一、redis主从
1.redis主从原理
1.从库配置主从同步
2.从库像主库发起sync命令
3.主库接收sync命令,执行bgsave,生成持久化rdb文件
4.主库将新的数据临时写入缓冲区
5.主库将rdb文件推送至从库
6.从库接收到rdb文件,会清空自己的数据
7.从库读取并导入rdb文件
8.主库将缓冲区的数据也传给从库
9.实现数据同步
2.redis主从实践
1)环境准备
| 角色 |
主机 |
IP |
端口 |
| 主库 |
db01 |
172.16.1.51 |
6379 |
| 从库 |
db02 |
172.16.1.52 |
6379 |
| 从库 |
db03 |
172.16.1.53 |
6379 |
2)配置主从
#1.登陆三台redis
[root@db01 redis]# redis-cli -h 172.16.1.51
172.16.1.51:6379>
[root@db02 redis]# redis-cli -h 172.16.1.52
172.16.1.52:6379>
[root@db03 redis]# redis-cli -h 172.16.1.53
172.16.1.53:6379>
#2.查看主从状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#3.配置主从
172.16.1.52:6379> SLAVEOF 172.16.1.51 6379
OK
172.16.1.53:6379> SLAVEOF 172.16.1.51 6379
OK
#4.再次查看主从状态
#主库
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.52,port=6379,state=online,offset=29,lag=0
slave1:ip=172.16.1.53,port=6379,state=online,offset=29,lag=0
master_repl_offset:29
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:28
#从库
172.16.1.52:6379> info replication
# Replication
role:slave
master_host:172.16.1.51
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:71
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#5.如果主库有密码
在从库的配置文件中加上
masterauth 123
3.如果主库出现故障
1)模拟主库故障
[root@db01 redis]# redis-cli shutdown
2)查看从库状态
172.16.1.52:6379> info replication
# Replication
role:slave
master_host:172.16.1.51
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:393
master_link_down_since_seconds:63
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
172.16.1.52:6379> set k1 v2
(error) READONLY You can't write against a read only slave.
#从库仍然还是从库,还是只读权限,没有办法提供写服务
3)选择一台机器,取消主从
#取消主从
172.16.1.52:6379> SLAVEOF no one
OK
#再次查看状态
172.16.1.52:6379> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
4)将其他从库指向新的主库
#重新做主从
172.16.1.53:6379> SLAVEOF 172.16.1.52 6379
OK
172.16.1.53:6379> info replication
# Replication
role:slave
master_host:172.16.1.52
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:1
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
二、redis高可用--sentinel哨兵
![]()
![]()
1.sentinel介绍
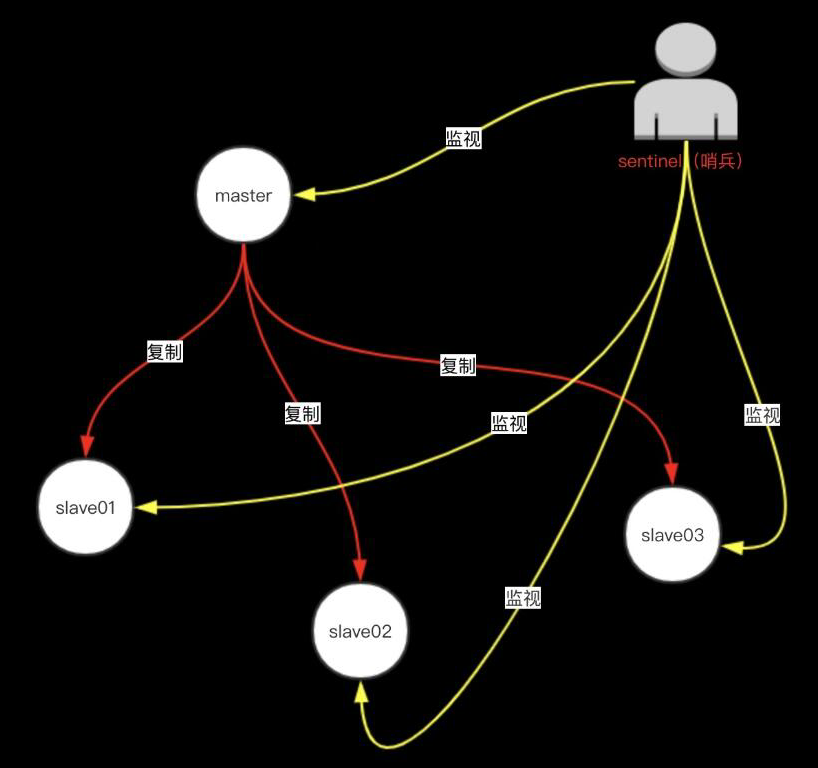
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
#必须在redis主从已经做好的前提下
2.sentinel的构造
Sentinel 是一个监视器,它可以根据被监视实例的身份和状态来判断应该执行何种动作。
![1596676063797]()
3.sentinel的功能
1.监控(Monitoring):
Sentinel会不断地检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification):
当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
4.sentinel的具体工作
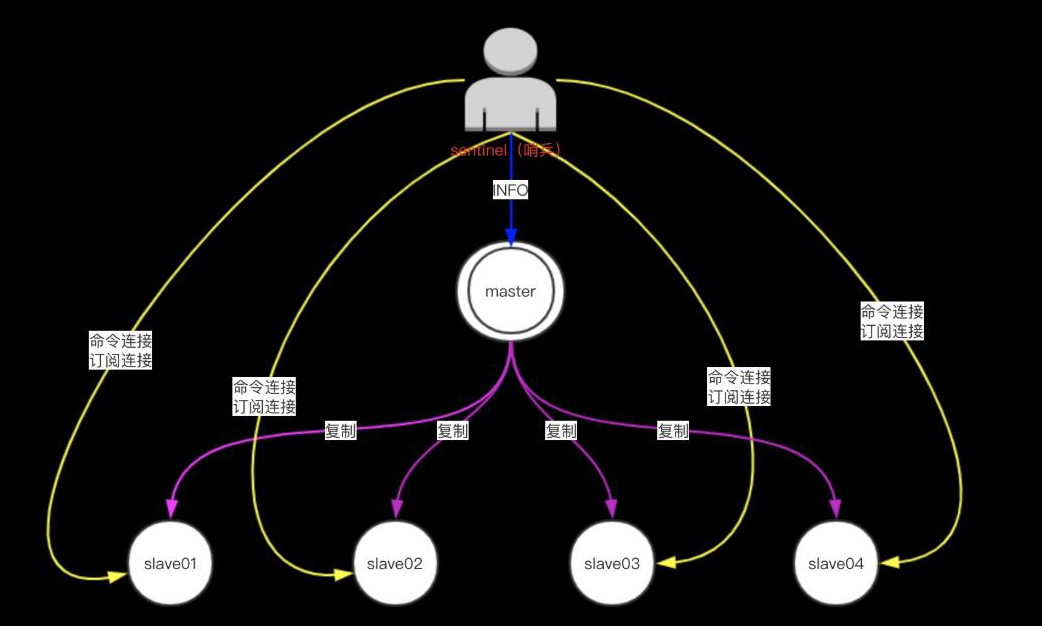
1.Sentinel通过用户给定的配置文件来发现主服务器
2.Sentinel会与被监视的主服务器创建两个网络连接:
命令连接用于向主服务器发送命令。
订阅连接用于订阅指定的频道,从而发现监视同一主服务器的其他Sentinel。
3.Sentinel通过向主服务器发送INFO命令来自动获得所有从服务器的地址。
4.发现其他sentinel
Sentinel 会通过命令连接向被监视的主从服务器发送 “HELLO” 信息,该消息包含 Sentinel 的 IP、端口号、ID 等内容,以此来向其他 Sentinel 宣告自己的存在。与此同时Sentinel 会通过订阅连接接收其他 Sentinel 的“HELLO” 信息,以此来发现监视同一个主服务器的其他 Sentinel 。
5.多个Sentinel之间只会互相创建命令连接,用于进行通信。因为已经有主从服务器作为发送和接收HELLO信息的中介,所以Sentinel之间不会创建订阅连接。
6.检测实例的状态:
Sentinel使用PING命令来检测实例的状态:如果实例在指定的时间内没有返回回复,或者返回错误的回复,那么该实例会被 Sentinel 判断为下线。
Redis的Sentinel中关于下线(down)有两个不同的概念:
1)主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
2)客观下线(Objectively Down,简称 ODOWN)指的是多个Sentinel实例在对同一个服务器做出SDOWN判断,并且通过SENTINEL is-master-down-by-addr命令互相交流之后,得出的服务器下线判断。(一个 Sentinel可以通过向另一个Sentinel发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。)
5.故障转移流程
一次故障转移操作由以下步骤组成:
1.发现主服务器已经进入客观下线状态。
2.基于Raft leader election协议,进行投票选举
3.如果当选失败,那么在设定的故障迁移超时时间的两倍之后,重新尝试当选。如果当选成功,那么执行以下步骤。
1)选出一个从服务器,并将它升级为主服务器。
2)向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
3)通过发布与订阅功能,将更新后的配置传播给所有其他Sentinel,其他Sentinel对它们自己的配置进行更新。
4)向已下线主服务器的从服务器发送SLAVEOF命令,让它们去复制新的主服务器。
5)当所有从服务器都已经开始复制新的主服务器时, leader Sentinel 终止这次故障迁移操作。
6.sentinel选择主库的规则
1.在失效主服务器属下的从服务器当中,那些被标记为主观下线、已断线、或者最后一次回复PING命令的时间大于五秒钟的从服务器都会被淘汰。
2.在失效主服务器属下的从服务器当中,那些与失效主服务器连接断开的时长超过down-after选项指定的时长十倍的从服务器都会被淘汰。
3.在经历了以上两轮淘汰之后剩下来的从服务器中,我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器;如果复制偏移量不可用,或者从服务器的复制偏移量相同,那么带有最小运行ID的那个从服务器成为新的主服务器。
7.sentinel特性
1.Sentinel自动故障迁移使用Raft算法来选举领头(leader)Sentinel ,从而确保在一个给定的周期(epoch)里,只有一个领头产生。
2.这表示在同一个周期中,不会有两个 Sentinel 同时被选中为领头,并且各个 Sentinel 在同一个节点中只会对一个领头进行投票。
3.更高的配置节点总是优于较低的节点,因此每个 Sentinel 都会主动使用更新的节点来代替自己的配置。
#简单来说,我们可以将Sentinel配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他Sentinel。
三、sentinel实战
1.环境准备
| 角色 |
主机 |
IP |
端口 |
| 主库 |
db01 |
172.16.1.51 |
6379 |
| 从库 |
db02 |
172.16.1.52 |
6379 |
| 从库 |
db03 |
172.16.1.53 |
6379 |
2.恢复主从状态
#修复坏掉的主库
[root@db01 ~]# redis-server /service/redis/6379/redis.conf
[root@db01 ~]# redis-cli -h 172.16.1.51
172.16.1.51:6379> info replication
172.16.1.51:6379> SLAVEOF 172.16.1.52 6379
OK
172.16.1.51:6379> info replication
#主库查看
172.16.1.52:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.53,port=6379,state=online,offset=4229,lag=1
slave1:ip=172.16.1.51,port=6379,state=online,offset=4229,lag=1
master_repl_offset:4229
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:4228
3.配置sentinel哨兵
#创建目录(随便创建)
[root@db01 ~]# mkdir /service/redis/26379
#编辑sentinel配置文件
[root@db01 ~]# vim /service/redis/26379/sentinel.conf
port 26379
daemonize yes
pidfile /service/redis/26379/sentinel.pid
logfile /service/redis/26379/sentinel.log
dir /service/redis/26379
bind 172.16.1.51 127.0.0.1
sentinel monitor mymaster 172.16.1.52 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
4.启动sentinel
[root@db01 ~]# redis-sentinel /service/redis/26379/sentinel.conf
#启动之后配置文件会发生改变
[root@db01 ~]# vim /service/redis/26379/sentinel.conf
port 26379
daemonize yes
pidfile "/service/redis/26379/sentinel.pid"
logfile "/service/redis/26379/sentinel.log"
dir "/service/redis/26379"
bind 172.16.1.51 127.0.0.1
sentinel myid 7d430385a1269307819e5300ecf09dfbf92b46f5
sentinel monitor mymaster 172.16.1.52 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel config-epoch mymaster 0
# Generated by CONFIG REWRITE
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 172.16.1.51 6379
sentinel known-slave mymaster 172.16.1.53 6379
sentinel current-epoch 0
5.停止sentinel
[root@db01 ~]# redis-cli -p 26379 shutdown
6.测试sentinel
#关闭主库的redis
[root@db02 ~]# redis-cli shutdown
#查看其它从库主从状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.16.1.53,port=6379,state=online,offset=586,lag=1
master_repl_offset:723
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:722
7.恢复故障节点
#修复故障节点
[root@db02 ~]# redis-server /service/redis/6379/redis.conf
#查看主库状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.53,port=6379,state=online,offset=5077,lag=1
slave1:ip=172.16.1.52,port=6379,state=online,offset=5077,lag=1
master_repl_offset:5077
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:5076
8.sentinel管理命令(不常用)
#连接sentinel管理端口
[root@db01 ~]# redis-cli -p 26379
#检测状态,返回PONG
127.0.0.1:26379> ping
PONG
#列出所有被监视的主服务器
127.0.0.1:26380> SENTINEL masters
#列出所有被监视的从服务器
127.0.0.1:26380> SENTINEL slaves mymaster
#返回给定名字的主服务器的IP地址和端口号
127.0.0.1:26380> SENTINEL get-master-addr-by-name mymaster
1) "172.16.1.51"
2) "6379
#重置所有名字和给定模式
127.0.0.1:26380> SENTINEL reset mymaster
#当主服务器失效时,在不询问其他Sentinel意见的情况下,强制开始一次自动故障迁移。
127.0.0.1:26380> SENTINEL failover mymaster
9.设置权重,指定主库的优先级
#查看db02的权重
172.16.1.52:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "100"
#修改db02的权重值为0
172.16.1.52:6379> CONFIG set slave-priority 0
OK
172.16.1.52:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "0"
#权重值越低越不会优先切换为主库
#强制开始一次自动故障迁移
127.0.0.1:26380> SENTINEL failover mymaster
#再次查看,主库为db03
172.16.1.53:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.52,port=6379,state=online,offset=71377,lag=0
slave1:ip=172.16.1.51,port=6379,state=online,offset=71377,lag=0
master_repl_offset:71514
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:70496
repl_backlog_histlen:1019
四、Redis Cluster 分布式集群
1.什么是Redis Cluster
1.Redis集群是一个可以在多个Redis节点之间进行数据共享的设施(installation)
2.Redis集群不支持那些需要同时处理多个键的Redis命令,因为执行这些命令需要在多个Redis节点之间移动数据,并且在高负载的情况下,这些命令将降低Redis集群的性能,并导致不可预测的行为。(使用ack协议)
3.Redis集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
4.Redis集群有将数据自动切分(split)到多个节点的能力。
2.Redis Cluster的特点
#高性能:
1.在多分片节点中,将16384个槽位,均匀分布到多个分片节点中
2.存数据时,将key做crc16(key),然后和16384进行取模,得出槽位值(0-16384之间)
3.根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上
4.如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进行数据存储
5.客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
6.Redis Cluster解决了redis资源利用率的问题
#高可用
7.在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof功能,同时当主节点down,实现类似于sentinel的自动failover的功能。
3.槽的概念
1.在集群中,会把所有节点分为16384个槽位
2.槽位的序号是 0 - 16383,序号不重要,数量才重要
3.每一个槽位分配到数据的概率是一样
4.redis故障转移
1.在集群里面,节点会对其他节点进行下线检测。
2.当一个主节点下线时,集群里面的其他主节点负责对下线主节点进行故障移。
3.换句话说,集群的节点集成了下线检测和故障转移等类似 Sentinel 的功能。
五、redis集群搭建
1.环境准备
| 节点 |
IP |
端口 |
| 节点1 |
172.16.1.51 |
6379,6380 |
| 节点2 |
172.16.1.52 |
6379,6380 |
| 节点3 |
172.16.1.53 |
6379,6380 |
2.搭建redis
#删除以前的redis数据
[root@db01 ~]# rm -rf /service/redis/*
#创建多实例目录
[root@db01 ~]# mkdir /service/redis/{6379,6380}
[root@db02 ~]# mkdir /service/redis/{6379,6380}
[root@db03 ~]# mkdir /service/redis/{6379,6380}
#配置所有redis
[root@db01 ~]# vim /service/redis/6379/redis.conf
bind 172.16.1.51 127.0.0.1
port 6379
daemonize yes
pidfile /service/redis/6379/redis.pid
loglevel notice
logfile /service/redis/6379/redis.log
dbfilename dump.rdb
dir /service/redis/6379
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
[root@db01 ~]# vim /service/redis/6380/redis.conf
bind 172.16.1.51 127.0.0.1
port 6380
daemonize yes
pidfile /service/redis/6380/redis.pid
loglevel notice
logfile /service/redis/6380/redis.log
dbfilename dump.rdb
dir /service/redis/6380
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
3.启动所有redis
[root@db01 ~]# redis-server /service/redis/6379/redis.conf
[root@db01 ~]# redis-server /service/redis/6380/redis.conf
[root@db02 ~]# redis-server /service/redis/6379/redis.conf
[root@db02 ~]# redis-server /service/redis/6380/redis.conf
[root@db03 ~]# redis-server /service/redis/6379/redis.conf
[root@db03 ~]# redis-server /service/redis/6380/redis.conf
4.关联所有redis节点
1)登录所有节点
[root@db01 ~]# redis-cli -h 172.16.1.51 -p 6379
[root@db01 ~]# redis-cli -h 172.16.1.51 -p 6380
[root@db02 ~]# redis-cli -h 172.16.1.52 -p 6379
[root@db02 ~]# redis-cli -h 172.16.1.52 -p 6380
[root@db03 ~]# redis-cli -h 172.16.1.53 -p 6379
[root@db03 ~]# redis-cli -h 172.16.1.53 -p 6380
2)查看集群节点
#查看集群节点,每一各节点只能看到自己
172.16.1.51:6379> CLUSTER NODES
28faba09f4c0ec8cdb90d92e09636796427b7143 :6379 myself,master - 0 0 0 connected
3)关联所有节点
172.16.1.51:6379> CLUSTER MEET 172.16.1.51 6380
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.52 6379
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.52 6380
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.53 6379
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.53 6380
OK
#查看集群状态,所有节点
172.16.1.51:6379> CLUSTER NODES
aee9f4e6e09a452fd44bca7639be442b5138f141 172.16.1.52:6380 master - 0 1596687131655 4 connected
777412c8d6554e3390e1083bf1f55002be08cf62 172.16.1.51:6380 master - 0 1596687131352 2 connected
ef18ab5bab6d8bc06917a0cf2dc9bffa8b431087 172.16.1.52:6379 master - 0 1596687132362 3 connected
f2747c92813ea06b25c3e9c8d5232b46b3cf9d3d 172.16.1.53:6379 master - 0 1596687131856 0 connected
25f735f08ac62b2f758c1e2c21e178cc46279087 172.16.1.53:6380 master - 0 1596687131251 5 connected
28faba09f4c0ec8cdb90d92e09636796427b7143 172.16.1.51:6379 myself,master - 0 0 1 connected
5.分配槽位
#查看集群状态
172.16.1.51:6379> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:1168
cluster_stats_messages_received:1168
#槽位规划
db01: 5462 个槽位 (0-5461)
db02: 5461 个槽位 (5462-10922)
db03: 5461 个槽位 (10923-16383)
#分配槽位
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 CLUSTER ADDSLOTS {0..5461}
OK
[root@db02 ~]# redis-cli -p 6379 -h 172.16.1.52 CLUSTER ADDSLOTS {5462..10922}
OK
[root@db02 ~]# redis-cli -p 6379 -h 172.16.1.53 CLUSTER ADDSLOTS {10923..16383}
一、redis主从
1.redis主从原理
1.从库配置主从同步
2.从库像主库发起sync命令
3.主库接收sync命令,执行bgsave,生成持久化rdb文件
4.主库将新的数据临时写入缓冲区
5.主库将rdb文件推送至从库
6.从库接收到rdb文件,会清空自己的数据
7.从库读取并导入rdb文件
8.主库将缓冲区的数据也传给从库
9.实现数据同步
2.redis主从实践
1)环境准备
| 角色 |
主机 |
IP |
端口 |
| 主库 |
db01 |
172.16.1.51 |
6379 |
| 从库 |
db02 |
172.16.1.52 |
6379 |
| 从库 |
db03 |
172.16.1.53 |
6379 |
2)配置主从
#1.登陆三台redis
[root@db01 redis]# redis-cli -h 172.16.1.51
172.16.1.51:6379>
[root@db02 redis]# redis-cli -h 172.16.1.52
172.16.1.52:6379>
[root@db03 redis]# redis-cli -h 172.16.1.53
172.16.1.53:6379>
#2.查看主从状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#3.配置主从
172.16.1.52:6379> SLAVEOF 172.16.1.51 6379
OK
172.16.1.53:6379> SLAVEOF 172.16.1.51 6379
OK
#4.再次查看主从状态
#主库
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.52,port=6379,state=online,offset=29,lag=0
slave1:ip=172.16.1.53,port=6379,state=online,offset=29,lag=0
master_repl_offset:29
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:28
#从库
172.16.1.52:6379> info replication
# Replication
role:slave
master_host:172.16.1.51
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:71
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#5.如果主库有密码
在从库的配置文件中加上
masterauth 123
3.如果主库出现故障
1)模拟主库故障
[root@db01 redis]# redis-cli shutdown
2)查看从库状态
172.16.1.52:6379> info replication
# Replication
role:slave
master_host:172.16.1.51
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:393
master_link_down_since_seconds:63
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
172.16.1.52:6379> set k1 v2
(error) READONLY You can't write against a read only slave.
#从库仍然还是从库,还是只读权限,没有办法提供写服务
3)选择一台机器,取消主从
#取消主从
172.16.1.52:6379> SLAVEOF no one
OK
#再次查看状态
172.16.1.52:6379> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
4)将其他从库指向新的主库
#重新做主从
172.16.1.53:6379> SLAVEOF 172.16.1.52 6379
OK
172.16.1.53:6379> info replication
# Replication
role:slave
master_host:172.16.1.52
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:1
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
二、redis高可用--sentinel哨兵
1.sentinel介绍
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
#必须在redis主从已经做好的前提下
2.sentinel的构造
Sentinel 是一个监视器,它可以根据被监视实例的身份和状态来判断应该执行何种动作。
![1596676063797]()
3.sentinel的功能
1.监控(Monitoring):
Sentinel会不断地检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification):
当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
4.sentinel的具体工作
1.Sentinel通过用户给定的配置文件来发现主服务器
2.Sentinel会与被监视的主服务器创建两个网络连接:
命令连接用于向主服务器发送命令。
订阅连接用于订阅指定的频道,从而发现监视同一主服务器的其他Sentinel。
3.Sentinel通过向主服务器发送INFO命令来自动获得所有从服务器的地址。
4.发现其他sentinel
Sentinel 会通过命令连接向被监视的主从服务器发送 “HELLO” 信息,该消息包含 Sentinel 的 IP、端口号、ID 等内容,以此来向其他 Sentinel 宣告自己的存在。与此同时Sentinel 会通过订阅连接接收其他 Sentinel 的“HELLO” 信息,以此来发现监视同一个主服务器的其他 Sentinel 。
5.多个Sentinel之间只会互相创建命令连接,用于进行通信。因为已经有主从服务器作为发送和接收HELLO信息的中介,所以Sentinel之间不会创建订阅连接。
6.检测实例的状态:
Sentinel使用PING命令来检测实例的状态:如果实例在指定的时间内没有返回回复,或者返回错误的回复,那么该实例会被 Sentinel 判断为下线。
Redis的Sentinel中关于下线(down)有两个不同的概念:
1)主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
2)客观下线(Objectively Down,简称 ODOWN)指的是多个Sentinel实例在对同一个服务器做出SDOWN判断,并且通过SENTINEL is-master-down-by-addr命令互相交流之后,得出的服务器下线判断。(一个 Sentinel可以通过向另一个Sentinel发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。)
5.故障转移流程
一次故障转移操作由以下步骤组成:
1.发现主服务器已经进入客观下线状态。
2.基于Raft leader election协议,进行投票选举
3.如果当选失败,那么在设定的故障迁移超时时间的两倍之后,重新尝试当选。如果当选成功,那么执行以下步骤。
1)选出一个从服务器,并将它升级为主服务器。
2)向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
3)通过发布与订阅功能,将更新后的配置传播给所有其他Sentinel,其他Sentinel对它们自己的配置进行更新。
4)向已下线主服务器的从服务器发送SLAVEOF命令,让它们去复制新的主服务器。
5)当所有从服务器都已经开始复制新的主服务器时, leader Sentinel 终止这次故障迁移操作。
6.sentinel选择主库的规则
1.在失效主服务器属下的从服务器当中,那些被标记为主观下线、已断线、或者最后一次回复PING命令的时间大于五秒钟的从服务器都会被淘汰。
2.在失效主服务器属下的从服务器当中,那些与失效主服务器连接断开的时长超过down-after选项指定的时长十倍的从服务器都会被淘汰。
3.在经历了以上两轮淘汰之后剩下来的从服务器中,我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器;如果复制偏移量不可用,或者从服务器的复制偏移量相同,那么带有最小运行ID的那个从服务器成为新的主服务器。
7.sentinel特性
1.Sentinel自动故障迁移使用Raft算法来选举领头(leader)Sentinel ,从而确保在一个给定的周期(epoch)里,只有一个领头产生。
2.这表示在同一个周期中,不会有两个 Sentinel 同时被选中为领头,并且各个 Sentinel 在同一个节点中只会对一个领头进行投票。
3.更高的配置节点总是优于较低的节点,因此每个 Sentinel 都会主动使用更新的节点来代替自己的配置。
#简单来说,我们可以将Sentinel配置看作是一个带有版本号的状态。一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他Sentinel。
三、sentinel实战
1.环境准备
| 角色 |
主机 |
IP |
端口 |
| 主库 |
db01 |
172.16.1.51 |
6379 |
| 从库 |
db02 |
172.16.1.52 |
6379 |
| 从库 |
db03 |
172.16.1.53 |
6379 |
2.恢复主从状态
#修复坏掉的主库
[root@db01 ~]# redis-server /service/redis/6379/redis.conf
[root@db01 ~]# redis-cli -h 172.16.1.51
172.16.1.51:6379> info replication
172.16.1.51:6379> SLAVEOF 172.16.1.52 6379
OK
172.16.1.51:6379> info replication
#主库查看
172.16.1.52:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.53,port=6379,state=online,offset=4229,lag=1
slave1:ip=172.16.1.51,port=6379,state=online,offset=4229,lag=1
master_repl_offset:4229
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:4228
3.配置sentinel哨兵
#创建目录(随便创建)
[root@db01 ~]# mkdir /service/redis/26379
#编辑sentinel配置文件
[root@db01 ~]# vim /service/redis/26379/sentinel.conf
port 26379
daemonize yes
pidfile /service/redis/26379/sentinel.pid
logfile /service/redis/26379/sentinel.log
dir /service/redis/26379
bind 172.16.1.51 127.0.0.1
sentinel monitor mymaster 172.16.1.52 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
4.启动sentinel
[root@db01 ~]# redis-sentinel /service/redis/26379/sentinel.conf
#启动之后配置文件会发生改变
[root@db01 ~]# vim /service/redis/26379/sentinel.conf
port 26379
daemonize yes
pidfile "/service/redis/26379/sentinel.pid"
logfile "/service/redis/26379/sentinel.log"
dir "/service/redis/26379"
bind 172.16.1.51 127.0.0.1
sentinel myid 7d430385a1269307819e5300ecf09dfbf92b46f5
sentinel monitor mymaster 172.16.1.52 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel config-epoch mymaster 0
# Generated by CONFIG REWRITE
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 172.16.1.51 6379
sentinel known-slave mymaster 172.16.1.53 6379
sentinel current-epoch 0
5.停止sentinel
[root@db01 ~]# redis-cli -p 26379 shutdown
6.测试sentinel
#关闭主库的redis
[root@db02 ~]# redis-cli shutdown
#查看其它从库主从状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.16.1.53,port=6379,state=online,offset=586,lag=1
master_repl_offset:723
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:722
7.恢复故障节点
#修复故障节点
[root@db02 ~]# redis-server /service/redis/6379/redis.conf
#查看主库状态
172.16.1.51:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.53,port=6379,state=online,offset=5077,lag=1
slave1:ip=172.16.1.52,port=6379,state=online,offset=5077,lag=1
master_repl_offset:5077
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:5076
8.sentinel管理命令(不常用)
#连接sentinel管理端口
[root@db01 ~]# redis-cli -p 26379
#检测状态,返回PONG
127.0.0.1:26379> ping
PONG
#列出所有被监视的主服务器
127.0.0.1:26380> SENTINEL masters
#列出所有被监视的从服务器
127.0.0.1:26380> SENTINEL slaves mymaster
#返回给定名字的主服务器的IP地址和端口号
127.0.0.1:26380> SENTINEL get-master-addr-by-name mymaster
1) "172.16.1.51"
2) "6379
#重置所有名字和给定模式
127.0.0.1:26380> SENTINEL reset mymaster
#当主服务器失效时,在不询问其他Sentinel意见的情况下,强制开始一次自动故障迁移。
127.0.0.1:26380> SENTINEL failover mymaster
9.设置权重,指定主库的优先级
#查看db02的权重
172.16.1.52:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "100"
#修改db02的权重值为0
172.16.1.52:6379> CONFIG set slave-priority 0
OK
172.16.1.52:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "0"
#权重值越低越不会优先切换为主库
#强制开始一次自动故障迁移
127.0.0.1:26380> SENTINEL failover mymaster
#再次查看,主库为db03
172.16.1.53:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.52,port=6379,state=online,offset=71377,lag=0
slave1:ip=172.16.1.51,port=6379,state=online,offset=71377,lag=0
master_repl_offset:71514
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:70496
repl_backlog_histlen:1019
四、Redis Cluster 分布式集群
1.什么是Redis Cluster
1.Redis集群是一个可以在多个Redis节点之间进行数据共享的设施(installation)
2.Redis集群不支持那些需要同时处理多个键的Redis命令,因为执行这些命令需要在多个Redis节点之间移动数据,并且在高负载的情况下,这些命令将降低Redis集群的性能,并导致不可预测的行为。(使用ack协议)
3.Redis集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
4.Redis集群有将数据自动切分(split)到多个节点的能力。
2.Redis Cluster的特点
#高性能:
1.在多分片节点中,将16384个槽位,均匀分布到多个分片节点中
2.存数据时,将key做crc16(key),然后和16384进行取模,得出槽位值(0-16384之间)
3.根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上
4.如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进行数据存储
5.客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
6.Redis Cluster解决了redis资源利用率的问题
#高可用
7.在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof功能,同时当主节点down,实现类似于sentinel的自动failover的功能。
3.槽的概念
1.在集群中,会把所有节点分为16384个槽位
2.槽位的序号是 0 - 16383,序号不重要,数量才重要
3.每一个槽位分配到数据的概率是一样
4.redis故障转移
1.在集群里面,节点会对其他节点进行下线检测。
2.当一个主节点下线时,集群里面的其他主节点负责对下线主节点进行故障移。
3.换句话说,集群的节点集成了下线检测和故障转移等类似 Sentinel 的功能。
五、redis集群搭建
1.环境准备
| 节点 |
IP |
端口 |
| 节点1 |
172.16.1.51 |
6379,6380 |
| 节点2 |
172.16.1.52 |
6379,6380 |
| 节点3 |
172.16.1.53 |
6379,6380 |
2.搭建redis
#删除以前的redis数据
[root@db01 ~]# rm -rf /service/redis/*
#创建多实例目录
[root@db01 ~]# mkdir /service/redis/{6379,6380}
[root@db02 ~]# mkdir /service/redis/{6379,6380}
[root@db03 ~]# mkdir /service/redis/{6379,6380}
#配置所有redis
[root@db01 ~]# vim /service/redis/6379/redis.conf
bind 172.16.1.51 127.0.0.1
port 6379
daemonize yes
pidfile /service/redis/6379/redis.pid
loglevel notice
logfile /service/redis/6379/redis.log
dbfilename dump.rdb
dir /service/redis/6379
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
[root@db01 ~]# vim /service/redis/6380/redis.conf
bind 172.16.1.51 127.0.0.1
port 6380
daemonize yes
pidfile /service/redis/6380/redis.pid
loglevel notice
logfile /service/redis/6380/redis.log
dbfilename dump.rdb
dir /service/redis/6380
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
3.启动所有redis
[root@db01 ~]# redis-server /service/redis/6379/redis.conf
[root@db01 ~]# redis-server /service/redis/6380/redis.conf
[root@db02 ~]# redis-server /service/redis/6379/redis.conf
[root@db02 ~]# redis-server /service/redis/6380/redis.conf
[root@db03 ~]# redis-server /service/redis/6379/redis.conf
[root@db03 ~]# redis-server /service/redis/6380/redis.conf
4.关联所有redis节点
1)登录所有节点
[root@db01 ~]# redis-cli -h 172.16.1.51 -p 6379
[root@db01 ~]# redis-cli -h 172.16.1.51 -p 6380
[root@db02 ~]# redis-cli -h 172.16.1.52 -p 6379
[root@db02 ~]# redis-cli -h 172.16.1.52 -p 6380
[root@db03 ~]# redis-cli -h 172.16.1.53 -p 6379
[root@db03 ~]# redis-cli -h 172.16.1.53 -p 6380
2)查看集群节点
#查看集群节点,每一各节点只能看到自己
172.16.1.51:6379> CLUSTER NODES
28faba09f4c0ec8cdb90d92e09636796427b7143 :6379 myself,master - 0 0 0 connected
3)关联所有节点
172.16.1.51:6379> CLUSTER MEET 172.16.1.51 6380
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.52 6379
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.52 6380
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.53 6379
OK
172.16.1.51:6379> CLUSTER MEET 172.16.1.53 6380
OK
#查看集群状态,所有节点
172.16.1.51:6379> CLUSTER NODES
aee9f4e6e09a452fd44bca7639be442b5138f141 172.16.1.52:6380 master - 0 1596687131655 4 connected
777412c8d6554e3390e1083bf1f55002be08cf62 172.16.1.51:6380 master - 0 1596687131352 2 connected
ef18ab5bab6d8bc06917a0cf2dc9bffa8b431087 172.16.1.52:6379 master - 0 1596687132362 3 connected
f2747c92813ea06b25c3e9c8d5232b46b3cf9d3d 172.16.1.53:6379 master - 0 1596687131856 0 connected
25f735f08ac62b2f758c1e2c21e178cc46279087 172.16.1.53:6380 master - 0 1596687131251 5 connected
28faba09f4c0ec8cdb90d92e09636796427b7143 172.16.1.51:6379 myself,master - 0 0 1 connected
5.分配槽位
#查看集群状态
172.16.1.51:6379> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:1168
cluster_stats_messages_received:1168
#槽位规划
db01: 5462 个槽位 (0-5461)
db02: 5461 个槽位 (5462-10922)
db03: 5461 个槽位 (10923-16383)
#分配槽位
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 CLUSTER ADDSLOTS {0..5461}
OK
[root@db02 ~]# redis-cli -p 6379 -h 172.16.1.52 CLUSTER ADDSLOTS {5462..10922}
OK
[root@db02 ~]# redis-cli -p 6379 -h 172.16.1.53 CLUSTER ADDSLOTS {10923..16383}
6.插入数据测试集群
#插入一条数据
172.16.1.51:6379> set k1 v1
(error) MOVED 12706 172.16.1.53:6379
#报错,该key的值只能插入到12706这个槽位
[root@db03 ~]# redis-cli -h 172.16.1.53
172.16.1.53:6379> set k1 v1
OK
#ASK协议,自动切换将数据添加到指定槽位
[root@db03 ~]# redis-cli -h 172.16.1.53
172.16.1.53:6379> set k2 v2
(error) MOVED 449 172.16.1.51:6379
172.16.1.53:6379> quit
[root@db03 ~]# redis-cli -c -h 172.16.1.53
172.16.1.53:6379> set k2 v2
-> Redirected to slot [449] located at 172.16.1.51:6379
OK
#脚本插入数据测试
[root@db03 ~]# vim data.sh
#!/bin/bash
for i in {1..1000};do
redis-cli -c -p 6379 -h 172.16.1.51 set k${i} v${i}
done
#查看数据分配
172.16.1.51:6379> DBSIZE
(integer) 341
172.16.1.52:6379> DBSIZE
(integer) 332
172.16.1.53:6379> DBSIZE
(integer) 327
7.添加副本节点
1)查看节点
172.16.1.51:6379> CLUSTER NODES
5a7f0cf95e1850b5b5ae81d873c4c76fd366d604 172.16.1.51:6380 master - 0 1596763193422 4 connected
5eb9e5356534ff4acda736d13f0dc9fc3d40049b 172.16.1.52:6379 master - 0 1596763192412 5 connected 5462-10922
50878ef6a4d8141c8dbca3e2bf7c84ed48a73ee2 172.16.1.53:6380 master - 0 1596763192512 3 connected
acc3a4d0e6e43fc74630c1f0714865fdcbdaf677 172.16.1.53:6379 master - 0 1596763191908 0 connected 10923-16383
2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 172.16.1.51:6379 myself,master - 0 0 1 connected 0-5461
381b54584572e8013becdae2eeaff48bf6eb5450 172.16.1.52:6380 master - 0 1596763193925 2 connected
2)配置主从
#db01的6380做db02的6379的从库
172.16.1.51:6380> CLUSTER REPLICATE 5eb9e5356534ff4acda736d13f0dc9fc3d40049b
OK
#db02的6380做db03的6379的从库
172.16.1.52:6380> CLUSTER REPLICATE acc3a4d0e6e43fc74630c1f0714865fdcbdaf677
OK
#db03的6380做db01的6379的从库
172.16.1.53:6380> CLUSTER REPLICATE 2325be6f1f9c1c9f57d5a033fc05e0d798ea823a
OK
3)再次查看节点信息
172.16.1.51:6379> CLUSTER NODES
5a7f0cf95e1850b5b5ae81d873c4c76fd366d604 172.16.1.51:6380 slave 5eb9e5356534ff4acda736d13f0dc9fc3d40049b 0 1596763362696 5 connected
5eb9e5356534ff4acda736d13f0dc9fc3d40049b 172.16.1.52:6379 master - 0 1596763363202 5 connected 5462-10922
50878ef6a4d8141c8dbca3e2bf7c84ed48a73ee2 172.16.1.53:6380 slave 2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 0 1596763362192 3 connected
acc3a4d0e6e43fc74630c1f0714865fdcbdaf677 172.16.1.53:6379 master - 0 1596763363203 0 connected 10923-16383
2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 172.16.1.51:6379 myself,master - 0 0 1 connected 0-5461
381b54584572e8013becdae2eeaff48bf6eb5450 172.16.1.52:6380 slave acc3a4d0e6e43fc74630c1f0714865fdcbdaf677 0 1596763364211 2 connected
8.故障演示
#停掉一台节点
[root@db03 ~]# reboot
#到另一台机器查看集群状态,发现集群是正常的
172.16.1.51:6379> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_sent:327031
cluster_stats_messages_received:326973
#查看节点信息,副本被提升为主库
172.16.1.51:6379> CLUSTER NODES
5a7f0cf95e1850b5b5ae81d873c4c76fd366d604 172.16.1.51:6380 slave 5eb9e5356534ff4acda736d13f0dc9fc3d40049b 0 1596763771309 5 connected
5eb9e5356534ff4acda736d13f0dc9fc3d40049b 172.16.1.52:6379 master - 0 1596763771310 5 connected 5462-10922
50878ef6a4d8141c8dbca3e2bf7c84ed48a73ee2 172.16.1.53:6380 slave,fail 2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 1596763736458 1596763734245 3 disconnected
acc3a4d0e6e43fc74630c1f0714865fdcbdaf677 172.16.1.53:6379 master,fail - 1596763736458 1596763735246 0 disconnected
2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 172.16.1.51:6379 myself,master - 0 0 1 connected 0-5461
381b54584572e8013becdae2eeaff48bf6eb5450 172.16.1.52:6380 master - 0 1596763772319 6 connected 10923-16383
9.节点恢复
#修复机器
[root@db03 ~]# redis-server /service/redis/6379/redis.conf
[root@db03 ~]# redis-server /service/redis/6380/redis.conf
#再次查看节点信息
172.16.1.51:6379> CLUSTER NODES
5a7f0cf95e1850b5b5ae81d873c4c76fd366d604 172.16.1.51:6380 slave 5eb9e5356534ff4acda736d13f0dc9fc3d40049b 0 1596764061287 5 connected
5eb9e5356534ff4acda736d13f0dc9fc3d40049b 172.16.1.52:6379 master - 0 1596764060781 5 connected 5462-10922
50878ef6a4d8141c8dbca3e2bf7c84ed48a73ee2 172.16.1.53:6380 slave 2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 0 1596764059770 3 connected
acc3a4d0e6e43fc74630c1f0714865fdcbdaf677 172.16.1.53:6379 slave 381b54584572e8013becdae2eeaff48bf6eb5450 0 1596764062094 6 connected
2325be6f1f9c1c9f57d5a033fc05e0d798ea823a 172.16.1.51:6379 myself,master - 0 0 1 connected 0-5461
381b54584572e8013becdae2eeaff48bf6eb5450 172.16.1.52:6380 master - 0 1596764061789 6 connected 10923-16383
#原主节点修复后变为从节点
六、使用工具搭建redis集群
1.环境准备
| 节点 |
IP |
端口 |
| 节点1 |
172.16.1.51 |
6379,6380 |
| 节点2 |
172.16.1.52 |
6379,6380 |
| 节点3 |
172.16.1.53 |
6379,6380 |
2.搭建redis
3.启动所有redis
4.安装集群插件
#EPEL源安装ruby支持
[root@db01 ~]# yum install ruby rubygems -y
#查看gem源
[root@db01 ~]# gem sources -l
*** CURRENT SOURCES ***
http://rubygems.org/
#添加阿里云的gem源
[root@db01 ~]# gem sources -a http://mirrors.aliyun.com/rubygems/
http://mirrors.aliyun.com/rubygems/ added to sources
#删除国外gem源
[root@db01 ~]# gem sources --remove https://rubygems.org/
http://rubygems.org/ removed from sources
#再次查看gem源
[root@db01 ~]# gem sources -l
#使用gem安装redis的ruby插件
[root@db01 ~]# gem install redis -v 3.3.3
Successfully installed redis-3.3.3
1 gem installed
Installing ri documentation for redis-3.3.3...
Installing RDoc documentation for redis-3.3.3...
5. redis-trib.rb命令
[root@db01 ~]# redis-trib.rb
create #创建一个集群
check #检查集群
info #集群状态
fix #修复集群
reshard #重新分配槽位
rebalance #平衡槽位数量
add-node #添加节点
del-node #删除节点
set-timeout #设置超时时间
call #向集群所有机器输入命令
import #导入数据
help #帮助
6.关联所有节点
[root@db01 ~]# redis-trib.rb create --replicas 1 172.16.1.51:6379 172.16.1.52:6379 172.16.1.53:6379 172.16.1.52:6380 172.16.1.53:6380 172.16.1.51:6380
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
172.16.1.51:6379
172.16.1.52:6379
172.16.1.53:6379
Adding replica 172.16.1.52:6380 to 172.16.1.51:6379
Adding replica 172.16.1.51:6380 to 172.16.1.52:6379
Adding replica 172.16.1.53:6380 to 172.16.1.53:6379
M: 5ad7bd957133eac9c3a692b35f8ae72258cf0ece 172.16.1.51:6379
slots:0-5460 (5461 slots) master
M: 7c79559b280db9d9c182f3a25c718efe9e934fc7 172.16.1.52:6379
slots:5461-10922 (5462 slots) master
M: d27553035a3e91c78d375208c72b756e9b2523d4 172.16.1.53:6379
slots:10923-16383 (5461 slots) master
S: fee551a90c8646839f66fa0cd1f6e5859e9dd8e0 172.16.1.52:6380
replicates 5ad7bd957133eac9c3a692b35f8ae72258cf0ece
S: e4794215d9d3548e9c514c10626ce618be19ebfb 172.16.1.53:6380
replicates d27553035a3e91c78d375208c72b756e9b2523d4
S: 1d10edbc5ed08f85d2afc21cd338b023b9dd61b4 172.16.1.51:6380
replicates 7c79559b280db9d9c182f3a25c718efe9e934fc7
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join...
>>> Performing Cluster Check (using node 172.16.1.51:6379)
M: 5ad7bd957133eac9c3a692b35f8ae72258cf0ece 172.16.1.51:6379
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: e4794215d9d3548e9c514c10626ce618be19ebfb 172.16.1.53:6380
slots: (0 slots) slave
replicates d27553035a3e91c78d375208c72b756e9b2523d4
M: d27553035a3e91c78d375208c72b756e9b2523d4 172.16.1.53:6379
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: fee551a90c8646839f66fa0cd1f6e5859e9dd8e0 172.16.1.52:6380
slots: (0 slots) slave
replicates 5ad7bd957133eac9c3a692b35f8ae72258cf0ece
S: 1d10edbc5ed08f85d2afc21cd338b023b9dd61b4 172.16.1.51:6380
slots: (0 slots) slave
replicates 7c79559b280db9d9c182f3a25c718efe9e934fc7
M: 7c79559b280db9d9c182f3a25c718efe9e934fc7 172.16.1.52:6379
slots:5461-10922 (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
7.查看集群状态
[root@db01 ~]# redis-cli -h 172.16.1.51 -p 6379 CLUSTER NODES
e4794215d9d3548e9c514c10626ce618be19ebfb 172.16.1.53:6380 slave d27553035a3e91c78d375208c72b756e9b2523d4 0 1596767315453 5 connected
d27553035a3e91c78d375208c72b756e9b2523d4 172.16.1.53:6379 master - 0 1596767315453 3 connected 10923-16383
5ad7bd957133eac9c3a692b35f8ae72258cf0ece 172.16.1.51:6379 myself,master - 0 0 1 connected 0-5460
fee551a90c8646839f66fa0cd1f6e5859e9dd8e0 172.16.1.52:6380 slave 5ad7bd957133eac9c3a692b35f8ae72258cf0ece 0 1596767313429 4 connected
1d10edbc5ed08f85d2afc21cd338b023b9dd61b4 172.16.1.51:6380 slave 7c79559b280db9d9c182f3a25c718efe9e934fc7 0 1596767313935 6 connected
7c79559b280db9d9c182f3a25c718efe9e934fc7 172.16.1.52:6379 master - 0 1596767314949 2 connected 5461-10922
8.重新做主从
#由于使用工具,始终有一台机器从库本机的从库,所以要重新分配主从
172.16.1.52:6380> CLUSTER REPLICATE d27553035a3e91c78d375208c72b756e9b2523d4
OK
172.16.1.53:6380> CLUSTER REPLICATE 5ad7bd957133eac9c3a692b35f8ae72258cf0ece
OK
9.插入数据测试
[root@db01 ~]# redis-trib.rb info 172.16.1.52:6379
172.16.1.52:6379 (7c79559b...) -> 332 keys | 5462 slots | 1 slaves.
172.16.1.51:6379 (5ad7bd95...) -> 341 keys | 5461 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 327 keys | 5461 slots | 1 slaves.
[OK] 1000 keys in 3 masters.
0.06 keys per slot on average.
[root@db01 ~]# redis-trib.rb info 172.16.1.52:6379
172.16.1.52:6379 (7c79559b...) -> 661 keys | 5462 slots | 1 slaves.
172.16.1.51:6379 (5ad7bd95...) -> 674 keys | 5461 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 665 keys | 5461 slots | 1 slaves.
[OK] 2000 keys in 3 masters.
0.12 keys per slot on average.
七、redis集群节点修改
#添加和删除节点的流程
1.新节点添加槽位
2.源节点中的数据进行迁移
3.源节点数据迁移完毕
4.迁移下一个槽位的数据,依次循环
1.添加节点
1)准备新机器
[root@db02 ~]# mkdir /service/redis/{6381,6382}
[root@db02 ~]# vim /service/redis/6381/redis.conf
[root@db02 ~]# vim /service/redis/6382/redis.conf
#启动新节点
[root@db02 ~]# redis-server /service/redis/6381/redis.conf
[root@db02 ~]# redis-server /service/redis/6382/redis.conf
2)将新节点添加到集群
[root@db01 ~]# redis-trib.rb add-node 172.16.1.52:6381 172.16.1.51:6379
#或者
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 cluster meet 172.16.1.52:6381
#查看节点信息
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 cluster nodes
3)重新分配槽位
[root@db01 ~]# redis-trib.rb reshard 172.16.1.51:6379
#你想移动多少个槽位到新节点
How many slots do you want to move (from 1 to 16384)? 4096
#新节点的ID是什么
What is the receiving node ID? a298dbd22c10b8492d9ff4295504c50666f4fb2e
#输入源节点的ID,如果是所有节点直接使用all
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
source node #1:all
#你确定要这么分配?
Do you want to proceed with the proposed reshard plan (yes/no)? yes
#分配完毕,查看分配结果
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 cluster nodes
e4794215d9d3548e9c514c10626ce618be19ebfb 172.16.1.53:6380 slave 5ad7bd957133eac9c3a692b35f8ae72258cf0ece 0 1596769469815 5 connected
d27553035a3e91c78d375208c72b756e9b2523d4 172.16.1.53:6379 master - 0 1596769468805 3 connected 12288-16383
5ad7bd957133eac9c3a692b35f8ae72258cf0ece 172.16.1.51:6379 myself,master - 0 0 1 connected 1365-5460
fee551a90c8646839f66fa0cd1f6e5859e9dd8e0 172.16.1.52:6380 slave d27553035a3e91c78d375208c72b756e9b2523d4 0 1596769467797 4 connected
1d10edbc5ed08f85d2afc21cd338b023b9dd61b4 172.16.1.51:6380 slave 7c79559b280db9d9c182f3a25c718efe9e934fc7 0 1596769469513 6 connected
a298dbd22c10b8492d9ff4295504c50666f4fb2e 172.16.1.52:6381 master - 0 1596769468302 7 connected 0-1364 5461-6826 10923-12287
7c79559b280db9d9c182f3a25c718efe9e934fc7 172.16.1.52:6379 master - 0 1596769468302 2 connected 6827-10922
[root@db01 ~]#
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
172.16.1.51:6379 (5ad7bd95...) -> 499 keys | 4096 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 501 keys | 4096 slots | 1 slaves.
172.16.1.52:6381 (a298dbd2...) -> 502 keys | 4096 slots | 0 slaves.
172.16.1.52:6379 (7c79559b...) -> 498 keys | 4096 slots | 1 slaves.
[OK] 2000 keys in 4 masters.
0.12 keys per slot on average.
4)添加新节点的副本
[root@db02 ~]# redis-cli -h 172.16.1.52 -p 6382 cluster replicate a298dbd22c10b8492d9ff4295504c50666f4fb2e
#或者
[root@db01 ~]# redis-trib.rb add-node --slave --master-id a298dbd22c10b8492d9ff4295504c50666f4fb2e 172.16.1.52:6382 172.16.1.51:6379
(集群中任意一台机器)
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 cluster nodes
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
172.16.1.51:6379 (5ad7bd95...) -> 499 keys | 4096 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 501 keys | 4096 slots | 1 slaves.
172.16.1.52:6381 (a298dbd2...) -> 502 keys | 4096 slots | 1 slaves.
172.16.1.52:6379 (7c79559b...) -> 498 keys | 4096 slots | 1 slaves.
[OK] 2000 keys in 4 masters.
0.12 keys per slot on average.
#调整主从,尽量保证每一台机器的副本都不于主节点在一台机器
5)模拟故障
#分配槽位的过程中
[root@db01 ~]# redis-trib.rb reshard 172.16.1.51:6379
#执行Ctrl+c
#查看集群状态一些命令看不出来有错
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 cluster info
[root@db01 ~]# redis-cli -p 6379 -h 172.16.1.51 cluster nodes
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
#必须使用工具检查集群
[root@db01 ~]# redis-trib.rb check 172.16.1.51:6379
#错误一:172.16.1.52:6379节点正在导出槽位,172.16.1.52:6381节点正在导入槽位
>>> Check for open slots...
[WARNING] Node 172.16.1.52:6381 has slots in importing state (6885).
[WARNING] Node 172.16.1.52:6379 has slots in migrating state (6885).
[WARNING] The following slots are open: 6885
>>> Check slots coverage...
#错误二:172.16.1.52:6379节点正在导出槽位
>>> Check for open slots...
[WARNING] Node 172.16.1.52:6379 has slots in migrating state (6975).
[WARNING] The following slots are open: 6975
>>> Check slots coverage...
#错误三:
>>> Check for open slots...
[WARNING] Node 172.16.1.52:6381 has slots in importing state (7093).
[WARNING] The following slots are open: 7093
>>> Check slots coverage...
6)修复故障
#使用fix修复集群
[root@db01 ~]# redis-trib.rb fix 172.16.1.52:6379
#将槽位平均分配
1.平均之前
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
172.16.1.51:6379 (5ad7bd95...) -> 499 keys | 4096 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 501 keys | 4096 slots | 1 slaves.
172.16.1.52:6381 (a298dbd2...) -> 648 keys | 5320 slots | 1 slaves.
172.16.1.52:6379 (7c79559b...) -> 352 keys | 2872 slots | 1 slaves.
[OK] 2000 keys in 4 masters.
0.12 keys per slot on average.
2.平均分配(如果节点之间槽位数量相差较小,不会平均分配)
[root@db01 ~]# redis-trib.rb rebalance 172.16.1.51:6379
>>> Performing Cluster Check (using node 172.16.1.51:6379)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Rebalancing across 4 nodes. Total weight = 4
Moving 1224 slots from 172.16.1.52:6381 to 172.16.1.52:6379
#####################################################################################################
3平均分配之后
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
172.16.1.51:6379 (5ad7bd95...) -> 499 keys | 4096 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 501 keys | 4096 slots | 1 slaves.
172.16.1.52:6381 (a298dbd2...) -> 492 keys | 4096 slots | 1 slaves.
172.16.1.52:6379 (7c79559b...) -> 508 keys | 4096 slots | 1 slaves.
[OK] 2000 keys in 4 masters.
0.12 keys per slot on average.
2.删除节点
1)重新分配槽位
#重新分配
[root@db01 ~]# redis-trib.rb reshard 172.16.1.51:6379
How many slots do you want to move (from 1 to 16384)? 1365 #要分配的槽位数量
What is the receiving node ID? #接收槽位的节点id
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 要删除的节点id
Source node #2: done
Do you want to proceed with the proposed reshard plan (yes/no)? yes
#第二次重新分配
[root@db01 ~]# redis-trib.rb reshard 172.16.1.51:6379
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 7c79559b280db9d9c182f3a25c718efe9e934fc7
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:a298dbd22c10b8492d9ff4295504c50666f4fb2e
Source node #2:done
Do you want to proceed with the proposed reshard plan (yes/no)? yes
#第三次重新分配
[root@db01 ~]# redis-trib.rb reshard 172.16.1.51:6379
How many slots do you want to move (from 1 to 16384)? 1366
What is the receiving node ID? d27553035a3e91c78d375208c72b756e9b2523d4
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:a298dbd22c10b8492d9ff4295504c50666f4fb2e
Source node #2:done
Do you want to proceed with the proposed reshard plan (yes/no)? yes
2)查看重新分配以后的节点信息
[root@db01 ~]# redis-trib.rb info 172.16.1.51:6379
172.16.1.51:6379 (5ad7bd95...) -> 664 keys | 5461 slots | 1 slaves.
172.16.1.53:6379 (d2755303...) -> 665 keys | 5462 slots | 2 slaves.
172.16.1.52:6381 (a298dbd2...) -> 0 keys | 0 slots | 0 slaves.
172.16.1.52:6379 (7c79559b...) -> 671 keys | 5461 slots | 1 slaves.
[OK] 2000 keys in 4 masters.
0.12 keys per slot on average.
3)删除节点
#删除没有数据的主节点
[root@db01 ~]# redis-trib.rb del-node 172.16.1.52:6381 a298dbd22c10b8492d9ff4295504c50666f4fb2e
>>> Removing node a298dbd22c10b8492d9ff4295504c50666f4fb2e from cluster 172.16.1.52:6381
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
#删除从节点
[root@db01 ~]# redis-trib.rb del-node 172.16.1.52:6382 47e3638a203488218d8c62deb82e768598977ba4
>>> Removing node 47e3638a203488218d8c62deb82e768598977ba4 from cluster 172.16.1.52:6382
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
#删除时不能删除有数据的主节点,从节点可以随便删除
[root@db01 ~]# redis-trib.rb del-node 172.16.1.53:6379 d27553035a3e91c78d375208c72b756e9b2523d4
>>> Removing node d27553035a3e91c78d375208c72b756e9b2523d4 from cluster 172.16.1.53:6379
[ERR] Node 172.16.1.53:6379 is not empty! Reshard data away and try again.
八、redis数据迁移
1.安装迁移工具
#1.安装依赖
[root@db02 ~]# yum install -y automake libtool autoconf bzip2
#2.拉取工具
[root@db02 ~]# git clone https://github.com/vipshop/redis-migrate-tool
#或者上传包
#3.安装
[root@db02 ~]# cd redis-migrate-tool/
[root@db02 redis-migrate-tool]# autoreconf -fvi
[root@db02 redis-migrate-tool]# ./configure
[root@db02 redis-migrate-tool]# make
2.编写数据迁移脚本
[root@db02 redis-migrate-tool]# vim tocluster.sh
[source]
type: single
servers:
- 172.16.1.52:6381
[target]
type: redis cluster
servers:
- 172.16.1.51:6379
[common]
listen: 0.0.0.0:8888
3.单节点生成数据
[root@db03 ~]# vim data.sh
#!/bin/bash
for i in {1001..2000};do
redis-cli -c -p 6381 -h 172.16.1.52 set k${i} v${i}
done
[root@db03 ~]# sh data.sh
4.迁移数据
[root@db02 redis-migrate-tool]# src/redis-migrate-tool -c tocluster.sh &
九、数据审计
1.安装工具
#1.安装依赖
[root@db02 ~]# yum install -y python-pip python-devel
#2.安装工具
[root@db02 ~]# pip install rdbtools python-lzf
#3.下载或上传
[root@db02 ~]# git clone https://github.com/sripathikrishnan/redis-rdb-tools
#或者上传
[root@db02 ~]# tar xf redis-rdb-tools.tar.gz
#4.安装
[root@db02 ~]# cd redis-rdb-tools
[root@db02 redis-rdb-tools]# python setup.py install
2.确认生成rdb文件
[root@db02 6381]# redis-cli -p 6381
127.0.0.1:6381> bgsave
Background saving started
127.0.0.1:6381> quit
[root@db02 6381]# ll
total 44
-rw-r--r-- 1 root root 26206 Aug 7 15:18 dump.rdb
3.使用工具分析文件
#使用工具生成CSV表格,下载下来进行分析
[root@db02 6381]# rdb -c memory ./dump.rdb -f memory.csv

 浙公网安备 33010602011771号
浙公网安备 33010602011771号