
hotchip2025 nvidia的GB10 SOC 转载
from 智能计算芯世界


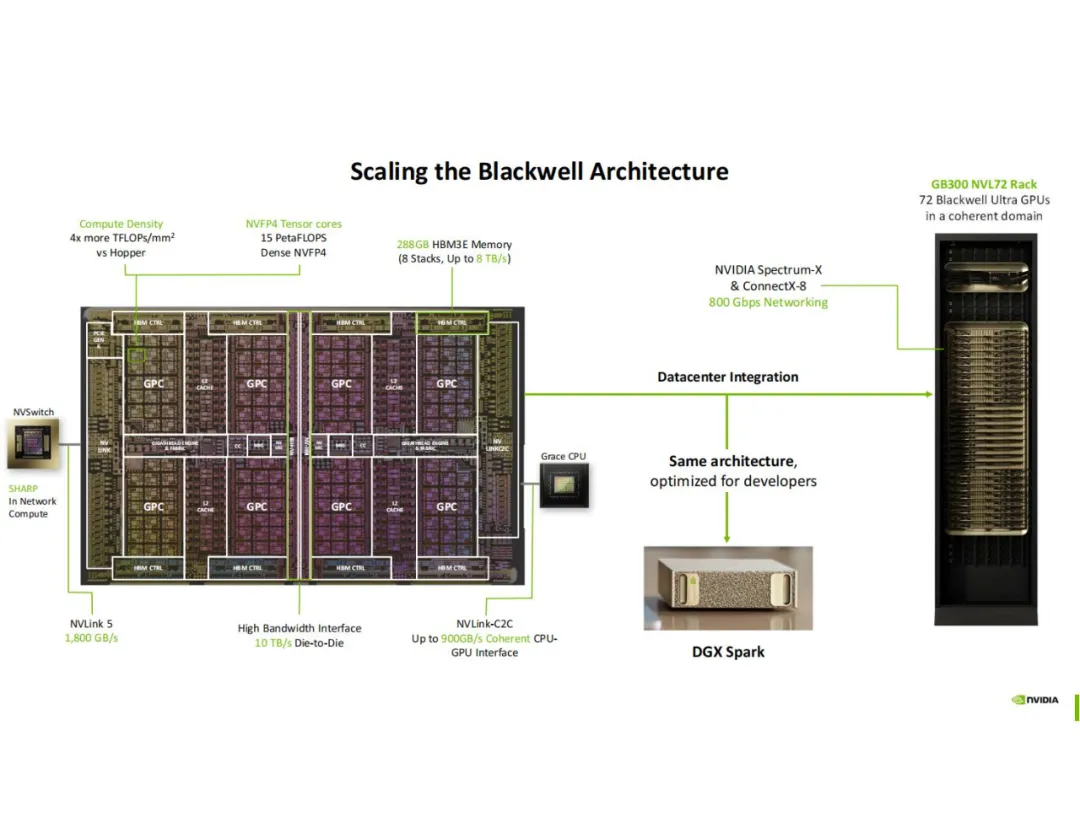

1. 基础架构:工艺、封装与功耗控制
GB10 采用台积电 3nm 工艺制造,通过 2.5D 中介层完成封装,最直接的优势是功耗控制:整体功耗稳定在 140 瓦,可直接接入标准壁式电源,无需依赖服务器机柜的复杂配电系统。这一设计对中小型研究团队、独立开发者及实验室场景极具实用价值 —— 无需搭建专业机房,即可拥有高性能计算能力。
2. CPU 部分:联发科 Arm 架构的协同优化
CPU 单元由联发科提供,基于 Arm v9.2 架构打造,采用 “双集群” 设计:
- 共 20 个内核,分为 2 个集群(每集群 10 核);
- 缓存配置为 “32MB 共享 L3 缓存 + 每核独立 L2 缓存”。
这种架构让 CPU 既能高效处理大规模并行任务(如数据预处理),也能灵活应对中小规模串行任务(如逻辑控制),兼顾 “低延迟” 与 “多线程吞吐能力”,为 CPU 与 GPU 的协同计算打下基础。
3. 内存子系统:统一架构破解数据同步难题
GB10 的核心突破之一是统一内存架构:采用 LPDDR5X-9400 规格,总线宽度 256 位,提供约 301GB/s 带宽,最高支持 128GB 容量。更关键的是,CPU 与 GPU 共享这一内存体系 —— 无需频繁进行内存复制与同步,彻底消除了传统 “CPU 内存 + GPU 显存” 分离架构下的 “数据搬运开销”。
这对 AI 场景意义重大:在模型训练与推理中,参数调用频率极高,统一内存可大幅减少数据传输延迟,直接提升计算效率。
4. GPU 部分:Blackwell 架构的 “精简不减质”
GPU 单元是 Blackwell 架构的缩小化版本,但核心特性完全保留:
- 精度支持:保留 FP4(4 位浮点)运算能力,在超低精度推理场景中可实现 1000 TOPS 的计算性能,FP32(32 位浮点)峰值性能达 31 TFLOPS,满足桌面级 AI 开发的算力需求;
- 缓存一致性:GPU 内置 24MB 二级缓存,并通过 “地址转换服务(ATS)+ 硬件管理” 实现与 CPU 的缓存一致性 —— 开发者无需在软件层面编写复杂的同步逻辑,大幅简化编程流程与工作流,这也是 GB10 架构的核心亮点之一。
5. 互联能力:C2C 链路与双机扩展
GB10 通过Chip-to-Chip(C2C)链路强化互联性能:提供约 600GB/s 带宽,实现 CPU 与 GPU 的低延迟数据交换,相比传统 PCIe 接口效率更高。同时,DGX Spark 集成 ConnectX-7 网卡,支持通过 PCIe 5.0 x8 通道与另一台 Spark 工作站配对,形成 “双机互联” 模式。
尽管受限于带宽,网卡的两个 200Gbps 接口无法同时满速运行,但对于中小规模分布式任务(如多卡协同微调模型),已具备实用价值,进一步拓展了轻量化场景的算力上限。
6. 设计逻辑:聚焦 “常用任务” 的效率优化
GB10 的设计核心并非追求与完整版 DGX 系统对等的峰值性能,而是 “精准匹配开发者常用任务”:通过合理的 CPU/GPU 配比、统一内存与缓存一致性,让数据预处理、模型原型验证、中小规模微调等高频操作,能在桌面级设备上顺畅运行 —— 为后续大规模训练提供 “前置实验环境”,减少对云端资源的依赖。
Part 2 DGX Spark:应用价值与产业意义
DGX Spark 作为 GB10 SoC 的落地载体,不仅是硬件创新的体现,更承载了英伟达 AI 生态战略的延伸 —— 它的出现,正在重新定义 “轻量化 AI 计算” 的边界。
1. 硬件能力:覆盖主流大模型开发需求
DGX Spark 的硬件配置直接瞄准桌面级 AI 开发痛点:
- 128GB 统一系统内存 + 最高 4TB SSD 存储,可支持700 亿参数模型的微调任务;
- 开发者无需依赖昂贵的云端数据中心资源,即可在本地完成 “数据处理→模型训练→效果验证” 的完整流程,大幅降低 AI 开发的 “启动成本”。
2. 场景适配:中小团队的 “高性价比选择”
尽管双机互联模式的性能不及 DGX SuperPOD 等高端集群,但对中小团队而言,这种组合已能胜任多数研究与商用开发任务(如行业定制化小模型训练、AI 应用原型开发)。它将 AI 开发的 “入门门槛” 从 “企业级投入” 拉到 “桌面级预算”,让更多用户有机会参与到大模型应用的实验中。
3. 生态价值:“桌面 - 云端” 的无缝衔接
英伟达明确将 DGX Spark 定位为 AI 开发的 “网关”:用户在本地通过 Spark 完成模型开发与验证后,可直接将成熟模型迁移至 DGX Cloud 或更大规模的 DGX 系统部署 —— 整个过程基于统一的 CUDA 软件栈,开发者无需因硬件环境差异调整开发逻辑,实现 “一次开发,多端部署” 的平滑过渡。
这种 “桌面 - 云端” 的生态闭环,进一步巩固了 CUDA 生态的粘性,也让英伟达的 AI 生态从 “高端数据中心” 下沉至 “桌面级开发”,覆盖更广泛的用户群体。
4. 战略意义:合作与下沉的 “双重突破”
GB10 的推出,也体现了英伟达在 CPU/GPU 协同领域的 “开放态度”:
- 与联发科的合作,标志着英伟达不再坚持 CPU 自研,而是通过生态合作快速补齐短板,这种跨企业深度绑定,未来可能延伸至高性能计算与消费级产品领域(如传闻中的 N1/N1x SoC,或基于 GB10 理念下沉至消费级笔记本);
- 面对 AMD、Intel 及 AI 芯片初创企业的竞争,GB10 与 DGX Spark 是英伟达在 “高端数据中心之外” 的新突破口 —— 通过 “轻量级 AI 超算” 体验,巩固其在 AI 开发者社区的地位,同时扩大 CUDA 生态的影响力。
5. 应用价值的三大核心层面
DGX Spark 的价值可概括为三个维度:
- 开发层面:为开发者提供 “低门槛、高性能” 的本地开发环境,缩短 AI 应用的研发周期;
- 生态层面:构建 “桌面 - 云端” 的无缝衔接链路,完善英伟达 AI 生态的闭环;
- 产业层面:通过跨界合作与技术下沉,拓展英伟达的市场版图,让 GB10 从 “单一硬件创新” 升级为 “产业布局的关键节点”。
小结
在 2025 年 Hot Chips 大会上,英伟达 GB10 SoC 展现了其在 “CPU/GPU 协同、统一内存架构、低功耗高性能设计” 上的新思路,而 DGX Spark 则是这一思路的落地载体 —— 它以 “缩小版 Blackwell GPU+Arm CPU” 的组合,为中小型团队提供了 “触手可及” 的 AI 开发平台,同时通过与云端 DGX 系统的无缝衔接,形成 “本地开发 - 云端部署” 的完整通路。
从长远来看,GB10 SoC 不仅为桌面级 AI 开发树立了新的性能基准,更可能成为未来消费级 SoC 的设计蓝本;而 DGX Spark 的推广,或将推动 AI 开发生态进一步普及,让更多用户群体直接参与到大模型的实验与应用中,为 AI 产业的 “轻量化、平民化” 发展注入新动力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号