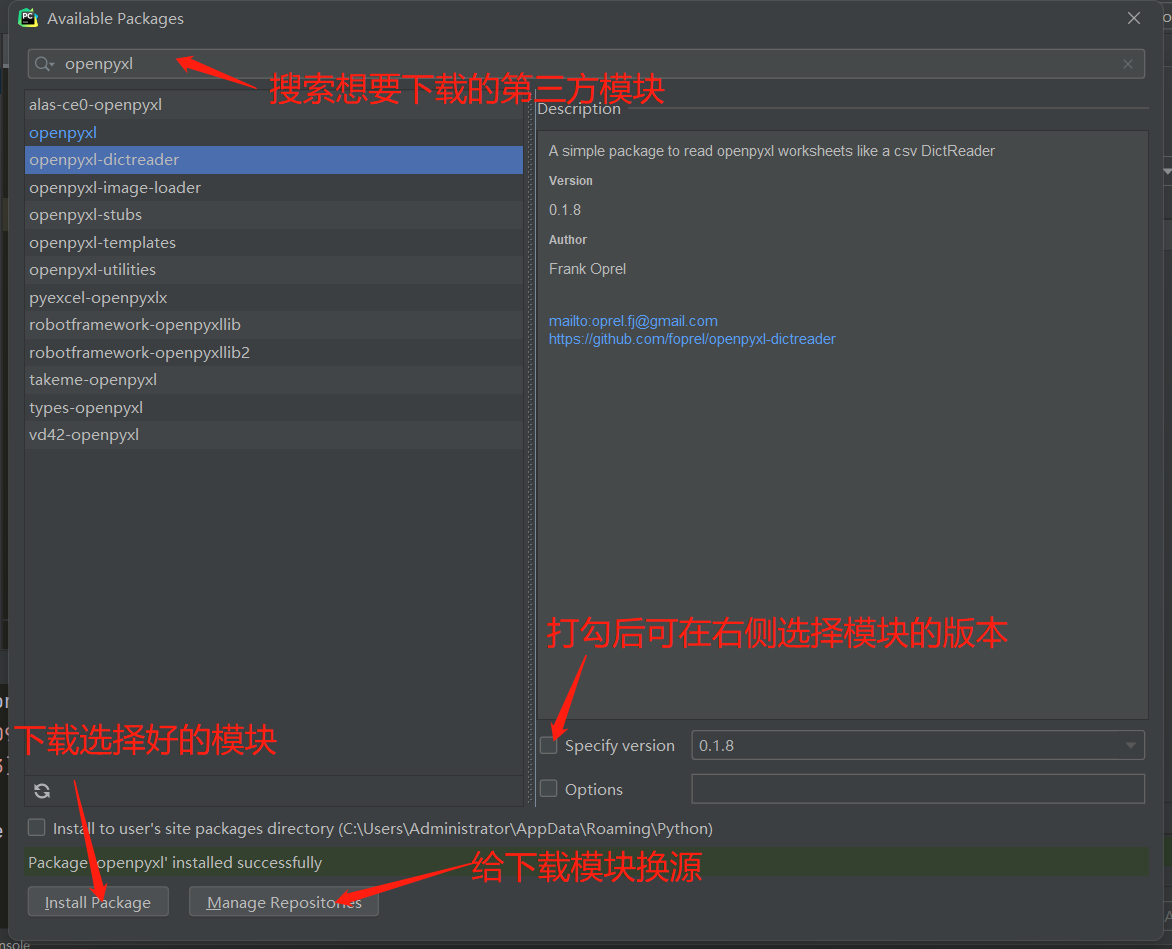
下载模块时可能会报错的信息:
1.报错信息中含有timeout关键字 原因是你当前计算机的网络不稳定,重新执行多次或者切换网络 2.报错信息中没有太多的关键字 并且很长 拷贝最后一行错误信息 去百度
openpyxl模块是一个读写Excel文档的Python库,openpyxl是一个比较综合的工具,能够同时读取和修改Excel文档。
""" excel文件的版本及后缀 2003版本之前 excel的文件后缀是xls 2003版本之后 excel的文件后缀是xlsx、csv 在python中能够处理excel文件的模块有很多 其中最出名的有 xlrd、xlwt分别控制excel文件的读写 能够兼容所有版本的文件 openpyxl针对03版本之前的兼容性可能不好 但是功能更加强大 """
1.如何创建excel文件
from openpyxl import Workbook
wb = Workbook() # 创建excel文件
wb1 = wb.create_sheet('学员名单') # 创建工作簿
wb2 = wb.create_sheet('缴费名单') # 创建工作簿
wb3 = wb.create_sheet('消费记录',0) # 创建工作簿
wb1.title = '学员名单名称修改' # 修改工作簿名称
wb.save('aaa.xlsx') # 保存excel文件
2.如何写数据
1.写普通数据方式1
wb1['C3'] = '麻辣香锅'
wb2['B1'] = '螺蛳粉'
wb3['D4'] = '肯德基全家桶'
2.写普通数据方式2
wb3.cell(row=2, column=3, value='饥不择食') # row行 column列
wb3.cell(row=1, column=1, value='清蒸鲍鱼')
3.批量写普通数据
wb1.append(['username','age','gender'])
wb1.append(['jason', 18, 'male'])
wb1.append(['jason2', 28, 'female'])
4.写公式数据(也可以在python代码中处理完毕以普通数据写入)
wb1['A1'] = 666
wb1['A2'] = 999
wb1['A3'] = '=sum(A1:A2)'
3.如何读数据
获取所有的工作簿名称,结果是列表数据类型
from openpyxl import load_workbook
wb = load_workbook('1.xlsx',read_only=True,data_only=True) # 获取1.xlsx中所有的工作薄名称
# read_only 优化阅读,不能编辑 data_only 控制带有公司的单元格是否具有公式或上传excel读取工作表时存储的值
print(wb.sheetnames)
取值方式
from openpyxl import load_workbook
wb = load_workbook('1.xlsx')
wb1 = wb['test'] # 拿到工作薄test对象
第一种取值方式
print(wb1['A3'].value) # 不是结果 需要再点value
print(wb1['A6'].value) # 获取用函数统计的数据,发生无法取到值
"""
第一需要加一个参数
第二需要人为的先去修改一下用程序产生的excel表格(不可能用程序产生excel文件之后又直接再用程序去读入,这样没有任何实际意义 通常用程序创建好表格后给人看,人讲自己修改的表格再交由程序处理)
"""
第二种取值方式
print(wb1.cell(row=3,column=4).value) # 第二种取值方式
获取一行行的数据
for row in wb1.rows: # 拿到每一行的数据
for data in row: # 拿到一行行数据里面每一个单元格的数据
print(data.value)
获取一列列的数据(如果想获取 必须把readonly去掉)
for column in wb1.columns: # 拿到每一列的数据
for r in column: # 拿到一列列数据里面每一个单元格的数据
print(r.value)
获取最大的行数和列数
print(wb1.max_row) print(wb1.max_column)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号