
音乐推荐与Audioscrobbler数据集
1. Audioscrobbler数据集
数据下载地址:
http://www.iro.umontreal.ca/~lisa/datasets/profiledata_06-May-2005.tar.gz
Audioscrobbler 数据集只记录了播放数据,如“Bob 播放了一首Prince 的歌曲”。播放记录所包含的信息比评分要少。仅凭Bob 播放过某一首歌这一信息并不能说明他真的喜欢这首歌。
虽然人们经常听音乐,但却很少给音乐评分。因此Audiocrobbler 数据集要大得多。它覆盖了更多的用户和艺术家,也包含了更多的总体信息,虽然单条记录的信息比较少,这种类型的数据通常被称为隐式反馈数据,因为用户和艺术家的关系是通过其他行动隐含体现出来的,而不是通过显示的评分或点赞得到的
2. 交替最小二乘推荐算法
现在我们要给这个隐式反馈数据选择一个合适的推荐算法。这个数据及只记录了用户和歌曲之间的交互情况。
除了艺术家的名字外,数据集没有包含用户的信息,也没有提供歌手的其他任何信息。我们要找的学习算法不需要用户和艺术家的属性信息。这类算法通常称为协同过滤算法。
举个例子:根据两个用户的年龄相同来判断他们可能有相似的偏好,这不叫协同过滤。相反,根据两个用户播放过许多相同歌曲来判断他们可能都喜欢某首歌,这才叫协同过滤
3. 矩阵分解模型
现在我们的用户和产品数据可以视为一个大矩阵A,矩阵第i 行和第j 列上的元素都有值,代表用户i 播放过艺术家 j 的音乐。
可以预料到,矩阵A 是稀疏的,里面大多数元素为0.因为相对于所有可能的 用户 – 艺术家 组合,只有很少一部分组合会出现在数据中。

这里我们使用的是一种矩阵分解模型( Non-negative matrix factorization)。算法将A 分解为两个小矩阵 X 和 Y 的乘积:
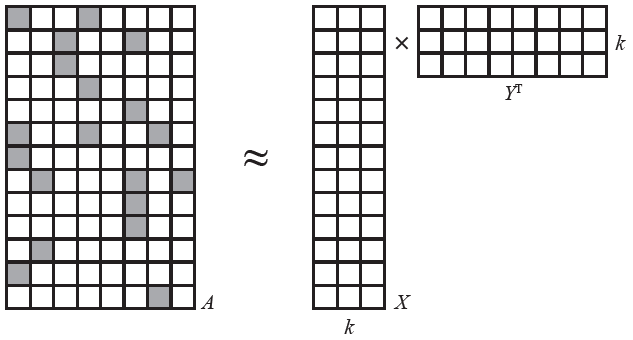
如图所示,假设A 为 m x n矩阵,X 为 m x k矩阵,Y为 n x k 矩阵。此时X与Y 均是行多列少。行分别为用户数与艺术家数,列均为 k(k为一个较小值)。此时 k 称为潜在因素。
4. 潜在因素
潜在因素(factor analysis)模型:
潜在因素模型试图通过数量相对较少的未被观察到的底层原因,来解释大量用户和产品之间可观察到的交互。
例如:有几千个专辑可选,为什么数百万人偏偏只买其中某些专辑?可以用对类别(可能只有数十种)的偏好来解释用户和专辑的关系,其中偏好信息并不能直接观察到,而数据也没有给出这些信息。
这里的偏好,其实就是我们上述要求的 k 里的值。这个k就是潜在因素,用于解释数据中的交互关系。由于k 很小,矩阵分解算法只能是某种近似。所以上述图里用的约等于号。
5. 矩阵补全算法
矩阵分解算法有时也称为矩阵补全(matrix completion)算法。因为原始矩阵A 可能非常稀疏,但是乘积 是稠密的。
因为在我们计算出所有列里的系数(最优解)后,在使用 XYT 还原A时,大部分数据会被补全。
两个矩阵分别有一行对应每个用户和每个艺术家。每行的值很少,只有 k 个。每个值代表了对应模型的一个隐含特征。
因此行表示了用户和艺术家怎样关联到这些隐含特征,而隐含特征可能就对应偏好或类别。
于是问题就简化为 用户 – 特征矩阵 和 特征 – 艺术家矩阵 的乘积,该乘积的结果是对整个稠密的 用户 – 艺术家 相互关系矩阵的完整估计。

不幸的是,A = XYT 通常根本没有解。原因就是X 和 Y 通常不够大(严格来讲,就是矩阵的阶太小),无法完美表示 A。
这其实也是好事。A 只是所有可能出现的交互关系的一个微小样本。在某种程度上我们认为 A 是对基本事实的一次观察,它太稀疏,因此很难解释这个基本事实。但用少数几个因素(k 个)就能很好地解释这个基本事实。
XYT 应该尽可能逼近 A,毕竟这是所有后续工作的基础,但它不能也不应该完全复制A。然而同样不幸的是,想直接得到 X 和 Y 的最优解是不可能的。好消息是,如果 Y 已知,求 X 的最优解是非常容易的,反之亦然。但 X 和 Y 事先都是未知的
当然,我们仍有办法求解X 和 Y,其中之一便是交替最小二乘(Alternating Least Squares, ALS)法。Spark Mllib 的ALS 就是此算法的实现。
虽然 Y 是未知的,但我们可以把它初始化为随机行向量矩阵。接着运用简单的线性代数,就能在给定 A 和 Y 的条件下求出 X 的最优解。
实际上,X 的第 i 行是 A 的第 i 行和 Y 的函数,因此可以很容易分开计算 X 的每一行。因为 X 的每一行可以分开计算,所以我们可以将其并行化,而并行化是大规模计算的一大优点。
AiY(YTY)-1 = Xi
想要两边精确相等是不可能的,因此实际的目标是最小化 | AiY(YTY)-1 - Xi | ,或者最小化它们的平方误差(为了计算优化方便)。这也就是著名的最小二乘法。
这里给出的方程式只是为了说明行向量的计算方法,但实践中从来不会对矩阵求逆,我们会借助于QR 分解之类的方法,这种方法速度更快且更直接。
同理,我们可以由X 计算 Yj 。然后又可以由 Y 计算 X,这样反复下去。这就是算法中“交替”的由来。
这里 Y 是随机的,X是由最优化计算出来的,如此迭代下去,X 和 Y 最终会收敛得到一个合适的结果。
将 ALS 算法用于隐形数据矩阵分解时,ALS 矩阵分解稍微复杂一点。它不是直接分解输入矩阵 A,而是分解由 0 和 1 组成的矩阵 P,当 A 中元素为正时,P 中对应元素为 1,否则为 0。A 中的具体值会在后面以权重的形式反映出来。
ALS 算法也可以利用输入数据是稀疏的这一特点。稀疏的输入数据、可以用简单的线性代数运算求最优解,以及数据本身可并行化,这三点使得算法在大规模数据上速度非常快。
6. 准备数据
1. 先把数据上传到 HDFS
2. Spark Mllib 的 ALS 算法实现有一个小缺点:它要求用户和产品的 ID 必须是数值型,并且是 32 位非负整数。这意味着大于 Integer.MAX_VALUE(即2147483647)的ID 都是非法的。我们的数据是否满足了这个要求?
3. 导入数据:
val rawUserArtistData = sc.textFile(“hdfs:///user/hadoop/profiledata/user_artist_data.txt“, 24)
默认情况下,RDD 为每个HDFS 块生成一个分区,将HDFS 块大小设为典型的128M 或 64M。
由于此文件大小为 400M 左右,所以文件被拆为 3 个或 6 个分区。这通常没什么问题,但由于相比简单文本处理,ALS 这类机器学习算法要消耗更多的计算资源,因此减小数据块大小以增加分区个数会更好。
减小数据块能使Spark 处理任务的同时使用的处理器核数更多。可以为textFile方法设置第二个参数,用这个参数指定一个不同于默认值的分区数,这样就可以将分区数设置的更大些。比如,可以考虑将这个参数设为集群处理器总核数。
首先我们查看一下数据样例:
scala> val first = rawUserArtistData.first
first: String = 1000002 1 55 (分别为用户id,艺术家id,和播放次数)
然后使用stats统计数据查看用户与艺术家的id 是否超过ALS 限制:
scala> rawUserArtistData.map(_.split(' ')(0).toDouble).stats()
[Stage 0:> (0 + 4) / 24] (这里会用24个container)
res2: org.apache.spark.util.StatCounter = (max: 2443548.000000, …)
scala> rawUserArtistData.map(_.split(' ')(1).toDouble).stats()
res1: org.apache.spark.util.StatCounter = (max: 10794401.000000, …)
通过stats() 得到的统计数据,可以发现用户 id 最高为2443548,艺术家 id 最高为 10794401,都远小于 ALS 的数值型限制。
另一文件 artist_data.txt 里存放了艺术家名字以及数值ID。我们可以看一下数据样例:
val rawArtistData = sc.textFile("hdfs:///user/hadoop/profiledata/artist_data.txt", 24)
val first = rawArtistData.first
String = 1134999 06Crazy Life
每行数据将 id 与 艺术家名字 以 tab 分隔。这里我们可以使用 span() 方法来分割字符串,并返回一对元组:
scala> first.span(_ != '\t')
res9: (String, String) = (1134999," 06Crazy Life")
将span() 方法应用到集群数据:
scala> val artistByID = rawArtistData.map( line => {
| val (id, name) = line.span(_ != '\t')
| (id.toInt, name.trim)
| })
但是在应用到集群数据时,会遇到报错:
scala> artistByID.count
Caused by: java.lang.NumberFormatException: For input string: "3AW“
说明有些数据是非法的,并不完全遵循数据格式。
flatMap 与 map 均是对每个元素应用一个函数操作的函数,它们的区别为:
val books = List("Hadoop", "Hive", "HDFS")
scala> books.map(_.toList)
res24: List[List[Char]] = List(List(H, a, d, o, o, p), List(H, i, v, e), List(H, D, F, S))
scala> books.flatMap(_.toList)
res25: List[Char] = List(H, a, d, o, o, p, H, i, v, e, H, D, F, S)
map 会返回每个函数作用后的结果。flatMap 在返回结果后,再将结果集合展开。
现在我们使用flatMap 和 Option 类一起用,来对artist_data 进行处理:
val result = head.flatMap( line => {
val (id, name) = line.span(_ != '\t')
try{
Some((id.toInt, name.trim))
} catch {
case e: NumberFormatException => None}
})
为了更好的理解map、flatMap 以及 Option 类的 Some,我们看一下下面这个例子:
假设我们有以下数据:
scala> head
res25: Array[String] = Array(1134999 06Crazy Life, AVW13, 10113088 Terfel, Bartoli- Mozart: Don, 10151459 The Flaming Sidebur,…)
其中 head(1) 里的数据“AVW13” 为异常数据。此时我们先用map命令,得到的结果为:
Array[Option[(Int, String)]] = Array(Some((1134999,06Crazy Life)), None, Some((10113088,Terfel, Bartoli- Mozart: Don)), …)
可以看到里面的元素为Option,且None 元素也被保留。
然后我们使用flatMap:
Array[(Int, String)] = Array((1134999,06Crazy Life), (10113088,Terfel, Bartoli- Mozart: Don), (10151459,The Flaming Sidebur),…)
可以看到 None 数据被过滤,且数据类型不再是 Option,而是元组。
由此说明,flatMap 在展开后,过滤掉了None,并且只展开一层(即Option[(Int, String)] )
Option 代表一个值可以不存在,有点像只有 1 或 0 的一个简单集合,1 对应子类 Some,0 对应子类 None。在上述案例中,返回的要么是 Some((id.toInt, name.trim)) 要么是 None
artist_alias.txt 将拼写错误的艺术家 ID 或非标准的艺术家 ID 映射为艺术家的正规名字。其中每行有两个ID,用制表符分隔。
这里我们有必要把它转成 Map 集合的形式,将“非标准的艺术家ID” 映射为“标准的艺术家ID”:
scala> val artistAlias = rawArtistAlias.flatMap{ line =>
| val tokens = line.split('\t')
| Some((tokens(0).toInt, tokens(1).toInt))
| }
但是发现以上代码报错:java.lang.NumberFormatException: For input string: ""
说明有数据异常,它为空字符串
因此我们再修改一下代码,若字符串为 “”,则返回None:
scala> val artistAlias = rawArtistAlias.flatMap{ line =>
val tokens = line.split('\t')
if (tokens(0).isEmpty) {
None
} else {
Some((tokens(0).toInt, tokens(1).toInt))
}}
artistAlias: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[11] at flatMap at <console>:25
scala> artistAlias.first
res1: (Int, Int) = (1092764,1000311)
在获取到ID 对应的元组后,我们可以使用 collectAsMap 方法将元组转为Map:val artistAlias = rawArtistAlias.flatMap{ line =>
val tokens = line.split('\t')
if (tokens(0).isEmpty) {
None
} else {
Some((tokens(0).toInt, tokens(1).toInt))
}}.collectAsMap()
artistAlias: scala.collection.Map[Int,Int] = Map(6803336 -> 1000010, 6663187 -> 1992, 2124273 -> 2814, 10412283 -> 1010353,…
从第一条记录我们可以看到:
6803336 映射为 1000010
我们在artistByID里查询这两条记录:
scala> artistByID.lookup(6803336).head
res9: String = Aerosmith (unplugged)
scala> artistByID.lookup(1000010).head
res10: String = Aerosmith
显然,这条记录将 Aerosmith (unplugged) 映射为 Aerosmith
7. 构建第一个模型
现在的数据集的形式完全符合Spark Mllib 的ALS 算法实现的要求,但我们还需额外做两个转换:
- 如果艺术家ID 存在一个不同的正规 ID,我们要用别名数据集对象将所有的艺术家ID 转换成正规 ID
- 需要把数据转成 Rating 对象,Rating 对象是ALS 算法实现对“用户 – 产品 – 值” 的抽象
scala> import org.apache.spark.mllib.recommendation._
scala> val bArtistAlias = sc.broadcast(artistAlias)
bArtistAlias: org.apache.spark.broadcast.Broadcast[scala.collection.Map[Int,Int]] = Broadcast(6)
scala> val trainData = rawUserArtistData.map { line =>
| val Array(userID, artistID, count) = line.split(' ').map(_.toInt)
| val finalArtistID =
| bArtistAlias.value.getOrElse(artistID, artistID)
| Rating(userID, finalArtistID, count)
| }.cache()
8. 广播变量
val bArtistAlias = sc.broadcast(artistAlias)
这里用了一个广播变量,将artistAlias 变量作为一个广播变量。广播变量的作用如下:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks.
Explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.
广播变量主要用于在迭代中一直需要被访问的只读变量。它将此变量缓存在每个executor 里,以减少集群网络传输消耗
Spark 执行一个阶段(stage)时,会为待执行函数建立闭包,也就是该阶段所有任务所需信息的二进制形式。这个闭包包括驱动程序里函数引用的所有数据结构。Spark 把这个闭包发送到集群的每个executor 上。
当许多任务需要访问同一个(不可变的)数据结构时,我们应该使用广播变量。它对任务闭包的常规处理进行扩展,是我们能够:
- 在每个 executor 上将数据缓存为原始的 Java 对象,这样就不用为每个人物执行反序列化
- 在多个作业和阶段之间缓存数据
在函数最后,我们调用了 cache() 以指示 Spark 在 RDD 计算好后将其暂时存储在集群的内存里。这样是有益的,因为 ALS 算法是 迭代的,通常情况下至少要访问该数据 10 次以上。如果不调用 cache(),那么每次要用到 RDD 时都需要从原始数据中重新计算。
9. 构建模型
现在我们已有了训练数据 Rating,格式如下:
Rating(1000002,1,55.0)
分别对应用户id,艺术家id,听的次数
然后我们构建模型:
scala> val model = ALS.trainImplicit(trainData, 10, 5, 0.01, 1.0)
这里除了训练数据外,其他全是模型参数。具体参数我们之后再介绍,这里可以先了解这个 10 是指 10 个特征向量,也就是 k 的值。
在这个例子中,对于每个用户和产品,模型都包含一个有 10 个值的特征向量。根据前面的介绍,我们将矩阵A 分为了两个矩阵 X 与 Y 的乘积。所以最终模型用两个不同的 RDD,它们分别表示“用户 - 特征” 和 “产品 – 特侦” 这两个大型矩阵。
我们再看看生产的模型里支持的操作:
scala> model.
predict productFeatures rank recommendProducts recommendProductsForUsers recommendUsers recommendUsersForProducts save userFeatures
从字面上我们可以基本判断模型支持的操作。其中 productFeatures 和 userFeatures 便是对艺术家和用户生成的特征。每条是一个包含10个元素的数组,也称为一个特征向量。
scala> model.userFeatures.first
res13: (Int, Array[Double]) = (120,Array(-0.16259685158729553, 0.058804575353860855, -0.08195385336875916, 0.14299602806568146, -0.24055717885494232, 0.07681675255298615, -0.1902841031551361, -0.17557889223098755, 0.10770561546087265, 0.15148405730724335))
上面即为用户120的特征向量
10. 检查推荐结果
现在我们看看模型给出的推荐从直观上来看是否合理:
1. 首先我们先获取某个用户听过的艺术家:
val rawArtistsForUser = rawUserArtistData.map(_.split(' ')).
filter { case Array(user,_,_) => user.toInt == 2093760}
2. 获取艺术家id并去重
scala> val existingProducts = rawArtistsForUser.map{ case Array(_,artist,_) => artist.toInt}.collect().toSet
existingProducts: scala.collection.immutable.Set[Int] = Set(1255340, 942, 1180, 813, 378)
打印出艺术家名字:
scala> artistByID.filter { case (id, name) => existingProducts.contains(id)}.values.collect().foreach(println)
David Gray
Blackalicious
Jurassic 5
The Saw Doctors
Xzibit
然后我们使用模型给此用户做5个推荐:
scala> val recommendations = model.recommendProducts(2093760, 5)
recommendations: Array[org.apache.spark.mllib.recommendation.Rating] = Array(
Rating(2093760,2814,0.031054236194155326), Rating(2093760,1001819,0.03031702049169676), Rating(2093760,930,0.029521346550942212), Rating(2093760,1300642,0.029004849813751586), Rating(2093760,4605,0.029003239498464842)
)
每个Rating 包括用户id,艺术家id,以及一个评分值。值越大,推荐质量越好。
scala> val recommendedProductIDs = recommendations.map(_.product).toSet
scala> artistByID.filter { case(id, name) =>
| recommendedProductIDs.contains(id)
| }.values.collect.foreach(println)
50 Cent
Snoop Dogg
2Pac
Eminem
The Game
看得出这些推荐并不咋样,虽然这些艺术家都比较受欢迎,而且是hippop之类的歌曲。但好像并没有针对用户的收听习惯进行个性化
11. 评价推荐质量
再考虑如何评价推荐质量:
- 我们假定用户会倾向于播放受人欢迎的艺术家的歌曲,而不会播放不受欢迎的艺术家的歌曲,这个假设是合理的。因此,用户的播放数据在一定程度上表示了“优秀的”和“糟糕的”艺术家推荐
- 推荐引擎这类的评分系统评价的指标之一就是:好艺术家在推荐列表中应该靠前。问题是如何评价“好的艺术家”?
- 推荐引擎的作用在于向用户推荐他从来没有听过的艺术家
计算AUC 来衡量模型,以及使用training data 和 test data
12. 选择超参数
超参数并不是通过算法学习到的参数,而是由调用者指定的指定。
在 ALS.trainImplicit() 的参数包括以下几个:
1. rank = 10
模型的潜在因素的个数,即“用户 – 特征” 和 “产品 – 特征” 矩阵的列数;一般来说,它也是矩阵的阶
2. Iteration = 5
矩阵分解迭代的次数;迭代的次数越多,花费的时间越长,但分解的结果可能会更好。
3. lambda = 0.01
标准的过拟合参数;值越大越不容易产生过拟合,但值太大会降低分解的准确度
4. alpha = 1.0
控制矩阵分解时,被观察到的“用户 – 产品” 交互相对没被观察到的交互的权重
第一次使用的超参数不一定是最优的。如何选择好的超参数在机器学习中是个普遍性的问题。最基本的方法是尝试不同值的组合并对每个组合评估某个指标,然后挑选指标值最好的组合。
如:
val evaluation =
for ( rank <- Array(10, 50);
lambda <- Array(1.0, 0.0001)
alpha <- Array(1.0, 40.0))
yield {
val model = ALS.trainImplicit(trainData, rank, 10, lambda, alpha)
val auc = …
((rank, lambda, alpha), auc) }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号